1.本发明属于滚珠丝杠副技术领域,特别是基于滚道表面轮廓的滚珠丝杠副磨损状态识别方法。
背景技术:
2.滚珠丝杠副由于其好的定位精度以及承载性能而在数控机床中广泛使用。滚珠丝杠作为机床系统的主要传动机构,其磨损会导致滚珠丝杠副性能不断退化,甚至造成机床损坏危及人的生命安全,因此能够精准判断滚珠丝杠副的磨损状态显得尤为重要。
3.目前关于滚珠丝杠副磨损状态识别都是通过采集滚珠丝杠副运转过程中的振动信号并提取其特征进而实现磨损状态识别,然而该方法容易受到噪声等的干扰,造成预测结果较差。
技术实现要素:
4.本发明的目的在于针对现有技术存在的问题,提供一种基于滚道表面轮廓的滚珠丝杠副磨损状态识别方法,解决滚珠丝杠副磨损状态识别不够精确的技术问题。
5.实现本发明目的的技术解决方案为:滚珠丝杠副运行过程中的磨损状况可以通过滚道表面轮廓的变化反映出来,因此本发明提出了基于滚道表面轮廓的滚珠丝杠副磨损状态识别方法。该方法不仅能克服现有手段的缺点,而且具有实用、便捷、精确度高、误差小等优点,为滚珠丝杠副的磨损状态识别提供了一种新方法。
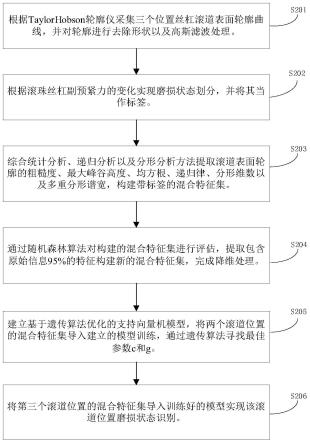
6.一种基于滚道表面轮廓的滚珠丝杠副磨损状态识别方法,所述方法包括以下步骤:
7.步骤1,采集三个滚道位置处滚珠丝杠副丝杠滚道表面轮廓曲线,并对轮廓进行去除形状以及高斯滤波处理;
8.步骤2,确定滚珠丝杠副磨损状态,将其作为标签;
9.步骤3,综合统计分析、递归分析以及分形分析方法提取滚道表面轮廓的主要特征,包括粗糙度、最大峰谷高度、均方根、递归律、分形维数以及多重分形谱宽,构建带标签的混合特征集合;
10.步骤4,评估混合特征集合中每个特征的重要性,之后根据重要性对混合特征集中的特征进行降序排列,提取包含原始信息超过p%的前m个特征构建新的混合特征集合;
11.步骤5,建立基于遗传算法优化的支持向量机模型,对所述新的混合特征集合进行归一化处理并提取两个滚道位置的混合特征集,之后导入建立的模型中进行训练,根据遗传算法选取最佳惩罚因子c和核函数参数g,完成模型的训练;
12.步骤6,将另一个滚道位置的混合特征集导入训练好的模型实现该滚道位置磨损状态识别,并将其与真实状态比较,获取模型的准确性;
13.步骤7,针对待识别的滚珠丝杠副,执行步骤1、步骤3至步骤4,获得其不带标签的混合特征集合,之后利用训练好的模型识别滚珠丝杠副的磨损状态。
14.进一步地,步骤1具体包括:
15.选取匀速运行区域丝杠的三个滚道位置,对其进行刻痕标记处理;
16.将滚珠丝杠副置于磨损试验台,在滚珠丝杠副运转前30万转时,每隔3万转停止试验台并拆下滚珠丝杠副,通过taylor hobson轮廓仪对其三个滚道位置进行表面轮廓曲线采集;在滚珠丝杠副运转30万转后,每隔6万转停止试验台并拆下滚珠丝杠副杠进行一次表面轮廓曲线采集;
17.通过高斯滤波对表面轮廓曲线进行平滑处理,之后采取五次多项式方法对平滑处理后的曲线进行去除形状操作,最终导出所需的滚道表面轮廓曲线。
18.进一步地,步骤2具体为:
19.以滚珠丝杠副预紧力变化趋势的转折点为分界点,将滚珠丝杠副磨损状态按序划分为磨合磨损、稳定磨损和急剧磨损状态;
20.依据当前滚珠丝杠副预紧力的变化趋势确定其磨损状态。
21.进一步地,步骤3具体包括:
22.步骤3-1,通过统计分析方法求解滚道表面轮廓曲线的粗糙度、最大峰谷高度以及均方根特征,所用公式为:
[0023][0024]
rz=z
max-z
min
[0025][0026]
其中,ra是粗糙度,rz是最大峰谷高度,rms是均方根,zi是第i个轮廓采样点的高度,z
min
和z
max
分别是最小轮廓高度以及最大轮廓高度,是轮廓的均值高度,n是采样率;
[0027]
