一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法
技术领域
1.本发明涉及自然语言处理技术领域,是一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法。
背景技术:
2.随着互联网以及信息技术的迅猛发展,自媒体和电商平台的发展被迅速带动,人们日常社交生活的方方面面都充斥着网络服务,第446次《中国互联网络发展状况统计报告》显示,截至2020年6月,我国网民规模达9.40亿,较2020年3月增长3625万,互联网普及率达67.0%,较2020年3月提升2.5个百分点。随着互联网用户的增加和论坛、社交平台以及电商平台的壮大,各类网络平台也渗透进人们的生活中,用户在各类论坛和自媒体平台上发表言论和观点,在电商平台上发布已购商品的评价,如此一来便产生了海量的文本数据,呈现出几何式爆炸增长的态势,这些数据带有着用户的情感倾向和个人观点,是用户对于不同方面事物的评价,因此这些数据长短不一、种类复杂、结构混乱,表现为口语化、简单化、多元化的特点,因此通过人工是难以进行分类和组织的。由此可见,一个深层次的、自动的、精确的情感分析模型对于处理文本数据和分析用户情感取向有重大意义。
技术实现要素:
3.本发明为了能够取得更为理想的情感分析效果,本发明提供了一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法。本发明提供了以下技术方案:
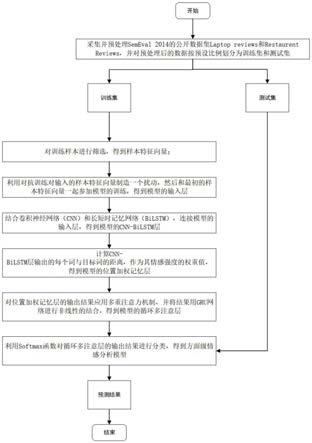
4.一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法,包括以下步骤:
5.步骤1:采集并预处理semeval 2014的公开数据集laptop reviews和restaurent reviews,并对预处理后的数据按预设比例划分为训练集和测试集;
6.步骤2:对训练样本进行筛选,得到样本特征向量;
7.步骤3:利用对抗训练对输入的样本特征向量制造一个扰动,与最初的样本特征向量一起参加模型的训练,得到模型的输入层;
8.步骤4:结合卷积神经网络和长短时记忆网络,连接模型的输入层,得到模型的cnn-bilstm层;
9.步骤5:计算cnn-bilstm层输出的每个词与目标词的距离,作为情感强度的权重值,得到模型的位置加权记忆层;
10.步骤6:对位置加权记忆层的输出结果应用多重注意力机制,并将结果用gru网络进行非线性的结合,得到模型的循环多注意层;
11.步骤7:利用softmax函数对循环多注意层的输出结果进行分类,得到方面级情感分析模型;
12.步骤8:将测试集输入方面级情感分析模型中,得到情感分析结果。
13.优选的,所述步骤2具体为:
14.对每个数据集中的训练样本进行筛选,只保留具有积极、消极和中性情感标签的数据,剩余的舍弃。
15.优选的,所述步骤3具体为:
16.步骤3.1:使用fgm方法进行对抗训练,表示为一个最小最大化公式为:
[0017][0018]
其中,x是输入的训练样本,y是训练样本的标签,θ是模型参数构成的集合,d为样本训练集,δ是对抗扰动,l为神经网络的损失函数;
[0019]
每一个文本中包含的t个词表示为:
[0020]
{w
(t)
|t=1,...,t}
[0021]
词向量矩阵表示为:
[0022]
v∈r
(k 1)
×d[0023]
其中,k为词汇表中词汇的数量,d表示词向量的维度。
[0024]
步骤3.2:将离散的向量输入转为连续的向量输入,通过下式表示:
[0025][0026][0027][0028]
扰动后的词向量嵌入层用正则化嵌入vk`来表示第i个单词的嵌入vk,fj表示第j个词汇的词频;
[0029]
步骤3.3:将vk`嵌入到扰动后的词向量嵌入层,词嵌入中添加扰动r
adv
,通过下式表示:
[0030][0031][0032]
其中,x为模型输入,为短文本分类器参数。
[0033]
优选的,所述步骤4具体为:
[0034]
步骤4.1:将输入层的输出作为cnn层的输入,词向量矩阵通过下式表示:
[0035]
v∈r
(k 1)
×d[0036]
其中,k为词汇表中的词汇的数量,d表示词向量的维度;
[0037]
步骤4.2:进行卷积操作,利用设置好的滤波器实现特征提取:
[0038]
si=f(ω
×
x
i:i g-1
b)
[0039]
其中,ω为卷积核,g为卷积核的尺寸,x
i:i g-1
表示从第i到第i g-1个词构成的句子向量矩阵,b是偏置向量;
[0040]
步骤4.3:经过卷积层,得到特征矩阵:
[0041]
