1.本发明涉及道路地图数据获取技术领域,尤其涉及一种基于轨迹密度匀化和层次分割的道路交叉口信息提取方法。
背景技术:
2.道路地图是导航位置服务、智慧交通管理和全息位置地图的重要数据资源,而交叉口具有复杂的空间结构和通行规则,是保证整个道路交通网络安全有效运行的核心部分。因此,维护道路交叉口信息的现势性和完整性是城市道路地图生产和更新的关键环节。传统的道路地图数据获取方法,如移动测量方法、遥感观测手段等,存在更新周期长、数据获取成本高、地物遮挡处理困难等问题。
3.在
″
人人都是传感器
″
的泛在测绘模式下,众源车辆轨迹数据提供了一种持续动态、覆盖面广、成本更低的地图生产方式,但众源轨迹对道路环境的信息感知会存在一定有偏性,这是由于:一是受车载gnss设备精度的限制,不同车辆轨迹的位置精度和采样间隔不同,因而会存在时空异质性问题;二是受道路本身交通流量不均衡的影响,不同等级道路上采集的轨迹疏密不均匀,往往表现为主干道上轨迹分布密集而次干道或郊区道路上轨迹稀疏甚至缺失。因此,现有技术中交叉口提取方法会受众源轨迹数据获取方式多样和道路交通流量不均衡等的影响,在正确检测交叉口目标,精细提取交叉口结构和轨迹数据处理效率等方面尚存在一定的改进空间。
技术实现要素:
4.本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种实现方法简单、成本低、精度以及效率高的基于轨迹密度匀化和层次分割的道路交叉口信息提取方法。
5.为解决上述技术问题,本发明提出的技术方案为:
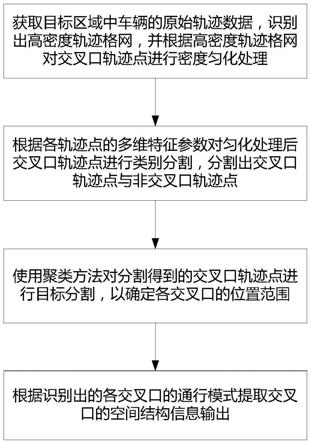
6.一种基于轨迹密度匀化和层次分割的道路交叉口信息提取方法,步骤包括:
7.s01.轨迹密度匀化:获取目标区域中车辆的原始轨迹数据,识别出轨迹点密度超过预设阈值的高密度轨迹格网,并根据所述高密度轨迹格网对交叉口轨迹点进行密度匀化处理;
8.s02.类别分割:根据各轨迹点的多维特征参数对步骤s01匀化处理后交叉口轨迹点进行类别分割,分割出交叉口轨迹点与非交叉口轨迹点;
9.s03.目标分割:使用聚类方法对步骤s02分割得到的交叉口轨迹点进行目标分割,以确定各交叉口的位置范围;
10.s04.通行模式分割:根据各轨迹点的起点航向与终点航向信息,对步骤s03目标分割后交叉口轨迹点进行通行模式分割,识别出各交叉口的通行模式;
11.s05.信息提取:根据步骤s04识别出的各交叉口的通行模式提取交叉口的空间结构信息输出。
12.进一步的,所述步骤s01包括:
13.s101.高密度轨迹格网识别:将目标区域划分为若干格网单元,统计落在每一个格网中的轨迹点数目占总轨迹点数的比值,根据统计的所述比值识别出所述高密度轨迹格网;
14.s102.邻域圆计算:以所述高密度轨迹格网的几何中心为圆心,构建邻域搜索圆,并统计落在所述邻域搜索圆内的轨迹点数目,计算出所述高密度轨迹格网的邻域圆;
15.s103.密度匀化处理:判断各轨迹与所述邻域圆之间的位置关系,根据位置关系进行交叉口轨迹点密度匀化处理。
16.进一步的,所述步骤s103中进行密度匀化处理时,保留整条轨迹均未落在所述高密度轨迹格网的所述邻域圆内,删除落入所述高密度轨迹格网的所述邻域圆的部分轨迹段、保留其他未落入所述邻域圆的轨迹段。
17.进一步的,所述步骤s02中,分别比较各轨迹点的速度变化量、航向变化量以及转弯距离比与对应预设阈值之间大小关系,若存在目标轨迹点的所述速度变化量、航向变化量以及转弯距离比均大于预设阈值,则将目标轨迹点作为候选交叉口轨迹点。
18.进一步的,所述步骤s03中,采用dbscan聚类算法对分割得到的交叉口轨迹点进行目标分割,将聚类得到的聚类中心到簇内各个轨迹点的最大距离为半径做外接圆,选择落入所述外接圆内所有轨迹段作为目标分割结果输出。
