1.本发明涉及计算机技术应用领域,尤其涉及一种构建水声目标识别模型的方法和装置。
背景技术:
2.水声目标识别是一项利用目标辐射噪声信号对目标进行分类的技术,基于传统统计模型的分类识别方法主要由预处理、特征提取与选择、分类器三步组成,常见的特征有功率谱、听觉谱、噪声包络信号识别(detection of envelope modulation on noise,简称demon)谱、低频分析记录(low frequency analysis recording,简称lofar)谱、小波特征、响度特征、梅尔倒谱系数(mel-frequency cepstral coefficients,简称mfcc)特征、感知线性预测(perceptual linear predictive,简称plp)特征等,能否提取到可靠的特征将会直接影响到水声目标的识别率。在大数据时代的背景下,人工神经网络的结构和算法不断优化,并在计算机图像识别领域取得了巨大的成功,同时,随着计算机硬件技术的飞速发展,神经网络的计算速度也获得了极大提高,从而进一步推动了神经网络的发展。如何利用深度神经网络完成水声目标识别任务也受到了越来越多的关注。深度神经网络可以直接从原始波形信号中自动提取特征,避免了复杂的特征提取和选择工作,而且利用神经网络也可以获得更高的识别率。
3.在实际工程应用中,水声数据获取困难且保密性较强,真实的水声目标数据非常稀少,用于训练目标识别模型的高质量水声样本进一步缩小。
4.针对目前相关技术中水声样本不足的问题,目前尚未得到有效的解决。
技术实现要素:
5.本发明实施例提供了一种构建水声目标识别模型的方法和装置,以至少解决相关技术中水声样本不足的问题。
6.根据本发明实施例的一个方面,提供了一种构建水声目标识别模型的方法,包括:选择水声数据样本,并将水声数据样本分为训练样本和测试样本;通过训练样本训练稠密连接网络,得到训练后的稠密连接网络;将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络。
7.可选的,选择水声数据样本,并将水声数据样本分为训练样本和测试样本包括:选择至少三类水声目标作为水声数据样本;依据预设比例将水声数据样本进行分类,得到训练样本和测试样本。
8.可选的,该方法还包括:构建稠密连接网络,其中,稠密连接网络包括:steam模块、密集连接模块、transition layer模块和分类模块。
9.进一步地,可选的,该方法还包括:确定网络的超参数,其中,超参数包括损失函数,学习率、迭代次数及批大小;损失函数包括:交叉熵损失函数。
10.可选的,通过训练样本训练稠密连接网络,得到训练后的稠密连接网络包括:通过
输入训练样本对稠密连接网络进行训练,得到训练样本对应的标签以及训练后的稠密连接网络。
11.进一步地,可选的,将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络包括:将测试样本输入训练后的稠密连接网络对测试样本中的数据进行识别,得到识别结果;依据识别结果判定训练后的稠密连接网络是否收敛;在判定结果为是的情况下,得到收敛的稠密连接网络。
12.根据本发明实施例的另一个方面,提供了一种构建水声目标识别模型的装置,包括:选择模块,用于选择水声数据样本,并将水声数据样本分为训练样本和测试样本;训练模块,用于通过训练样本训练稠密连接网络,得到训练后的稠密连接网络;识别模块,用于将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络。
13.可选的,选择模块包括:选择单元,用于选择至少三类水声目标作为水声数据样本;分类单元,用于依据预设比例将水声数据样本进行分类,得到训练样本和测试样本。
14.可选的,该装置还包括:构建模块,用于构建稠密连接网络,其中,稠密连接网络包括:steam模块、密集连接模块、transition layer模块和分类模块。
15.进一步地,可选的,该装置还包括:参数确定模块,用于确定网络的超参数,其中,超参数包括损失函数,学习率、迭代次数及批大小;损失函数包括:交叉熵损失函数。