s=[s1,s2,...s
n-g 1
]
[0042]
步骤4.4:经过池化层,进行下采样操作,利用最大池化技术maxpooling,求得局部最优解:
[0043]
m=max{s1,s2,...,s
n-g 1
}
[0044]
步骤4.5:通过全连接层将mi向量连接成向量q作为bilstm的输入:
[0045]
q={m1,m2,...,mn}
[0046]
步骤4.6:遗忘门f
t
、记忆门i
t
、输出门o
t
均由上一个时刻的隐藏状态h
t-1
和当前时刻的输入x
t
计算得到,具体表示过程:
[0047]ft
=logistic(wfx
t
ufh
t-1
bf)
[0048]it
=logistic(wix
t
u
iht-1
bi)
[0049][0050][0051]ot
=logistic(wox
t
u
oht-1
bo)
[0052]ht
=o
t
*tanh(c
t
)
[0053]
其中,wf、uf、wi、ui、wc、uc、wo、uo是权重矩阵;bf、bi、bc、bo是偏移量;tanh和logistic为激活函数,为临时记忆状态,c
t
为当前记忆状态,h
t
为当前隐藏状态。设在t时刻正向lstm输出的隐藏状态为反向lstm输出的隐藏状态为将bilstm输出的隐藏状态h表示为:
[0054][0055]
产生的向量矩阵为h
t*
:
[0056]ht*
={h
1*
,h
2*
,...,h
t*
,...,h
t*
}
[0057]
其中其中
[0058]
优选的,所述步骤5为计算句子中第m个词的权重值具体为:
[0059][0060]
其中,m
max
为输入句子的最大长度,句子中每个词语与目标词的相对偏移量为:
[0061][0062]
得到最终的位置加权记忆值为:
[0063]ht
={h1,h2,...,h
t
,...h
t
}
[0064]ht
=(α
t
·ht*
,β
t
)。
[0065]
优选的,所述步骤6具体为:
[0066]
步骤6.1:计算每一个输入的向量矩阵的注意力值,[,β
τ
]代表attention层输出的最后结果与评论目标实体有关:
[0067]gt
=w
t
(m
t
,e
t-1
[,β
τ
] b
t
),
[0068]
步骤6.2:将每一个输入的向量矩阵的注意力值标准化:
[0069][0070]
步骤6.3:在t时间,将上一时刻attention的结果x
t
和当前时刻的输入e
t-1
作为gru层的输入:
[0071][0072]
步骤6.4,gru层为:
[0073]zt
=σ(w
t
·
x
t
uz·et-1
),
[0074]rt
=σ(wr·
x
t
ur·et-1
),
[0075][0076][0077]
其中,h为gru隐藏层大小,l为lstm层数。
[0078]
优选的,所述步骤所述步骤7中通过softmax函数分类,使用的loss函数为:
[0079][0080]
其中,n为情感分析的类别集;d为训练样本的数据集;y为一个one-hot向量;f(x;θ)为模型的预测出来的情感分布,λ为正二化项的权重。
[0081]
优选的,所述步骤8为利用所述基于对抗训练和多注意力的cnn-bilstm方面情感分析模型进行验证,评估所述模型的性能。
[0082]
本发明具有以下有益效果:
[0083]
本发明充分发挥了cnn提取文本短语级特征的能力和bilstm提取文本全局结构信息的能力;引入多层注意力机制,用来捕获距离相对较远的情感特征,增强对不相关信息的鲁棒性,准确地提取出相关信息;增加经过扰动后的词向量嵌入层,以免造成过拟合而出现敌对样本,用于解决目前深度学习模型存在的模型不稳定问题,提高模型的稳定性,增强模型的泛化能力。
[0084]
针对传统深度学习算法中的循环神经网络出现的梯度爆炸和梯度消失的弊端,以及目前的神经网络深度学习模型存在不稳定的缺点,增加经过扰动后的词向量嵌入层,以免造成过拟合而出现敌对样本,用于解决目前深度学习模型存在的模型不稳定问题,提高模型的稳定性,增强模型的泛化能力。
[0085]
对于改进的双向循环神经网络不能聚焦文本的局部特征的缺点,以及卷积神经网络不能获取分类文本的全局特征的问题,结合双向循环神经网络和卷积神经网络,充分发挥cnn提取文本短语级特征的能力和bilstm提取文本全局结构信息的能力,达到了充分挖掘文本隐含的语义特征的目的,同时引入了多层注意力机制,用来捕获距离相对较远的情感特征,增强对不相关信息鲁棒性。
[0086]
另外,引入了位置加权记忆值的概念,句子中的某个词语距离目标词语越近,其对
分析整个句子的情感越重要,分配的权重值就越大,提高了模型的准确率。
附图说明
[0087]
