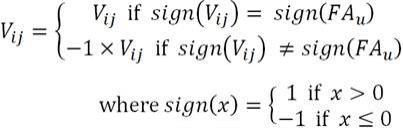
1.本发明属于人工智能安全领域,具体涉及一种基于鲁棒水印的深度学习模型保护方法。
背景技术:
2.模型保护的一种解决方案是在dnn模型中添加水印,这是一种用于识别dnn 模型所有权的常用方法。从根本上说,水印就是在模型中添加一些人工信息来标记它,从而使模型可以被跟踪和认证。水印通常包括嵌入水印和提取水印两个步骤。嵌入水印是指在模型的开发或训练阶段将数字水印添加到模型中,而提取水印是指从模型中提取和恢复水印,然后对植入的水印进行处理。
3.目前神经网络水印主要包括两种方法:黑盒水印和白盒水印,在白盒水印方法中,需要知道模型的具体细节才能完成水印嵌入,同样在提取水印时也需要模型的具体细节。另一方面,大多数黑盒水印嵌入方案是通过在 dnn 模型中嵌入后门来实现的。通常的做法是构造一个特定的触发集。触发集通常由一组图片和对应的特定标签(通常是错误的标签)组成。只有模型所有者知道触发器集的细节。在训练包含触发集的模型后,模型可以将触发集预测为特定标签。由于正常模型对触发集进行大量正常预测,因此以这种方式区分模型。特定输入与其标签之间的映射被视为后门并用作水印。如果检测到后门,则可以说所有者拥有该模型的所有权。文献structural watermarking to deep neural networks利用剪枝算法选取冗余参数进行水印嵌入,但是冗余参数在面对攻击时更容易导致水印丢失,为了解决这个问题,本发明引入多种剪枝算法选取重要参数进行水印嵌入,使得水印在面对攻击时具有更强的鲁棒性。
技术实现要素:
4.本发明解决的技术问题:提供一种利用剪枝算法会保留重要参数的特性针对模型水印构造更加鲁棒的模型水印。
5.技术方案:为了解决上述技术问题,本发明采用的技术方案如下:一种基于鲁棒水印的深度学习模型保护方法,其特征在于,采用不同的剪枝方法分别选择重要滤子,然后对不同剪枝方法取得的滤子进行求交集选择具有普遍性和重要性的滤子;然后对选择的滤子进行处理后作为水印嵌入模型中。主要包括以下步骤:步骤1:选择要向模型中嵌入的水印;步骤2:通过伪随机数生成器生成噪声序列;步骤3:使用生成的噪声序列对水印进行加噪;步骤4:使用基于熵的剪枝方法选择重要滤子;步骤5:使用基于l1范式的剪枝方法选择重要滤子;步骤6:使用基于bn的缩放因子选择重要滤子;步骤7:对步骤4-6中采用不同剪枝方法求得的重要滤子求交集选择更加具有普遍
性和重要性的滤子;步骤8:对于已经选择的重要滤子的每一层选择绝对值最大的参数,并且作为载体嵌入1bit的水印;步骤9:对嵌入水印之后的模型进行微调,直到模型的性能恢复到未嵌入水印的水平,得到水印模型。
6.进一步地,步骤1中,选择要向模型中嵌入的水印,方法为:将要嵌入的水印转化为二进制并且进行映射,获得水印为a={ai|ai∈{-1,1},i∈[0,f-1]},f表示水印的位数,见附图2。
[0007]
进一步地,步骤3中,使用生成的噪声序列对水印进行加噪,方法为:噪声序列为pr={pri|pri∈{-1,1},i∈[0,f-1]},pri表示噪声序列在第i位的值,通过噪声序列对水印进行加噪,获得水印为fa={fai|fai=pri×ai
,i∈[0,f-1]},噪声序列和水印的位数相同,见附图2。
[0008]
进一步地,步骤4中,使用基于熵的剪枝方法选择重要滤子,方法如下:步骤4.1:将第i层的滤子产生的激活张量表示为,同时也是第i 1层的输入,c、h、w分别代表激活张量在不同维度下的大小,采用全局池化层映射为1
×
c的向量;步骤4.2:输入g张图片,可以获得矩阵,将每一个通道分成b个块,通过求熵公式获得每个通道的熵,其中pi表示为第i个块的概率。
[0009]
步骤4.3:对求得通道熵进行降序排序,选取前m个,获得在此方法下的重要滤子序列t={t1,t2,
⋯
,tm}。
[0010]
进一步地,步骤5中,使用基于l1范式的剪枝方法选择重要滤子,方法如下:步骤5.1:对每一个滤子求绝对值之和∑|f
i,j
|,其中f
i,j
表示为滤子,通过衡量绝对值的大小来判断滤子的重要性,认为绝对值越大的滤子越重要。
[0011]
步骤5.2:对不同滤子的绝对值进行降序排列,选取前m个,获得在此方法下的重要滤子序列k={k1,k2,
⋯
,km}。
[0012]
进一步地,步骤6中,使用基于bn的缩放因子选择重要滤子,方法如下:步骤6.1:在对模型训练之前在模型卷积层之后加入bn层,记为:,其中:z
in
代表bn层的输入,z
