技术特征:
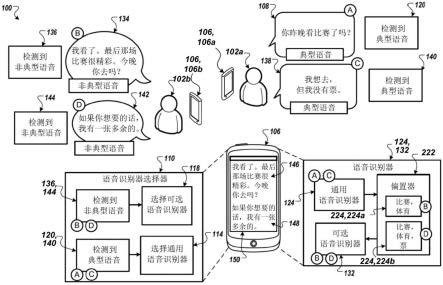
1.一种计算机实现的方法(400),其特征在于,当所述方法在数据处理硬件(510)上执行时使所述数据处理硬件(510)执行以下操作:接收由用典型语音说话的第一用户(102a)说出的第一话语(108)的声学特征(205);使用通用语音识别器(124)处理所述第一话语(108)的所述声学特征(205),以生成所述第一话语(108)的第一转录(218);分析所述第一话语(108)的所述第一转录(218),以识别所述第一转录(218)中的一个或多个偏置词语(224),用于偏置可选语音识别器(132);在所述第一转录(218)中识别的所述一个或多个偏置词语(224)上对所述可选语音识别器(132)进行偏置;接收由用非典型语音说话的第二用户(102b)说出的第二话语(134)的声学特征(205);以及使用在所述第一转录(218)中识别的所述一个或多个偏置词语(224)上被偏置的所述可选语音识别器(132)来处理所述第二话语(134)的所述声学特征(205),以生成所述第二话语(134)的第二转录(230)。2.根据权利要求1所述的计算机实现的方法(400),其特征在于,所述操作还包括,在与所述第一用户(102a)相关联的用户设备(106)的显示器上显示所述第二话语(134)的所述第二转录(230)。3.根据权利要求1或2所述的计算机实现的方法(400),其特征在于,所述操作还包括:为所述第二话语(134)的所述第二转录(230)生成合成语音表示(236);以及提供所述合成语音表示(236),用于从与所述第一用户(102a)相关联的用户设备(106)进行音频输出。4.根据权利要求1至3中任一项所述的计算机实现的方法(400),其特征在于,所述操作还包括,在接收由用所述非典型语音说话的所述第二用户(102b)说出的所述第二话语(134)的所述声学特征(205)之后:对所述第二话语(134)的所述声学特征(205)执行说话者识别,以将所述第二话语(134)的说话者识别为用所述非典型语音说话的所述第二用户(102b);以及基于将所述第二用户(102b)识别为所述第二话语(134)的所述说话者的、对所述第二话语(134)的所述声学特征(205)执行的所述说话者识别,选择所述可选语音识别器(132)对所述第二话语(134)的所述声学特征(205)执行语音识别。5.根据权利要求1至4中任一项所述的计算机实现的方法(400),其特征在于,所述操作还包括,在接收由用所述非典型语音说话的所述第二用户(102b)说出的所述第二话语(134)的所述声学特征(205)之后:使用语音分类器模型(310)生成输出(211),所述输出(211)指示所述第二话语(134)的所述声学特征(205)与具有所述非典型语音的说话者说出的话语相关联;以及基于所述语音分类器模型(310)生成的所述输出(211),选择所述可选语音识别器(132)对所述第二话语(134)的所述声学特征(205)执行语音识别,所述输出(211)指示所述第二话语(134)的所述声学特征(205)与具有所述非典型语音的所述说话者说出的所述话语相关联。6.根据权利要求5所述的计算机实现的方法(400),其特征在于,所述语音分类器模型
(310)在非典型训练话语(302)上被训练,所述非典型话语(302)包括指示所述非典型训练话语(302)由具有非典型语音的说话者说出的相应标签。7.根据权利要求6所述的计算机实现的方法(400),其特征在于,所述非典型训练话语(302)包括由具有以下中的至少一种的说话者说出的话语:言语障碍、聋语音、混乱、发展性言语障碍、构音障碍、声韵障碍、语音障碍、言语不清、口吃、嗓音障碍或口齿不清。8.根据权利要求6或7所述的计算机实现的方法(400),其特征在于,所述语音分类器模型(310)还在典型训练话语(304)上被训练,所述典型训练话语(304)包括指示所述典型训练话语(302)由具有典型语音的说话者说出的相应标签。9.