16.本发明实施例中,基于选择水声数据样本,并将水声数据样本分为训练样本和测试样本;通过训练样本训练稠密连接网络,得到训练后的稠密连接网络;将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络。也就是说,本发明实施例能够解决了水声样本不足的问题,从而避免复杂繁重的特征工程,并且极大地加强了特征重用,在一定程度上缓解了水声样本不足的技术效果。
附图说明
17.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
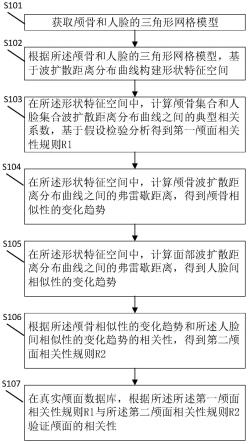
18.图1为本发明实施例提供的一种水声目标识别方法的流程示意图;
19.图2为本发明实施例提供的一种构建水声目标识别模型的方法中dense block结构的示意图;
20.图3为本发明实施例提供的一种构建水声目标识别模型的装置的示意图。
具体实施方式
21.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
22.需要说明的是,本发明的说明书和权利要求书及附图中的术语“第一”、“第二”等是用于区别不同对象,而不是用于限定特定顺序。
23.根据本发明实施例的一个方面,提供了一种构建水声目标识别模型的方法,图1为
本发明实施例提供的一种构建水声目标识别模型的方法的流程示意图。如图1所示,本技术实施例提供构建水声目标识别模型的方法包括:
24.步骤s102,选择水声数据样本,并将水声数据样本分为训练样本和测试样本;
25.可选的,步骤s102中选择水声数据样本,并将水声数据样本分为训练样本和测试样本包括:选择至少三类水声目标作为水声数据样本;依据预设比例将水声数据样本进行分类,得到训练样本和测试样本。
26.具体的,本技术实施例提供构建水声目标识别模型的方法采用的数据集为湖试数据集,该数据集是在丹江口湖上采集所得,湖试数据集共分为4类,是4种不同型号船只的辐射噪声,分别为铁皮船、曙航号、国泰号和新世纪号,利用两个8阵元线阵进行全天候数据采集。取每类目标的15个声音样本,每个样本时长为5s,对数据进行分帧后,随机选取其中的80%作为训练样本集,其余20%作为测试样本集。
27.可选的,本技术实施例提供构建水声目标识别模型的方法还包括:构建稠密连接网络,其中,稠密连接网络包括:steam模块、密集连接模块、transition layer模块和分类模块。
28.具体的,图2为本发明实施例提供的一种构建水声目标识别模型的方法中dense block结构的示意图,如图2所示,搭建densenet网络模型。densenet网络具体包含了steam模块、密集连接模块(dense block)、transition layer模块和分类模块(classification layer):
29.(1)确定steam模块的结构,steam模块放置在整个网络的最前面,由一个卷积层和一个最大池化层构成,卷积层卷积核大小为3*1,步长为2,最大池化层池的尺寸为3*1,步长为2,通过该steam模块,特征图减小为原来的1/4;
30.(2)确定dense block模块的结构。dense block模块是本发明网络的核心部分,其要点是采用了密集连接,即把前面所有层的特征图在channel维度上进行拼接并作为该层的输入,通过这种密集连接的方式,本网络能够大大增强特征重用,在水声样本不足的情况下完成水声目标识别任务。本发明采用的基础单元块由一个卷积核大小为1*1的卷积层和一个卷积核大小为3*1的卷积层相连所构成,然后把数量不等的基础单元块采用密集连接的方式进行连接构成一个dense block模块,第1、2、3、4个dense block模块分别包含6、12、24、16个基础单元块;
31.(3)确定transition layer模块的结构。transition layer模块由一个卷积层和一个平均池化层组成,卷积层卷积核大小为1*1,步长为1,平均池化层池的尺寸为2*1,步长为2,通过该transition layer模块特征图的尺寸减小为原来的一半,能够加快模型训练速度;
32.(4)把上面搭建的4个dense block模块和3个transition layer模块交替连接;