步骤3-2,利用递归分析方法求解滚道表面轮廓的递归律,所用公式为:
[0028]rij
=|z
i-zj|
[0029]
ε=0.5σ
[0030]rij
(ε)=θ(ε-r
ij
)
[0031][0032][0033]
其中,rr为递归律,zi和zj均为轮廓高度,i,j=1,2,...,n,r
ij
表示任意两点i,j之间的距离,r
ij
为矩阵的一个元素,σ为标准偏差,ε为阈值,θ(x)为heaviside函数。
[0034]
步骤3-3,求解滚道表面轮廓的分形维数,过程包括:
[0035]
利用w-m函数表征非线性的滚道表面轮廓,公式为:
[0036][0037]
其中,1<d<2,γ>1,d是分形维数,g是高度尺度系数,γn是粗糙表面的频谱,n
为采样率,n1是最小采样率,l是采样长度,通常γ=1.5,z(x)是随机轮廓的高度,x为轮廓的位置坐标;
[0038]
w-m函数的功率谱函数表示为:
[0039][0040]
定义z(x)的增量方差为结构函数,如下式所示:
[0041][0042]
其中,τ=nδl,δl是采样间隔;
[0043]
联立上式可得:
[0044][0045]
其中c=γ(2d-3)sin((d-1.5)π)/(4-2d)lnγ,γ(*)是gamma函数,
[0046]
对上式两边取对数得:
[0047]
lgs(τ)=(4-2d)lgτ lgc 2(d-1)lgg
[0048]
根据上式可得分形维数d为:
[0049][0050]
其中,k为直线的斜率,分形维数可以反映滚道轮廓的复杂性和无规则性,分形维数越大,滚道轮廓越复杂,无规则性越大;
[0051]
步骤3-4,由于分形维数仅从单一测度对滚道轮廓进行描述,多重分形谱可以从多个测度对滚道轮廓进行描述,因此引入多重分形谱。
[0052]
采用盒计数法计算滚道表面轮廓的多重分形谱,提取滚道表面轮廓数据最小值当做下限零以保证幅值全为正值,采用许多尺寸为ε'的小盒子覆盖滚道轮廓,0<ε'<1,总的轮廓高度si(ε)表示当盒子尺寸为ε时第i个小盒子内所有轮廓幅值之和,则概率测度pi(ε)定义为:
[0053][0054]
其中,∑si(ε)为全部滚道轮廓数据幅值之和;
[0055]
在无标度区间内,pi(ε)也可写成指数形式:
[0056]
pi(ε)~ε
α
[0057]
其中,α为奇异指数,用于反映pi(ε)的奇异强度;
[0058]
设具有相同奇异指数α的盒子数量为n
α
(ε),则在无标度区间内n
α
(ε)写成指数形式:
[0059]nα
(ε)~ε-f(α)
[0060]
其中,f(α)表示奇异指数α对应的分形维数,且f(α)越小,n
α
(ε)越小;
[0061]
定义多重分形的配分函数为χq(ε),其公式为:
[0062]
χq(ε)=∑pi(ε)q=ε
τ(q)
[0063]
其中,q为权重因子,τ(q)为质量指数;
[0064]
当ε
→
0时,τ(q)写为公式:
[0065][0066]
联合α、f(α)和τ(α)三个参数并根据三者之间存在的legendre变换关系得:
[0067][0068]
f(α)=q
·
α(q)-τ(q)
[0069]
α和f(a)组成多重分形谱图;
[0070]
定义多重分形谱宽δα为:
[0071]
δα=α
max-α
min
[0072]
其中,α
min
和α
max
分别为最小奇异指数和最大奇异指数,δα表示序列的概率测度的不均匀性,对应表面轮廓高度的波动范围,波动范围越大,则δα越大;
[0073]
步骤3-5,联合三个滚道位置滚道表面轮廓的粗糙度、最大峰谷高度、均方根、递归律、分形维数以及多重分形谱宽,以及步骤2的标签,形成带标签的混合特征集合。
[0074]
进一步地,步骤4中采用基于袋外数据的随机森林算法评估混合特征集合中每个特征的重要性,具体过程包括:
