1.本发明涉及一种基于语义融合表征的轨迹预测方法。
背景技术:
2.伴随着互联网、物联网技术的蓬勃发展,诞生了海量的轨迹数据。轨迹数据包含交通轨迹数据、人类活动轨迹数据以及其他可移动对象的轨迹数据。通过对轨迹数据的挖掘,可以获得移动对象的活动规律。
3.然而,针对汽车位置的预测,传统的方法过于单一,准确性不高。具体的,时间序列模型被广泛用于预测车辆的轨迹,比较有代表性的时间序列模型是rnn,lstm等。但是,当前轨迹预测模型缺乏对汽车轨迹点以及轨迹序列的语义融合表征,且传统的时间序列模型难以捕获轨迹点之间的相关性,因此模型的整体预测准确度不高。
4.因此,针对传统的方法缺乏对多模态轨迹数据的语义挖掘表征和轨迹点之间相关性信息的获取,本发明提出一种基于语义融合表征的轨迹预测方法。
技术实现要素:
5.本发明的目的是提供一种基于语义融合表征的轨迹预测方法,该方法能够更好地预测汽车在未来时间的位置和区域分布,提高预测车辆轨迹的准确性,使得驾驶员能够提前做出改变出行时间或出行轨迹,避免交通拥堵。
6.为了实现上述目的,本发明提供了一种基于语义融合表征的轨迹预测方法,所述方法包括:
7.步骤1:利用轨迹数据预处理方法,去除误差点和冗余点,并采用滑动窗口的对轨迹数据进行划分,形成带标签的轨迹序列;
8.步骤2:结合车辆的经纬度信息、时间信息、速度信息和方向信息,进行多维轨迹融合向量表征;
9.步骤3:利用自动编码器学习轨迹序列的深度特征,结合轨迹序列的原始特征,共同构建轨迹序列的语义表征;
10.步骤4:基于transformer的轨迹预测方法,通过多头自注意力机制和基于掩码的自注意力方法,学习轨迹间的相关性,进而实现轨迹的预测。
11.优选地,所述方法还包括步骤5:对轨迹预测模型进行验证。
12.优选地,步骤1包括:
13.步骤1.1:误差点去除;
14.设轨迹点pi和pj之间的时间间隔为δt1,空间距离为δd1;
15.设轨迹点pj和pk之间的时间间隔为δt2,空间距离为δd2;
16.设城市道路车辆驾驶速度上限为v
max
;
17.若满足条件:δd1》δt1*v
max
且δd2》δt2*v
max
,则判断轨迹点pj为误差点,应当去除;
18.步骤1.2:冗余点去除;
19.设轨迹点pi、pj、pk、pn之间的距离依次为δd1、δd2和δdn,设置圆半径阈值r=20m,若满足条件δd1《2*r,δd2《2*r且δdn《2*r,则认为车辆在时间段内位置基本保持不变,使用轨迹点p作为该区域内冗余点的等效点;其中,p的经纬度根据冗余区域内的平均值计算得到;
20.步骤1.3:轨迹序列形成;
21.采用基于滑动窗口对轨迹进行划分,在轨迹开始设置固定长度的滑动窗口,将窗口中最后一个轨迹点设为待预测位置点,其余轨迹点为训练特征,形成一条训练样本;窗口依次向前滑动一个位置,形成新的训练样本,分别加入到训练特征序列和标签序列中;当窗口达到轨迹序列最后一个位置提取轨迹点后,划分结束;具体的,在时间窗口tj,轨迹t={p1,p2,...,pn},将p1,p2,...,p
j-1
作为训练特征,pj作为该轨迹的下一个位置标签。
22.优选地,在步骤2中,设定多模态语义轨迹为traj(oi)={p1(oi),p2(oi),...,pn(oi)},其中,pn(oi)表示对象oi的第n个位置的轨迹语义信息,即pn(oi)={ln,tn,dn,in};其中,ln表示对象oi在第n个位置经纬度语义信息,tn表征时间语义信息,dn表征车辆的车速信息,in表征车辆的方向信息;
23.多维轨迹融合向量表征包括:
24.轨迹经纬度特征语义表征,包括对一定经纬度范围内形成的区域采用网格划分的方法进行表征,用于捕获经纬度特征的语义信息;
25.假设将网格划分为n段,则ln可表示为n
×
1维向量;同时,设计维度为d
l
×
n的转换向量e
l
,将ln转化为d
l
×
1的向量公式如下所示:
[0026][0027]
轨迹时间特征语义表征,包括对时间段采用网格划分的方法进行表征,用于捕获时间特征的语义信息;
[0028]
设定以小时为周期进行网格划分,将一小时划分为m段,则tn可表示为m