根据权利要求1至8中任一项所述的计算机实现的方法(400),其特征在于,分析所述第一话语(108)的所述第一转录(218)以识别所述第一转录(218)中的一个或多个偏置词语(224)包括,通过识别所述第一转录(218)中的非功能性词语(224)来识别所述一个或多个偏置词语(224)。10.根据权利要求1至9中任一项所述的计算机实现的方法(400),其特征在于,分析所述第一话语(108)的所述第一转录(218)以识别所述第一转录(218)中的一个或多个偏置词语(224)包括,对所述第一转录(218)执行词频-逆向文件频率(tf-idf)分析,以识别所述一个或多个偏置词语(224)。11.根据权利要求1至10中任一项所述的计算机实现的方法(400),其特征在于,分析所述第一话语(108)的所述第一转录(218)以识别所述第一转录(218)中的一个或多个偏置词语(224)包括,在所述第一用户(102a)与所述第二用户(102b)之间正在进行的对话期间识别由所述通用语音识别器(124)产生的多个转录中包括的相互信息。12.根据权利要求1至11中任一项所述的计算机实现的方法(400),其特征在于,所述第一话语(108)由与所述第一用户(102a)相关联的第一用户设备(102a)捕获;以及所述数据处理硬件(510)驻留在所述第一用户设备(102a)上。13.根据权利要求1至12中任一项所述的计算机实现的方法(400),其特征在于,所述第一话语(108)由与所述第一用户(102a)相关联的第一用户设备(102a)捕获;以及所述数据处理硬件(510)驻留在与所述第一用户设备(102a)通信的远程计算设备(201)上。14.一种系统(500),其特征在于,所述系统包括:数据处理硬件(510);和与所述数据处理硬件(510)通信的存储器硬件(520),所述存储器硬件(520)存储指令,当所述指令在所述数据处理硬件(510上执行时使所述数据处理硬件(510)执行以下操作:接收由用典型语音说话的第一用户(102a)说出的第一话语(108)的声学特征(205);使用通用语音识别器(124)处理所述第一话语(108)的所述声学特征(205),以生成所述第一话语(108)的第一转录(218);分析所述第一话语(108)的所述第一转录(218),以识别所述第一转录(218)中的一个或多个偏置词语(224),用于偏置可选语音识别器(132);在所述第一转录(218)中识别的所述一个或多个偏置词语(224)上对所述可选语音识
别器(132)进行偏置;接收由用非典型语音说话的第二用户(102b)说出的第二话语(134)的声学特征(205);以及使用在所述第一转录(218)中识别的所述一个或多个偏置词语(224)上被偏置的所述可选语音识别器(132)来处理所述第二话语(134)的所述声学特征(205),以生成所述第二话语(134)的第二转录(230)。15.根据权利要求14所述的系统(500),其特征在于,所述操作还包括,在与所述第一用户(102a)相关联的用户设备(106)的显示器上显示所述第二话语(134)的所述第二转录(230)。16.根据权利要求14或15所述的系统(500),其特征在于,所述操作还包括:为所述第二话语(134)的所述第二转录(230)生成合成语音表示(236);以及提供所述合成语音表示(236),用于从与所述第一用户(102a)相关联的用户设备(106)进行音频输出。17.根据权利要求14至16中任一项所述的系统(500),其特征在于,所述操作还包括,在接收由用所述非典型语音说话的所述第二用户(102b)说出的所述第二话语(134)的所述声学特征(205)之后:对所述第二话语(134)的所述声学特征(205)执行说话者识别,以将所述第二话语(134)的说话者识别为用所述非典型语音说话的所述第二用户(102b);以及基于将所述第二用户(102b)识别为所述第二话语(134)的所述说话者的、对所述第二话语(134)的所述声学特征(205)执行的所述说话者识别,选择所述可选语音识别器(132)对所述第二话语(134)的所述声学特征(205)执行语音识别。18.