[0075]
建立总体数据集d,其包括m个样本和n=6个特征组成;从数据集中独立抽样k次,每次抽样方式均为bagging重采样,每次随机抽取m个样本构成训练集s,即形成了k个相互独立的训练数据集,整个取样过程中未被抽到的数据称为袋外数据,即oob数据;
[0076]
对任意的训练数据集生成对应的单颗决策树,总共生成k颗决策树,每颗决策树通过oob数据集预测验证,预测结果为y
p
,真实值为y,取真实值与预测值的均方误差记为ε
mse
;
[0077]
对袋外数据n个特征中的某一特征ni添加噪声干扰,生成新的测试集,重新计算真实值与预测值均方误差,记为i=1,2,
…
,n;
[0078]
将特征变量ni对应的单颗决策树的重要性程度记为msei,其值为
[0079]
遍历由k颗决策树形成的随机森林,得到特征变量ni在整个随机森林中的重要性程度,记为
[0080]
进一步地,步骤5从所述新的混合特征集合提取两个滚道位置的混合特征集并进行归一化处理,之后导入建立的模型中进行训练,根据遗传算法选取最佳惩罚因子c和核函数参数g,完成模型的训练,具体包括:
[0081]
步骤5-1,随机生成m1个个体作为初始种群,并对参数c和g进行编码,设置最大进
化迭代次数为n1;
[0082]
步骤5-2,计算群体中每个个体的适应度;
[0083]
步骤5-3,对当前群体的最优个体进行解码处理,并判断其适应度是否满足条件或者是否达到种群最大进化迭代次数,若是,则转至步骤5-5,否则转至步骤5-4;
[0084]
步骤5-4,对参数c和g再次进行编码处理,对种群进行选择、交叉和变异操作,得到新的种群,转至步骤5-3;
[0085]
步骤5-5,输出最佳的参数c和g。
[0086]
进一步地,步骤5-2中适应度为滚珠丝杠副磨损状态识别的准确率,公式为:
[0087][0088]
式中,fitness为适应度,s为数据样本识别正确的数量,t为数据样本的总数量。
[0089]
本发明与现有技术相比,其显著优点为:
[0090]
1)本发明可以更精确、更简洁地实现滚珠丝杠副磨损状态识别,克服了传统上从振动信号提取特征存在大的噪声干扰造成磨损状态识别不准确的缺点。
[0091]
2)本发明建立的基于遗传算法优化的支持向量机模型可以很好地实现滚珠丝杠副磨损状态识别,准确率较高。
[0092]
下面结合附图对本发明作进一步详细描述。
附图说明
[0093]
图1为本发明基于滚道表面轮廓的滚珠丝杠副磨损状态识别方法的流程图。
[0094]
图2为一个实施例中提供的滚珠丝杠副滚道表面轮廓采集的结构示意图。
[0095]
图3为一个实施例中提供的滚珠丝杠副磨损试验台对应的结构示意图。
[0096]
图4为一个实施例中提供的基于滚道表面轮廓的滚珠丝杠副磨损状态识别的流程示意图。
[0097]
图5为一个实施例中提供的滚珠丝杠副疲劳剥落示意图,其中图5(a)为丝杠非工作区域滚道表面形貌,图5(b)为丝杠工作区域发生疲劳剥落滚道表面形貌。
[0098]
图6为一个实施例中提供的滚珠丝杠副磨损状态划分示意图。
[0099]
图7为一个实施例中提供的基于随机森林评估的特征重要性示意图。
[0100]
图8为一个实施例中提供的基于遗传算法优化支持向量机的模型训练示意图。
[0101]
图9为一个实施例中提供的基于遗传算法优化支持向量机的滚珠丝杠副磨损状态识别混淆矩阵示意图。
[0102]
图10为一个实施例中提供的降维前基于遗传算法优化支持向量机的模型训练示意图。
[0103]
图11为一个实施例中提供的降维前基于遗传算法优化支持向量机的滚珠丝杠副磨损状态识别混淆矩阵示意图。
具体实施方式
[0104]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不
用于限定本技术。