19.进一步的,所述采用dbscan聚类算法对分割得到的交叉口轨迹点进行目标分割的步骤包括:
20.s301.计算每个交叉口轨迹点的邻域点集,并选择邻域点集中点数大于预设最小包含点数minpts的轨迹点为核心种子点;
21.s302.获取一个所述核心种子点作为当前核心种子点,建立初始簇,选择当前核心种子点的邻域点集,将所述邻域点集内交叉口轨迹点添加至所述初始簇;
22.s303.循环遍历当前簇中所有核心种子点,寻找与所述核心种子点密度相连的交叉口轨迹点并添加至同一簇中,直到没有密度相连的交叉口轨迹点被添加至当前簇中;
23.s304.遍历下一个未处理的核心种子点,重复执行步骤s302、s303,直到所有核心种子点完成处理,得到聚类中心,转入步骤s305;
24.s305.以得到的所述聚类中心到簇内各个轨迹点的最大距离为半径做外接圆,选择落入该外接圆内所有轨迹段作为目标分割结果输出。
25.进一步的,所述步骤s04包括:
26.s401.预先对隶属于同一交叉口的各轨迹段的起、终点航向进行编码;
27.s402.统计隶属于航向编码矩阵中各元素的轨迹段数量占目标交叉口总轨迹数量的比例,选择所述比例高于给定阈值的目标元素作为目标交叉口的通行模式。
28.进一步的,所述步骤s05中,使用分段轨迹迭代连接方法,分段迭代求解各交叉口的每一组通行模式轨迹段簇的中心线,提取得到交叉口轨迹的空间结构信息。
29.进一步的,所述使用分段轨迹迭代连接方法,分段迭代求解各交叉口的每一组通行模式轨迹段簇的中心线,提取得到交叉口轨迹的空间结构信息的步骤包括:
30.s501.选择待处理通行模式轨迹段簇中最长的一条轨迹段作为初始中心线;
31.s502.以当前中心线的各顶点t1...tm为圆心,以|t1t2|...|t
m-1
tm|,|tmt
m-1
|为半径
分别构建缓冲区g1...gm;
32.s503.统计落在各缓冲区g1...gm内的轨迹点,并分别计算各轨迹点的平均几何中心以更新当前中心线的各顶点;
33.s504.重复步骤s502和s503,直到两次迭代前后拟合的中心线之间距离小于给定阈值,提取得到交叉口轨迹的空间结构信息输出。
34.一种计算机装置,包括处理器以及存储器,所述存储器用于存储计算机程序,所述处理器用于执行所述计算机程序,所述处理器用于执行所述计算机程序以执行如上述方法。
35.与现有技术相比,本发明的优点在于:
36.1、本发明通过首先对原始轨迹数据进行自适应密度匀化处理,之后结合多维特征对轨迹点进行类别分割,再利用聚类方法对识别出的交叉口轨迹进行目标分割,然后通过轨迹起始点航向信息进行交叉口内部通行模式分割,最后根据识别出的通行模式提取出交叉口空间结构信息,能够结合轨迹密度匀化处理与三层次的分割实现交叉口空间结构的高效提取。
37.2、本发明基于轨迹密度匀化和多层次分割实现道路交叉口信息提取,对于采样频率低、密度分布不均匀的众源轨迹数据,依然能够获得较高的正确率和召回率,还能够有效减少如停车场、加油站、小区等不规则转弯轨迹的误识别。
38.3、本发明通过对原始轨迹数据进行高密度格网识别和轨迹密度匀化处理,能够有效降低直接处理原始轨迹数据的时间消耗,同时又能够一定程度避免密度分布不均引起的交叉口误识别和漏识别。
39.4、本发明通过采用类别层次、目标层次和通行模式三个层次的轨迹层次分割策略,能够由粗到细地识别道路交叉口的位置、范围和内部结构,尤其适用于形态各异、结构复杂的各类道路交叉口识别。
附图说明
40.图1是本发明实施例基于轨迹密度匀化和层次分割的道路交叉口信息提取方法的实现流程示意图。
41.图2是本发明实施例的轨迹点转弯距离比计算示意图。
