1.本发明涉及孤独症谱系障碍自助式筛查技术领域,更具体地,涉及一种孤独症谱系障碍自助式筛查方法。
背景技术:
2.孤独症谱系障碍俗称孤独症(asd),是一种终生发育障碍。孤独症由于其特殊性,目前尚无法通过基因检测、血液检查、核磁共振等生化性指标确诊,医生资源也极其有限,一个家庭往往为了儿童的确诊要辗转多地、耗时多年,耽误了早期康复的时间。孤独症由于其特殊性,目前尚无法通过基因检测、血液检查、核磁共振等生化性指标确诊,医生资源也极其有限,一个家庭往往为了儿童的确诊要辗转多地、耗时多年,耽误了早期康复的时间。目前国内90%以上的孤独症诊疗都采用的是传统的手段,如图1所示,医生主要根据两个关键量表的评分对儿童进行诊断。常用量表有abc量表和cars量表,abc量表为家长评定量表,共57个项目4级评分,53分疑诊,67分确诊;cars量表为医生评定量表,共15个项目4级评分,总分大于30分可以诊断为孤独症。这种诊断方式受时间、地域、医生经验及主观意识影响较大。这种诊断方式存在以下问题:评估耗时时间长、问题数量多、使用静态基本评分函数生成孤独症评分、需要专门的临床医生来统计管理整个过程。
3.对此,本发明提出一种新的孤独症谱系障碍自助式筛查方法,用机器学习取代经典筛查方法中的常规评分功能。与传统的筛查方式相比,本专利提出的基于机器学习的孤独症筛查系统具有更高的准确性、敏感性和特异性,可以大大的减轻医院和诊疗人员的工作量,有可能改变未来孤独症谱系障碍筛查的新方式。
技术实现要素:
4.本发明的目的在于提供一种孤独症谱系障碍自助式筛查方法,该方法利用机器学习筛选方法能够通过查看隶属数据样本来学习和孤独症相关的隐藏知识和模式来进行预测,不仅可以提供准确的诊断前分类,还可以提高筛查过程的效率和准确性。
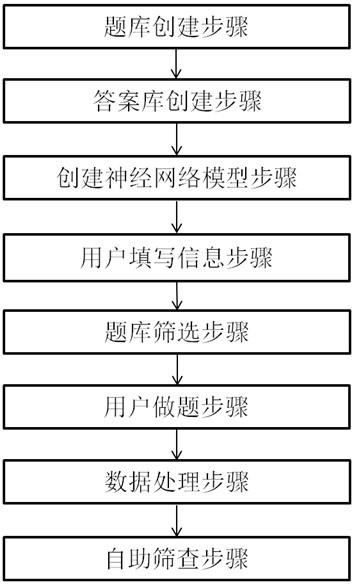
5.为达到上述目的,提供了一种孤独症谱系障碍自助式筛查方法,包括以下步骤:题库创建步骤,预设若干个基础项,建立题库;题库包括若干组问题集;每个问题集对应一个或多个基础项;所述问题集包括依据对应的基础项筛选的若干个用于孤独症谱系障碍诊断的问题,每个问题对应一个唯一的问题序列;答案库创建步骤,建立答案库;所述答案库用于存储答题流水号、问题序号、答案序号并使得答题流水号、问题序号、答案序号之间相互关联;创建神经网络模型步骤,采用神经网络及机器学习训练方法建立的神经网络模型;所述神经网络模型以用户信息项、问题集的所有问题序列结合对应答案序列组成的数据集为输入,以孤独症谱系障碍评定结果为输出;所述孤独症谱系障碍评定结果为孤独症类别;用户填写信息步骤,获取用户填写的基本信息;所述基本信息包括若干个用户信
息项;所述用户信息项中含有基础项;题库筛选步骤,根据基本信息的基础项从题库筛选问题集;用户做题步骤,生成答题流水号,获取用户填写问题集的每个问题的答案信息,并将答案信息转化为答案序号;数据处理步骤,将经过用户做题步骤获得的答题流水号、问题序号、答案序号存储至答题库,并将用户填写信息步骤获得的基础项、问题序号组成问题序列及对应答案序号组成为数据集;自助筛查步骤,将数据处理步骤获得的数据集输入至神经网络模型,输出孤独症谱系障碍评定结果。
6.特别的,还包括设于数据处理步骤后的数据有效性判断步骤,数据有效性判断步骤为设定判断出没有任何孤独症谱系障碍的标准答案序号;若数据处理步骤的数据集中的答案序号与标准答案序号匹配或数据集中的答案序号的长度小于问题集中问题序列的长度则返回用户做题步骤;否则进行自助筛查步骤。
7.特别的,还包括数据反馈步骤,将自助筛查步骤的用户信息项、问题集的所有问题序列及对应答案序列组成的数据集。
8.特别的,创建神经网络模型步骤中采用神经网络及机器学习训练方法具体为:(1)收集海量不同基础项的数据样本,并编译以用户信息项、问题集的所有问题序列结合对应答案序列组成的数据集;(2)将数据集转化为用户数据表;所述用户数据表包括若干个系数的1维张量;所述系数分别为用户信息项、问题集的所有问题序列及对应答案序列;(3)通过应用独热编码、删除虚拟变量对用户数据表进行预处理;预处理过程为将输入的1维张量系数增加到40个系数,然后将预处理后的数据反馈给cnn模型;所述cnn模型包括卷积层、扁平化层和全连接层;(4)将步骤(3)预处理后的数据输入卷积层输出特征图;(5)将步骤(4)获得的特征图输入扁平化层获得一维特征图;(6)将步骤(5)获得的一维特征图输入全连接层实现依据孤独症谱系障碍评定结的分类。