33.(5)确定classification layer模块的结构。classification layer模块由一个平均池化层和一个全连接层组成,平均池化层池的尺寸为7*1,步长为21,然后采用softmax函数实现水声目标分类。
34.进一步地,可选的,本技术实施例提供构建水声目标识别模型的方法还包括:确定网络的超参数,其中,超参数包括损失函数,学习率、迭代次数及批大小;损失函数包括:交叉熵损失函数。
35.具体的,本技术实施例提供构建水声目标识别模型的方法中损失函数选择交叉熵损失函数,学习率设置为0.0001,迭代次数为100,批大小为128。
36.步骤s104,通过训练样本训练稠密连接网络,得到训练后的稠密连接网络;
37.可选的,步骤s104中通过训练样本训练稠密连接网络,得到训练后的稠密连接网络包括:通过输入训练样本对稠密连接网络进行训练,得到训练样本对应的标签以及训练后的稠密连接网络。
38.具体的,将步骤s102中划分出的训练样本集作为densenet网络的输入,对应标签作为期望的输出,完成对网络模型的训练。
39.步骤s106,将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络。
40.可选的,步骤s106中将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络包括:将测试样本输入训练后的稠密连接网络对测试样本中的数据进行识别,得到识别结果;依据识别结果判定训练后的稠密连接网络是否收敛;在判定结果为是的情况下,得到收敛的稠密连接网络。
41.具体的,将步骤s102中划分出的测试样本集输入到训练好的densenet网络模型中,测试模型的稳健性。最终模型在测试样本集上的识别率达到了0.9352,超过了卷积神经网络的0.8523。
42.综上,结合步骤s102至步骤s106,在实际应用中,水声数据的获取较为困难,出于保密原因,也很少有人在网上公开发表获取到的水声数据集,因此水声目标数据比较稀少,而本技术实施例提供构建水声目标识别模型的方法中提出的模型利用密集连接结构,极大地加强了特征重用,有效地解决了水声样本少的问题。此外,在传统统计模型中,往往需要手动选择要提取什么样的特征,因此能否提取到高质量的特征直接影响了最终的识别结果,而本技术实施例提供构建水声目标识别模型的方法采用的是神经网络,摆脱了繁重的特征工程,模型可以根据输入波形主动去学习相应特征,完成水声目标识别任务。
43.本发明实施例中,基于选择水声数据样本,并将水声数据样本分为训练样本和测试样本;通过训练样本训练稠密连接网络,得到训练后的稠密连接网络;将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络。也就是说,本发明实施例能够解决了水声样本不足的问题,从而避免复杂繁重的特征工程,并且极大地加强了特征重用,在一定程度上缓解了水声样本不足的技术效果。
44.根据本发明实施例的另一个方面,提供了一种构建水声目标识别模型的装置,图3为本发明实施例提供的一种构建水声目标识别模型的装置的示意图,如图3所示,本技术实施例提供的构建水声目标识别模型的装置包括:选择模块32,用于选择水声数据样本,并将水声数据样本分为训练样本和测试样本;训练模块34,用于通过训练样本训练稠密连接网络,得到训练后的稠密连接网络;识别模块36,用于将测试样本输入训练后的稠密连接网络,得到收敛的稠密连接网络。
45.可选的,选择模块32包括:选择单元,用于选择至少三类水声目标作为水声数据样本;分类单元,用于依据预设比例将水声数据样本进行分类,得到训练样本和测试样本。
46.可选的,本技术实施例提供的构建水声目标识别模型的装置还包括:构建模块,用于构建稠密连接网络,其中,稠密连接网络包括:steam模块、密集连接模块、transition layer模块和分类模块。
47.进一步地,可选的,本技术实施例提供的构建水声目标识别模型的装置还包括:参数确定模块,用于确定网络的超参数,其中,超参数包括损失函数,学习率、迭代次数及批大小;损失函数包括:交叉熵损失函数。
48.以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。