1.本发明属于文本处理技术领域,特别是关于一种基于大数据的文本乱码自动识别方法及系统。
背景技术:
2.在互联网带来的海量文件中,可用信息资源得到了极大的丰富。人们迫切需要从海量的非结构化文件中通过实体识别或别的信息抽取技术获得有用信息。这就需要确定该数据是不是乱码,如果数据不是乱码,就可以进行编码判断与转换、语言判断、实体识别、关系提取、标签抽取、事件抽取等操作,以此来获得有用信息,并对信息进行分析。如果数据是乱码,则进行编码判断与转换、语言判断、实体识别等操作时,就无法进行下去,或者返回不可预知的结果。文件的乱码判断在信息抽取和自然语言处理领域具有重要的作用。
3.乱码指的是终端设备不能显示正确的字符,而显示其他无意义的字符或空白。由于各种原因,电子文本在处理、传输、存储、转换过程中可能产生乱码,影响了用户对文本的阅读,也妨碍了对数据的进一步使用,是一种数据质量问题,识别乱码是文本大数据质量检查的重要问题。
4.乱码出现的形式多种多样,无法用统一的模式描述,也无法用一个有限的乱码表及其组合来限定,在此前的文献中未公开过识别自由文本中乱码的有效方法。
技术实现要素:
5.本发明的目的在于提供一种基于大数据的文本乱码自动识别方法及系统,其能够解决自由文本中乱码识别效率低的技术问题。
6.本发明提供了一种基于大数据的文本乱码自动识别方法,包括以下步骤:
7.s1,利用n-gram语言模型对多篇标准文本进行分词筛选,得到n-gram字典;
8.s2,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码;若否,则判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章;或
9.判断待测文本是否含有连续中文非常用字,若是则判断为中文字符乱码;若否,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码,若否,则判断该待测文本为正常文章。
10.优选地,所述步骤s2还包括:先去除所有非中文字符,并将所有繁体字转化为简体字,进行n-gram切割;
11.然后判断是否含有三个及以上的n-gram字典的内容,若否则判断为中文字符乱码,若是则判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码,若否,则判断该待测文本为正常文章。
12.优选地,所述中文字符乱码包括古文码、问句码和锟拷码;
13.所述拉丁语乱码包括口字码、符号码和拼音码。
14.优选地,所述标准文本包括搜集而来的正常词。
15.优选地,所述s1具体包括:建立多篇标准文本的集合,对所述集合进行分句,然后进行n元切分得到n元序列的集合,统计各序列出现的频率,按从多到少排序,选择前x%序列,或者出现次数不小于k的序列,作为第一序列集合;然后将待检测文本与所述第一序列集合对比,判断是否为乱码文本。
16.优选地,所述s2还包括:通过运用假名在待测文本中的比例来筛选日语文章,筛选出的日语文章为正常文章。
17.本发明还提供了一种用于实现基于大数据的文本乱码自动识别的系统,包括:
18.分词模块,利用n-gram语言模型对多篇标准文本进行切割和统计,得到n-gram字典;
19.拉丁语乱码判断模块,用于判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码;
20.中文字符乱码判断模块,用于判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章。
21.本发明还提供了一种电子设备,包括存储器、处理器,所述处理器用于执行存储器中存储的计算机管理类程序时实现基于大数据的文本乱码自动识别方法的步骤。
22.本发明还提供了一种计算机可读存储介质,其上存储有计算机管理类程序,所述计算机管理类程序被处理器执行时实现基于大数据的文本乱码自动识别方法的步骤。
23.与现有技术相比,根据本发明的一种基于大数据的文本乱码自动识别方法及系统,其中方法包括:s1,利用n-gram语言模型对多篇标准文本进行分词筛选,得到n-gram字典;s2,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码;若否,则判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章;或,判断待测文本是否含有连续中文非常用字,若是则判断为中文字符乱码;若否,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码,若否,则判断该待测文本为正常文章。采用基于大数据生成文本的高频n-gram集合,来判断文本是否是乱码。可以适用于各个语种的文本检查。能快速解决中文的大部分乱码以及外文的拉丁语符号乱码。无需人工构建或者维护,能够自动维护系统。效率高,查全率高,节省大量人力。还可以通过分类建立各种语言的字典从而增加外文识别的准确性。自动、高效地识别海量文本中存在的乱码情况。