图1是基于对抗训练和多注意力的cnn-bilstm方面情感分析方法的流程图;
[0088]
图2是与其他单一情感分析模型的准确率对比表;
[0089]
图3是与其他改进情感分析模型的准确率对比表。
具体实施方式
[0090]
以下结合具体实施例,对本发明进行了详细说明。
[0091]
具体实施例一:
[0092]
根据图1至图3所示,为解决上述技术问题采取的具体优化技术方案是:本发明涉及一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法:
[0093]
一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法,包括以下步骤:
[0094]
在步骤s1中,采集并预处理semeval 2014的公开数据集laptop reviews和restaurent reviews,并对预处理后的数据按预设比例划分为训练集和测试集。
[0095]
也就是说,对数据集进行处理,包括缺失值处理、异常值处理和归一化处理,并将处理后的数据集按7:3划分为训练集和测试集。
[0096]
在步骤s2中,对训练样本进行筛选,得到样本特征向量。
[0097]
具体地,对每个数据集中的训练样本进行筛选,只保留具有积极、消极和中性情感标签的数据,其他的舍弃。
[0098]
在步骤s3中,利用对抗训练对输入的样本特征向量制造一个扰动,然后和最初的样本特征向量一起参加模型的训练,得到模型的输入层。
[0099]
具体地,首先使用fgm方法进行对抗训练,可以表示为一个最小最大化公式为:
[0100][0101]
其中,x是输入的训练样本,y是训练样本的标签,θ是模型参数构成的集合,d为样本训练集,δ是对抗扰动,l为神经网络的损失函数;
[0102]
每一个文本中包含的t个词表示为:
[0103]
{w
(t)
|t=1,...,t}
[0104]
词向量矩阵表示为:
[0105]
v∈r
(k 1)
×d[0106]
其中k为词汇表中词汇的数量,d表示词向量的维度。
[0107]
然后将离散的向量输入转为连续的向量输入,如式所示
[0108][0109]
其中,
[0110]
[0111][0112]
扰动后的词向量嵌入层用正则化嵌入vk`来表示第i个单词的嵌入vk,fj表示第j个词汇的词频;
[0113]
最后将vk`嵌入到扰动后的词向量嵌入层,词嵌入中添加扰动r
adv
,如式所示
[0114][0115][0116]
其中,x为模型输入,为短文本分类器参数。
[0117]
在步骤s4中,首先将输入层的输出作为cnn层的输入,词向量矩阵表示为:
[0118]
v∈r
(k 1)
×d[0119]
其中,k为词汇表中的词汇的数量,d表示词向量的维度;
[0120]
进行卷积操作,利用设置好的滤波器实现特征提取:
[0121]
si=f(ω
×
x
i:i g-1
b)
[0122]
其中ω为卷积核,g为卷积核的尺寸,x
i:i g-1
表示从第i到第i g-1个词构成的句子向量矩阵,b是偏置向量;
[0123]
经过卷积层,得到特征矩阵:
[0124]
s=[s1,s2,...s
n-g 1
]
[0125]
经过池化层,进行下采样操作,利用最大池化技术maxpooling,求得局部最优解:
[0126]
m=max{s1,s2,...,s
n-g 1
}
[0127]
通过全连接层将mi向量连接成向量q作为bilstm的输入:
[0128]
q={m1,m2,...,mn}
[0129]
遗忘门f
t
、记忆门i
t
、输出门o
t
均由上一个时刻的隐藏状态h
t-1
和当前时刻的输入x
t
计算得到,具体表示过程:
[0130]ft
=logistic(wfx
t
ufh
t-1
bf)
[0131]it
=logistic(wix
t
u
iht-1
bi)
[0132][0133][0134]ot
=logistic(wox
t
u
oht-1
bo)
[0135]ht
=o
t
*tanh(c
t
)
[0136]
其中,wf、uf、wi、ui、wc、uc、wo、uo是权重矩阵;bf、bi、bc、bo是偏移量;tanh和logistic为激活函数,为临时记忆状态,c
t
为当前记忆状态,h
t
为当前隐藏状态。设在t时刻正向lstm输出的隐藏状态为反向lstm输出的隐藏状态为将bilstm输出的隐藏状态h表示为:
[0137][0138]
产生的向量矩阵为h
t*
:
[0139]ht*
={h
1*
,h
2*
,...,h
t*
,...,h
t*
}
[0140]
其中
[0141]
在步骤s5中,计算句子中第m个词的权重值:
