1.本发明涉及交通导航技术领域,具体涉及一种基于时序差分学习的可靠性导航方法
背景技术:
2.随机交通路网中的导航问题一直是交通领域的研究热点之一。最简单的导航设计方案是基于路网模型计算出一条最短路径供用户使用。然而这种方案功能过于单一,仅仅考虑了最小化行程时间的平均值,而忽略了交通环境的随机性为用户带来的行程时间的变化,例如交通拥挤或通顺导致的道路通行时间在极大范围内变化,积水、修路等自然原因导致某些道路被彻底阻断,交通事故导致道路能否继续保持通畅存疑。这种路网中行程时间的不确定性,对导航车辆行驶时间影响极大,进入拥挤路段会使驾驶者感到疲惫并加剧交通堵塞,或者一次临时的绕路可能增加数倍的出行成本。
3.因此先需要一种针对城市交通路网中通过道路所耗时间的不确定性因素做出合理判断的导航方法,以进一步提高导航的准确性和效率
技术实现要素:
4.针对现有技术的上述不足,本发明提供了一种基于时序差分学习的可靠性导航方法,解决了现有技术中无法在道路存在不确定因素的情况下做出最优导航决策的问题。
5.为达到上述发明目的,本发明所采用的技术方案为:
6.一种基于时序差分学习的可靠性导航方法,包括以下步骤:
7.步骤a:建立决策过程模型,并生成数个节点s和数个指定动作a;
8.步骤b:制定决策列表策略π,采用π确定数个指定动作a的优先级;
9.步骤c:基于决策过程模型,采集得到当前行驶代价r的样本值,并分别求取g
π
(s)和g
π
(s,a)的均值估计值与方差估计值;其中g
π
(s)的均值估计值和方差估计值分别为v
π
(s)和g
π
(s,a)的均值估计值和方差值分别为q
π
(s,a)和
10.所述g
π
(s)为智能体从节点s出发,并遵守策略π直到到达终点累计的奖励之和;所述g
π
(s,a)为智能体从节点s出发,并执行动作a后遵守策略π直到到达终点,累计收集的奖励之和;
11.步骤d:根据步骤c中的均值估计值和方差估计值计算线性组合值z
π
(s,a);将上述线性组合值代入步骤b中的决策列表策略π,并更新决策列表策略得到π
′
;
12.步骤e:循环步骤b-步骤d,直到完成规定学习次数,输出更新后的决策列表策略π
′
,导航根据π
′
进行实时指引,直到智能体到达终点。
13.采用上述方案,通过对各节点动作的均值能够判断该动作所对应道路的行程时间,个节点动作的方差值能够判断该节点对应道路的不确定性风险,通过将均值与方差值进行线性组合并得到线性组合值z
π
(s,a),即对通过该道路的时间长短和对该道路的通过风险进行综合性的判断,通过上述方案,能够有效判断处该道路的综合优先级,避免出现传
统技术中盲目选择路程较短的道路,而忽视了该道路可能出现的如堵车、修路、积水等自然原因导致的通过缓慢的问题,实现了提高导航准确性的技术效果。
14.所述步骤b的具体步骤为:
15.步骤b1:收集所有边的集合作为最大动作集m,并根据计算线性组合值从小到大的顺序排列m中的各个指定动作a,得到按照优先级顺序排列的集合π(s)={a1、a2、a3......ak};
16.步骤b2:选择其中优先级最高的指定动作a1,若a1所对应的边不可通行,则顺延选用下一优先级的指定动作。
17.所述步骤c的具体步骤为:
18.步骤c1:实时采集当前行驶代价r的样本值;
19.步骤c2:通过步骤c1中的r对g
π
(s)和g
π
(s,a)的均值估计值进行实时更新;
20.步骤c3:通过步骤c1中的r对g
π
(s)和g
π
(s,a)的方差估计值进行实时更新。
21.采用上述方案,具体公开了如何计算g
π
(s)和g
π
(s,a)的均值估计值,该均值估计值能够体现出完成动作a后选择的道路的通过时间,该均值估计值越小,则通过该道路的时间越少,该道路的选择优先级越高;其中方差估计值能够体现道路的稳定性,若该道路的方差估计值越小,则说明该道路发生影响通过速度的自然事件的概率越低,道路越通畅,该道路的选择优先级越高,通过对g
π
(s)和g
π
(s,a)的均值估计值和方差估计值的计算,能够较为全面的评估道路的通过时间与通过风险,使输出的决策列表策略更加准确。
22.所述步骤c2的具体步骤为:
23.步骤c21:对g
π
(s)和g
π
(s,a)的均值估计值进行实时更新:
[0024]vπ
(s)=ex[g
π
(s)]
[0025]qπ
(s,a)=ex[g
π
(s,a)]
[0026]
其中ex[g
π
(s)]表示g
π