×
1维向量;同时,设计维度为d
t
×
m的转换向量e
t
,将tn转化为d
t
×
1的向量公式如下所示:
[0029][0030]
车辆速度信息语义表征,对应轨迹信息中所包含的速度信息,设定车速的离散值个数为v个;首先,将速度信息dn编码为一个v
×
1的向量,v表示当前数据集中离散速度值的个数;接着,使用维度为dd×
v转化矩阵ed将dn转换为公式如下所示:
[0031][0032]
车辆方向信息语义表征,对应轨迹中所包含的车辆方向信息,设定车辆方向信息的离散值个数为q个,则in的维度向量为q
×
1,使用维度为di×
q转化矩阵ei将in转换为公式如下所示:
[0033][0034]
至此,计算多维度轨迹语义pn(oi)公式如下:
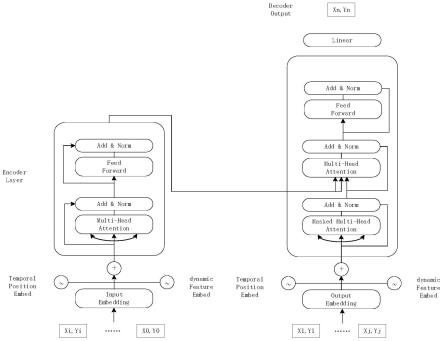
[0035]
[0036]
优选地,步骤3包括:
[0037]
步骤3.1:编码;
[0038]
采用encoder-decoder的自动编码器学习轨迹序列的深度特征,即将得到的多维度轨迹语义序列输入到自动编码器的encoder部分,隐藏层的更新方式如下公式所示:
[0039]hi
=f
encoder
(h
i-1
,bi)
[0040]
其中,f
encoder
表示自动编码器的encoder函数,bi表示轨迹点的语义输入;
[0041]
步骤3.2:解码;
[0042]
步骤3.1中encoder的隐藏层最终输出hi将代表整个轨迹序列,将作为解码器lstm的初始隐藏层,得到输出序列{c1,c2,...,ci},解码器的隐藏层更新如下公式所示:
[0043]
h'i=f
decoder
(h'
i-1
,c
i-1
)
[0044]
其中,f
decoder
表示自动编码器的decoder函数,c
i-1
表示解码器的输出;
[0045]
步骤3.3:解码器的学习目标为编码器的输入,编码器和解码器通过最小误差,误差采用函数如下:
[0046][0047]
经过训练编码器的输出可以有效表示输入数据,即输出信息中包含了轨迹序列的深度特征信息。
[0048]
优选地,步骤4包括轨迹预测模型编码训练和轨迹预测模型解码训练。
[0049]
优选地,在轨迹预测模型编码训练中,假设轨迹序列的表征向量为t=(t1 t2 ... tn),其中,n为轨迹点的个数,ti为每个轨迹点的语义表征,轨迹序列的输入需要在序列结束加一个《/s》,设定序列的长度为f,对于轨迹序列长度不足f的,通过padding方式使其长度为f;同样,对输出序列的起始位置添加《s》,结尾位置添加《/s》,设定轨迹的输出预测序列长度为m;包括:
[0050]
首先,训练时采用batch的方式进行,设定batch的大小为b,则输入的轨迹序列维度(b,f),设定轨迹编码和位置编码的维度相同且均为e,在经过trajectory embedding和position embedding之后,此时的向量维度为(b,f,e);
[0051]
其次,将embedding之后的向量维度从(b,f,e)调整为(b*f,e),接着使用该向量构建query,key,value矩阵,使其维度均为(b*f,e);然后重新转置query,key,value矩阵的维度从(b*f,e)到(b,f,e);由于采用多头注意力机制,设定头的个数为n,且n*h=e,那么query,key,value被划分为(b,f,n,h),根据query,key,value计算得到attention得分scores,公式如下:
[0052][0053]
最后使用scores得分和value矩阵计算得到attention向量;
[0054]
在得到attention向量之后,获取的输入维度为(b,f,e),输入到全连接层中,中间隐变量的维度设置为d,序列中不同的词乘以权重矩阵(e,d),然后在乘以另一个权重矩阵(d,e),所以矩阵的最后维度为(b,f,e);经过其余5层encoder之后,最终获得的encoder输出为(b,f,e)。
[0055]