[0105]
结合图1,对本发明基于滚道表面轮廓的滚珠丝杠副磨损状态识别方法进行描述。参考图2,滚珠丝杠副滚道表面轮廓采集试验主要包括taylor hobson轮廓仪、支撑单元、pc和v型块等。采用taylor hobson轮廓仪对丝杠滚道表面轮廓进行提取,将滚珠丝杠副放置在两个v型块上支撑。轮廓仪测量前需校平,设置其采样长度为1mm。该测量位置为50th滚道,对其进行刻痕标记处理从而记录测量位置,68th滚道和98th滚道也进行同样的操作采取表面轮廓数据,选取的三个滚道位置均位于匀速运行区域。在此将其分别记为位置一到位置三。
[0106]
接着进行滚珠丝杠副磨损试验,参考图3,滚珠丝杠副磨损试验台主要由电涡流制动器、加载滚珠丝杠副、直线导轨、工作台以及步进电机等组成,通过设置电涡流制动器电流大小可以调节施加给滚珠丝杠副的轴向载荷大小,本试验设置电涡流制动器电流为2.5a,对应的轴向载荷为150kn。将被测滚珠丝杠副安装于该磨损试验台,滚珠丝杠副运转前30万转时,每隔3万转停止试验台并拆下丝杠,通过taylor hobson轮廓仪对其三个滚道位置进行表面轮廓曲线的采集。滚珠丝杠副运转30万转后,每隔6万转停止试验台并拆下丝杠进行一次轮廓采集试验。接着通过高斯滤波对其进行平滑处理,采取五次多项式方法对平滑处理后的曲线进行去除形状操作,最终导出所需的滚道表面轮廓曲线。
[0107]
接着根据滚珠丝杠副运行过程中预紧力的变化趋势实现滚珠丝杠副磨损状态的划分。
[0108]
进一步地,通过统计分析方法、递归分析方法以及分形分析方法提取采集的滚道表面轮廓曲线的特征值,具体步骤包括:
[0109]
首先通过统计分析方法求解提取的滚道轮廓曲线的粗糙度、最大峰谷高度以及均方根特征,该方法提取的特征可以反映滚道轮廓最原始的特性,且对磨损的变化较为敏感,三者越大,表示滚道轮廓越粗糙不平,该方法所用公式为:
[0110][0111]
rz=z
max-z
min
[0112][0113]
其中,ra是粗糙度,rz是最大峰谷高度,rms是均方根,zi是第i个轮廓采样点的高度,z
min
和z
max
分别是最小轮廓高度以及最大轮廓高度,z是轮廓的均值高度,n是采样率。
[0114]
利用递归分析方法求解提取的滚道轮廓曲线的递归律,递归律可以反映滚道轮廓的波动性和稳定性,递归律越大,则对应的轮廓越平稳,波动性越小,该方法所用公式为:
[0115]rij
=|z
i-zj|
[0116]
ε=0.5σ
[0117]rij
(ε)=θ(ε-r
ij
)
[0118]
[0119][0120]
其中,rr是递归律,zi和zj都是轮廓高度,i,j=1,2,...,n,r
ij
表示任意两点之间的距离,r
ij
是矩阵的一个元素,σ为标准偏差,ε为阈值,θ(x)是heaviside函数。
[0121]
统计分析方法以及递归分析方法都是尺度依赖的分析方法,与设备的采样长度有关,由于分形维数具有自相似性和无标度性,是尺度独立的特征,因此引入分形维数。分形维数的求解方法众多,结构函数法较为准确,本发明依据结构函数法求解分形维数。w-m函数适合用来表征非线性的滚道表面轮廓,公式为:
[0122][0123]
其中,1<d<2,γ>1,d是分形维数,g是高度尺度系数,γn是粗糙表面的频谱,n为采样率,n1是最小采样率,l是采样长度,通常γ=1.5,z(x)是随机轮廓的高度,x为轮廓的位置坐标,
[0124]
上式的功率谱函数可以表示为:
[0125][0126]
定义z(x)的增量方差为结构函数,如下式所示:
[0127][0128]
其中,τ=nδl,δl是采样间隔。
[0129]
联立上式可得:
[0130][0131]
其中c=γ(2d-3)sin((d-1.5)π)/(4-2d)lnγ,γ(*)是gamma函数,
