1.本发明涉及复杂网络分析技术领域,特别涉及一种基于社团密度优化的社群提取方法及系统。
背景技术:
2.社团密度用于评估社团稀疏性,社团密度的计算方法有很多种。kun等人提出基于节点相似性的社团密度,他们把社团内的节点相似性之和与社团的邻节点相似性之和的比值做为社团的密度。clauset等人将社团看作一个子图,社团满足内部边数大于外部边数,他们把社团密度定义为社团内部边数与内部边数以及外部边数之和的比值。cheng等人提出基于社团规模和社团稀疏性的社团密度。社团规模指社团包含节点个数与复杂网络节点个数的比值,社团稀疏性指社团内部边数与外部边数的比值,他们用社团规模与社团稀疏性的乘积来评估社团的密度。cheng等人定义的社团密度当复杂网络规模较大时容易将复杂网络中的小社团当作稀疏社团,筛选稀疏社团不准确,社团检测准确性低。
技术实现要素:
3.为解决上述现有技术中所存在的问题,本发明提供一种基于社团密度优化的社群提取方法及系统,在cea算法社团检测的基础上,通过重新定义筛选稀疏社团的社团密度,并提出基于社团密度优化的种子扩展社团检测算法d_sea(seed extended community detection algorithm based on community density optimization),提高了社团检测提取的准确性。
4.为了实现上述技术目的,本发明提供了一种基于社团密度优化的社群提取方法,包括:
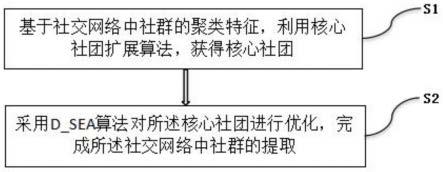
5.s1,基于社交网络中社群的聚类特征,利用核心社团扩展算法,获得核心社团;
6.s2,采用d_sea算法对所述核心社团进行优化,完成所述社交网络中社群的提取。
7.可选的,所述s2包括:
8.s21,设置稀疏性阈值,计算所述核心社团的稀疏性;
9.s22,选择所述稀疏性中的稀疏性最小社团,并计算与所述稀疏性最小社团相似性最大的社团,得到最大相似社团;
10.s23,合并所述稀疏性最小社团和所述最大相似社团,得到合并社团;
11.s24,重复执行所述s21-所述s23,直至所述合并社团的稀疏性大于所述稀疏性阈值,完成所述社交网络中社群的提取。
12.可选的,所述相似性的计算公式为:
[0013][0014]
式中,ci表示第i个社团,cj表示第j个社团,sim(u,v)表示杰卡德相似性,|ci|表示
社团ci的节点数,|cj|表示社团cj的节点数。
[0015]
可选的,所述稀疏性的计算公式为:
[0016][0017]
式中,γ
′i表示社团ci的稀疏性,表示社团ci的内部边,表示社团ci与其他社团连接的边数。
[0018]
本发明还提供了一种基于社团密度优化的社群提取系统,包括:核心社团模块和优化模块;
[0019]
所述核心社团模块用于基于社交网络中社群的聚类特征,利用核心社团扩展算法,获得核心社团;
[0020]
所述优化模块用于采用d_sea算法对所述核心社团进行优化,完成所述社交网络中社群的提取。
[0021]
可选的,所述优化模块包括:稀疏性单元、相似性单元、合并单元和提取单元;
[0022]
所述稀疏性单元用于设置稀疏性阈值,计算所述核心社团的稀疏性;
[0023]
所述相似性单元用于选择所述稀疏性中的稀疏性最小社团,并计算与所述稀疏性最小社团相似性最大的社团,得到最大相似社团;
[0024]
所述合并单元用于合并所述稀疏性最小社团和所述最大相似社团,得到合并社团;
[0025]
所述提取单元用于重复所述稀疏性单元、所述相似性单元和所述合并单元,直至所述合并社团的稀疏性大于所述稀疏性阈值,完成所述社交网络中社群的提取。
[0026]
可选的,所述相似性单元的计算公式为:
[0027][0028]
式中,ci表示第i个社团,cj表示第j个社团,sim(u,v)表示杰卡德相似性,|ci|表示社团ci的节点数,|cj|表示社团cj的节点数。
[0029]
可选的,所述稀疏性单元的计算公式为:
[0030][0031]
式中,γ
′i表示社团ci的稀疏性,表示社团ci的内部边,表示社团ci与其他社团连接的边数。
[0032]
本发明具有如下技术效果:
[0033]
