1.本发明属于信号处理技术领域,具体涉及一种基于神经网络的多通道语音增强方法及系统。
背景技术:
2.伴随着当今世界科学技术的快速发展,人工智能技术的引用日益成熟,语音作为人机交互的一部分,其地位显得更加重要。在日常的生活工作中,搭载语音处理系统的设备更是随处可见,例如会议系统、话务设备、无人车等设备。而将深度神经网络应用于语音增强技术中,借助神经网络结构的复杂非线性映射能力和学习表达能力,通过大量的实验数据,以频谱特征作为监督信息可以训练出具有良好效果的语音增强系统,提高了语音清晰度和可懂度。
3.传统的多通道增强方法有着扎实的数据理论支持,实现简单,但其算法效果依赖于场景假设、阵列空间信息以及参数估计等先验信息,在实际使用过程中往往不能准确得到结果,很多时候只能依靠估算,导致算法性能下降明显。
技术实现要素:
4.针对现有技术中的缺陷,本发明提供一种基于神经网络的多通道语音增强方法及系统,准确性高,不需要进行场景假设,不依赖阵列空间信息以及参数估计等先验信息。
5.第一方面,一种基于神经网络的多通道语音增强方法,包括:
6.接收多个通道的语音信号;
7.利用各个通道的滤波器对通道的语音信号进行处理,以得到各个通道对应角度的波束;
8.根据所有波束确定目标波束以及波达方向;
9.根据多个通道的语音信号和波达方向得到多个参考噪声;
10.将参考噪声和目标波束输入至自适应消噪层,对目标波束进行增强。
11.进一步地,利用各个通道的滤波器对通道的语音信号进行处理,以得到各个通道对应角度的波束具体包括:
12.选择一个通道作为参考通道;
13.在每个通道中,利用滤波器对语音信号进行卷积操作,以得到每个通道对应角度的波束。
14.进一步地,滤波器的优化方法包括:
15.分别计算每个通道得到的波束与参考通道得到的波束之间的余弦相似度,以得到每个通道的相似度;
16.将所有通道的相似度输入至全连接网络中,以得到第一输出数据;
17.对所有通道的滤波器进行仿射变换,以得到第二输出数据;
18.将第一输出数据和第二输出数据相加后,输入至映射函数中,以得到所有通道优
化后的滤波器。
19.进一步地,根据所有波束确定目标波束以及波达方向具体包括:
20.为每个通道的波束分配权重;
21.利用所有通道的权重对所有波束进行选择,以得到目标方向上的目标波束以及波达方向。
22.进一步地,权重的优化方法包括:
23.对所有通道的权重进行仿射变换,以得到第三输出数据;
24.将第一输出数据和第三输出数据相加后,输入至映射函数中,以得到所有通道优化后的权重。
25.进一步地,自适应消噪层包括编码器、1
×
1卷积层和解码器;
26.编码器用于对子帧进行处理,以得到第四输出,子帧由参考噪声划分得到;
[0027]1×
1卷积层用于对第四输出进行1
×
1卷积提取特征,以得到多个噪声特征;
[0028]
解码器用于利用噪声特征增强目标波束的幅度谱。
[0029]
第二方面,一种基于神经网络的多通道语音增强系统,包括:
[0030]
输入层:用于接收多个通道的语音信号;
[0031]
固定波束形成层:用于利用各个通道的滤波器对通道的语音信号进行处理,以得到各个通道对应角度的波束;
[0032]
波束方向选择单元:用于根据所有波束确定目标波束以及波达方向;
[0033]
噪声阻塞层:用于根据多个通道的语音信号和波达方向得到多个参考噪声;
[0034]
自适应消噪层:用于接收参考噪声和目标波束,输出目标波束的增强信号。
[0035]
进一步地,固定波束形成层具体用于:
[0036]
选择一个通道作为参考通道;
[0037]
在每个通道中,利用滤波器对语音信号进行卷积操作,以得到每个通道对应角度的波束。
[0038]
进一步地,波束方向选择单元具体用于:
[0039]
为每个通道的波束分配权重;
[0040]
利用所有通道的权重对所有波束进行选择,以得到目标方向上的目标波束以及波达方向。
[0041]
进一步地,自适应消噪层包括编码器、1
×
1卷积层和解码器;
[0042]
编码器用于对子帧进行处理,以得到第四输出,子帧由参考噪声划分得到;
[0043]1×
1卷积层用于对第四输出进行1
×
1卷积提取特征,以得到多个噪声特征;
[0044]
解码器用于利用噪声特征增强目标波束的幅度谱。
[0045]
