1.本说明书一般涉及语音处理。
背景技术:
2.语音处理是对语音信号和信号处理方法的研究。信号通常以数字表示进行处理,因此语音处理可以被认为是应用于语音信号的数字信号处理的例子。语音处理的各方面包括语音信号的获取、处理、存储、传输和输出。
技术实现要素:
3.对于具有非典型语音(例如,言语障碍(apraxia),混乱,发展性言语障碍(developmental verbal dyspraxia),构音障碍(dysarthria),声韵障碍(dysprosody),语音障碍(speech sound disorder),口吃(stuttering),嗓音障碍(voice disorder),口齿不清(lisp)等)的说话者来说,确保其他人能够理解说话者正在说什么是具有挑战性的。利用语音识别技术通过转录说话者的语音并在用户界面中或通过合成语音输出转录来协助其他人将是有帮助的。然而,正如收听者可能难以理解具有非典型语音的说话者一样,语音识别器在转录非典型语音时可能出现准确性下降的问题。
4.为了克服这个挑战,确定具有非典型语音的说话者和具有典型语音的另一说话者之间的对话的上下文可能是有帮助的。系统可以使用多个语音识别器,并且根据系统是否检测到非典型语音或典型语音来选择性地激活其中一个语音识别器。
5.系统可以使用通用语音识别器来产生来自具有典型语音的说话者的语音的转录。系统可以使用转录来确定会话的上下文,以偏置可选语音识别器。在转录具有非典型语音的说话者的语音时系统可以在使用偏置的可选语音识别器。通过偏置可选语音识别器,系统可以提高来自具有典型语音的说话者的语音的转录的准确性。
6.这在各种类型的情况下可能是有帮助的。一个示例可以包括两个人之间的电话对话,一个人用非典型语音讲话,另一个人用典型语音讲话。系统可以使用以典型语音讲话的说话者的对话的转录来偏置可选语音识别器。系统使用偏置的可选语音识别器对以非典型语音说的说话者的对话执行语音识别。系统可以输出具有非典型语音的说话者的对话的转录或者输出合成语音,使得以典型语音说话的说话者能够更好地理解以非典型语音说话的说话者。
7.本公开的一个方面公开了一种计算机实现的方法,当所述方法在数据处理硬件上执行时使所述数据处理硬件执行以下操作:接收由用典型语音说话的第一用户说出的第一话语的声学特征;使用通用语音识别器处理所述第一话语的所述声学特征,以生成所述第一话语的第一转录;分析所述第一话语的所述第一转录,以识别所述第一转录中的一个或多个偏置词语,用于偏置可选语音识别器;在所述第一转录中识别的所述一个或多个偏置词语上对所述可选语音识别器进行偏置。所述操作还包括:接收由用非典型语音说话的第二用户说出的第二话语的声学特征;以及使用在所述第一转录中识别的所述一个或多个偏
置词语被偏置的所述可选语音识别器来处理所述第二话语的所述声学特征,以生成所述第二话语的第二转录。
8.本公开的实施方式可以包括以下可选特征的一种或多种。在一些实施方式中,所述操作包括在与所述第一用户相关联的用户设备的显示器上显示所述第二话语的所述第二转录,和/或为所述第二话语的所述第二转录生成合成语音表示,以及提供所述合成语音表示,用于从与所述第一用户相关联的用户设备进行音频输出。在一些示例中,所述操作还包括,在接收由用所述非典型语音说话的所述第二用户说出的所述第二话语的所述声学特征之后:对所述第二话语的所述声学特征执行说话者识别,以将所述第二话语的说话者识别为用所述非典型语音说话的所述第二用户;以及基于将所述第二用户识别为所述第二话语的所述说话者的、对所述第二话语的所述声学特征执行的所述说话者识别,选择所述可选语音识别器对所述第二话语的所述声学特征执行语音识别。
9.在一些示例中,所述操作还包括:在接收由用所述非典型语音说话的所述第二用户说出的所述第二话语的所述声学特征之后:使用语音分类器模型生成输出,所述输出指示所述第二话语的所述声学特征与具有所述非典型语音的说话者说出的话语相关联;以及基于所述语音分类器模型生成的所述输出,选择所述可选语音识别器对所述第二话语的所述声学特征执行语音识别,所述输出指示所述第二话语的所述声学特征与具有所述非典型语音的所述说话者说出的所述话语相关联。在这些其它示例中,所述语音分类器模型在非典型训练话语上被训练,所述非典型话语包括指示所述非典型训练话语由具有非典型语音的说话者说出的相应标签。这里,所述非典型训练话语包括由具有以下中的至少一种的说话者说出的话语:言语障碍、聋语音、混乱、发展性言语障碍、构音障碍、声韵障碍、语音障碍、言语不清、口吃、嗓音障碍或口齿不清。所述语音分类器模型还在典型训练话语上被训练,所述典型训练话语包括指示所述典型训练话语由具有典型语音的说话者说出的相应标签。