在cea算法社团检测的基础上,通过重新定义筛选稀疏社团的社团密度,并提出基于社团密度优化的种子扩展社团检测算法d_sea,提高了社团检测的准确性。
附图说明
[0034]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施
例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0035]
图1为本发明实施例一基于社团密度优化的社群提取方法的流程框图;
[0036]
图2为本发明实施例一中稀疏性最小社团和最大相似社团的合并划分效果图;
[0037]
图3为本发明实施例一中d_sea算法及其对比算法在lfr5网络上的实验结果图;
[0038]
图4为本发明实施例一中d_sea算法及其对比算法在lfr6网络上的实验结果图;
[0039]
图5为本发明实施例一中d_sea算法及其对比算法在lfr7网络上的实验结果图;
[0040]
图6为本发明实施例一中d_sea算法及其对比算法在lfr8网络上的实验结果图。
具体实施方式
[0041]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
实施例一
[0043]
如图1所示,本发明公开一种基于社团密度优化的社群提取方法,包括:
[0044]
s1,基于社交网络中社群的聚类特征,利用核心社团扩展算法,获得核心社团。
[0045]
s2,采用d_sea算法对核心社团进行优化,完成社交网络中社群的提取。
[0046]
本发明定义社团相似性和社团密度。社团相似性用于评估社交网络中两个社团的等价程度,社团密度用于评估社团的稀疏性。
[0047]
s21,设置稀疏性阈值δ,计算核心社团的稀疏性;
[0048]
阈值δ的范围设置在[0,1]。
[0049]
cheng等人认为社团的稀疏性与社团的规模有关。cheng等人定义社团稀疏性的计算公式如下所示:
[0050][0051]
式中,γi表示cheng等人定义的社团ci的稀疏性,表示cheng等人定义的社团ci的内部边,表示cheng等人定义的社团ci与其他社团连接的边数,|vi|表示cheng等人定义的社团ci的节点的个数,|v|表示整个复杂网络的数量。其中,整个复杂网络节点的个数也是影响社团稀疏性的因素。当整个复杂网络节点个数较大时,|vi|与|v的比值就越小,因而筛选节点规模较小的社团时不准确,容易把小社团当作稀疏社团。因此,本实施例重新定义了社团稀疏性,重新定义后的社团稀疏性与社交网络的规模无关,不会把小社团筛选为稀疏社团,提高了筛选稀疏社团的准确性,本实施例重新定义的社团稀疏性计算公式如下:
[0052][0053]
式中,γ
′i表示社团ci的稀疏性,表示社团ci的内部边,表示社团ci与其他社团连接的边数。
[0054]
s22,选择稀疏性中的稀疏性最小社团,并计算与稀疏性最小社团相似性最大的社
团,得到最大相似社团;
[0055]
社团相似性与社团内的每个节点的相似性有关,采用杰卡德相似性来评估社团内节点的相似性,杰卡德相似性的计算公式为:
[0056][0057]
式中,n(i)表示节点i的邻节点,n(j)表示节点j的邻节点。
[0058]
社团相似性为两个社团之间节点相似性之和与这两个社团中规模较小的社团的节点数的比值,社团相似性的计算公式如下:
[0059][0060]
式中,ci表示第i个社团,cj表示第j个社团,sim(u,v)表示杰卡德相似性,|ci|表示社团ci的节点数,|cj|表示社团cj的节点数。
[0061]
s23,合并稀疏性最小社团和最大相似社团,得到合并社团;
[0062]
s1中核心社团扩展算法将社交网络划分为c1,c2,c3三个核心社团,通过s22中的公式(1)计算社团稀疏性可知:γ
′1=1.5,γ
′2=3,γ
′3=0,由此可知,c3为稀疏性最小社团,由s22中的公式(3)可知,sim(c1,c3)=0.278,sim(c2,c3)=0,因此,将c1和c3合并,得到合并社团,划分结果如图2所示。
[0063]
s24,重复执行s21-s23,直至合并社团的稀疏性大于稀疏性阈值,完成社交网络中社群的提取。
[0064]