由上述技术方案可知,本发明提供的多通道语音增强方法及系统,根据历史数据训练神经网络模型,利用训练好的神经网络模型对语音信号进行增强,准确性高,不需要进行场景假设,不依赖阵列空间信息以及参数估计等先验信息。
附图说明
[0046]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件
或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
[0047]
图1为实施例提供的多通道语音增强方法的流程图。
[0048]
图2为实施例提供的目标波束确定方法的流程图。
[0049]
图3为实施例提供的滤波器和权重优化方法的流程图。
[0050]
图4为实施例提供的多通道语音增强系统的模块框图。
具体实施方式
[0051]
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。需要注意的是,除非另有说明,本技术使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
[0052]
应当理解,当在本说明书和所附权利要求书中使用时,术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
[0053]
还应当理解,在此本发明说明书中所使用的术语仅仅是出于描述特定实施例的目的而并不意在限制本发明。如在本发明说明书和所附权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。
[0054]
如在本说明书和所附权利要求书中所使用的那样,术语“如果”可以依据上下文被解释为“当...时”或“一旦”或“响应于确定”或“响应于检测到”。类似地,短语“如果确定”或“如果检测到[所描述条件或事件]”可以依据上下文被解释为意指“一旦确定”或“响应于确定”或“一旦检测到[所描述条件或事件]”或“响应于检测到[所描述条件或事件]”。
[0055]
实施例:
[0056]
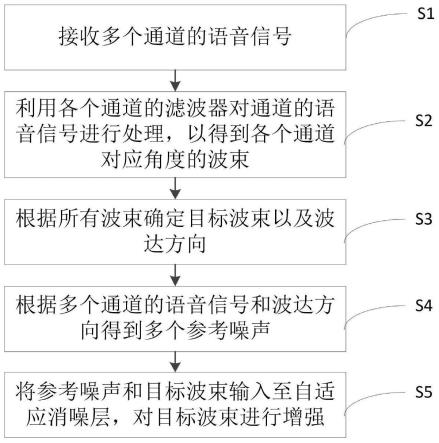
一种基于神经网络的多通道语音增强方法,参见图1,包括:
[0057]
s1:接收多个通道的语音信号;
[0058]
s2:利用各个通道的滤波器对通道的语音信号进行处理,以得到各个通道对应角度的波束;
[0059]
s3:根据所有波束确定目标波束以及波达方向;
[0060]
s4:根据多个通道的语音信号和波达方向得到多个参考噪声;
[0061]
s5:将参考噪声和目标波束输入至自适应消噪层,对目标波束进行增强。
[0062]
在本实施例中,语音信号可以为对原始语音信号进行短时傅里叶变换后得到的信号,原始语音信号可以包括通过麦克风阵列接收到的多通道(例如m个通道)、带有噪声的信号。不同通道的语音信号可以具有相同或不同的角度,该多通道语音增强方法在得到多通道的语音信号后,对语音信号进行处理,以得到各个通道对应角度下的波束,例如该方法对语音信号进行处理后,得到0度-180度下的频域波束特征。该方法在得到各个角度的波束时,对所有波束进行筛选,选出目标方向上的目标波束,其中目标波束可以根据设定好的方向或参数进行筛选。该方法还能得到目标波束的波达方向(doa)。
[0063]
在本实施例中,该方法还可以根据多个通道的语音信号和波达方向得到多个参考噪声,例如该方法可以得到m个通道的参考噪声。该方法最后将m个参考噪声和目标波束输入至自适应消噪层,自适应消噪层对目标波束进行增强。其中自适应消噪层可以由dnn声学
模型训练得到,该方法当得到目标波束的增强信号后,可以将增强信号再次输入至dnn声学模型中,优化dnn声学模型,从而实现自适应消噪层的优化。
[0064]
该多通道语音增强方法,根据历史数据训练神经网络模型,利用训练好的神经网络模型对语音信号进行增强,准确性高,不需要进行场景假设,不依赖阵列空间信息以及参数估计等先验信息。
[0065]
进一步地,在一些实施例中,参见图2,利用各个通道的滤波器对通道的语音信号进行处理,以得到各个通道对应角度的波束具体包括:
[0066]
s11:选择一个通道作为参考通道;
[0067]