out
代表bn层的输出,μb和σ分别表示激活输入的平均值和标准偏差,
ϵ
表示非常小的正实数,β表示可训练的仿射变换参数,γ为比例因子,使用数据集对模型进行训练之后,通过比例因子的大小判断滤子的重要性,越大的比例因子越重要。同时加入bn层并不会增大模型的训练量,也不会改变模型的训练过程。
[0013]
步骤6.2:训练之后对不同滤子的比例因子进行降序排列,选取前m个,获得在此方法下的重要滤子序列u={u1,u2,
⋯
,um}。
[0014]
进一步地,步骤7中,对不同剪枝方法求得的重要滤子求交集选择更加具有普遍性和重要性的滤子,方法如下:三种方法获得的不同重要滤子序列t={t1,t2,
⋯
,tm}、k={k1,k2,
⋯
,km}和u={u1,u2,
⋯
,um}求交集,如果三种剪枝方法都认为某个滤子重要,则将此滤子加入到重要滤子序列,最后获得的重要滤子序列i={i1,i2,
⋯
,i
t
},从序列i中随机选取v个滤子组成序列e={e1,e2,
⋯
,ev}作为最后的水印载体。
[0015]
进一步地,步骤8中,对于已经选择的重要滤子的每一层选择绝对值最大的参数,并且作为载体嵌入1bit的水印,方法如下:步骤8.1:向滤子的每一层都嵌入1bit水印,找到每一层中的绝对值最大的参数作为载体嵌入。
[0016]
步骤8.2:通过对绝对值最大的参数与要嵌入水印的参数进行映射来完成水印的嵌入式中,v
ij
为要嵌入水印的参数,fau为要嵌入的水印。
[0017]
进一步地,步骤9中,对嵌入水印之后的模型进行微调,直到模型的性能恢复到未嵌入水印的水平,得到水印模型。由于水印的嵌入会改变模型的原始参数可能会导致模型性能下降,所以需要对嵌入水印后的模型进行微调。
[0018]
有益效果:与现有技术相比,本发明具有以下优点:(1)本发明提出基于剪枝的深度神经网络模型水印防御方法,将通道级剪枝策略选择滤子融入到模型水印中。
[0019]
(2)本发明融合了三种剪枝策略,包括基于缩放因子、基于l1范式和基于熵,通过单种剪枝方法选择的重要参数可能具有冗余性,所以本发明融合三种不同的剪枝方法获得三种方法都认为重要的参数,从而选择更加具有普遍性的重要参数,使得以重要参数为载体进行嵌入的水印在面对攻击时拥有更强的鲁棒性。
[0020]
(3)本发明相比于其他水印嵌入方法,拥有更强的鲁棒性,给水印参数载体的选择提供了另一种参考。
附图说明
[0021]
图1是本发明基于鲁棒水印的深度学习模型保护方法的流程示意图。
[0022]
图2是本发明的水印生成图。
[0023]
图3是本发明于鲁棒水印的深度学习模型保护方法的水印嵌入示意图。
具体实施方式
[0024]
下面结合具体实施例,进一步阐明本发明,实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
[0025]
本发明的基于鲁棒水印的深度学习模型保护方法,首先选取要嵌入的水印;通过
伪随机数生成器生成噪声序列;使用噪声序列对水印进行加噪;使用基于熵的剪枝方法选择重要滤子;使用基于l1范式的剪枝方法选择重要滤子;使用基于bn的缩放因子选择重要滤子;对不同剪枝方法求得的重要滤子求交集选择更加重要的滤子;然后对于滤子的每一层选择绝对值最大的参数,并且作为载体嵌入1bit的水印;最后对嵌入水印之后的模型进行微调使得模型的性能恢复从而获得最后的水印模型。具体包括如下步骤1-步骤9共九大步骤:步骤1:选择要向模型中嵌入的水印,具体方式如下:将要嵌入的水印转化为二进制并且进行映射,获得水印为a={ai|ai∈{-1,1},i∈[0,f-1]},f表示水印的位数,见附图2。
[0026]
步骤2:通过伪随机数生成器生成噪声序列;步骤3:使用生成的噪声序列对水印进行加噪,具体方式如下:噪声序列为pr={pri|pri∈{-1,1},i∈[0,f-1]},pri表示噪声序列在第i位的值,通过噪声序列对水印进行加噪,获得水印为fa={fai|fai=pri×ai
,i∈[0,f-1]},噪声序列和水印的位数相同,见附图2。
[0027]
步骤4:使用基于熵的剪枝方法选择重要滤子,具体方式如下:步骤4.1:将第i层的滤子产生的激活张量表示为,同时也是第i 1层的输入,c、h、w分别代表激活张量在不同维度下的大小,采用全局池化层映射为1
×
c的向量;步骤4.2:输入g张图片,可以获得矩阵,将每一个通道分成b个块,通过求熵公式获得每个通道的熵,其中pi表示为第i个块的概率。
[0028]
步骤4.3:对求得通道熵进行降序排序,选取前m个,获得在此方法下的重要滤子序列t={t1,t2,