[0132]
对式两边取对数得式:
[0133]
lgs(τ)=(4-2d)lgτ lgc 2(d-1)lgg
[0134]
根据上式可得分形维数d为:
[0135][0136]
其中,k为直线的斜率。分形维数可以反映滚道轮廓的复杂性和无规则性,分形维数越大,滚道轮廓越复杂,无规则性越大。
[0137]
由于分形维数仅从单一测度对滚道轮廓进行描述,多重分形谱可以从多个测度对滚道轮廓进行描述,因此引入多重分形谱。采用盒计数法计算滚道轮廓的多重分形谱,提取采集的滚道轮廓数据最小值当做下限零以保证幅值全为正值,采用许多尺寸为ε(0<ε<1)
的小盒子覆盖滚道轮廓,总的轮廓高度si(ε)表示当盒子尺寸为ε时第i个小盒子内所有轮廓幅值之和,则概率测度pi(ε)可以被定义为:
[0138][0139]
其中,∑si(ε)为全部滚道轮廓数据幅值之和。
[0140]
在无标度区间内,pi(ε)也可以写成指数形式,如公式:
[0141]
pi(ε)~ε
α
[0142]
其中,α为奇异指数,可以反映pi(ε)的奇异强度。
[0143]
假设具有相同奇异指数α的盒子数量为n
α
(ε),则在无标度区间内n
α
(ε)可以写成指数形式:
[0144]nα
(ε)~ε-f(α)
[0145]
其中,f(α)表示奇异指数α对应的分形维数,且f(α)越小,n
α
(ε)越小。由于奇异指数的盒子数量难以直接计算得到,因此通过引入配分函数计算。定义多重分形的配分函数为χq(ε),其公式为:
[0146]
χq(ε)=∑pi(ε)q=ε
τ(q)
[0147]
其中,q为权重因子,τ(q)为质量指数。q的取值本应在[-∞, ∞],然而实际计算时q的取值不能取无限大,因此本发明取q值为[-20,30],间隔为1。
[0148]
当ε
→
0时,τ(q)可以写为公式:
[0149][0150]
联系α、f(α)和τ(α)三个参数并根据三者之间存在的legendre变换关系得公式:
[0151][0152]
f(α)=q
·
α(q)-τ(q)
[0153]
α和f(a)组成多重分形谱图。定义多重分形谱宽δα为:
[0154]
δα=α
max-α
min
[0155]
其中,α
min
和α
max
分别为最小奇异指数和最大奇异指数,δα表示序列的概率测度的不均匀性,对应表面轮廓高度的波动范围,波动范围越大,则δα越大。
[0156]
通过上述方法将三个滚道位置表面轮廓的粗糙度、最大峰谷高度、均方根、递归律、分形维数以及多重分形谱宽联合,构建带标签的混合特征集。
[0157]
接着进行降维处理,降维方法为基于袋外数据(oob)的随机森林算法,具体过程为:
[0158]
建立总体数据集d,其由m个样本和n个特征组成。从数据集中独立抽样k次,每次抽样方式都是bagging重采样,每次随机抽取m个样本构成训练集s,即形成了k个相互独立的训练数据集,整个取样过程中未被抽到的数据称为袋外数据,即oob数据。
[0159]
·
对任意的训练数据集生成对应的单颗决策树,总共生成k颗决策树,每颗决策树通过oob数据集预测验证,预测结果为y
p
,真实值为y,取真实值与预测值的均方误差记为
ε
mse
。
[0160]
·
对袋外数据n个特征中的某一特征ni(i=1,2,
…
,n)添加噪声干扰,生成新的测试集,重新计算真实值与预测值均方误差,记为
[0161]
·
特征变量ni对应的单颗决策树的重要性程度记为msei,其值为
[0162]
·
遍历由k颗决策树形成的随机森林,得到特征变量ni在整个随机森林中的重要性程度,记为
[0163]
重要性程度mse可能会出现正值、负值和零三种情况。当输入的特征与输出有着强的关联性时,此时给该特征添加噪声,则关联性会减弱,重要性程度mse会出现正值,且正值越大表示该特征的重要性程度越大;当输入的特征与输出几乎没有关联性,且添加噪声也不会导致预测结果发生改变时,重要性程度mse为零;当添加噪声后输入的特征与输出的关联性增强时,重要性程度mse为负值。