优选地,在轨迹预测模型解码训练中,训练过程的decoder,接受的输入序列为(b,t),对其进行轨迹编码和位置编码,该轨迹编码和位置编码与encoder中的是同一组权值矩阵;包括:
[0056]
首先,对输入序列经过轨迹编码和位置编码之后,得到的矩阵维度为(b,t,e),使用掩码的多头注意力机制进行编码;掩码的多头注意力与自注意力网络的结构相同,但增加了一个mask矩阵,用于对训练时的输入的完整的序列t添加mask矩阵来掩盖未来信息;
[0057]
其次,在经过多头注意力机制之后,decoder编码的信息需要与encoder编码的信息进行注意力计算,从encoder编码的信息中获取key和value向量,从decoder内部序列变量构建query向量,然后进行attention操作;将decoder重复5次相同的结构,得到最终的输出序列嵌入表示为(b,t,e);
[0058]
然后,将decoder输出的(b,t,e)向量接入全连接层到区域表的logits空间,变成(b,t,z);其中,z是区域表的大小;将logits向量接一层softmax得到概率,根据概率得到预测序列,对预测序列与目标序列使用交叉熵损失函数计算损失函数值,然后开启参数优化过程。
[0059]
优选地,步骤5包括:
[0060]
将待预测的轨迹序列输入到encoder里面,得到一个encoder编码向量(f,e),然后在decoder里面输入开始标记《s》的单个元素序列,预测出下一个轨迹区域t1,然后将《s》与t1拼接起来,作为decoder的输入序列,继续预测下一个轨迹区域,直到预测出来的序列有《/s》为止。
[0061]
根据上述技术方案,本发明在分析现有车辆轨迹数据基础之上,对数据进行预处理,剔除轨迹数据中的误差点和冗余点,并形成轨迹序列数据,接着提出一种多模态语义融合表征方法,融合车辆的位置、时间、速度和方向信息,最后采用基于transformer的轨迹预测方法,实现车辆的轨迹预测,与现有方法比,本发明提出的基于语义融合表征的transformer轨迹预测方法,可以融合多模态的轨迹语义表征,通过提取轨迹之间的相关性,有效实现轨迹预测方法。
[0062]
本发明的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
[0063]
附图是用来提供对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明,但并不构成对本发明的限制。在附图中:
[0064]
图1是本发明中自动编码器学习轨迹深度特征的示意图;
[0065]
图2是本发明中基于transformer的轨迹预测方法的流程图。
具体实施方式
[0066]
以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
[0067]
本发明提供一种基于语义融合表征的轨迹预测方法,所述方法包括:
[0068]
步骤1:利用轨迹数据预处理方法,去除误差点和冗余点,并采用滑动窗口的对轨迹数据进行划分,形成带标签的轨迹序列;
[0069]
步骤2:结合车辆的经纬度信息、时间信息、速度信息和方向信息,进行多维轨迹融合向量表征;
[0070]
步骤3:利用自动编码器学习轨迹序列的深度特征,结合轨迹序列的原始特征,共同构建轨迹序列的语义表征;
[0071]
步骤4:基于transformer的轨迹预测方法(如图2所示),通过多头自注意力机制和基于掩码的自注意力方法,学习轨迹间的相关性,进而实现轨迹的预测。
[0072]
其中,步骤1包括:
[0073]
步骤1.1:误差点去除;
[0074]
设轨迹点pi和pj之间的时间间隔为δt1,空间距离为δd1;
[0075]
设轨迹点pj和pk之间的时间间隔为δt2,空间距离为δd2;
[0076]
设城市道路车辆驾驶速度上限为v
max
;
[0077]
若满足条件:δd1》δt1*v
max
且δd2》δt2*v
max
,则判断轨迹点pj为误差点,应当去除;
[0078]
步骤1.2:冗余点去除;
[0079]