42.图3是本发明实施例的基于速度变化、方向变化和转弯距离比的交叉口轨迹点识别示意图。
43.图4是本发明实施例的轨迹点航向的八方向蜘蛛编码示意图。
44.图5是本发明实施例的基于起终点航向编码的交叉口通行模式分割示意图。
45.图6是本发明实施例的道路交叉口空间结构提取示意图。
46.图7是本发明实施例的不经过/经过轨迹密度匀化处理的道路交叉口识别结果对比图。
47.图8是本发明实施例的道路交叉口通行模式识别与结构提取结果示意图。
具体实施方式
48.以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而
限制本发明的保护范围。
49.如图1所示,本实施例基于轨迹密度匀化和层次分割的道路交叉口信息提取方法的步骤包括:
50.s01.轨迹密度匀化:获取目标区域中车辆的原始轨迹数据,识别出轨迹点密度超过预设阈值的高密度轨迹格网,并根据高密度轨迹格网对交叉口轨迹点进行密度匀化处理;
51.s02.类别分割:根据各轨迹点的多维特征参数对步骤s01匀化处理后交叉口轨迹点进行类别分割,分割出交叉口轨迹点与非交叉口轨迹点;
52.s03.目标分割:使用聚类方法对步骤s02分割得到的交叉口轨迹点进行目标分割,以确定各交叉口的位置范围;
53.s04.通行模式分割:根据各轨迹点的起点航向与终点航向信息,对步骤s03目标分割后交叉口轨迹点进行通行模式分割,识别出各交叉口的通行模式。
54.s05.信息提取:根据步骤s04识别出的各交叉口的通行模式提取交叉口的空间结构信息输出,上述空间结构也即为交叉口的骨架结构。
55.本实施例通过首先对原始轨迹数据进行自适应密度匀化处理,之后结合多维特征对轨迹点进行类别分割,然后利用聚类方法对识别出的交叉口轨迹进行目标分割,再通过轨迹起始点航向信息进行交叉口内部通行模式分割,最后根据识别出的通行模式提取出交叉口空间结构信息,能够结合轨迹密度匀化处理与三层次的分割(即类别分割、目标分割、通行模式分割)实现交叉口空间结构的高效提取,尤其对采样频率低、密度分布不均匀的众源轨迹数据,可以提高交叉口提取正确率和召回率,有效减少误识别,解决众源轨迹数据存在时空异质性和密度分布不均等问题。
56.本实施例步骤s01具体通过识别高密度轨迹格网,计算高密度轨迹格网的邻域圆,基于邻域圆筛选所有轨迹点,实现对交叉口轨迹点进行密度匀化处理,步骤具体包括:
57.s101.高密度轨迹格网识别:将目标区域划分为若干格网单元,统计落在每一个格网中的轨迹点数目占总轨迹点数的比值,根据统计的比值识别出高密度轨迹格网;
58.s102.邻域圆计算:以高密度轨迹格网的几何中心为圆心,构建邻域搜索圆,并统计落在邻域搜索圆内的轨迹点数目,计算出高密度轨迹格网的邻域圆;
59.s103.密度匀化处理:判断各轨迹与邻域圆之间的位置关系,根据位置关系进行交叉口轨迹点密度匀化处理。
60.上述步骤s103中进行密度匀化处理时,具体保留整条轨迹均未落在高密度轨迹格网的邻域圆内,删除落入高密度轨迹格网的邻域圆的部分轨迹段、保留其他未落入邻域圆的轨迹段,实现轨迹密度匀化处理,能够克服车流不均引起的道路感知有偏性问题,有效降低了直接处理原始轨迹数据的时间消耗,同时又一定程度避免了密度分布不均引起的交叉口误识别和漏识别,从而提高交叉口轨迹识别精度,减少误识别。
61.在具体应用实施例中,先按照固定格网大小将目标区域划分为若干格网单元,统计落在每一个格网中的轨迹点数目占目标区域总轨迹点数的比值,识别出高密度轨迹格网;然后以高密度格网的几何中心为圆心,确定初始半径与增长步长,依次构建邻域搜索圆,统计落在邻域搜索圆内的轨迹点数目,当增长前后邻域圆内轨迹点数目比值大于给定阈值且位于局部峰值时邻域搜索结束,定义此时的邻域搜索圆为该高密度格网的邻域圆,