s12:在每个通道中,利用滤波器对语音信号进行卷积操作,以得到每个通道对应角度的波束。
[0068]
在本实施例中,该方法可以定义上述m个通道中任何一个通道为参考通道,分别利用m个通道的滤波器对各自通道的语音信号进行卷积操作,例如在首次使用时,该方法可以对每个通道的滤波器进行初始化,以得到各个滤波器的初始值,这样在首次使用时,利用滤波器的初始值对语音信号进行卷积操作。而在后续使用过程中,该方法可以根据历史数据对滤波器的值进行优化,以得到各个滤波器的优化值,这样在后续使用过程中,利用滤波器的优化值对语音信号进行卷积操作,提高准确度。
[0069]
在本实施例中,例如将所有通道滤波器的集合表示为filter=[h0,h1,
···
,hm],其中filter为集合名称,hm为第m个通道的滤波器的值,接着该方法利用滤波器对语音信号进行卷积操作,以得到每个通道对应角度的波束其中ym为第m个通道得到的波束,为卷积运算,x为各个通道的语音信号的集合,x=[x0,x1,
···
,xm],xm为第m个通道的语音信号。
[0070]
进一步地,在一些实施例中,参见图3,滤波器的优化方法包括:
[0071]
s21:分别计算每个通道得到的波束与参考通道得到的波束之间的余弦相似度,以得到每个通道的相似度;
[0072]
s22:将所有通道的相似度输入至全连接网络中,以得到第一输出数据;
[0073]
s23:对所有通道的滤波器进行仿射变换,以得到第二输出数据;
[0074]
s24:将第一输出数据和第二输出数据相加后,输入至映射函数中,以得到所有通道优化后的滤波器。
[0075]
在本实施例中,该方法为了提高准确度,在使用过程中可以根据结果优化滤波器的值。该方法在进行滤波器优化时,首先分别计算每个通道得到的波束与参考通道得到的波束之间的余弦相似度,以得到每个通道的相似度,其中所有相似度的集合可以表示为sim=[sim0,sim1,
···
,simm],sim为集合名称,simm为第m个通道的相似度,simm=cos_sim(ym,ref_channel),ref_channel为参考通道得到的波束,cos_sim为余弦相似度函数。接着该方法将所有通道的相似度sim输入至全连接网络net中,以得到第一输出数据delta。接着对所有通道的滤波器进行仿射变换,以得到第二输出数据res1,将第一输出数据delta和第二输出数据res1相加后,输入至映射函数f(
·
)中,以得到所有通道优化后的滤波器,该方法当选用不同的映射函数f(
·
),就能得到不同的波束形成器,例如当选用的映射函数f(
·
)为softmax(
·
)函数时,得到波束形成器为fsb波束形成器,每个通道的滤波器系数之和为1。即表示为:
[0076]
delta=net(sim);
[0077]
res1=σ(filter);
[0078]
filter=f(res1 delta);
[0079]
在本实施例中,上述滤波器的优化方法能够在多次反复计算过程中,将各个通道的信号与参考通道的信号逐渐在时间上对齐,使用层叠结构来提高滤波器的稳定性,使得最终滤波器的值filter趋于稳定。滤波器的优化方法可以采用以下损失函数:loss=mse(sim,1),式中1表示目标是得到最高的余弦相似度。
[0080]
进一步地,在一些实施例中,参见图2,根据所有波束确定目标波束以及波达方向具体包括:
[0081]
s13:为每个通道的波束分配权重;
[0082]
s14:利用所有通道的权重对所有波束进行选择,以得到目标方向上的目标波束以及波达方向。
[0083]
在本实施例中,为了实现更好的增强效果,该方法在fsb波束形成器的基础上,可以使用额外的网络单独估计每个通道的权重,为每个通道分配不同的权重,利用所有通道的权重对所有波束进行选择,以得到目标方向上的目标波束以及波达方向。例如在首次使用时,该方法可以对每个通道的权重进行初始化,以得到各个权重的初始值,这样在首次使用时,利用权重的初始值对所有波束进行选择。而在后续使用过程中,该方法可以根据历史数据对权重的值进行优化,以得到各个权重的优化值,这样在后续使用过程中,利用权重的优化值对所有波束进行选择,提高准确度。
[0084]
进一步地,在一些实施例中,参见图3,权重的优化方法包括:
[0085]
