1.本发明涉及一种软件跨模态检索方法,具体涉及一种异构语义空间中基于假设检验的可以应用于多种任务的软件跨模态检索方法。
背景技术:
2.随着互联网技术与大数据系统的发展,软件开发过程中的软件数据逐渐被积累并存储在开源软件数据库中,其中比较有代表性的软件数据库包括代码版本管理数据库github、软件漏洞数据库nvd以及软件缺陷追踪数据库bugzilla等。利用软件仓库中积累的知识来指导软件开发,有助于降低软件开发与维护的周期,提高软件产品的质量和安全性。因此,为了充分利用软件数据库中的知识来指导软件工程的生产实践,软件信息检索领域在近几年受到了广泛的关注。其中,自然语言文本与代码间的软件跨模态检索(如缺陷定位、代码搜索等文本检索代码的任务,以及漏洞知识检索、补丁日志检索等代码检索文本的任务)是该领域中的热门研究方向之一。
3.关于软件跨模态检索的早期研究主要通过人工特征分别表示文本与代码,并通过计算二者的相似度来实现信息检索。但是该类方法更关注跨模态数据在词法等低级语义特征上的相似性,难以抽取文本和代码的深层语义重叠。为了解决这一问题,部分研究采用基于深度学习的特征提取模型,即通过自然语言编码网络和程序语言编码网络分别将文本和代码投影为同一语义空间中的两个不同的特征向量,并通过相似度度量函数(如余弦相似度或欧几里德距离)或二分类层(类别1为匹配,类别0为不匹配)来衡量文本和代码的相似性。但是,由于代码的上下文无关的文法类型以及数据流与控制流等特殊语法结构,其往往被认为与文本是不同模态的数据,因此在同一个语义空间中准确衡量二者的语义重叠是较为困难的。
4.此外,现有研究没有关注不同代码执行与文本相关性的区别。在软件跨模态检索任务中,文本往往和代码在不同输入条件下的具体执行有不同的相关性。例如,在缺陷(bug)定位任务中,bug仅会在某些特定的输入条件下的代码执行中被触发。由于bug报告往往是对代码中的bug的描述,因此可以认为其和存在bug的代码执行更相关。
5.目前,尚未检索到有文献在软件跨模态检索任务中将多模态数据投影到异构语义空间中,也未检索到有文献使用基于假设检验的深度学习模型在异构空间中计算异构数据的匹配分数。
技术实现要素:
6.本发明的目的是提供一种在异构语义空间中基于假设检验的软件跨模态检索方法(deepht),deepht将代码投影为样本空间中的cfp样本向量,将文本投影为分布空间中的cfp相关分布,并通过假设检验计算二者的匹配分数。本发明将文本和代码映射到异构的语义空间中,有利于提取文本和代码各自的独特语义,提高信息检索的精度。
7.本发明的目的是通过以下技术方案实现的:
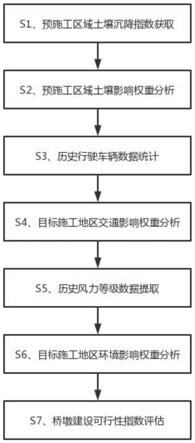
8.一种在异构语义空间中基于假设检验的软件跨模态检索方法,包括如下步骤:
9.步骤1:对文本和代码数据进行预处理;
10.步骤2:使用分布生成网络将文本表示为cfp相关分布;
11.步骤3:使用样本生成网络将代码表示为cfp样本向量集合;
12.步骤4:使用某种假设检验方法在异构语义空间中计算cfp样本向量集合和cfp相关分布的匹配分数;
13.步骤5:通过三元组损失函数和随机梯度下降算法优化分布生成网络和样本生成网络;
14.步骤6:使用步骤5训练好的分布生成网络和样本生成网络实现文本检索代码形式的跨模态检索任务;
15.步骤7:使用步骤5训练好的分布生成网络和样本生成网络实现代码检索文本形式的跨模态检索任务。