计算高密度轨迹格网的邻域圆;然后保留整条轨迹均未落在高密度轨迹格网的邻域圆内的轨迹,舍去部分轨迹段落入高密度轨迹格网的邻域圆的轨迹段、保留其他轨迹段,完成交叉口轨迹点密度匀化处理。
62.本实施例步骤s02将轨迹类别分割作为交叉口轨迹层次分割的第一层次分割,以区分出交叉口轨迹与非交叉口轨迹,轨迹类别分割时通过结合多维特征参数的判断实现。多维特征参数具体包括车辆轨迹点间速度变化量δvi、方向变化量δθi以及转弯距离比δri等,其中轨迹点间速度变化量δvi即为当前轨迹点与前一轨迹点的速度差绝对值,轨迹点间的方向变化量δθi即为当前轨迹点与前一轨迹点航向差绝对值,转弯距离比δri具体为采用基于弯曲深度二叉树分割的轨迹点转弯距离比,即对轨迹段进行的弯曲深度二叉树分割。如图2所示,记录各轨迹点的转弯距离hi与所在弯曲段的基线长度bendi,如轨迹点p2所在弯曲段的基线长度bend2=|p1p
10
|,转弯距离h2等于轨迹点p2到基线p1p
10
的垂直距离。轨迹类别分割时,分别比较各轨迹点的速度变化量、航向变化量以及转弯距离比与对应预设阈值之间大小关系,若存在目标轨迹点的速度变化量、航向变化量以及转弯距离比均大于预设阈值,则将目标轨迹点作为候选交叉口轨迹点,从而综合轨迹点的多维特征参数区别出交叉口轨迹与非交叉口轨迹,对匀化处理后的交叉口轨迹点实现类别分割。
63.在具体应用实施例中,分别使用基于速度变化量δvi、方向变化量δθi以及转弯距离比δri得到的交叉口轨迹点识别结果如图3所示,由图3可知,转弯距离比可有效区分局部不规则的转弯轨迹和实际交叉口的规则转弯轨迹,则综合速度变化量δvi、方向变化量δθi以及转弯距离比δri能够有效提高交叉口轨迹点的识别精度。
64.本实施例在完成第一层次分割(类别分割)后,步骤s03对类别分割得到的交叉口轨迹进行第二层次分割,即轨迹目标分割,通过轨迹目标分割确定各轨迹点簇对应的交叉口目标范围。本实施例步骤s03中具体利用dbscan(density-based spatial clustering of applications with noise,具有噪声的基于密度的聚类方法)聚类算法对分割处理后的交叉口轨迹点进行目标分割,将聚类得到的聚类中心到簇内各个轨迹点的最大距离为半径做外接圆,选择落入外接圆内所有轨迹段作为目标分割结果输出,以作为后续交叉口通行模式分割的输入。算法使用前需预设算法参数:领域半径eps与最小包含点数minpts。利用聚类算法可以将密度相连的轨迹点划分为一类,从而有效划分出属于各交叉口的轨迹点。
65.本实施例中,采用dbscan聚类算法对分割得到的交叉口轨迹点进行目标分割的步骤具体包括:
66.s301.计算每个交叉口轨迹点的邻域点集neps(pi)={pj|dis(pi,pj)≤eps},并选择邻域点数大于预设最小包含点数minpts(|neps(pi)|≥minpts)的轨迹点为核心种子点;
67.s302.获取一个核心种子点作为当前核心种子点,建立初始簇,选择当前核心种子点的邻域点集,将邻域点集内交叉口轨迹点添加至初始簇;
68.s303.循环遍历当前簇中所有核心种子点,寻找与核心种子点密度相连的交叉口轨迹点并添加至同一簇中,直到没有密度相连的交叉口轨迹点被添加至当前簇中;
69.s304.遍历下一个未处理的核心种子点,重复执行步骤s302、s303,直到所有核心种子点完成处理,得到聚类中心,转入步骤s305;
70.s305.以得到的聚类中心到簇内各个轨迹点的最大距离为半径做外接圆,选择落
入该外接圆内所有轨迹段作为目标分割结果输出。