根据权利要求14至17中任一项所述的系统(500),其特征在于,所述操作还包括,在接收由用所述非典型语音说话的所述第二用户(102b)说出的所述第二话语(134)的所述声学特征(205)之后:使用语音分类器模型(310)生成输出(211),所述输出(211)指示所述第二话语(134)的所述声学特征(205)与具有所述非典型语音的说话者说出的话语相关联;以及基于所述语音分类器模型(310)生成的所述输出(211),选择所述可选语音识别器(132)对所述第二话语(134)的所述声学特征(205)执行语音识别,所述输出(211)指示所述第二话语(134)的所述声学特征(205)与具有所述非典型语音的所述说话者说出的所述话语相关联。19.根据权利要求18所述的系统(500),其特征在于,所述语音分类器模型(310)在非典型训练话语(302)上被训练,所述非典型话语(302)包括指示所述非典型训练话语(302)由具有非典型语音的说话者说出的相应标签。20.根据权利要求19所述的系统(500),其特征在于,所述非典型训练话语(302)包括由具有以下中的至少一种的说话者说出的话语:言语障碍、聋语音、混乱、发展性言语障碍、构音障碍、声韵障碍、语音障碍、言语不清、口吃、嗓音障碍或口齿不清。21.根据权利要求19或20所述的系统(500),其特征在于,所述语音分类器模型(310)还在典型训练话语(304)上被训练,所述典型训练话语(304)包括指示所述典型训练话语(302)由具有典型语音的说话者说出的相应标签。
22.根据权利要求14至21中任一项所述的系统(500),其特征在于,分析所述第一话语(108)的所述第一转录(218)以识别所述第一转录(218)中的一个或多个偏置词语(224)包括,通过识别所述第一转录(218)中的非功能性词语(224)来识别所述一个或多个偏置词语(224)。23.根据权利要求14至22中任一项所述的系统(500),其特征在于,分析所述第一话语(108)的所述第一转录(218)以识别所述第一转录(218)中的一个或多个偏置词语(224)包括,对所述第一转录(218)执行词频-逆向文件频率(tf-idf)分析,以识别所述一个或多个偏置词语(224)。24.根据权利要求14至23中任一项所述的系统(500),其特征在于,分析所述第一话语(108)的所述第一转录(218)以识别所述第一转录(218)中的一个或多个偏置词语(224)包括,在所述第一用户(102a)与所述第二用户(102b)之间正在进行的对话期间识别由所述通用语音识别器(124)产生的多个转录中包括的相互信息。25.根据权利要求14至24中任一项所述的系统(500),其特征在于,所述第一话语(108)由与所述第一用户(102a)相关联的第一用户设备(102a)捕获;以及所述数据处理硬件(510)驻留在所述第一用户设备(102a)上。26.根据权利要求14至25中任一项所述的系统(500),其特征在于,所述第一话语(108)由与所述第一用户(102a)相关联的第一用户设备(102a)捕获;以及所述数据处理硬件(510)驻留在与所述第一用户设备(102a)通信的远程计算设备(201)上。
技术总结
一种方法(400)包括接收由用典型语音说话的第一用户(102a)说出的第一话语(108)的声学特征(205),以及使用通用语音识别器(124)处理所述第一话语的所述声学特征以生成所述第一话语的第一转录(218)。所述操作还包括分析所述第一话语的所述第一转录以识别所述第一转录中的一个或多个偏置词语(224),并在所述一个或多个偏置词语上对所述可选语音识别器(132)进行偏置。所述操作还包括接收由用非典型语音说话的第二用户说出的第二话语的声学特征(205),以及使用在所述第一转录中识别的所述一个或多个偏置词语上被偏置的所述可选语音识别器来处理所述第二话语的所述声学特征,以生成所述第二话语的第二转录(230)。以生成所述第二话语的第二转录(230)。以生成所述第二话语的第二转录(230)。
技术研发人员:法迪
受保护的技术使用者:谷歌有限责任公司
技术研发日:2021.01.20
技术公布日:2022/9/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。