[0142][0143]
其中m
max
为输入句子的最大长度,句子中每个词语与目标词的相对偏移量为:
[0144][0145]
得到最终的位置加权记忆值为:
[0146]ht
={h1,h2,...,h
t
,...h
t
}
[0147]ht
=(α
t
·ht*
,β
t
)
[0148]
在步骤s6中,计算每一个输入的向量矩阵的注意力值,[,β
τ
]代表attention层输出的最后结果与评论目标实体有关:
[0149]gt
=w
t
(m
t
,e
t-1
[,β
τ
] b
t
),
[0150]
将每一个输入的向量矩阵的注意力值标准化:
[0151][0152]
在t时间,将上一时刻attention的结果x
t
和当前时刻的输入e
t-1
作为gru层的输入:
[0153][0154]
gru具体实现为:
[0155]zt
=σ(w
t
·
x
t
uz·et-1
)
[0156]rt
=σ(wr·
x
t
ur·et-1
)
[0157][0158][0159]
其中h为gru隐藏层大小,l为lstm层数。
[0160]
在步骤s7中,通过softmax函数分类,使用的loss函数为:
[0161][0162]
其中,n为情感分析的类别集;d为训练样本的数据集;y为一个one-hot向量;f(x;θ)为模型的预测出来的情感分布,λ为正二化项的权重。
[0163]
在步骤s8中,利用所述基于对抗训练和多注意力的cnn-bilstm方面情感分析模型进行验证,评估所述模型的性能。
[0164]
另外,测试集还可验证模型分类性能,并根据acc值和macro-f1值来评估模型的情
感分析效果。
[0165]
具体地,下面通过一个具体实施例对本发明实施例提出的基于对抗训练和多注意力的cnn-bilstm方面情感分析方法的有效性进行验证。
[0166]
基于相同的网贷数据,与其他单一情感分析模型和改进情感分析模型进行比较分析。首先对数据进行预处理,并按照7:3的比例划分为训练集和测试集,使用向量化工具word2vec将两个数据集中的评论数据表示成向量矩阵的形式。使用单一的情感分析模型lstm、bilstm、cnn与本文提出的模型进行对照试验,实验结果如表1所示。从表1中的结果可以明显看出提出的方法在准确率和macro-f1方面都比单一的cnn、lstm和bi lstm模型要好,在分类准确率方面,数据集laptop reviews上分别比cnn、lstm和bi lstm模型分别要提高8个百分点、3个百分点和2个百分点,在数据集restaurent reviews上分别比cnn、lstm和bilstm模型分别要提高11个百分点、4个百分点和3个百分点。
[0167]
接下来本文使用改进后的情感分析模型cnn-bilstm、cnn-bilstm-attention、ram与本文提出的模型进行对照实,实验结果如表2所示。表2中的结果可以看出提出的方法在准确率和macro-f1方面都比已存在改进后的情感分析模型cnn-bilstm、cnn-bilstm-attention、ram要好,在分类准确率方面,在数据集laptop reviews上分别比cnn-bilstm、cnn-bilstm-attention和ram分别要提高1.5个百分点、1.3个百分点和1个百分点,在数据集restaurent reviews上分别比cnn-bilstm、cnn-bilstm-attention和ram模型分别要提高2.9个百分点、2.5个百分点和1.9个百分点。
[0168]
综上所述,根据本发明实施例提出的基于对抗训练和多注意力的cnn-bilstm方面情感分析方法,在模型中融入对抗训练,不但能防止过拟合产生敌对样本,还通过产生错误分类反攻模型使错误样本加入训练过程,使模型拥有鲁棒性和相对较好的泛化能力,还通过融合具有不同优势的神经网络达到充分挖掘文本隐含的语义特征的目的,同时引用多层注意力机制并使用gru进行非线性结合,可以实现捕获距离相对较远的情感特征。通过与其他情感分析方法进行对比,验证了本文提出的方法的有效性,提高了情感分析的准确率。
[0169]
以上所述仅是一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法的优选实施方式,一种基于对抗训练和多注意力的cnn-bilstm方面情感分析方法的保护范围并不仅局限于上述实施例,凡属于该思路下的技术方案均属于本发明的保护范围。应当指出,对于本领域的技术人员来说,在不脱离本发明原理前提下的若干改进和变化,这些改进和变化也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。