10.在一些实施方式中,分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语包括,通过识别所述第一转录中的非功能性词语来识别所述一个或多个偏置词语。分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语包括对所述第一转录执行词频-逆向文件频率(tf-idf)分析,以识别所述一个或多个偏置词。附加地或可选地,分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语包括,在所述第一用户与所述第二用户之间正在进行的对话期间识别由所述通用语音识别器产生的多个转录中包括的相互信息。
11.所述第一话语由与所述第一用户相关联的第一用户设备捕获,所述数据处理硬件驻留在所述第一用户设备上。在其它的配置中,所述数据处理硬件驻留在与所述第一用户设备通信的远程计算设备上。
12.本公开的另一方面公开了一种系统,所述系统包括数据处理硬件和与所述数据处理硬件通信的存储器硬件,所述存储器硬件存储指令,当所述指令在所述数据处理硬件上执行时使所述数据处理硬件执行以下操作:接收由用典型语音说话的第一用户说出的第一话语的声学特征;使用通用语音识别器处理所述第一话语的所述声学特征,以生成所述第一话语的第一转录;分析所述第一话语的所述第一转录,以识别所述第一转录中的一个或多个偏置词语,用于偏置可选语音识别器;在所述第一转录中识别的所述一个或多个偏置
词语上对所述可选语音识别器进行偏置。所述操作还包括:接收由用非典型语音说话的第二用户说出的第二话语的声学特征;以及使用在所述第一转录中识别的所述一个或多个偏置词语被偏置的所述可选语音识别器来处理所述第二话语的所述声学特征,以生成所述第二话语的第二转录。
13.该方面可以包括以下可选特征的一种或多种。在一些实施方式中,所述操作包括在与所述第一用户相关联的用户设备的显示器上显示所述第二话语的所述第二转录,和/或为所述第二话语的所述第二转录生成合成语音表示,以及提供所述合成语音表示,用于从与所述第一用户相关联的用户设备进行音频输出。在一些示例中,所述操作还包括,在接收由用所述非典型语音说话的所述第二用户说出的所述第二话语的所述声学特征之后:对所述第二话语的所述声学特征执行说话者识别,以将所述第二话语的说话者识别为用所述非典型语音说话的所述第二用户;以及基于将所述第二用户识别为所述第二话语的所述说话者的、对所述第二话语的所述声学特征执行的所述说话者识别,选择所述可选语音识别器对所述第二话语的所述声学特征执行语音识别。
14.在一些示例中,所述操作还包括:在接收由用所述非典型语音说话的所述第二用户说出的所述第二话语的所述声学特征之后:使用语音分类器模型生成输出,所述输出指示所述第二话语的所述声学特征与具有所述非典型语音的说话者说出的话语相关联;以及基于所述语音分类器模型生成的所述输出,选择所述可选语音识别器对所述第二话语的所述声学特征执行语音识别,所述输出指示所述第二话语的所述声学特征与具有所述非典型语音的所述说话者说出的所述话语相关联。在这些其它示例中,所述语音分类器模型在非典型训练话语上被训练,所述非典型话语包括指示所述非典型训练话语由具有非典型语音的说话者说出的相应标签。这里,所述非典型训练话语包括由具有以下中的至少一种的说话者说出的话语,言语障碍、聋语音、混乱、发展性言语障碍、构音障碍、声韵障碍、语音障碍、言语不清、口吃、嗓音障碍或口齿不清。所述语音分类器模型还在典型训练话语上被训练,所述典型训练话语包括指示所述典型训练话语由具有典型语音的说话者说出的相应标签
15.在一些实施方式中,分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语包括,通过识别所述第一转录中的非功能性词语来识别所述一个或多个偏置词语。分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语包括对所述第一转录执行词频-逆向文件频率(tf-idf)分析,以识别所述一个或多个偏置词。附加地或可选地,分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语包括,在所述第一用户与所述第二用户之间正在进行的对话期间识别由所述通用语音识别器产生的多个转录中包括的相互信息。
16.所述第一话语由与所述第一用户相关联的第一用户设备捕获,所述数据处理硬件驻留在所述第一用户设备上。在其它的配置中,所述数据处理硬件驻留在与所述第一用户设备通信的远程计算设备上。
17.本公开的一个或多个实施方式的细节在附图和以下描述中阐述。从说明书和附图以及权利要求书中,其它方面、特征、和优点将是显而易见的。
附图说明
18.图1是正在对话的两个用户的示例性环境的示意图,其中计算设备输出以非典型语音说话的用户的用户语音转录。
19.图2是对典型语音和非典型语音执行语音识别的示例自动语音识别(asr)系统的示意图。
20.图3是用于训练语音分类器模型的示例训练过程的示意图。
21.图4是对典型语音和非典型语音执行语音识别的方法的操作的示例布置的流程图。
