1.本发明属于司法审判技术领域,具体涉及基于深度学习技术的减刑刑期预测方法。
背景技术:
2.本发明基于多文档注意力机制模型构建减刑预测识别模型,根据基础的减刑文书文档信息,再迁移 结合有关减刑犯罪的其他文书文档信息,来预测减刑刑期,这更加符合现实中的减刑判刑的逻辑,更加 精确有效地预测减刑刑期。
3.
技术实现要素:
4.本发明的目的在于提供一种能够客观、正确预测减刑刑期的方法。
5.本发明提供的预测减刑刑期的方法,是基于深度学习技术的,具体利用多文档注意力 机制构建减刑预测模型,根据基础的减刑文书文档信息,再迁移结合有关减刑犯罪的其他 文书文档信息,来预测减刑刑期;
6.为了让深度学习模型能跨文档结合更多的信息,实现更精确地预测减刑刑期的需求, 本发明通过设计新的跨文档刑期预测模型,通过文档分类的阶层注意力网络 (hierarchical attention networks for document classification)
1.中的局部上下文 向量机制,基于减刑文书的主要内容,迁移联合犯罪文书、法条依据的内容,更好地对减 刑刑期进行预测识别。本发明的模型可以训练部署在服务器上,可以使用接口调用模型进 行预测。
7.具体步骤如下:
8.(一)收集数据和预处理
9.首先,收集减刑文书数据、及其对应的犯罪文书数据、关键法条依据,并进行预处理。
10.预处理包括:
11.(1)正则匹配:根据减刑判刑时提交的主要材料——《罪犯减刑(假释)审核表》, 将其与文书内容进行对照,确认文书中的罪名(crime)、原判刑期变动(judge)、改造 表现(performance)、犯罪事实(fact)、法条依据(article)这几个部分是决定减刑 刑期的关键部分。由于文书格式有一定的标准,可以通过编写规则的方式,利用正则匹配 提取相应数据。分别对减刑文书文档和对应的犯罪文书文档提取这些关键信息,获得模型 需要的数据。
12.(2)数据清洗:将文本中多次重复提到的、与预测减刑刑期无关的词、句,通过正则 匹配的方式删除;将中文数字转为阿拉伯数字;删除清洗后的空白数据。
13.(3)分词:对于清洗完成的数据,可以有两种处理:分字符或分词并去除停用词。
14.(二)设计模型文本编码器
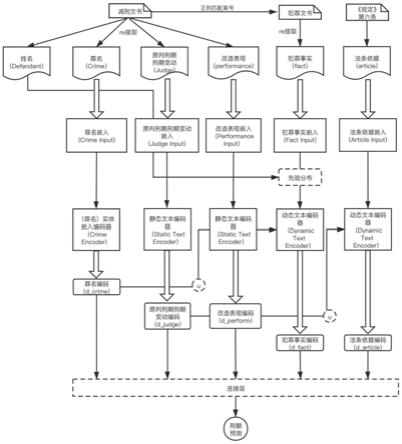
15.多文档减刑刑期预测模型的主要部分是文本编码器(text encoder),由三部分组成, 分别是:静态文本编码器(static text encoder)、(罪名)实体嵌入编码器(crime encoder)、 动态文本编码器(dynamic text encoder)。文本编码器的功能是输入罪名、原判刑期刑 期变动、改造表现、犯罪事实、法条依据,相应的编码器生成编码向量——d
crime
、d
judge
、 d
performance
、d
fact
、d
article
;
16.a)静态文本编码器
17.静态文本编码器(static text encoder)采用阶层注意网络模型(hierarchicalattention networks for document classification)
1.。原判刑期刑期变动(judge)和 改造表现(performance)段落文档将通过静态文本编码器(statictext encoder)生成 表示向量,其中模型中使用到了全局级别的上下文向量(context vectors),用于选择 有丰富信息的词和句子,就是图1中所示的u。
18.下面介绍具体内容:
19.所述阶层注意网络模型由几个部分组成:(1)词序列编码器;(2)词级注意力层; (3)句子编码器;(4)句子级注意力层;各个部分的具体解释如下:
20.假设文书某文本具有l个句子,sentence
i
代表第i个句子,第i个句子中包含t
i
个单词, word
it
(i∈[1,l],t∈[1,t
i
])代表第i个句子中的第t个单词。阶层注意网络模型能够将各个文 书原始文本映射到向量表示中。其中:
[0021]
(1)词序列编码器(word encoder)
[0022]
对句子进行预处理,可以采用嵌入矩阵将单词转为词向量,再通过双向gru层来获得 该单词的上下文表示。
[0023]