9.特别的,所述cnn模型由两个卷积层组成,两个卷积层分别有32个卷积核和64个卷积核组成;每一层卷积层连接一个最大池化层,所述最大池化层用于对每个卷积层获得的特征图进行下采样。
10.特别的,两个卷积层都对特征图应用了3
ꢀ×ꢀ
1的窗口,而下采样由大小为4
ꢀ×ꢀ
1的卷积核完成;所述卷积层没有步长,最大池化层的步长为2
ꢀ×ꢀ
2。
11.特别的,所述用户信息项包括年龄、性别、出生周数、过敏源、是否有黄疸,有无asd家族病史;所述基础项包括年龄。
12.特别的,所述孤独症谱系障碍评定结果包括孤独症轻度、孤独症中度和孤独症重度。
13.使用上述孤独症谱系障碍自助式筛查方法的系统,包括:自助式筛查终端,包括数据库、数据处理装置和神经网络模型模块;所述数据库用于存储题库和答案库;所述数据处理装置用于根据基本信息的基础项从题库筛选问题集;
所述数据处理装置用于将经过用户做题步骤获得的答题流水号、问题序号、答案序号存储至答题库,并将用户填写信息步骤获得的基础项、问题序号组成问题序列及对应答案序号组成为数据集后输入至神经网络模型;所述神经网络模型模块用于输出孤独症谱系障碍评定结果;用户终端,用于获取用户填写的基本信息,还用于生成答题流水号,获取用户填写问题集的每个问题的答案信息,并将答案信息转化为答案序号;用户及筛查终端交互装置,用于将用户填写的基本信息发送给自助式筛查终端,用于将自助式筛查终端筛选的问题集发送至用户终端,还用于将用户填写问题集的每个问题的答案信息和答案序号发送至自助式筛查终端。
14.本发明的有益效果如下所示:本发明与传统的筛查方式相比,本发明提出的一种孤独症谱系障碍自助式筛查方法主要基于机器学习进行自学习自诊断,比传统的筛查方法具有更高的准确性、敏感性和特异性,可以大大的减轻医院和诊疗人员的工作量,有可能改变未来孤独症谱系障碍筛查的新方式。目前市面上的有关孤独症筛查评估软件(如asdetect、asdtsets、awesomely aytistic等)大都采用了传统的筛查问卷方式进行评分,采用静态规则进行筛查过程和经典评分函数进行预测,这很容易受主观因素影响。而本发明开发的基于机器学习的孤独症筛查方法取代了传统筛查方法中的手动评分功能,利用卷积神经网络提高筛查的准确性,最大限度地减少主观影响。人工智能的应用能够让更多的医生诊断孤独症,从而突破儿童健康保健的关键瓶颈,缩短由首次担忧发育或行为到最终孤独症谱诊断的时间。
附图说明
15.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
16.图1为本发明实施例的流程图。
17.图2为本发明实施例的创建神经网络模型步骤中采用神经网络及机器学习训练方法的流程图。
具体实施方式
18.下面结合附图对本发明的优选实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
19.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
20.需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该实用新型产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本实用新型和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本实用新型的限制。此外,术语“第一”、“第二”、“第三”等仅用于区分描述,而不能理解为指
示或暗示相对重要性。
21.此外,术语“水平”、“竖直”、“悬垂”等术语并不表示要求部件绝对水平或悬垂,而是可以稍微倾斜。如“水平”仅仅是指其方向相对“竖直”而言更加水平,并不是表示该结构一定要完全水平,而是可以稍微倾斜。