22.图5是可用于实施本文所述的系统和方法的示例性计算设备的示意图。
23.各图中的相同的附图标记和标号表示相同的元素。
具体实施方式
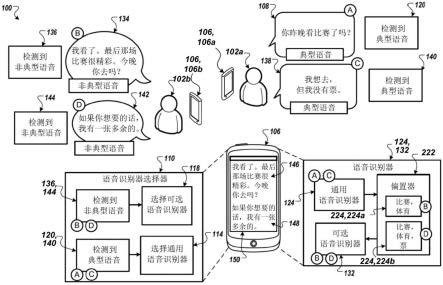
24.图1示出了正在对话的两个用户102a,102b的示例性环境100,其中计算设备106输出由以非典型语音讲话的用户102b讲话的语音的副本146,146a-b。简而言之,如下面更详细地描述的,用典型语音对话的用户102a与用非典型语音对话的用户102b正在对话。为了帮助用户102a理解用户102b,计算设备106提供包括由用户102b说出的话语(utterance)134,142的副本146a,146b的图形界面150。计算设备106通过偏置被配置为识别非典型语音的可选语音识别器132来提高对来自用户102的非典型语音执行的语音识别的准确性。会话可以包括经由相应的用户设备106,106a-b(例如,智能电话)的电话会话。在其他示例中,用户102a、102b可能正在进行当面交谈,其中单个用户设备106正在捕捉由两个用户102a、102b所说的话语108,134、138、142。
25.更详细地,用户102b用非典型语音讲话,而用户102a不用非典型语音讲话,这有时使得其他人难以理解用户102b。用户102可以使用用户设备106来帮助理解具有非典型语音的用户102b。用户设备106可以对应于具有多个语音识别器124,132的计算设备。例如,用户设备106可以使用通用语音识别器(general speech recognizer)124对不包括非典型语音的语音执行语音识别,并且使用可选语音识别器(alternative speech recognizer)132对非典型语音执行语音识别。更具体地,通用语音识别器124可以在用典型语音讲话的说话者为主的语音上训练,使得通用语音识别器124难以准确地识别由具有非典型语音的用户讲话的语音。可选语音识别器132是在有各种类型的语音障碍的说话者所讲的语音话语上进行训练的,语音障碍例如但不限于言语障碍(apraxia of speech)、混乱(cluttering)、发育性言语障碍(developmental verbal dyspraxia)、构音障碍(dysarthria)、声韵障碍(dysprosody)、语音障碍(speech sound disorder)、言语不清(slurred speech)、口吃(stuttering)、嗓音障碍(voice disorder)、口齿不清(lisp)或可使其它人难以理解的任何其它类似语音障碍。
26.在阶段a,用户102a说出话语108,“你昨晚看比赛了吗(did you see the game last night)?”用户设备106可以包括捕获话语108的麦克风204(图2)。用户设备106包括语音识别器选择器(speech recognizer selector)110,语音识别器选择器110被配置为确定说出所捕获的话语108的用户102a是否用非典型语音说话。基于指示话语108不包括非典型语音的决定(decision)120,语音识别器选择器110得到决定114,指示选择通用语音识别器
124。
27.用户设备106使用通用语音识别器124对表征话语108的音频数据执行语音识别。通用语音识别器124输出话语108的asr结果218(图2),并将话语108的asr结果218提供给语音识别偏置器222。语音识别偏置器222被配置为选择词语(term)224和偏置可选语音识别器132的类。在该示例中,语音识别偏置器222确定话语108与运动相关,并将可选语音识别器132偏置为与运动相关的词语224a的类。语音识别偏置器还将词语“比赛”识别为偏置可选语音识别器132的适当的词语224a。
28.在阶段b,用户102b说出话语134,“我看了。最后那场比赛很精彩。今晚你去吗?(i did.that last play was great.are you going tonight?)”用户102b的语音是非典型的,这使得用户102a难以理解用户102b正在说什么。用非典型语音讲话也可能使得通用语音识别器124难以准确地对话语104的音频数据执行语音识别。用户设备106的麦克风捕获话语134,并将话语132转换为以数字格式表征话语132的音频数据(例如,声学特征205(图2))。语音识别器选择器110分析话语134的音频数据,并确定话语134包括非典型语音,如决定136所示。
29.基于语音识别器选择器110确定发声134包括非典型语音,语音识别器选择器110指示用户设备106使用可选语音识别器132对音频数据执行语音识别。可选语音识别器132可以访问/接收由偏置器222识别的偏置词语224,用于将可选语音识别器132偏置向包括词语“游戏”和与运动类相关的词语集合的那些词语224a。可选语音识别器132生成“我看了。最后那场比赛很精彩。今晚你去吗?”的转录146。
