1.本发明涉及古籍文字识别技术领域,具体是指一种基于区块链的古籍文化素材提取工作量标定方法。
背景技术:
2.古籍作为人类文化遗产的重要组成部分,具有极高的学术研究和艺术欣赏价值。由于其珍奇、稀有的特点,古籍的上述价值无法在大范围内为公众所利用,即使在严格限定的范围内,古籍原件的安全性和可持续保藏性依然难以保障。对古籍文献的发掘和有效利用已成为各国数字化图书馆工程的主要目标之一。在古籍整理和数字化方面,缺乏一个完整的系统实现从原始古籍资源到现代化素材提取的过程。
技术实现要素:
3.本发明要解决古籍藏书数字化、数据化、知识化比例严重不足的问题,形成一个具有自主知识产权的古籍文化资源批量开发复用的古籍文化素材提取工作量标定方法。
4.为解决上述技术问题,本发明提供的技术方案为:
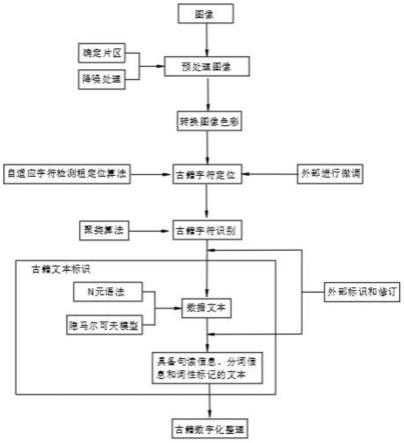
5.一种基于区块链的古籍文化素材提取工作量标定方法,包括图像、古籍字符定位、古籍字符识别、古籍文本标识和古籍数字化整理,所述的标定方法步骤如下:
6.s1、图像获取:通过外部摄像拍摄照片;
7.s2、预处理图像:对s1步骤中的照片进行预处理,并通过照片进行区域分割;
8.s3、转换图像色彩:对s2步骤中的照片的页面图像转换成黑白两色;
9.s4、古籍字符定位:通过自适应字符检测粗定位算法对照片进行字符定位,通过二值化、网格化和预处理技术进行粗划分,利用中文字符特征进行精细划分,实现海量数字化古籍对象的字符定位;
10.s5、古籍字符识别:通过聚类算法对近似字形进行自动化聚类,相似字形的字符被归为一类,得到一系列单字的大量字符的数据文本;
11.s6、古籍文本标识:通过n元语法和隐马尔可夫模型对数据文本进行自动分词,为文本提供句读和词性信息,得到具备句读信息、分词信息和词性标记的文本,
12.s7、古籍数字化整理:对文本的信息进行汇总和整理成的知识成果。
13.采用以上结构后,本发明具有如下优点:
14.将原始古籍资源系统化整合起来,并将其转化为数字资源,便于学者查询,并且可以在此基础上进行素材提取。本系统加快了古籍数字化进程、利用人在回路提高了古籍字符的识别准确率。
15.作为改进,所述的s4步骤中的字符定位可在页面显示定位结果,用户可对结果进行微调,使定位更准确。
16.作为改进,所述的s5步骤中的古籍字符识别的数据文本,允许专家和大众对聚类整体进行标识,对聚类错误的字符图像进行纠错标。
17.作为改进,所述的s6步骤中的古籍文本标识允许专家和大众对算法分词结果进行修订,对文本添加人名、地名和做标记。
18.作为改进,所述的s7步骤中的古籍数字化整理展示各个古籍的数字化进度,方便用户对古籍进行检索查询,数字化进度以百分比的形式呈现。
附图说明
19.图1是本发明的流程图。
20.图2是本发明古籍数字化整理的展示截面。
21.图3是本发明实施例一的示意图。
具体实施方式
22.下面结合全文对本发明做进一步的详细说明。
23.结合附图1-图3,一种基于区块链的古籍文化素材提取工作量标定方法,包括图像、古籍字符定位、古籍字符识别、古籍文本标识和古籍数字化整理,所述的标定方法步骤如下:
24.s1、图像获取:通过外部摄像拍摄照片;
25.s2、预处理图像:对s1步骤中的照片进行预处理,并通过照片进行区域分割,通过区域分割把没有古籍字符的区域进行预处理进行分割去除;
26.s3、转换图像色彩:对s2步骤中的照片的页面图像转换成黑白两色,可采用rgb图像向灰度图像转换、直接提取亮度信号和自编码器,自编码器为限制潜在空间的维度或具有比输入数据(x)更小的维度,是通过最小化损失函数l(x,g(f(x)))来学习,其中l是一个损失函数,它会因为和x不一致而惩罚g(f(x))。g(f(x))是自编码器的编码和解码过程(也就是自编码器的输出),损失函数是个均方差函数,x就是彩色图像。g(f(x))是重建后的黑白图像。损失函数会因为自编码器未能重建出彩图的黑白版而对其作出惩罚。