其中,编码部分可以引入bert预训练,使得模型可以迁移学习其他文本的词和句子的 信息,优化一些词和句子向量的表示程度,进一步提升模型准确率。
[0024]
对于第i个句子,句子的词编码过程用公式表示如下:
[0025]
x
it
=w
we
word
it
,t∈[1,t
i
];
[0026][0027][0028]
其中,word
it
为第i个句子中的第t个单词的独热(one
‑
hot)编码表示,第i个句子 单词长度为t
i
,w
we
代表嵌入向量,得到的x
it
即为第i个句子中的第t个单词的预训练向 量表示。和为双向gru层的结果,为第i个句子中的第t个单词的隐向量表示。
[0029]
(2)词级注意力层(word attention)
[0030]
并非所有单词对句子语义的表示都有同等作用。因此,引入注意力机制来提取对句子 语义表示重要的词,并汇总这些词的表示以形成句子向量。首先将文本中第i个句子中的 第t个单词的隐向量表示通过单层全连接层,获取作为第i个句子中的第t个单词的学习 表示u
it
;然后初始化一个代表单词级别的上下文向量u
w
,通过计算第i个句子中的第t 个单词与单词级别的上下文向量的相似性,并进行softmax归一化,得到一个能够测量该 第t单词在其所在的第i个句子中的重要性程度α
it
。之后,计算基于权重的单词表示的加 权来获得句子向量s
i
。其中,上下文向量u
w
被视为固定问题的“高级表示”,即“哪些是 有用的
单词”,模型在训练过程中随机初始化并联合学习单词上下文向量u
w
;
[0031]
具体过程用公式表示如下:
[0032]
u
it
=tanh(w
wa
h
it
b
wa
);
[0033][0034][0035]
其中,w
wa
和b
wa
分别为单层全连接层的权值参数和偏置参数;h
it
是由上述(1)部分 提到的双向gru层获得的第i个句子中的第t个单词的隐向量;u
it
代表通过单层全连接层 获得的第i个句子中的第t个单词的表示。u
w
代表单词级别的上下文向量;α
it
代表第i 个句子中的第t个单词占第i个句子所有t
i
单词中的权重。s
i
表示综合第i个句子中t
i
个单 词向量,计算得到的第i个句子的向量表示。
[0036]
(3)句子编码器(sentence encoder)
[0037]
句子级别编码和词级别编码采用类似的方法,对计算出的l个句子的表示向量进行双 向gru来获得每个句子的上下文表示,具体过程用公式表示如下:
[0038][0039][0040]
其中,s
i
是上文计算好的第i个句子的向量表示;和为双向gru层的结果,代表第 i个句子的隐向量表示。
[0041]
(4)句子级注意力层(sentence attention)
[0042]
句子级别注意力和词级别注意力采用类似的方法,首先通过单层全连接层,然后经过 句子界别的上下文向量u
s
计算得到第i个句子占文档的权重,通过最后得到文档向量d, 它总合了文档中句子的所有信息;
[0043]
具体过程用公式表示如下:
[0044]
u
i
=tanh(w
sa
h
i
b
sa
);
[0045][0046][0047]
其中,w
sa
和b
sa
分别为单层全连接层的权值参数和偏置参数,h
i
是由上述(2)部分提 到的双向gru层获得的第i个句子的隐向量;u
i
代表通过单层全连接层获得的第i个句子 的向量表示。u
s
代表句子级别的上下文向量,α
i
代表第i个句子占整个文档所有l个句子 中的权重。d表示综合整个文档所有l个句子向量获得的文档向量表示。
[0048]
d
judge
、d
performance
就是通过上述静态文本编码器的(1)
‑
(4)的所有文本编码步骤, 生成得到的代表原判刑期刑期变动和改造表现的编码向量。
[0049]
b)(罪名)实体嵌入编码器
[0050]
罪名是有限的、离散的实体数据,模型将一个罪名看作一个词,同样用独热(one
‑
hot) 编码表示罪名,可以借鉴文本编码的方式,将罪名编码成向量形式,输入到模型中。罪
得到的罪名、原判刑期刑期变动、改造表现的编码向量。和分别是犯罪事实 和法条依据单词级别的上下文向量;和分别是犯罪事实和法条依据句子级别的 上下文向量。
[0064]