30.为了帮助用户102a理解用户102b,用户设备106生成包括转录146的图形界面150。用户设备106将图形界面150输出到用户设备106的显示器。用户102a能够在用户设备106的显示器查看到“我看了。最后那场比赛很精彩。今晚你去吗?”用户设备106可以附加地或可选地可听地(audibly)输出转录146的合成语音表示。
31.在阶段c中,用户102a回复话语138“我想去,但我没有票(i want to,but i don’t have a ticket.)”,用户102a和用户102b之间的对话继续。用户设备106的麦克风捕获话语138,并将话语138转换为以数字格式表征话语138的音频数据(例如,声学特征205(图2))。语音识别器选择器110分析话语138的音频数据。语音识别器选择器110确定话语138是由不具有非典型语音的用户说出的,如决定140所示。
32.语音识别器选择器110向通用语音识别器124提供指令以对话语138的音频数据执行语音识别。在一些实施方式中,计算设备106不对通用语音识别器124偏置。通用语音识别器124生成话语138的asr结果218,并将话语138的asr结果218提供给语音识别偏置器222。在该示例中,语音识别偏置器222确定话语138将词语“票”识别为偏置可选语音识别器132的词语224,224b。语音识别偏置器222添加词语“票”作为词语224b以偏置可选语音识别器132,使得偏置词语224现在包括词语“比赛”和“票”以及与“体育”类相关的词语集合。
33.在一些实施方式中,语音识别偏置器222分析用户102a所说的累积话语,以确定来偏置可选语音识别器132的词语224。例如,语音识别偏置器222可以分析话语108和话语138的asr结果218,以确定任何后续话语的偏置词语224。在这种情况下,语音识别偏置器222可以基于分析具有典型语音的说话者102a说出的话语108,138的asr结果218来识别词语“比赛”和“票”以及与“体育”类相关的词语集。
34.在一些实施方式中,语音识别偏置器222分析用户102a所说的最近的话语以确定词语224和与所识别的类别相关的词语集合以添加到先前所识别的词语224中。例如,语音识别偏置器222可以分析话语138以确定额外偏置的词语224b。在这种情况下,语音识别偏置器222可以基于分析话语138的asr结果224来识别词语“票”。语音识别偏置器222可以在驻留在用户设备106上的存储器硬件中存储先前识别的词语224a以及新的词语“票”224b。语音识别偏置器222可使用偏置词语224,224a-b偏置可选语音识别器132。
35.在阶段d,用户102b说出话语142,“如果你想要的话,我有一张多余的(i have an extra one if you want it.)”。用户102b继续用非典型语音讲话。用户设备106的麦克风捕获话语142,并将话语142转换为表征话语142的音频数据。语音识别器选择器110分析话语142的音频数据,并确定话语142由具有非典型语音的用户说出,如决定144所示。
36.基于语音识别器选择器110确定话语142由具有非典型语音的用户说出,语音识别器选择器110指示用户设备106对音频数据执行语音识别。可选语音识别器132访问/接收偏置词语224,并将可选语音识别器132偏置向偏置词语224a和偏置词语224b,偏置词语224a包括词语“比赛”和与“体育”类相关的词语集合,偏置词语224b包括词语“票”。可选语音识别器132生成“如果你想要的话,我有一张多余的”的转录148。
37.用户设备106更新图形界面150以包括转录148。用户设备106将图形界面150输出到用户设备106的显示器。用户102能够在计算设备106的显示器上查看“如果你想要的话,我有一张多余的”。用户设备106可以附加地或可选地可听地输出转录148的合成语音表示。
38.图2示出了对典型语音和非典型语音执行语音识别的示例性自动语音识别(asr)系统200。在一些实施方式中,asr系统200驻留在用户102,104的用户设备106上和/或驻留在与用户设备通信的远程计算设备201(例如,在云计算环境中执行的分布式系统的一个或多个服务器)上。在一些示例中,asr系统200的组件的一部分驻留在用户设备106上,而组件的剩余部分驻留在远程计算设备201上。尽管用户设备106被描述为移动计算设备(例如智能电话),但是用户设备106可以对应于任何类型的计算设备,例如但不限于平板设备、膝上型/台式计算机、可佩戴设备、数字助理设备、智能扬声器/显示器、智能设备、汽车信息娱乐系统、或物联网(iot)设备。