71.本实施例步骤s04对第二层次分割(目标分割)得到的结果进行交叉口轨迹层次分割的第三层次分割(通行模式分割),可得到交叉口内部通行规则。通行模式分割利用轨迹点起点航向与终点航向信息,对目标分割处理后的交叉口轨迹点进行内部通行模式分割,具体步骤包括:
72.s401.预先对隶属于同一交叉口的各轨迹段的起、终点航向进行编码;
73.s402.统计隶属于航向编码矩阵中各元素的轨迹段数量占目标交叉口总轨迹数量的比例,选择比例高于给定阈值的目标元素作为目标交叉口的通行模式。
74.相比于起、终点角度差和中间轨迹点平均角度,轨迹起点航向和终点航向能够更为准确的描述交叉口轨迹特征,本实施例利用各轨迹段的起、终点航向进行交叉口的通行模式分割,能够确保通行模式识别的精度。
75.如图4所示,本实施例具体对隶属于同一交叉口的各轨迹段的起、终点航向进行八方向蜘蛛编码(a~h),两个方向之间相差45度,如航向角介于[337.5
°
,360
°
]∪[0
°
,22.5
°
),则编码为h;如航向角介于[22.5
°
,67.5
°
),则编码为a,则基于起、终点航向编码可以将各轨迹段划分为64种可能通行模式,得到交叉口轨迹段起终点航向编码矩阵如图5(a)所示,每种模式分别对应了图5(a)中起终点航向编码矩阵的一个元素,其中圆形符号大小代表该交叉口轨迹簇中隶属于各元素的轨迹段比例,统计隶属于航向编码矩阵中各元素的轨迹段数量占该交叉口总轨迹数量的比例,选择比例高于给定阈值的元素,即作为该交叉口的典型通行模式,图5-(a)中矩形框表示最终识别的通行模式,图5-(b)列举了其中4个典型通行模式。
[0076]
本实施例步骤s05中具体使用分段轨迹迭代连接方法,分段迭代求解各交叉口的每一组通行模式轨迹段簇的中心线,提取得到交叉口轨迹的空间结构信息,详细步骤包括:
[0077]
s501.选择待处理通行模式轨迹段簇中最长的一条轨迹段作为初始中心线;
[0078]
s502.以当前中心线的各顶点t1...tm为圆心,以|t1t2|...|t
m-1
tm|,|tmt
m-1
|为半径分别构建缓冲区g1...gm;
[0079]
s503.统计落在各缓冲区g1...gm内的轨迹点,并分别计算各轨迹点的平均几何中心以更新当前中心线的各顶点;
[0080]
s504.重复步骤s502和s503,直到两次迭代前后拟合的中心线之间距离小于给定阈值,提取得到交叉口轨迹的空间结构信息输出。
[0081]
在具体应用实施例中采用上述方法提取到的道路交叉口空间结构结果如图6所示。
[0082]
本实施例上述步骤可以通过计算机软件编程实现,包括交叉口轨迹密度匀化、层次分割以及空间结构提取过程等,具体可以使用matlab软件实现,同时使用arcgis软件实现提取结果的可视化。
[0083]
本发明针对不同道路获取的轨迹数据密度不均匀问题,通过对原始轨迹数据进行自适应密度匀化处理的办法,既保证使用的轨迹数据对道路网的均匀采样,又减少对所有轨迹进行处理的复杂计算,从而有效降低了直接处理原始轨迹数据的时间消耗,同时又一定程度避免了密度分布不均引起的交叉口误识别和漏识别。同时采用类别层次、目标层次和通行模式三个层次的轨迹层次分割策略,由粗到细地识别道路交叉口的位置、范围和内
部结构,使得对于采样频率低、密度分布不均匀的众源轨迹数据,能够获得较高的正确率和召回率,特别是能够有效减少停车场、加油站、小区等不规则转弯轨迹的误识别,以利于维护道路交叉口信息的现势性和完整性。进一步针对不同车辆轨迹数据的时空异质性问题,本发明通过充分利用车辆轨迹的方向、速度、转弯距离比等多维特征对车辆轨迹进行类别层次和目标层次轨迹分割,最后结合起始航向编码和分段轨迹迭代连接方法建立各道路交叉口的精细结构层次表达,能够精准、高效的提取态各异结构复杂的道路交叉口空间结构。
[0084]