附图说明
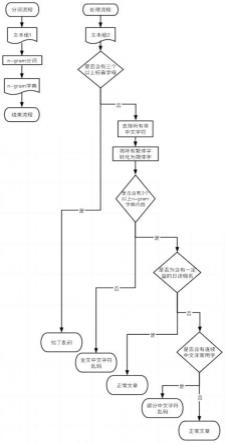
24.图1为本发明提供的一种基于大数据的文本乱码自动识别方法流程图;
25.图2为本发明提供的一种可能的电子设备的硬件结构示意图;
26.图3为本发明提供的一种可能的计算机可读存储介质的硬件结构示意图;
27.图4为本发明提供的一种基于大数据的文本乱码自动识别方法的中文字符乱码示例图。
具体实施方式
28.下面结合附图,对本发明的具体实施方式进行详细描述,但应当理解本发明的保
护范围并不受具体实施方式的限制。
29.除非另有其它明确表示,否则在整个说明书和权利要求书中,术语“包括”或其变换如“包含”或“包括有”等等将被理解为包括所陈述的元件或组成部分,而并未排除其它元件或其它组成部分。
30.如图1所示,根据本发明优选实施方式的一种基于大数据的文本乱码自动识别方法,包括:s1,利用n-gram语言模型对多篇标准文本进行分词筛选,得到n-gram字典;s2,判断待测文本是否有多个(实际应用中一般设定为三个或三个以上)连续音标字符,若是则判断为拉丁语乱码,若否进入到s3;s3,判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章。
31.其中,步骤s2与步骤s3可以互换,即还有另一种方案为:判断待测文本是否含有连续中文非常用字,若是则判断为中文字符乱码;若否,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码,若否,则判断该待测文本为正常文章。
32.采用基于大数据生成文本的高频n-gram集合,来判断文本是否是乱码。可以适用于各个语种的文本检查。能快速解决中文的大部分乱码以及外文的拉丁语符号乱码。无需人工构建或者维护,能够自动维护系统。效率高,查全率高,节省大量人力。还可以通过分类建立各种语言的字典从而增加外文识别的准确性。自动、高效地识别海量文本中存在的乱码情况。
33.优选的方案,步骤s2还包括:先去除所有非中文字符,并将所有繁体字转化为简体字,然后判断是否含有多个n-gram字典的内容,若否则判断为中文字符乱码。具体地,首先去除所有非中文字符,并将所有繁体字转化为简体字。这步是在避免非中文字符和繁体字的干扰,为准确判断n-gram打下基础。接着,判断是否含有三个及其以上的n-gram字典内容。一篇正常的文章很长,理论上会包含与文章长度类似的全覆盖n-gram字典。但是为了提高效率,我们认为,一篇正常的文章应该至少包含三个以上高词频的n-gram字典内容。故,如果该文章无法达到这个标准,则表示该文章词义不通,存在全文乱码现象。如果文章可以达到此标准,则需要查看其是否为日语文章。
34.具体地,本发明实施例方案主要包括四个步骤:
35.第一步,创建一个属于与需要筛选乱码类别相同的n-gram词典,因为n-gram库是筛选中文乱码最重要的一步。分词流程的主要目的是通过处理一组有关文本,得出n-gram字典,用于处理流程。需要建立多篇标准文本的集合,对其进行分句,然后进行n元切分,得到n元序列的集合,统计各个序列出现的频率,按从多到少排序,选择前x%序列,或者出现次数不小于k的序列,作为第一序列集合。传统的方式是需要乱码词典,本技术不需要乱码词典,可以无监督的进行。传统的乱码词典里存的都是基于经验判定的乱码,而n-gram词典不是特别挑选过的,不需要先验知识。
36.其中,标准文本能涵盖所有的文本乱码,这样就能建立完整的n-gram词典(库),避免漏掉文本乱码。
37.第二步,筛选拉丁语乱码。首先选择待测文本,选择与第一序列集合相同的文本,这样正常词语识别的准确率会大大提高。将第二文本组导入程序后,判断其是否有三个以上连续音标字符。通过这一步可以快速识别出拉丁语乱码,因为正常的拉丁系语言不会有此结构。