39.asr系统200包括在用户设备106上实施的音频子系统202,而系统200的其它组件可以驻留在用户设备106和/或远程系统201上。音频子系统202可以包括一个或多个麦克风204,模数(a-d)转换器206,缓冲器(buffer)208和各种其它音频滤波器。一个或多个麦克风204被配置为捕获诸如用户102说出的语音的音频,并且a-d转换器206被配置为将音频转换为与能够由asr系统200的各种组件处理的输入声学特征205相关联的相应数字格式。在一些示例中,声学特征205包括一系列参数化的输入声学帧,每个声学帧包括80维log-mel特征,以短(例如25毫秒(ms))窗口计算,并且每隔例如10ms移位。缓冲器208可以存储从由一个或多个麦克风204捕获的相应音频中采样的最近的声学特征205(例如,上个10秒),以便由asr系统200进行进一步处理。asr系统200的其它组件可以访问并存储在缓冲器208中的声学特征205以用于进一步处理。
40.在一些实施方式中,asr系统200包括说话者识别器210,说话者识别器210被配置成从音频子系统202接收声学特征205并确定声学特征205是与由具有非典型语音的说话者说出的话语相关联还是与由具有典型语音的说话者说出的话语相关联。说话者识别器210
可以生成指示声学特征205是与非典型语音还是与典型语音相关联的输出211。例如,图1所示的典型语音检测决定120,140中的每一个以及非典型语音检测决定136,144中的每一个可以包括由说话者识别器210生成的相应输出211。在一些示例中,说话者识别器210通过处理声学特征205以生成说话者嵌入(例如,d矢量或i矢量)并确定说话者嵌入是否与存储的具有非典型语音或典型语音的用户的说话者嵌入相匹配,来执行说话者识别/识别。当说话者嵌入和所存储的说话者嵌入之间的嵌入距离满足距离阈值时,说话者嵌入可以匹配所存储的说话者嵌入。
41.在另外的示例中,说话者识别器210包括语音分类器模型310,语音分类器模型310被训练以接收声学特征205作为输入,并生成输出211,输出211指示声学特征205是否与具有非典型语音的说话者或具有非典型语音的说话者说出的话语相关联。例如,图3示出了用于训练语音分类器模型310的示例训练过程300。语音分类器模型310可以是基于神经网络的模型。训练过程300在非典型训练话语302上训练语音分类器模型310,非典型训练话语302包括具有非典型语音的说话者说出的话语。非典型训练话语302可以包括有各种类型的语音障碍的说话者所讲的话语,语音障碍例如但不限于言语障碍、混乱、发展性言语障碍、构音障碍、声韵障碍、语音障碍、言语不清、口吃、嗓音障碍、口齿不清或可使其它人难以理解的任何其它类似语音障碍。非典型训练话语302可以被标记以教导语音分类器模型310将非典型说话者所说的话语分类为非典型语音。在一些情况下,模型310被训练以生成输出211,输出211指示话语是否由具有特定类型的非典型语音的说话者说出。例如,输出211可以指示与由具有构音障碍的说话者说的话语相关联的声学特征包括构音障碍,输出211可以指示与由不同的聋的说话者说的另一个话语相关联的其它声学特征包括聋语音(deaf speech)。在这些场景中,模型310在明确标记为包括构音障碍的非典型语音的非典型训练话语302以及明确标记为包括聋语音的非典型训练话语302上被训练。模型310可以被训练以生成输出211,输出211指示任何数量的不同特定类型的非典型语音,以提供更大的粒度。以这种方式,每种类型的非典型语音可以与相应的可选语音识别器132相关联,可选语音识别器132被个性化以识别特定类型的非典型语音。
42.附加地或可选地,训练过程300在典型训练话语304上训练语音分类器模型310,典型训练话语304包括具有典型语音的说话者说出的话语。如同非典型训练话语302一样,可以标记典型训练话语304以教导语音分类器模型310将典型说话者所说的话语分类为典型语音。
43.系统200还包括语音识别器选择器112。语音识别器选择器112被配置成接收由说话者识别器210生成的输出211,输出211指示声学特征205是否包括具有典型语音或非典型语音的说话者说出的话语。如果由语音识别器选择器112接收的输出211指示声学特征205包括具有非典型语音的说话者说出的话语,则语音识别器选择器112选择(例如,经由决定118)可选语音识别器132以对声学特征205执行语音识别。如果语音识别器选择器112接收的输出211指示音频特征205不包括由具有非典型语音的说话者说出的话语,则语音识别器选择器112选择(例如,经由决定114)通用语音识别器124以对声学特征205执行语音识别。
44.在一些实施方式中,说话者识别器210被配置为识别不同类型的非典型语音。例如,说话者识别器210可以被配置为确定说话者是否不具有非典型语音、具有构音障碍的语音、或者具有言语障碍(apraxia of speech)。也就是说,说话者识别器210可以实施说话者