16.本发明提供了一种将多模态数据投影到异构的语义空间中,并在异构空间中构建统计学分布模型来建模不同代码执行和文本之间的相关性的方法。该方法被称为深度假设检验(deep hypothesis testing,deepht),“深度”指将假设检验理论转化为深度学习实现。deepht不仅有利于捕获代码在不同输入条件下的具体执行,还有利于区别不同具体执行与文本的相关性。具体地,对于代码的特征提取阶段,抽取其控制流图(control flow graph,cfg)上的每一条控制流路径(control flow path,cfp),其中每条路径都可以代表某一种具体的代码执行,并将每一条cfp映射为样本空间中的样本向量。对于文本的特征提取阶段,本发明将文本映射为分布空间中的多维正态分布(也称作cfp相关分布)用于建模每条cfp对文本的相关程度。相比于现有技术,本发明具有如下优点:
17.1、本发明首次提出将代码和文本投影到异构语义空间中进行表示学习,即将文本投影到cfp相关分布空间并将代码投影到cfp样本空间,相比现有的在同一语义空间中计算文本和代码表示的方法,其好处在于能够准确表征文本和代码各自的独特语义,提高跨模态检索的准确性。
18.2、本发明提出基于假设检验理论的深度学习模型,可以准确衡量cfp样本集合对cfp相关分布的服从程度,从而实现精准的跨语义空间的匹配分数计算。
19.3、本发明中提出的cfp相关分布可以用于区别不同代码执行与文本的相关程度。
20.4、本发明可以实现多种软件跨模态检索任务,包括文本检索代码(如缺陷定位和代码搜索等)和代码检索文本形式的跨模态检索任务(如漏洞知识检索和补丁日志检索等)。
21.5、与将文本和代码投影到同一语义空间的现有方法不同,本发明首次将代码和文本投影到异构的语义空间中。
附图说明
22.图1是本发明软件跨模态检索方法的总体流程图。
23.图2是以cve-2020-5331为例介绍文本预处理过程的实例图。
24.图3是以linux内核中的漏洞函数radeon_atom_tv_timings为例介绍代码预处理过程的实例图。
25.图4是以漏洞知识检索任务为例,以漏洞函数radeon_atom_tv_timings为查询,检索cve-2010-5331和cve-2020-15211构成的数据库中与之相关的cve的实例图。
具体实施方式
26.下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
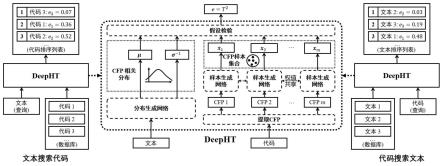
27.本发明提供了一种在异构语义空间中基于假设检验的软件跨模态检索方法,首先使用分布生成网络将文本投影到分布空间中的cfp相关分布,其次将代码表示为控制流图,并抽取其中所有的路径,然后利用样本生成网络将cfp映射为样本空间中的cfp样本向量,此时代码被表示为一个cfp样本向量集合,最后使用假设检验计算cfp样本向量集合对cfp相关分布的服从程度作为二者的匹配分数,并用于实现代码检索文本或文本检索代码形式的跨模态检索任务。如图1所示,所述方法具体包括如下步骤:
28.步骤1:对代码和文本进行预处理。
29.在文本检索代码的任务中,需要对文本查询以及数据库中的所有待检索代码进行预处理;在代码检索文本的任务中,需要对代码查询以及数据库中的所有待检索文本进行预处理。具体步骤如下:
30.步骤11:文本预处理。去除文本中的停用词、数字以及标点符号,拆分以驼峰命名法或下划线命名法出现的标识符,并对每一个词进行词性还原和小写化。
31.步骤12:提取代码中的cfp。对于文件粒度的搜索任务,首先基于下推自动机的函数文法分析器提取代码文件中的所有函数(函数粒度的检索任务跳过该步骤)。随后,对函数中的语句换行方式进行规范化。最后,将每一个函数都转化为cfg,并通过深度优先搜索提取其中的每一条cfp。通过上述过程可以将代码转化为一个cfp集合。
32.步骤13:cfp预处理。对cfp中以驼峰命名法或下划线命名法命名的标识符进行拆分,并对拆分后的token进行词性还原和小写化。
33.步骤2:使用深度学习模型将文本表示为cfp相关分布,该深度学习模型也被称作分布生成网络。