38.第三步,筛选中文字符乱码。首先去除所有非中文字符,也可以把所有繁体字转化为简体字,可以在避免非中文字符和繁体字的干扰,为准确判断n-gram打下基础。接着,判断是否含有三个及其以上n-gram字典内容。一篇正常的文章很长,理论上会包含与文章长度类似的全覆盖n-gram字典。但是为了提高效率,一篇正常的文章应该至少包含三个以上高词频的n-gram字典内容。故,如果该文章无法达到这个标准,则表示该文章词义不通,存在全文乱码现象。如果文章可以达到此标准,则需要查看其是否为日语文章。因为日语中含有大量的中文。
39.进一步地,通过运用假名在待测文本中的比例来筛选日语文章。筛选过后,筛选出的日语文章为正常文章(理论上可以用日语n-gram字典筛查日语乱码)最后一步则要筛选该文章有无中文的连续中文非常用字。因为乱码中存在大部分正常而只有一小段是乱码的现象。所以用连续中文常用字筛选可以快速找到文章中的小段部分乱码。最后通过测试则为正常文章。至此,三个乱码类别也被全部返回。
40.如图4所示,进一步的方案,文本乱码包括通过n-gram语言模型检测出的中文字符乱码和由拉丁无意义字符组成的拉丁语乱码。中文字符乱码包括古文码、问句码和锟拷码;拉丁语乱码包括口字码、符号码和拼音码。经过观察和测试,可以将文本乱码分为n-gram检测出的中文字符乱码(古文码、问句码和锟拷码)和由大量拉丁无意义字符组成的拉丁语乱码(口字码、符号码和拼音码)。
41.本发明实施例还提供了一种用于实现基于大数据的文本乱码自动识别的系统,包括以下步骤:
42.分词模块,利用n-gram语言模型对多篇标准文本进行切割和统计,得到n-gram字典;
43.拉丁语乱码判断模块,用于判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码;
44.中文字符乱码判断模块,用于判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章。
45.优选的方案,中文字符乱码判断模块还用于:先去除所有非中文字符,进行n-gram切分,然后判断是否含有多个(三个或三个以)上n-gram字典的内容,若否则判断为中文字符乱码,若是则进入到。
46.请参阅图2为本发明实施例提供的电子设备的实施例示意图。如图2所示,本发明实施例提了一种电子设备,包括存储器1310、处理器1320及存储在存储器1310上并可在处理器1320上运行的计算机程序1311,处理器1320执行计算机程序1311时实现以下步骤:s1,利用n-gram语言模型对多篇标准文本进行分词筛选,得到n-gram字典;
47.s2,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码;若否,则判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章;或
48.判断待测文本是否含有连续中文非常用字,若是则判断为中文字符乱码;若否,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码,若否,则判断该待测文本为正常文章。
49.请参阅图3为本发明提供的一种计算机可读存储介质的实施例示意图。如图3所
示,本实施例提供了一种计算机可读存储介质1400,其上存储有计算机程序1411,该计算机程序1411被处理器执行时实现如下步骤:s1,利用n-gram语言模型对多篇标准文本进行分词筛选,得到n-gram字典;
50.s2,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码;若否,则判断是否含有连续中文非常用字,若是则判断为中文字符乱码,若否则判断该待测文本为正常文章;或
51.判断待测文本是否含有连续中文非常用字,若是则判断为中文字符乱码;若否,判断待测文本是否有多个连续音标字符,若是则判断为拉丁语乱码,若否,则判断该待测文本为正常文章。
52.本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
53.本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
54.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
55.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
56.前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。