分类器模型310,以生成指示不同类型的非典型语音和典型语音的输出211,和/或说话者识别器210可以简单地对接收到的声学特征205执行说话者识别,以确定说话者嵌入是否与存储的说话者嵌入相匹配,存储的说话者嵌入用于已知用特定类型的非典型语音或典型语音说话的说话者。在该示例中,asr系统200可以包括三个语音识别器:用于识别典型语音的通用语音识别器124;训练成识别构音障碍语音的第一可选语音识别器132;以及训练以识别言语障碍的第二可选语音识别器132。如果说话者识别器210生成说话者不具有非典型语音的输出211,则语音识别器选择器110可以选择通用语音识别器124。如果说话者识别器110生成指示说话者具有构音障碍语音的输出211,则语音识别器选择器110可以为具有构音障语音的说话者选择第一可选语音识别器132。如果说话者识别器210生成指示说话者具有言语障碍的输出211,则语音识别器选择器110可以为具有言语障碍的说话者选择第二可选语音识别器132。
45.在语音识别器选择器110经由决定114选择通用语音识别器124的情况下,通用语音识别器124从音频子系统202或从存储从音频子系统202接收的声学特征205的存储设备中接收声学特征205。通用语音识别器124对声学特征205执行语音识别,以为具有典型语音的说话者说出的话语生成asr结果218。
46.语音识别器偏置器222访问/接收由通用语音识别器124生成的asr结果218,并使用asr结果218偏置可选语音识别器132。具体而言,语音识别器偏置器222被配置为识别asr结果218中最突出(prominent)的词语224,并将可选语音识别器132偏置向那些词语224。因此,由偏置器222在asr结果217中识别出的突出词语224可以被称为用于偏置可选语音识别器132的偏置词语224。在一些实施方式中,语音识别器偏置器222通过识别asr结果218中最多重复的非功能词语来识别突出词语。在另外的实施方式中,语音识别器偏置器222通过对asr结果218执行词频-逆向文件频率(term frequency-inverse document frequency,tf-idf)分析来识别突出词语224。附加地或可选地,语音识别器偏置器222可以通过识别多asr结果218中包含的相互(mutual)信息来识别突出词语,多asr结果218是由通用语音识别器124在正在进行的对话期间生成的。
47.在一些实施方式中,语音识别器偏置器222使用衰减函数来确定突出词语224以偏置可选语音识别器132。在这种情况下,语音识别器偏置器222将权重分配给每个词语224,并且当asr系统200接收到不包括先前识别的词语的额外话语时,减小权重。例如,如果语音识别器偏向器222在第一话语中识别出词语“雪”和“冰”,然后在随后的话语中识别出词语“雨”,则语音识别器偏向器222可以将可选语音识别器132偏向“雨”的程度比偏向“雪”和“雨”的程度大。
48.在一些附加的实施方式中,语音识别器偏置器222还使用偏置、语言模型自适应、和/或波束搜索的任何组合来调整可选语音识别器132。语音识别器偏置器222还可使用馈送来更新可选语音识别器132,使得可选语音识别器132更了解对话的主题、域、和/或语言上下文。语音识别器偏置器222可以被配置为在可选语音识别器132的波束搜索解码期间增强某些单词或短语。语音识别器偏置器222可以被配置为在可选语音识别器132的第一遍(first pass)或第二遍(second pass)上即时(on the fly)建立和/或调整语言模型。语音识别器偏置器222可以被配置为修改可选语音识别器132,使得可选语音识别器132在循环神经网络语言模型编码器隐藏状态上使用注意力。
49.在语音识别器选择器110经由决定118选择可选语音识别器132的情况下,可选语音识别器132从音频子系统202或从存储从音频子系统202接收的声学特征205的存储设备中接收声学特征205。可选语音识别器132对与话语相对应的声学特征205执行语音识别,并将话语的转录230(例如,图1的146,转录146)存储在存储器硬件中。这里,当在声学特征205上执行语音识别时,可选语音识别器132可以由偏置词语224偏置,偏置词语224由语音识别器偏置器222从asr结果218识别,asr结果218由通用语音识别器124从具有典型语音的说话者说出的对话的先前话语生成。
50.用户界面生成器232访问/接收来自可选语音识别器132的转录230,并生成包括可选语音识别器转录230的用户界面150。asr系统200在与系统200通信的显示器上输出用户界面150。例如,asr系统200可以在与图1的、用典型语音讲话用户102a相关联的用户设备106a的显示器上输出用户界面150。值得注意的是,第二转录230是规范文本(canonical text),使得第一用户102a可以理解由具有非典型语音的第二用户102b说出的第二话语134。