⋯
,tm}。
[0029]
步骤5:使用基于l1范式的剪枝方法选择重要滤子,具体方式如下:步骤5.1:对每一个滤子求绝对值之和∑|f
i,j
|,其中f
i,j
表示为滤子,通过衡量绝对值的大小来判断滤子的重要性,认为绝对值越大的滤子越重要。
[0030]
步骤5.2:对不同滤子的绝对值进行降序排列,选取前m个,获得在此方法下的重要滤子序列k={k1,k2,
⋯
,km}。
[0031]
步骤6:使用基于bn的缩放因子选择重要滤子,具体方式如下:步骤6.1:在对模型训练之前在模型卷积层之后加入bn层,记为:,其中:z
in
代表bn层的输入,z
out
代表bn层的输出,μb和σ分别表示激活输入的平均值和标准偏差,
ϵ
表示非常小的正实数,β表示可训练的仿射变换参数,γ为比例因子,使用数据集对模型进行训练之后,通过比例因子的大小判断滤子的重要性,越大的比例因子越重要。同时加入bn层并不会增大模型的训练量,也不会改变模型的训练过程。
[0032]
步骤6.2:训练之后对不同滤子的比例因子进行降序排列,选取前m个,获得在此方法下的重要滤子序列u={u1,u2,
⋯
,um}。
[0033]
步骤7:对不同剪枝方法求得的重要滤子求交集选择更加具有普遍性和重要性的滤子,具体方式如下:三种方法获得的不同重要滤子序列t={t1,t2,
⋯
,tm}、k={k1,k2,
⋯
,km}和u={u1,u2,
⋯
,um}求交集,如果三种剪枝方法都认为某个滤子重要,则将此滤子加入到重要滤子序列,最后获得的重要滤子序列i={i1,i2,
⋯
,i
t
},从序列i中随机选取v个滤子组成序列e={e1,e2,
⋯
,ev}作为最后的水印载体。
[0034]
步骤8:对于已经选择的重要滤子的每一层选择绝对值最大的参数,并且作为载体嵌入1bit的水印,具体方式如下:步骤8.1:向滤子的每一层都嵌入1bit水印,找到每一层中的绝对值最大的参数作为载体嵌入。
[0035]
步骤8.2:通过对绝对值最大的参数与要嵌入水印的参数进行映射来完成水印的嵌入式中v
ij
为要嵌入水印的参数,fau为要嵌入的水印。
[0036]
步骤9:由于水印的嵌入会改变模型的原始参数可能会导致模型性能下降,所以需要对嵌入水印后的模型进行微调;对嵌入水印之后的模型进行微调,直到模型的性能恢复到未嵌入水印的水平,得到水印模型。
[0037]
本发明通过以下实验验证本发明的方法有效性和效率:评估标准为在面对攻击时的水印准确率,该度量表示未改变或者丢失的水印占原水印的比例。
[0038]
首先选定数据集,cifar-10数据集,包括数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但一些训练批次可能包含来自一个类别的图像比另一个更多。本发明对于每种剪枝方法选择前10%的滤子作为重要滤子,对三种结果求交集选择重要滤子,模型选择vgg19,在模型中嵌入256位水印。本发明与文献embedding watermarks into deep neural networks中提出的方法进行比较,下面称为其他水印方法。
[0039]
表1 不同方法在微调攻击下的效果
表2 不同方法在剪枝攻击下的效果表3不同方法在覆盖攻击下的效果表1的结果表示,实验结果表明本发明方法的水印准确率显示了方法的总体有效性,在面对微调攻击时即使攻击200轮,两种方法的水印准确率都可以达到100%。表2所示,在面对剪枝攻击时,剪枝率达到90%时,采用本发明方法的水印准确率仍然高达99%以上。如表3所示,在面对覆盖攻击时覆盖256bit的新水印,本发明的水印准确率一直可以保持100%,但是其他方法的水印损失率最高可以达到30.9%。所以可以看到在面对各种攻击时本发明方法具有很强的鲁棒性。总体而言,本发明提出基于剪枝的深度神经网络模型水印防御方法,将通道级剪枝策略选择滤子融入到模型水印中。
[0040]
本发明融合了三种剪枝策略,包括基于缩放因子、基于l1范式和基于熵,通过单种剪枝方法选择的重要参数可能具有冗余性,所以本发明融合三种不同的剪枝方法获得三种方法都认为重要的参数,从而选择更加具有普遍性的重要参数,使得以重要参数为载体进行嵌入的水印在面对攻击时拥有更强的鲁棒性。
[0041]
本发明相比于其他水印嵌入方法,拥有更强的鲁棒性,给水印参数载体的选择提供了另一种参考。
[0042]
以上仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