(s)的平均值,ex[g
π
(s,a)]表示g
π
(s,a)的平均值,v
π
(s)为g
π
(s)的均值估计值,q
π
(s,a)为g
π
(s,a)的均值估计值;
[0027]
步骤c22:根据r更新v
π
(s)的数值:
[0028]vπ
(s)1=v
π
(s) α(r γv
π
(s
′
)-v
π
(s))
[0029]
其中,s
′
是在状态s处执行动作a后达到的下一状态,γ=1,α是均值学习率,v
π
(s)1是完成更新后的v
π
(s)值;
[0030]
步骤c23:根据r更新q
π
(s,a)的数值:
[0031]qπ
(s,a)1=q
π
(s,a) α(r γv
π
(s
′
)-q
π
(s,a))
[0032]
其中,q
π
(s,a)1是完成更新后的q
π
(s,a)值。
[0033]
所述步骤c3的具体步骤为:
[0034]
步骤c31:对g
π
(s)和g
π
(s,a)的方差估计值进行实时更新:
[0035][0036][0037]
其中var[g
π
(s)]表示[g
π
(s)]的方差值,var[g
π
(s,a)]表示g
π
(s,a)的方差值,为g
π
(s)的方差估计值,为g
π
(s,a)的方差估计值;
[0038]
步骤c32:根据r更新的数值:
[0039][0040]
其中为时序差分误差,其计算公式为:其中为更新后的数值,是方差学习率,s
′
是在状态s处执行动作a后达到的下一状态,γ=1;
[0041]
步骤c33:根据r更新的数值:
[0042][0043]
其中δ(s,a)为的时序差分误差,其计算公式为:δ(s,a)=r γv
π
(s
‘
)-q
π
(s,a),其中为更新后的数值。
[0044]
步骤a的具体步骤为:
[0045]
步骤a1:输入地图graph和导航的起点o、终点d;
[0046]
步骤a2:设定最大学习次数n
t
;
[0047]
步骤a3:初始化数据,使学习次数i=0,s=0。
[0048]
步骤e的具体步骤为:
[0049]
步骤e1:根据公式计算每个状态-动作对应的z
π
(s,a)数值;
[0050]
步骤e2:将所有指定动作按照其对应的z
π
(s,a)数值排序,得到新的决策列表策略π
‘
;
[0051]
步骤e3:判断当前学习次数i是否小于最大学习次数n
t
,若否,则输出决策列表策略π
‘
;若是,则判断当前节点s是否等于终点d,若当前节点s等于终点d,则重新判断学习次数是否小于最大学习次数n
t
,若当前节点s不等于终点d,则继续循环步骤e1-e2。
[0052]
所述步骤d的具体步骤为:
[0053]
步骤d1:根据得到的q
π
(s,a)值和q
π
(s,a)值计算z
π
(s,a)数值:
[0054][0055]
其中,ζ为可靠性系数;
[0056]
步骤d2:将所有指定动作按照其对应的z
π
(s,a)数值排序,得到新的决策列表策略π
′
。
[0057]
综上,本发明的有益效果为:
[0058]
1.通过采用决策列表策略和强化学习方法解决了交通网中导航存在的道路通行概率和道路行程时间两种不确定性因素所带来的总体行程时间变化的问题,在实际使用中,可以使用户通过导航系统避免拥堵、临时绕路等问题,导航系统通过提前判断拥堵路段、不确定性自然因素造成的不可通行路段,使用户所花费的时间得到合理的优化。
[0059]
2.通过决策列表策略,能够将各个节点中的各个指定动作进行优先级排序,并根据排序后的指定动作进行决策列表策略的更新,通过该种方案,能够进一步提高导航学习的效率。
附图说明
[0060]
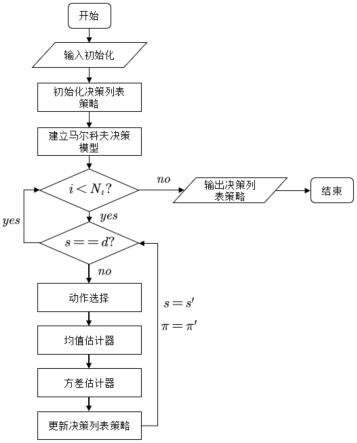
图1为本发明的算法流程图。
具体实施方式
[0061]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0062]
实施例一:
[0063]
一种基于时序差分学习的可靠性导航方法,包括以下步骤:
[0064]
步骤a:建立决策过程模型,并生成数个节点s和数个指定动作a;
[0065]
步骤b:制定决策列表策略π,采用π确定数个指定动作a的优先级;
[0066]
步骤c:基于决策过程模型,采集得到当前行驶代价r的样本值,并分别求取g
π
(s)和g
π
(s,a)的均值估计值与方差估计值;其中g
π
(s)的均值估计值和方差估计值分别为v
π
(s)和g