动态文本编码器(dynamic text encoder)中犯罪事实(fact)和法条依据(article) 的上下文向量不是直接随机初始化,而是通过结合罪名(crime)、原判刑期刑期变动 (judge)、改造表现(performance)的关键信息获得上下文向量,进行训练学习。模型 能够关联提取该案件的犯罪事实、法条依据的相关信息,生成具有与减刑信息更相关的文 本编码——d
fact
、d
article
。
[0065]
(三)模型减刑刑期分布的确定
[0066]
最后,串联这些相关的文本信息编码d.,并通过一个softmax分类器来预测输入案件 的减刑刑期分布。
[0067]
d=concat(d
crime
,d
judge
,d
performance
,d
fact
,d
article
);
[0068]
p=softmax(w
c
d b
c
);
[0069]
其中,d.表示某一文本经过文本编码器得到的编码向量,d表示预测减刑刑期需要的 编码向量,w
c
和b
c
是单层全连接层的权值参数和偏置参数。
[0070]
采用交叉熵损失(categorical cross entropy)作为训练的损失:
[0071][0072]
其中,x表示输入样本,c为待分类的减刑刑期类别总数,y
i
为第i个类别对应的真实 减刑刑期标签类别,logf
i
(x)为对应的模型输出减刑刑期类别值。
[0073]
通过最小化交叉熵损失,训练模型参数,来获得可以预测减刑刑期分布的模型。
[0074]
本发明的有益效果是:
[0075]
提出了一种新的跨文书减刑预测模型,基于此模型可以更好地结合相关犯罪文书信息, 提高预测减刑刑期的准确度。
附图说明
[0076]
图1为本发明多文档减刑案件预测识别模型图示。
[0077]
图2为本发明实施部署图示。
具体实施方式
[0078]
实施例:减刑预测模型采用tensorflow2.0(keras)实现模型的训练和预测并基于 django部署,通过django admin为管理员提供模型管理配置的界面,为用户提供restfulapi接口以调用模型进行预测。
[0079]
如图2所示,模型部署分为训练端和预测端,训练端由研究人员部署好训练好的模型, 可以直接供预测使用;也允许后续管理员自行添加数据,进行远程训练。
[0080]
训练端首先需要新增一个配置的训练模型数据(对应django定义的dataset数据), 需要设置:模型名称、训练过程(定义一个得到模型的训练过程的基于keras的python 函数)、超参数(模型函数中所需要的超参数),若上传已训练好的模型,则上传:已训 练好的模型权重文件、已训练好的罪名词典、已训练好的原判信息词典、已训练好的改造 表现
词典、模型标签(训练好的模型对应数据的标签list),若是上传需要训练的模型, 则设置:batchsize(每轮训练中取训练集的大小)、epochs(训练的轮次)、verbose(是 否在服务器中可见训练的过程)、训练进度(训练过程中会同步修改训练进度百分比), 还需要再对该模型加入数据标签。数据标签可以通过批量、单个上传。批量上传文件类型 为csv文件。上传完成未训练模型配置和对应的数据集合之后,可以利用服务器对模型进 行训练。
[0081]
预测端可以直接输入原始文书的pdf格式,也可以按要求输入文本内容,获取训练好 的模型结果。上传pdf格式文件,后台通过将pdf转换为txt格式文件,再经过基于规则 的正则匹配提取出模型需要的输入内容,之后再由模型得出减刑刑期预测结果;键入内容 信息,并且选择对应的训练好的模型,得出减刑刑期预测结果。
[0082]
参考文献:
[0083]
[1]yang,z.,et al.(2016).hierarchical attention networks for document classification.proceedings of the 2016conference of the north american chapter of the association for computational linguistics:human language technologies.
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。