[0164]
设置随机森林中决策树的个数为20,将步骤4中的混合特征集导入python,提取包含95%原始信息的特征构建新的混合特征集,进而实现降维。
[0165]
建立基于遗传算法优化的支持向量机模型,首先将两个滚道位置的混合特征集归一化处理并导入支持向量机模型,接着通过遗传算法实现最佳惩罚因子c以及核函数参数g的选取,完成模型的训练,具体过程为:
[0166]
·
随机生成m个个体作为初始种群,并将参数c和g进行编码,设置最大进化迭代次数为n。
[0167]
·
根据构建的混合特征集进行种群个体的评价,计算群体中每个个体的适应度进而评定每个个体的优劣程度。
[0168]
·
将当前群体的最优个体解码处理,并判断其适应度是否满足条件或者是否达到种群最大进化迭代次数,若有,则转至步骤最后一步,否则转至下一步。
[0169]
·
参数c和g再次进行编码处理,对种群进行选择、交叉和变异操作,对步骤3中适应度高的个体选择程度高,设置交叉概率和变异概率并得到新的种群,转至步骤3。
[0170]
·
得到最佳的参数c和g。
[0171]
本技术将状态识别模型的准确率设置为适应度,其公式为:
[0172][0173]
其中,s为数据样本分类正确的数量,t为数据样本的总数量。
[0174]
最后将第三个滚道位置的混合特征集归一化处理并导入到训练好的支持向量机模型实现滚珠丝杠副磨损状态的识别,其整体的流程图如图4所示。
[0175]
下面通过一个实施例对本发明方法进行阐述。
[0176]
选取试验丝杠为位于中国山东的博特精工股份有限公司生产的gd4010系列丝杠,主要参数如表1所示。
[0177]
表1 滚珠丝杠副参数
[0178][0179]
持续进行滚道表面轮廓数据采集,直到丝杠滚道表面出现疲劳剥落时停止,此时滚珠丝杠副总共运转142万转,如图5所示。将滚道表面轮廓进行高斯滤波处理以及五次多项式去除形状后导出,根据前文提到的特征提取方法提取六个特征随着滚珠丝杠副运行转数的变化。
[0180]
接着根据滚珠丝杠副运行过程中预紧力的变化实现滚珠丝杠副磨损状态划分,如图6所示,通过曲线拟合可发现预紧力呈现明显的三阶段变化趋势,分别代表磨合磨损、稳定磨损和急剧磨损状态,将其作为标签。
[0181]
接着将带标签的混合特征集导入随机森林评估算法中进行降维处理,得到的模型评分结果如图7所示,其重要性从高到低分别为均方根、粗糙度、递归律、最大峰谷高度、分形维数以及多重分形谱宽。可发现前5个特征所包含的原始信息已经超过95%,因此将多重分形谱宽舍去,由粗糙度、最大峰谷高度、均方根、递归律、分形维数五个特征构建新的混合特征集。
[0182]
建立完成基于遗传算法优化的支持向量机模型后,将三个滚道位置的混合特征集归一化处理。接着将位置一和位置二滚道表面轮廓构建的降维后的混合特征集导入到模型训练,遗传算法参数寻优的结果如图8所示,训练的准确率为100%。
[0183]
最后将位置三滚道的混合特征集导入到训练好的模型中实现滚珠丝杠副磨损状态识别,识别的混淆矩阵如图9所示,其识别准确率为96.7%。
[0184]
为验证随机森林算法降维的效果,将未降维的混合特征集导入到基于遗传算法优化的支持向量机模型,其训练过程和识别过程的混淆矩阵分别如图10和图11所示。观察可发现降维前后模型的训练准确率一致,都达到了100%,然而降维前的识别准确率仅为90%,降维后的准确率与之相比提高了近7%,说明经过随机森林算法评估降维是十分必要的。
[0185]
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。