以下以在具体应用实施例中采用本发明上述方法实现道路交叉口空间结构信息提取为例,对本发明进行进一步说明。
[0085]
本实施例实现道路交叉口空间结构信息提取的详细步骤为:
[0086]
步骤1:轨迹密度匀化
[0087]
步骤1.1,识别高密度轨迹格网
[0088]
按照固定格网大小(w,h)将目标区域划分为若干格网单元,格网宽度w和高度h的设置具体按照公式(1)计算得到,其中dxi,dyi分别为相邻轨迹点的坐标差,k为密度参数,本实施例设k=1000,统计落在每一个格网中的轨迹点数目占实验区总轨迹点数的比值,若该比值大于给定阈值n
grid
,则该格网被标记为高密度轨迹格网。
[0089][0090]
步骤1.2,计算高密度轨迹格网的邻域圆
[0091]
以高密度格网的几何中心gi为圆心、10米为初始半径、1米为增长步长,依次构建邻域搜索圆,统计落在邻域搜索圆内的轨迹点数目,当增长前后邻域圆内轨迹点数目比值大于给定阈值n
circle
且位于局部峰值时邻域搜索结束,定义此时的邻域搜索圆(gi,ri)为该高密度格网的邻域圆,同理确定其他所有高密度格网的邻域圆。
[0092]
步骤1.3,轨迹密度匀化处理
[0093]
为尽可能保留原始轨迹数据记录的道路变化信息,选择从原始1个月的轨迹数据中每隔2天选择次日的实验轨迹数据保留,如第1天、第4天、第7天等,共计10天,再逐一遍历剩余轨迹,若整条轨迹均未落在高密度轨迹格网的邻域圆内,则保留其整条轨迹;若有部分轨迹段落入高密度轨迹格网的邻域圆,则舍去落入高密度轨迹格网邻域圆内的轨迹段,保留其他轨迹段。
[0094]
步骤2:轨迹类别分割
[0095]
对步骤1轨迹密度匀化处理后的轨迹数据进行类别分割,包括以下步骤:
[0096]
步骤2.1,计算各轨迹点间速度变化量δvi,即当前轨迹点与前一轨迹点的速度差绝对值;
[0097]
步骤2.2,计算各轨迹点间方向变化量δθi,即当前轨迹点与前一轨迹点航向差绝对值;
[0098]
步骤2.3,计算转弯距离比δri,采用对轨迹段进行的弯曲深度二叉树分割,如图2所示,记录各轨迹点的转弯距离hi与所在弯曲段的基线长度bendi,则转弯距离比等于hi除以bendi,如图2中轨迹点p2所在弯曲段的基线长度bend2=|p1p
10
|,转弯距离h2等于轨迹点p2到基线p1p
10
的垂直距离;
[0099]
步骤2.4,若轨迹点的速度变化量δvi和航向变化量δθi分别大于给定阈值tv和
t
α
,且转弯距离比δri=hi/bendi大于给定阈值t
dr
时,则该轨迹点被识别为候选交叉口轨迹点。经过上述分割后得到的结果如图3所示。
[0100]
步骤3:轨迹目标分割
[0101]
在步骤2交叉口轨迹类别层次分割基础上,将交叉口候选轨迹点作为dbscan输入样本集,经过聚类后确定各个交叉口的位置范围,具体实现包含以下步骤:
[0102]
步骤3.1,计算每个交叉口轨迹点的邻域点集n
eps
(pi)={pj|dis(pi,pj)≤eps},dis(pi,pj)为两轨迹点间欧氏距离,选择邻域点数|n
eps
(pi)|≥minpts的轨迹点为核心种子点;
[0103]
步骤3.2,逐一遍历各核心种子点,建立初始簇,选择当前核心种子点的邻域点集,将邻域点集内交叉口轨迹点添加至初始簇;
[0104]
步骤3.3,循环遍历当前簇中所有核心种子点,寻找与之密度相连的交叉口轨迹点,添加至同一簇中,直到没有密度相连的交叉口轨迹点被添加至该簇中;
[0105]
步骤3.4,继续遍历其他未处理的核心种子点,重复步骤3.2和3.3直到所有核心种子点皆被处理。
[0106]