27.s4、古籍字符定位:通过自适应字符检测粗定位算法对照片进行字符定位,通过二值化、网格化和预处理技术进行粗划分,利用中文字符特征进行精细划分,实现海量数字化古籍对象的字符定位,页面显示定位结果,用户可对结果进行微调,使定位更准确。
28.s5、古籍字符识别:通过聚类算法对近似字形进行自动化聚类,相似字形的字符被归为一类,得到一系列单字的大量字符的数据文本,字符定位可在页面显示定位结果,用户可对结果进行微调,使定位更准确;
29.s6、古籍文本标识:通过n元语法和隐马尔可夫模型对数据文本进行自动分词,为文本提供句读和词性信息,得到具备句读信息、分词信息和词性标记的文本,古籍文本标识允许专家和大众对算法分词结果进行修订,对文本添加人名、地名和做标记;
30.s7、古籍数字化整理:对文本的信息进行汇总和整理成的知识成果,古籍数字化整理展示各个古籍的数字化进度,方便用户对古籍进行检索查询,数字化进度以百分比的形式呈现。
31.所述的s4步骤中的字符定位可在页面显示定位结果,用户可对结果进行微调,使定位更准确。
32.所述的s5步骤中的古籍字符识别的数据文本,允许专家和大众对聚类整体进行标
识,对聚类错误的字符图像进行纠错标。
33.所述的s6步骤中的古籍文本标识允许专家和大众对算法分词结果进行修订,对文本添加人名、地名和做标记。
34.所述的s7步骤中的古籍数字化整理展示各个古籍的数字化进度,方便用户对古籍进行检索查询,检索查询可通过书号、部/类/属/目分类、书名、著者时代或著者姓名进行查询,数字化进度以百分比的形式呈现,如图2所示。
35.实施例一:
36.古籍文化素材提取工作量标定方法步骤如下:
37.s1、图像获取:通过外部摄像拍摄照片,如图3所示的第一张图片,拍摄的为古籍的照片;
38.s2、预处理图像:对s1步骤中的照片进行预处理,并通过照片进行区域分割,通过区域分割把没有古籍字符的区域进行预处理进行分割去除;
39.s3、转换图像色彩:对s2步骤中的照片的页面图像转换成黑白两色,可采用rgb图像向灰度图像转换、直接提取亮度信号和自编码器把图像色彩改变,如图3所示的第二张图片所示;
40.s4、古籍字符定位:通过自适应字符检测粗定位算法对照片进行字符定位,通过二值化、网格化和预处理技术进行粗划分,利用中文字符特征进行精细划分,实现海量数字化古籍对象的字符定位,把图片内容中的中文字符进行分割划分操作,按照原文中的文字顺序(从右至左)将分割后的单个字符图片进行保存;页面显示定位结果,用户可对结果进行微调,使定位更准确,如图3所示的第三张图片所示;
41.s5、古籍字符识别:通过聚类算法对近似字形进行自动化聚类,相似字形的字符被归为一类,得到一系列单字的大量字符的数据文本,字符定位可在页面显示定位结果,如图3所示的第四张图片所示,用户可对结果进行微调,使定位更准确;
42.s6、古籍文本标识:通过无监督、无词典的n元语法和隐马尔可夫模型对数据文本进行自动分词,为文本提供句读和词性信息,得到具备句读信息、分词信息和词性标记的文本,如图3所示的最后一张图片所示,古籍文本标识允许专家和大众对算法分词结果进行修订,对文本添加人名、地名和做标记;
43.s7、古籍数字化整理:对文本的信息进行汇总和整理成的知识成果,古籍数字化整理展示各个古籍的数字化进度,方便用户对古籍进行检索查询,数字化进度以百分比的形式呈现,如图2所示。
44.将原始古籍资源系统化整合起来,并将其转化为数字资源,便于学者查询,并且可以在此基础上进行素材提取。本系统加快了古籍数字化进程、利用人在回路提高了古籍字符的识别准确率。
45.以上对本发明及其实施方式进行了描述,这种描述没有限制性,全文中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。