51.在一些实施方式中,asr系统200包括语音合成器234,语音合成器234生成由可选语音识别器132生成的转录230的合成语音236。合成器234可以包括文本到语音模块/系统。asr系统200可以通过扬声器或其它音频输出设备输出合成语音236。例如,asr系统200可以通过与图1的、用典型语音讲话的用户102a相关联的用户设备106a的扬声器上输出合成语音236。这里,合成语音表示236对应于传达由具有非典型语音的第二用户102b说出的话语134,142的规范(canonical)语音。
52.当asr系统200使用通用语音识别器124来执行语音识别时,则asr系统200停用或绕过在可选语音识别器132上执行语音识别。当asr系统200使用可选语音识别器132之一时,则asr系统200可停用或绕过在通用语音识别器124和任何其它可选备选语音识别器132上执行语音识别。
53.图4是偏置可选语音识别器132的方法400的操作的示例性布置的流程图。可选语音识别器132可以被训练为对具有非典型语音的用户说出的语音执行自动语音识别(asr)。数据处理硬件510(图5)可执行存储在存储器硬件520(图5)上的指令以执行方法400的操作。数据处理硬件510和存储器硬件520可以驻留在与用户102相关联的用户设备106上或与用户设备106通信的远程计算设备(例如,服务器)上。方法400可以参考图1和2进行描述。
54.在操作402,方法400包括接收由具有典型语音的第一用户102a说出的第一话语108的声学特征205,并且在操作404,方法400包括使用通用语音识别器124处理第一话语108的声学特征以生成第一话语108的第一转录(即,asr结果)218。
55.在操作406,方法400包括分析第一话语108的第一转录218以识别第一转录218中的一个或多个偏置词语224,用于偏置可选语音识别器132。在操作408,方法400包括在第一转录218中识别的一个或多个偏置词语224上偏置可选语音识别器132。一个或多个偏置词语224的至少一部分可以与第一转录218中识别出的主题或类别相关的偏向词语相关联。例如,如果由通用语音识别器124生成的转录218与政治相关,则方法400可以将可选语音识别器132在与政治相关的一个或多个偏置词语224的集合上偏置。
56.在操作410,方法400包括接收由以非典型语音讲话的第二用户102b讲话的第二话语134的声学特征205。在操作412,方法400包括使用偏置在第一转录224中识别的一个或多
个偏置词语224的可选语音识别器132来处理第二话语134的声学特征205,以生成第二话语134的第二转录230。
57.在一些示例中,计算设备106在图形用户界面150中显示第二话语134的第二转录146,使得第一用户104。值得注意的是,第二转录230是规范文本,使得第一用户102a可以理解由具有非典型语音的第二用户102b说出的第二话语134。附加地或可选地,方法400还可以使用合成器(例如,文本到语音模块)234为第二转录230生成合成语音表示236,并且从计算设备106可听地输出合成语音表示236。这里,合成语音表示236对应于传达由以非典型语音说话的第二用户102b说出的话语134的规范语音。
58.图5是可用于实施本文中描述的系统(例如,语音识别器200)和方法(例如,方法400)的示例计算设备500的示意图。计算设备500旨在表示各种形式的数字计算机,例如膝上型电脑、台式机、工作站、个人数字助理、服务器、刀片服务器、大型机和其他合适的计算机。此处显示的各部件、它们的连接和关系及其功能仅作为示例,而不是要限制在本文件中描述和/或要求保护的本发明的实现。
59.计算设备500包括处理器510(例如数据处理硬件)、存储器520(例如存储器硬件)、存储设备530、连接到存储器520和多个高速扩展端口540的高速接口/控制器540、以及连接到低速总线570和存储设备530的低速接口/控制器560。组件510、520、530、540、550和560中的每一个使用各种总线互连,并且可以适当地安装在公共母板上或以其它方式安装。处理器510可以处理用于在计算设备500内执行的指令,包括存储在存储器520中或存储设备530上的指令,以在例如与高速接口540连接的显示器580的、外部输入/输出设备上显示gui的图形信息。在其他实施方式中,可以视情况使用多个处理器和/或多个总线以及多个存储器和多个存储器类型。此外,可以连接多个计算设备500,每个设备提供必要操作的一部分(例如,作为服务器组、刀片服务器组、或多处理器系统)。
60.存储器520在计算设备500内非瞬态地存储信息。存储器520可以是计算机可读介质,易失性存储器单元或非易失性存储器单元。非瞬态存储器520可以是临时或永久地存储由计算设备500使用的程序(例如,指令序列)或数据(例如,程序状态信息)的物理设备。非易失性存储器的实例包括但不限于,闪存和只读存储器(rom)/可编程只读存储器(prom)/可擦除可编程只读存储器(eprom)/电子可擦除可编程只读存储器(eeprom)(例如,通常用于固件,例如引导程序)。易失性存储器的示例包括但不限于随机存取存储器(ram),动态随机存取存储器(dram),静态随机存取存储器(sram),相变存储器(pcm)以及磁盘或磁带。