设轨迹点pi、pj、pk、pn之间的距离依次为δd1、δd2和δdn,设置圆半径阈值r=20m,若满足条件δd1《2*r,δd2《2*r且δdn《2*r,则认为车辆在时间段内位置基本保持不变,使用轨迹点p作为该区域内冗余点的等效点;其中,p的经纬度根据冗余区域内的平均值计算得到;
[0080]
步骤1.3:轨迹序列形成;
[0081]
本发明的研究目标是预测轨迹的下一个位置,直接使用轨迹的最后一个位置作为标签不利于轨迹的预测结果。因此,本发明采用基于滑动窗口对轨迹进行划分,在轨迹开始设置固定长度的滑动窗口,将窗口中最后一个轨迹点设为待预测位置点,其余轨迹点为训练特征,形成一条训练样本;窗口依次向前滑动一个位置,形成新的训练样本,分别加入到训练特征序列和标签序列中;当窗口达到轨迹序列最后一个位置提取轨迹点后,划分结束;具体的,在时间窗口tj,轨迹t={p1,p2,...,pn},将p1,p2,...,p
j-1
作为训练特征,pj作为该轨迹的下一个位置标签。
[0082]
在步骤2中,设定多模态语义轨迹为traj(oi)={p1(oi),p2(oi),...,pn(oi)},其中,pn(oi)表示对象oi的第n个位置的轨迹语义信息,即pn(oi)={ln,tn,dn,in};其中,ln表示对象oi在第n个位置经纬度语义信息,tn表征时间语义信息,dn表征车辆的车速信息,in表征车辆的方向信息;
[0083]
多维轨迹融合向量表征包括:
[0084]
轨迹经纬度特征语义表征,包括对一定经纬度范围内形成的区域采用网格划分的方法进行表征,用于捕获经纬度特征的语义信息;
[0085]
假设将网格划分为n段,则ln可表示为n
×
1维向量;同时,设计维度为d
l
×
n的转换向量e
l
,将ln转化为d
l
×
1的向量公式如下所示:
[0086][0087]
轨迹时间特征语义表征,包括对时间段采用网格划分的方法进行表征,用于捕获时间特征的语义信息;
[0088]
设定以小时为周期进行网格划分,将一小时划分为m段,则tn可表示为m
×
1维向量;同时,设计维度为d
t
×
m的转换向量e
t
,将tn转化为d
t
×
1的向量公式如下所示:
[0089][0090]
车辆速度信息语义表征,对应轨迹信息中所包含的速度信息,设定车速的离散值个数为v个;首先,将速度信息dn编码为一个v
×
1的向量,v表示当前数据集中离散速度值的个数;接着,使用维度为dd×
v转化矩阵ed将dn转换为公式如下所示:
[0091][0092]
车辆方向信息语义表征,对应轨迹中所包含的车辆方向信息,设定车辆方向信息的离散值个数为q个,则in的维度向量为q
×
1,使用维度为di×
q转化矩阵ei将in转换为公式如下所示:
[0093][0094]
至此,计算多维度轨迹语义pn(oi)公式如下:
[0095][0096]
步骤3包括:
[0097]
步骤3.1:编码;
[0098]
采用encoder-decoder的自动编码器学习轨迹序列的深度特征,自动编码器结构如图1所示。将得到的多维度轨迹语义序列输入到自动编码器的encoder部分,隐藏层的更新方式如下公式所示:
[0099]hi
=f
encoder
(h
i-1
,bi)
[0100]
其中,f
encoder
表示自动编码器的encoder函数,bi表示轨迹点的语义输入;
[0101]
步骤3.2:解码;
[0102]
步骤3.1中encoder的隐藏层最终输出hi将代表整个轨迹序列,将作为解码器lstm的初始隐藏层,得到输出序列{c1,c2,...,ci},解码器的隐藏层更新如下公式所示:
[0103]
h'i=f
decoder
(h'
i-1
,c
i-1
)
[0104]
其中,f
decoder
表示自动编码器的decoder函数,c
i-1
表示解码器的输出;
[0105]
步骤3.3:解码器的学习目标为编码器的输入,编码器和解码器通过最小误差,误差采用函数如下:
[0106][0107]
经过训练编码器的输出可以有效表示输入数据,即输出信息中包含了轨迹序列的深度特征信息。
[0108]
步骤4包括轨迹预测模型编码训练和轨迹预测模型解码训练。其中,模型分为encoder和decoder两部分,训练时encoder和decoder分别接受了不同的输入。