s25:对所有通道的权重进行仿射变换,以得到第三输出数据;
[0086]
s26:将第一输出数据和第三输出数据相加后,输入至映射函数中,以得到所有通道优化后的权重。
[0087]
在本实施例中,权重的优化方法和滤波器的优化方法类似。该方法在进行权重的优化方法时,首先分别计算每个通道得到的波束与参考通道得到的波束之间的余弦相似度,以得到每个通道的相似度,接着该方法将所有通道的相似度sim输入至全连接网络net中,以得到第一输出数据delta。接着对所有通道的权重进行仿射变换,以得到第三输出数据res2,将第一输出数据delta和第三输出数据res2相加后,输入至映射函数f(
·
)中,以得到所有通道优化后的权重channel_weight,即表示为:
[0088]
delta=net(sim);
[0089]
res2=σ(filter);
[0090]
channel_weight=f(res2 delta);
[0091]
在本实施例中,权重的优化方法可以采用以下损失函数:式中表示滤波后的输出,而y表示目标波束的增强信号。
[0092]
进一步地,在一些实施例中,自适应消噪层包括编码器、1
×
1卷积层和解码器;
[0093]
编码器用于对子帧进行处理,以得到第四输出,子帧由参考噪声划分得到;
[0094]1×
1卷积层用于对第四输出进行1
×
1卷积提取特征,以得到多个噪声特征;
[0095]
解码器用于利用噪声特征增强目标波束的幅度谱。
[0096]
在本实施例中,自适应消噪层利用多通道之间的信息,在网络中加入1
×
1卷积层来融合通道之间的信息,并使用转置卷积进行上采样恢复纯净语音,有利于多通道语音的增强。自适应消噪层主要由一个编码器(encoder)、一个1
×
1卷积层(特征提取层)以及一个解码器(decoder)组成。自适应消噪层还可以加入远跳连接,使得解码器能够充分地利用编码器中的信息,同时也能提高网络的训练效率。
[0097]
在本实施例中,自适应消噪层首先将c个通道的参考噪声分为t个子帧,每一子帧的长度为f,然后送入编码器进行处理,对编码器的输出经过1
×
1卷积层提取特征,接着送入解码器中,编码器和解码器中对应的层可以使用远跳连接,这样就可以在通道纬度上将数据拼接起来,最后输出增强后的单通道纯净语音,即增强后的目标波束。
[0098]
在本实施例中,编码器和解码器可以由对应的多个block组成。该方法在将输入的数据经1
×
1卷积层融合通道特征后,再进行二维卷积。每次卷积后都使用elu激活函数来提供非线性,同时在二维卷积后使用groupnorm进行归一化操作。
[0099]
一种基于神经网络的多通道语音增强系统,参见图4,包括:
[0100]
输入层:用于接收多个通道的语音信号;
[0101]
固定波束形成层:用于利用各个通道的滤波器对通道的语音信号进行处理,以得到各个通道对应角度的波束;
[0102]
波束方向选择单元:用于根据所有波束确定目标波束以及波达方向;
[0103]
噪声阻塞层:用于根据多个通道的语音信号和波达方向得到多个参考噪声;
[0104]
自适应消噪层:用于接收参考噪声和目标波束,输出目标波束的增强信号。
[0105]
进一步地,在一些实施例中,固定波束形成层具体用于:
[0106]
选择一个通道作为参考通道;
[0107]
在每个通道中,利用滤波器对语音信号进行卷积操作,以得到每个通道对应角度的波束。
[0108]
进一步地,在一些实施例中,波束方向选择单元具体用于:
[0109]
为每个通道的波束分配权重;
[0110]
利用所有通道的权重对所有波束进行选择,以得到目标方向上的目标波束以及波达方向。
[0111]
进一步地,在一些实施例中,自适应消噪层包括编码器、1
×
1卷积层和解码器;
[0112]
编码器用于对子帧进行处理,以得到第四输出,子帧由参考噪声划分得到;
[0113]1×
1卷积层用于对第四输出进行1
×
1卷积提取特征,以得到多个噪声特征;
[0114]
解码器用于利用噪声特征增强目标波束的幅度谱。
[0115]
本发明实施例所提供的系统,为简要描述,实施例部分未提及之处,可参考前述实施例中相应内容。
[0116]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。