61.存储设备530能够为计算设备500提供大容量存储。在一些实施方式中,存储设备530是计算机可读介质。在各种不同的实施方式中,存储设备530可以是或包含计算机可读介质,例如软盘设备、硬盘设备、光盘设备或磁带设备、闪存或其他类似的固态存储设备,或一组设备,包括存储区域网络或其他配置中的设备。在另外的实施方式中,计算机程序产品被有形地包含在信息载体中。所述计算机程序产品包含指令,所述指令在被执行时执行一个或多个方法,例如上述的那些方法。信息载体是计算机或机器可读介质,例如存储器520,存储设备530或处理器510上的存储器。
62.高速控制器540管理计算设备500的带宽密集型操作,而低速控制器560管理较低带宽密集型操作。这种功能分配只是示例。在一些实施方式中,高速控制器540连接到存储器520、显示器580(例如,通过图形处理器或加速器)、以及高速扩展接口550,其可以接受多
种扩展卡(未示出)。在一些实施方式中,低速控制器560耦合到存储设备530和低速扩展端口590。包括各种通信端口(例如,usb、蓝牙、以太网、无线以太网)的低速扩展端口590可以连接到一个或多个输入/输出设备,例如键盘、指点设备、扫描仪、或网络设备,如交换机或路由器,例如,通过网络适配器。
63.如图所示,计算设备500可以以多种不同的形式实现。例如,它可以被实现为标准服务器500a或者在一组这样的服务器500a中多次实现为膝上型计算机500b,或者被实现为机架服务器系统500c的一部分。
64.此处描述的系统和技术的各种实现可以在数字电子电路、集成电路、专门设计的asic(专用集成电路)、计算机硬件、固件、软件和/或它们的组合中实现。这些各种实现可以包括在可编程系统上可执行和/或可解释的一个或多个计算机程序中的实现,所述可编程系统包括至少一个可编程处理器,所述可编程处理器可以是专用的或通用的,被耦合以从存储系统,至少一个输入设备和至少一个输出设备接收数据和指令,以及向其发送数据和指令。
65.这些计算机程序(也称为程序、软件、软件应用、或代码)包括用于可编程处理器的机器指令,并且可以用高级过程、和/或面向对象的编程语言、和/或汇编/机器语言来实现。如本文所用,术语“机器可读介质”和“计算机可读介质”是指用于向可编程处理器提供机器指令和/或数据的任何计算机程序产品、装置和/或设备(例如,磁盘、光盘、存储器、可编程逻辑设备(pld),包括接收作为机器可读信号的机器指令的机器可读介质。术语“机器可读信号”是指用于向可编程处理器提供机器指令和/或数据的任何信号。
66.本说明书中描述的过程和逻辑流程可以由一个或多个可编程计算机执行,可编程计算机执行一个或多个计算机程序以通过对输入数据进行操作并生成输出来执行功能。处理和逻辑流程也可以由专用逻辑电路执行,例如fpga(现场可编程门阵列)或asic(专用集成电路)。例如,适于执行计算机程序的处理器包括通用和专用微处理器,以及任何类型的数字计算机的任何一个或多个处理器。通常,处理器将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的基本元件是用于执行指令的处理器和用于存储指令和数据的一个或多个存储器设备。通常,计算机还将包括或被可操作地耦合以从一个或多个大容量存储设备接收数据或向一个或多个大容量存储设备传送数据,所述大容量存储设备用于存储数据,例如磁盘,磁光盘或光盘。然而,计算机不必具有这样的设备。适于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,包括例如半导体存储器设备,例如eprom、eeprom和闪存设备;磁盘,例如内部硬盘或可移动磁盘;磁光盘;cd rom和dvd-rom盘。处理器和存储器可以由专用逻辑电路补充或结合在专用逻辑电路中。
67.为了提供与用户的交互,本公开的一个或多个方面可以在具有显示设备(例如,crt(阴极射线管)或lcd(液晶显示器)监视器)的计算机上实现,用于向用户、键盘、和定点设备(例如,鼠标或轨迹球)显示信息,用户可以通过它向计算机提供输入。也可以使用其他类型的设备来提供与用户的交互;例如,提供给用户的反馈可以是任何形式的感官反馈,例如,视觉反馈、听觉反馈或触觉反馈;并且可以以包括声学、语音或触觉输入的任何形式来接收来自用户的输入。此外,计算机可以通过向用户使用的设备发送文档和从用户使用的设备接收文档来与用户交互;例如,通过响应于从web浏览器接收的请求向用户的客户端设
备上的web浏览器发送网页。
68.已经描述了多种实现方式。然而,应当理解,在不脱离本公开的精神和范围的情况下,可以进行各种修改。因此,其它实施方式在以下权利要求的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