34.为了简化问题,本发明将cfp相关分布的协方差矩阵∑看作是一个对角线元素大于0而其他元素为0的对角阵,并将由其对角线元素构成的向量定义为σ2,由σ2中每个元素的平方根的倒数构成的向量定义为σ-1
。具体步骤如下:
35.步骤21:将文本中的单词表示为独热编码,并使用一个可训练的词嵌入层将文本中的每个单词表示为词嵌入向量;
36.步骤22:使用text-cnn网络(convolutional neural networks for sentence classification,2014)提取文本的语义向量表示;
37.步骤23:将该文本的语义向量表示送入激活函数为tanh的全连接层中生成期望向量μ并输出;
38.步骤24:将该文本的语义向量表示送入激活函数为sigmoid的全连接层中生成标准差倒数向量σ-1
并输出,生成的μ和σ2可以唯一地表示一个cfp相关分布n(μ,σ2)。
39.步骤3:使用深度学习模型将代码表示为cfp样本向量集合,该深度学习模型也被
称作样本生成网络。具体步骤如下:
40.步骤31:将给定的cfp中每条语句中的基本词法单元(token)都表示为独热编码,使用与步骤21中相同的可训练的词嵌入层将每个token表示为词嵌入向量。
41.步骤32:对于给定的cfp中的每条语句,使用多个不同卷积核大小的卷积神经网络(convolutional neural network,cnn)分别提取语句在不同感受野下的向量表示,并将不同感受野下的向量表示拼接,得到语句的向量表示。
42.步骤33:将cfp都表示为cfp样本向量。将cfp中语句的表示序列送入到长短期记忆网络(long short-term memory,lstm)中,使用每个时刻输出的平均作为cfp样本向量;
43.步骤34:对代码中的所有cfp执行步骤31-步骤33,从而将代码表示为一个cfp样本向量集合。
44.步骤4:通过假设检验计算cfp样本向量集合(即代码)对cfp相关分布(即文本)的服从程度,作为二者的匹配分数。
45.为了在异构的语义空间中衡量异构数据的相关性,本发明提出一种基于假设检验的深度学习模型(即深度假设检验)。该模型可以通过衡量cfp样本向量集合(即代码)对cfp相关分布(即文本)的服从程度来计算二者的匹配分数。假设检验在数理统计领域中被广泛应用于验证样本集合与分布是否存在某种关系,如判断样本集合是否服从分布,其一般流程为:
46.1)对事实做出假设,记作h0。
47.2)选择统计量s,且当假设h0成立时该统计量会服从于分布d。
48.3)基于待检验的分布或样本计算统计量s的观测值v。
49.4)对是否接受假设h0做出决策。由于当假设h0成立时统计量s服从于分布d,我们可以根据d计算s取值为v的概率p。如果p的值较小,表明在h0成立时会引起小概率事件的发生,即与假设h0成立相矛盾,此时应拒绝h0。反之,若p的值较大,则接受h0。
50.本发明以t2检验为例来介绍匹配分数的计算方法,也可以采用其他假设检验方法。具体步骤如下:
51.步骤41:做出零假设h0:e(x)=μ和另外一个可供选择的假设h1:e(x)=μ,其中x=[x1,x2,
…
,xn]为cfp样本向量集合,xi为第i个cfp样本向量,e(x)为x的均值,μ为cfp相关分布的期望向量。
[0052]
步骤42:选择统计量t2,有:
[0053][0054][0055]
其中,
⊙
表示哈达玛积。
[0056]
步骤43:根据t2检验的基本理论可知,当假设h0成立时,t2服从卡方分布,记作t2~χ2,采用左边检验,当显著性水平为α时有:
[0057][0058]
由于α的值往往较小,因此是一个小概率事件。如果假设h0成立导致该小概率事件的发生,可以认为采样检验的结果与假设h0成立相矛盾,因此应该拒绝假设h0并接
受假设h1。反之,当时则接受假设h0并拒绝假设h1。因此,本发明使用t2作为文本和代码的匹配分数e,当样本集合服从分布时e的取值比较小,反之取值比较大。