由于lfr基准网络和真实网络数据集的拓扑特征不相同,lfr基准网络中的社团较稀疏。当稀疏性阈值δ为0.1时,d_sea算法在各个lfr网络上表现最优,因而本实施例在lfr网络中实验时将阈值δ设置为0.1。真实网络中社团的密度较大。在真实网络上实验时,本实施例将阈值固定在[0,1]范围内每次阈值增加0.1的实验发现,当阈值δ=0.7时d_sea算法在各个真实网络的效果较好,因而在真实网络实验时本章将阈值δ默认设置为0.7。
[0065]
本实施例将四组lfr基准网络命名为lfr5、lfr6、lfr7和lfr8。lfr5和lfr6网络的规模、节点的最大度以及社团的最大规模均相同,lfr6网络的平均度大于lfr5网络,lfr5网络中的最小社团小于lfr6网络。lfr7和lfr8网络的网络规模不同,其余参数设置相同。四组网络混合参数μ的取值范围都是[0.1,0.8]。
[0066]
本实施例采用模块度q(modularity)和标准化互信息nmi(normalized mutual information)作为评价指标。gn、louvain、lpa、walktrap、springlass和nsa算法为对比算法。
[0067]
d_sea算法及其对比算法在lfr5网络上的实验结果如图3所示:当μ≤0.3时d_sea算法与lpa算法和walktrap算法社团检测对应的nmi和q最优,nmi的值为1,q的值为0.7235。当μ》0.3时d_sea算法社团检测的nmi和q都在降低,由图3可知,d_sea算法的nmi和q均优于nsa算法,证明d_sea算法可以进一步提升种子扩展社团检测提取算法的准确性。
[0068]
d_sea算法及其对比算法在lfr6网络上的实验结果如图4所示:当μ≤0.3时d_sea算法与walktrap算法、gn算法、sea算法和nsa算法社团检测对应的nmi和q的值最大,nmi的值为1,q的值为0.6905。随着μ增大,d_sea算法社团检测的nmi和q都会降低,从图4整体上可知,d_sea算法社团检测的效果优于nsa算法,证明d_sea算法可以进一步提升种子扩展社团
检测提取算法的准确性。
[0069]
d_sea算法及其对比算法在lfr7网络上的实验结果如图5所示:当μ=0.1时d_sea算法社团检测的准确性优于springlass算法,但低于其他对比算法。当μ》0.2时d_sea算法社团检测的准确性在降低,nmi和q的值也在降低。当0.2≤μ《0.5时d_sea算法社团检测的nmi优于nsa算法。
[0070]
d_sea算法及其对比算法在lfr8网络上的实验结果如图6所示:从图6可知,d_sea算法社团检测的效果优于nsa算法,d_sea算法筛选稀疏社团的准确性不会随着网络规模的增加而降低。进一步提升了种子扩展算法社团检测提取的准确性。
[0071]
实施例二
[0072]
一种基于社团密度优化的社群提取系统,包括:核心社团模块和优化模块;核心社团模块用于基于社交网络中社群的聚类特征,利用核心社团扩展算法,获得核心社团;优化模块用于采用d_sea算法对所述核心社团进行优化,完成所述社交网络中社群的提取。
[0073]
优化模块包括:稀疏性单元、相似性单元、合并单元和提取单元;
[0074]
稀疏性单元用于设置稀疏性阈值,所述核心社团的稀疏性;稀疏性单元的计算公式为:
[0075][0076]
式中,γ
′i表示社团ci的稀疏性,表示社团ci的内部边,表示社团ci与其他社团连接的边数。
[0077]
相似性单元用于选择稀疏性中的稀疏性最小社团,并计算与稀疏性最小社团相似性最大的社团,得到最大相似社团;相似性单元的计算公式为:
[0078][0079]
式中,ci表示第i个社团,cj表示第j个社团,sim(u,v)表示杰卡德相似性,|ci|表示社团ci的节点数,|cj|表示社团cj的节点数。
[0080]
合并单元用于合并稀疏性最小社团和最大相似社团,得到合并社团;
[0081]
提取单元用于重复稀疏性单元、相似性单元和合并单元,直至合并社团的稀疏性大于所述稀疏性阈值,完成社交网络中社群的提取。
[0082]
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。