22.如图1所示,本发明实施例一种孤独症谱系障碍自助式筛查方法,包括以下步骤:题库创建步骤,预设若干个基础项,建立题库;题库包括若干组问题集;每个问题集对应一个或多个基础项;所述问题集包括依据对应的基础项筛选的若干个用于孤独症谱系障碍诊断的问题,每个问题对应一个唯一的问题序列;答案库创建步骤,建立答案库;所述答案库用于存储答题流水号、问题序号、答案序号并使得答题流水号、问题序号、答案序号之间相互关联;创建神经网络模型步骤,采用神经网络及机器学习训练方法建立的神经网络模型;所述神经网络模型以用户信息项、问题集的所有问题序列结合对应答案序列组成的数据集为输入,以孤独症谱系障碍评定结果为输出。孤独症谱系障碍评定结果为孤独症类别;用户填写信息步骤,获取用户填写的基本信息。基本信息包括若干个用户信息项;所述用户信息项中含有基础项;用户信息项包括年龄、性别、出生周数、过敏源、是否有黄疸,有无asd家族病史;所述基础项包括年龄。
23.题库筛选步骤,根据基本信息的基础项从题库筛选问题集;用户做题步骤,生成答题流水号,获取用户填写问题集的每个问题的答案信息,并将答案信息转化为答案序号;数据处理步骤,将经过用户做题步骤获得的答题流水号、问题序号、答案序号存储至答题库,并将用户填写信息步骤获得的基础项、问题序号组成问题序列及对应答案序号组成为数据集。
24.数据处理步骤后的数据有效性判断步骤,数据有效性判断步骤为设定判断出没有任何孤独症谱系障碍的标准答案序号;若数据处理步骤的数据集中的答案序号与标准答案序号匹配或数据集中的答案序号的长度小于问题集中问题序列的长度则返回用户做题步骤;否则进行自助筛查步骤。
25.自助筛查步骤,将数据处理步骤获得的数据集输入至神经网络模型,输出孤独症谱系障碍评定结果。
26.数据反馈步骤,将自助筛查步骤的用户信息项、问题集的所有问题序列及对应答案序列组成的数据集。
27.如图2所示,创建神经网络模型步骤中采用神经网络及机器学习训练方法具体为:(1)收集海量不同基础项的数据样本,并编译以用户信息项、问题集的所有问题序列结合对应答案序列组成的数据集;(2)将数据集转化为用户数据表;所述用户数据表包括若干个系数的1维张量;所述系数分别为用户信息项、问题集的所有问题序列及对应答案序列;(3)通过应用独热编码(one-hot编码,作用:扩充特征)、删除虚拟变量对用户数据表进行预处理;预处理过程为将输入14个系数的1维张量系数增加到40个系数,然后将预处理后的数据反馈给cnn模型。cnn模型包括卷积层、扁平化层和全连接层;cnn模型由两个卷积层组成,两个卷积层分别有32个卷积核和64个卷积核组成;每一层卷积层连接一个最大
池化层最大池化层用于对每个卷积层获得的特征图进行下采样。两个卷积层都对特征图应用了3
ꢀ×ꢀ
1的窗口,而下采样由大小为4
ꢀ×ꢀ
1的卷积核完成。卷积层没有步长,最大池化层的步长为2
ꢀ×ꢀ
2。
28.(4)将步骤(3)预处理后的数据输入卷积层输出特征图;(5)将步骤(4)获得的特征图输入扁平化层获得一维特征图;(6)将步骤(5)获得的一维特征图输入全连接层实现依据孤独症谱系障碍评定结的分类。孤独症谱系障碍评定结果包括孤独症轻度、孤独症中度和孤独症重度。
29.cnn模型是自适应的,即微调和一旦有一批新的用户数据可用,就进行再培训,从使用系统的新用户获取的新知识。
30.cnn模型的输出是与用户配置文件相关联的asd可能性,其中cnn模型通过web服务将预测结果返回给用户。
31.使用上述孤独症谱系障碍自助式筛查方法的系统,包括:自助式筛查终端,包括数据库、数据处理装置和神经网络模型模块;所述数据库用于存储题库和答案库;所述数据处理装置用于根据基本信息的基础项从题库筛选问题集;所述数据处理装置用于将经过用户做题步骤获得的答题流水号、问题序号、答案序号存储至答题库,并将用户填写信息步骤获得的基础项、问题序号组成问题序列及对应答案序号组成为数据集后输入至神经网络模型;所述神经网络模型模块用于输出孤独症谱系障碍评定结果;用户终端,用于获取用户填写的基本信息,还用于生成答题流水号,获取用户填写问题集的每个问题的答案信息,并将答案信息转化为答案序号;用户及筛查终端交互装置,用于将用户填写的基本信息发送给自助式筛查终端,用于将自助式筛查终端筛选的问题集发送至用户终端,还用于将用户填写问题集的每个问题的答案信息和答案序号发送至自助式筛查终端。
32.虽然结合附图描述了本发明的实施方式,但是专利所有者可以在所附权利要求的范围之内做出各种变形或修改,只要不超过本发明的权利要求所描述的保护范围,都应当在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。