[0059]
步骤5:通过三元组损失函数和随机梯度下降算法优化分布生成网络和样本生成网络,使分布生成网络和样本生成网络学习如何生成cfp相关分布和cfp样本。具体步骤如下:
[0060]
步骤51:从训练集中不重复地取出一个mini-batch的正样本文本-代码对(简称为正样本对)。
[0061]
步骤52:对mini-batch中的每个正样本对通过负采样构造负样本对。具体地,将正样本对中的文本或代码随机替换为数据集中的另外一个文本或代码,使二者不再互相匹配,从而获得负样本对。
[0062]
步骤53:使用如下的三元组损失函数计算损失,并通过adam优化器反向更新网络参数:
[0063][0064]
其中,n为mini-batch中样本的数量,为其中第i个正样本对的匹配分数,为其中第i个负样本对的匹配分数,c为阈值超参数。
[0065]
步骤54:重复步骤51-步骤53,直到遍历完训练集中的所有样本对,此时完成一个epoch的训练过程。
[0066]
步骤55:重复步骤54,直到达到预定的最大迭代次数。取在验证集上取得最佳性能的参数作为训练好的模型参数。
[0067]
步骤6:使用训练好的分布生成网络和样本生成网络实现文本检索代码的软件跨模态检索。具体步骤如下:
[0068]
步骤61:使用样本生成网络将待检索的数据库中的每个代码都转化为cfp样本向量集合;
[0069]
步骤62:使用分布生成网络将文本查询转化为cfp相关分布;
[0070]
步骤63:使用假设检验计算cfp相关分布和每一个cfp样本向量集合的匹配分数;
[0071]
步骤64:将数据库中的所有代码按照匹配分数升序排序,并将排序列表的前n个结果返回给用户。
[0072]
步骤7:使用训练好的分布生成网络和样本生成网络实现代码检索文本的软件跨模态检索。具体步骤如下:
[0073]
步骤71:使用分布生成网络将待检索的数据库中的每个文本都转化为cfp相关分布;
[0074]
步骤72:使用样本生成网络将代码查询转化为cfp样本向量集合;
[0075]
步骤73:使用假设检验计算cfp样本向量集合和每一个cfp相关分布的匹配分数;
[0076]
步骤74:将数据库中的所有文本按照匹配分数升序排序,并将排序列表的前n个结果返回给用户。
[0077]
实施例1:
[0078]
以cve-2010-5331为例介绍文本的预处理过程。文本的预处理过程包括去停用词、数字和标点符号,拆分标识符,词性还原和小写化,如图2所示。
[0079]
实施例2:
[0080]
以漏洞代码片段为例介绍cfp集合的提取过程。首先将构建代码的cfg,并从cfg上抽取所有的cfp,具体过程如图3所示。
[0081]
实施例3:
[0082]
以漏洞知识搜索任务为例(使用漏洞函数作为查询,检索cve数据库中与之相关的漏洞描述)介绍使用假设检验进行跨模态检索的方法。具体地,以linux内核中的漏洞函数radeon_atom_tv_timings为查询,检索cve数据库中的相关cve。为了方便计算,假设cve数据库中只包含cve-2020-15211和cve-2010-5331两种漏洞。首先,对漏洞数据库中的第j个cve的文本描述,将其送入到分布生成网络中来生成μj和代表了一个cfp相关分布其次,对给定的代码查询,将其表示为cfp集合,并将其中的每个cfp分别送入到样本生成网络中以生成cfp样本向量(第i个cfp样本向量记作xi),从而将代码转化为cfp样本向量集合x=[x1,x2,
…
,xn]。最后,通过假设检验计算x对每一个cfp相关分布的匹配分数,根据该分数对数据库中所有的cve升序排序并输出,计算过程如图4所示。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。