每个交叉口轨迹点簇与单个交叉口目标对应,计算每个交叉口轨迹点簇的聚类中心后,以聚类中心到簇内各个轨迹点的最大距离为半径做外接圆,选择落入该外接圆内所有轨迹段作为后续步骤4交叉口通行模式分割的输入。
[0107]
步骤4:通行模式分割
[0108]
步骤4.1,对隶属于同一交叉口的各轨迹段的起、终点航向进行八方向蜘蛛编码,各编码对应的航向角区间如图4所示;
[0109]
步骤4.2,基于起、终点航向编码将各轨迹段划分为8
×
8=64种可能通行模式,每种模式分别对应了图5-(a)中起终点航向编码矩阵的一个元素,统计隶属于各元素的轨迹段数量占该交叉口总轨迹数量的比例,选择比例高于给定阈值ratio的元素,则这些元素所对应的通行模式即为该交叉口的典型通行模式。
[0110]
完成上述交叉口轨迹层次分割的第三层次分割(内部通行模式分割)后,即可得到交叉口内部通行规则,如图5-(a)所示为某交叉口对应的起终点航向编码矩阵,圆形符号大小代表该交叉口轨迹簇中隶属于各元素的轨迹段比例,矩形框表示最终识别的通行模式,图5-(b)列举了其中4个典型通行模式。
[0111]
步骤5:空间结构提取
[0112]
针对各交叉口识别的每一组通行模式轨迹段簇,利用分段轨迹迭代连接方法对各个交叉口的所有通行模式的片段簇求解其中心线,具体实现包含以下步骤:
[0113]
步骤5.1,选择某通行模式轨迹段簇中最长的一条轨迹段{t1...tm}作为初始中心线;
[0114]
步骤5.2,以当前中心线的各顶点t1...tm为圆心,以|t1t2|.../t
m-1
tm|,/tmt
m-1
|为半径分别构建缓冲区g1...gm;
[0115]
步骤5.3统计落在各缓冲区内的轨迹点分别计算这些轨迹点的平均几何中心c1...cm,以此更新原中心线各顶点t1...tm;
[0116]
步骤5.4,重复步骤5.2和5.3,直到两次迭代前后拟合的中心线之间hausdorff距离小于给定阈值ε。最终生成各个交叉口道路中心线,完成道路交叉口的提取。
[0117]
经过上述步骤后提取得到的道路交叉口空间结构如图6所示。
[0118]
为验证本发明的有效性,分别采用本发明方法与传统不经过密度匀化方法进行识别交叉口,结果如图7所示,其中,图7-(a)是不经过密度匀化直接识别的交叉口结果,图7-(b)是采用本发明经过密度匀化后识别得到的交叉口结果。通过与天地图对比进行精度检查,三角形对应为正确识别交叉口,正方形对应为错误识别交叉口,圆形对应为漏识别交叉口。由图7可见,本发明的方法经过密度匀化处理,能够正确探测到的交叉口数量明显更多,且错误识别的交叉口数量相对较少(如图中矩形框a所示)。本发明通过轨迹密度匀化处理,能够识别出一些车流稀疏、轨迹不均的道路交叉口(如图中椭圆框b所示),一定程度克服车流不均引起的道路感知有偏性问题。此外,采用速度变化、转向差异等局部特征还可以将通过停车场、小区等区域车辆轨迹(矩形框a右侧)错误识别为交叉口轨迹,本发明通过引入转弯距离比可有效克服该问题。
[0119]
如图8为本实施例得到的道路交叉口通行模式识别与最终交叉口结构提取结果,图8-(a)中线条为最终提取的道路交叉口结果,从图中可看出,道路交叉口形态各异、结构复杂,本发明方法能够在识别交叉口内部各种通行模式的基础上进行道路中心线提取。图8-(b)和(d)、(c)和(e)分别是图8-(a)中椭圆框中对应的复杂交叉口结构提取和通行模式识别的结果放大效果图,从图中可看出与实际影像具有较高一致性。
[0120]
本实施例还提供计算机装置,包括处理器以及存储器,存储器用于存储计算机程序,处理器用于执行计算机程序,其特征在于,处理器用于执行计算机程序以执行如上述方法。
[0121]
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。