[0109]
具体的,在轨迹预测模型编码训练中,假设轨迹序列的表征向量为t=(t1 t2 ... tn),其中,n为轨迹点的个数,ti为每个轨迹点的语义表征,轨迹序列的输入需要在序列结束加一个《/s》,设定序列的长度为f,对于轨迹序列长度不足f的,通过padding方式使其长度
为f;同样,对输出序列的起始位置添加《s》,结尾位置添加《/s》,设定轨迹的输出预测序列长度为m;包括:
[0110]
首先,训练时采用batch的方式进行,设定batch的大小为b,则输入的轨迹序列维度(b,f),设定轨迹编码和位置编码的维度相同且均为e,在经过trajectory embedding和position embedding之后,此时的向量维度为(b,f,e);
[0111]
其次,将embedding之后的向量维度从(b,f,e)调整为(b*f,e),接着使用该向量构建query,key,value矩阵,使其维度均为(b*f,e);然后重新转置query,key,value矩阵的维度从(b*f,e)到(b,f,e);由于采用多头注意力机制,设定头的个数为n,且n*h=e,那么query,key,value被划分为(b,f,n,h),根据query,key,value计算得到attention得分scores,公式如下:
[0112][0113]
最后使用scores得分和value矩阵计算得到attention向量;
[0114]
在得到attention向量之后,获取的输入维度为(b,f,e),输入到全连接层中,中间隐变量的维度设置为d,序列中不同的词乘以权重矩阵(e,d),然后在乘以另一个权重矩阵(d,e),所以矩阵的最后维度为(b,f,e);经过其余5层encoder之后,最终获得的encoder输出为(b,f,e)。
[0115]
在轨迹预测模型解码训练中,训练过程的decoder,接受的输入序列为(b,t),对其进行轨迹编码和位置编码,该轨迹编码和位置编码与encoder中的是同一组权值矩阵;包括:
[0116]
首先,对输入序列经过轨迹编码和位置编码之后,得到的矩阵维度为(b,t,e),使用掩码的多头注意力机制进行编码;掩码的多头注意力与自注意力网络的结构相同,只是增加了一个mask矩阵,本质上是对未来信息的遮掩,训练时的输入是一个完整的序列t,需要添加mask矩阵用以掩盖未来信息。
[0117]
其次,在经过多头注意力机制之后,decoder编码的信息需要与encoder编码的信息进行注意力计算,从encoder编码的信息中获取key和value向量,从decoder内部序列变量构建query向量,然后进行attention操作;将decoder重复5次相同的结构,得到最终的输出序列嵌入表示为(b,t,e);
[0118]
然后,将decoder输出的(b,t,e)向量接入全连接层到区域表的logits空间,变成(b,t,z);其中,z是区域表的大小;将logits向量接一层softmax得到概率,根据概率得到预测序列,对预测序列与目标序列使用交叉熵损失函数计算损失函数值,然后开启参数优化过程。
[0119]
进一步的,该方法还包括步骤5:对轨迹预测模型进行验证,包括将待预测的轨迹序列输入到encoder里面,得到一个encoder编码向量(f,e),然后在decoder里面输入开始标记《s》的单个元素序列,预测出下一个轨迹区域t1,然后将《s》与t1拼接起来,作为decoder的输入序列,继续预测下一个轨迹区域,直到预测出来的序列有《/s》为止。
[0120]
以上结合附图详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简
单变型,这些简单变型均属于本发明的保护范围。
[0121]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
[0122]
此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。