π
(s,a)的均值估计值和方差值分别为q
π
(s,a)和
[0067]
所述g
π
(s)为智能体从节点s出发,并遵守策略π直到到达终点累计的奖励之和;所述g
π
(s,a)为智能体从节点s出发,并执行动作a后遵守策略π直到到达终点,累计收集的奖励之和;
[0068]
步骤d:根据步骤c中的均值估计值和方差估计值计算线性组合值z
π
(s,a);将上述线性组合值代入步骤b中的决策列表策略π,并更新决策列表策略得到π
′
;
[0069]
步骤e:循环步骤b-步骤d,直到完成规定学习次数,输出更新后的决策列表策略π
′
,导航根据π
′
进行实时指引,直到智能体到达终点。
[0070]
在上述实施例中,g
π
(s)和g
π
(s,a)使在策略过程模型中采集得到的,本发明中的均值估计值和方差估计值均以上述g
π
(s)和g
π
(s,a)的数值作为基础计算,基于该中方案,需要以准确的导航地图和路况信息作为信息来源;
[0071]
进一步来说,在本实施例中通过计算预估g
π
(s)和g
π
(s,a)的均值和标准差值,来判断在各个节点中做出不同指定动作对整个路线的影响,从而得到在各个节点中的最优指定动作,上述指定动作主要为方向性动作,如向左行驶、向右行驶,其中每个指定动作a完成后,均会选择一条道路直到下一个节点,上述方差值能够体现该道路的稳定性,主要包括堵车、积水或其他自然因素所带来的影响,其中方差值越低,则说明该道路的能够通畅行驶的概率越高,在实际计算中,将该方差值换算为标准差值,其判断依据不变;上述均值能够反映通过该道路的行驶时间,其中均值越小,则说明通过该道路的时间越短,通过计算上述标准差之和均值的组合线性值,能够较为全面的体现道路选择的优先级。
[0072]
进一步来说,在上述方案中,设计对道路的选择,具体来讲就是通过对指定动作a的优先级排序,使汽车选择较优的道路,其具体通过步骤b来实现,其中步骤b的具体步骤为:
[0073]
步骤b1:收集所有连接编的集合为最大动作集m,并根据计算线性组合值从小到大的顺序排列m中的各个指定动作a,得到按照优先级顺序排列的集合π(s)={a1、a2、a3......ak};
[0074]
步骤b2:选择其中优先级最高的指定动作a1,若a1所对应的边不可通行,则顺延选用下一优先级的指定动作。
[0075]
为方便理解,在本实施例中设集合m={a2、a1、a3、a4},在完成优先级排序后,得到按照优先级排序的集合π(s)={a1、a2、a3、a4},其中a1、a2、a3、a4代表方向不同的指定动作,并分别能够进入方向不同的道路,此时系统进行判断,首先选择进行指定动作a1,若a1所指向的道路无法通行,则顺延进行指定动作a2,若a2所指向的道路也无法通行,则顺延进行指定动作a3。
[0076]
在上述指定动作选择的讯息训练阶段,假设任意道路的可通行概率为ρ,车辆在每个节点s处遵循以下原则进行动作采样:
[0077]
1.对前一部分数据进行动作选择,直到选择到数量上限的指定动作;
[0078]
2.后一部分的数据按当前节点所对应的决策列表顺序进行选择,当前指定动作包括a1、a2、a3......ak,其中k为当前节点对应的最大可执行边数,执行指定动作a1、a2、a3......ak的概率分别为
[0079]
3.设置greedy策略,使每个指定动作选择的奖励值最大化。
[0080]
上述公式中,指定动作a1的优先级最高,其a1所指向的道路能够通行的概率为ρ1;其中指定动作a2的优先级排在第二,且a2所指向的道路能够通行的概率为ρ2,当指定动作a1所指向的道路无法通行时,则执行指定动作a2,在整个方案中,执行指定动作a2且指定动作a2所指向的道路能够通行的概率为(1-ρ1)ρ2,后续其他方向的道路通行概率与上述道路的计算方式相同。
[0081]
由上述方案可知,在本实施例中需要对各个指定动作进行优先级排序,该优先级排序的依据为z
π
(s,a)值的大小,其中z
π
(s,a)中的各计算元素由步骤c得出,其中步骤c的具体步骤为:
[0082]
步骤c1:实时采集当前行驶代价r的样本值;
[0083]
步骤c2:通过步骤c1中的r对g
π
(s)和g
π
(s,a)的均值估计值进行实时更新;
[0084]
步骤c3:通过步骤c1中的r对g
π
(s)和g
π
(s,a)的方差估计值进行实时更新。其中计算g
π
(s)的均值估计值与方差估计值的目的是得出计算g
π
(s,a)的均值估计值和方差估计值,最终的z
π
(s,a)计算公式中只包含g
π
(s,a)的均值估计值和标准差,其具体为:其中为g
π
(s,a)的标准差,数值大小为g
π
(s,a)的方差估计值的平方根。
[0085]
其中步骤c2的具体步骤为:
[0086]
步骤c21:对g
π
(s)和g
π
(s,a)的均值估计值进行实时更新:
[0087]vπ
(s)=ex[g
π
(s)]
[0088]qπ
(s,a)=ex[g
π
(s,a)]
[0089]
其中ex[g
π
(s)]表示g
π
(s)的平均值,ex[g
π
(s,a)]表示g
π
(s,a)的平均值,v
π
(s)为g
π
(s)的均值估计值,q
π
(s,a)为g
π
(s,a)的均值估计值;
[0090]
步骤c22:根据r更新v
π
(s)的数值:
[0091]vπ
(s)1=v
π
(s) α(r γv
π
(s
′
)-v
π
(s))
[0092]
其中,s
′
是在状态s处执行动作a后达到的下一状态,γ=1,α是均值学习率,v
π
(s)
1是完成更新后的v
π
(s)值;
[0093]
步骤c23:根据r更新q
π
(s,a)的数值:
[0094]qπ
(s,a)1=q
π
(s,a) α(r γv
π
(s
′
)-q
π
(s,a))
[0095]
其中,q
π
(s,a)1是完成更新后的q
π
(s,a)值。
[0096]
在上述实施例中,α为均值学习率,工作人员可根据需要进行自定义。通过上述对于g
π
(s,a)的均值估计值的更新公式,能够实时调整在最终公式(s,a)的均值估计值的更新公式,能够实时调整在最终公式中均值估计值的数值,以使决策列表策略中的优先据排序更加准确。
[0097]
进一步来说,上述g
π
(s)和g
π
(s,a)的方差估计值的计算及更新方法为:
[0098]
步骤c31:对g
π
(s)和g
π
(s,a)的方差估计值进行实时更新:
[0099][0100][0101]
其中var[g
π
(s)]表示[g
π
(s)]的方差值,var[g
π
(s,a)]表示g
π
(s,a)的方差值,为g
π
(s)的方差估计值,为g
π
(s,a)的方差估计值;
[0102]
步骤c32:根据r更新的数值:
[0103][0104]
其中为时序差分误差,其计算公式为:其中为更新后的数值,是方差学习率,s
′
是在状态s处执行动作a后达到的下一状态,γ=1;
[0105]
步骤c33:根据r更新的数值:
[0106][0107]
其中δ(s,a)为的时序差分误差,其计算公式为:δ(s,a)=r γv
π
(s
‘
)-q
π
(s,a),其中为更新后的数值。
[0108]
步骤a的具体步骤为:
[0109]
步骤a1:输入地图graph和导航的起点o、终点d;
[0110]
步骤a2:设定最大学习次数n
t
;
[0111]
步骤a3:初始化数据,使学习次数i=0,s=0。
[0112]
步骤d的具体步骤为:
[0113]
步骤d1:根据得到的q
π
(s,a)值和q
π
(s,a)值计算z
π
(s,a)数值:
[0114][0115]
其中,ζ为可靠性系数;
[0116]
步骤d2:将所有指定动作按照其对应的z
π
(s,,a)数值排序,得到新的决策列表策略π
′
。步骤e的具体步骤为:判断当前学习次数i是否小于最大学习次数n
t
,若否,则输出决策列表策略π
‘
;若是,则判断当前节点s是否等于终点d,若当前节点s等于终点d,则重新判断学习次数是否小于最大学习次数n
t
,若当前节点s不等于终点d,则继续循环步骤b-步骤d。
[0117]
在上述方案中,使用人员需要预先设定学习次数i和起点o、终点d和最大学习次数n
t
,其中车辆从起点o开始,每遇到一个节点s,进行一次学习,具体包括上述步骤b-到步骤d中的更新决策列表策略,当遇到下一路口时,先进行判断,当前学习次数i是否小于最大学习次数n
t
,若是,则进行下一步判断,当前节点s是否为终点d,若否,则循环上述步骤步骤b到步骤d中的更新决策列表策略,直到学习次数i不小于最大学习次数n
t
,且当前节点s为终点d,输出此时的决策列表策略π’,此时,车辆导航将按照决策列表策略π’中的各个指定动作为车辆进行导航。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
