基于resnet-gau模型的pcvcs端到端语音识别方法
技术领域
1.本发明涉及语音识别技术领域,具体涉及基于resnet-gau模型的pcvcs端到端语音识别方法。
背景技术:
2.空中交通管制(atc)的主要任务是防相撞,维护和加速空中交通有序的流动。管制指令的下达主要通过飞行员-管制员语音通话(pcvcs)实现的,指令的准确性对于保障飞行安全及其重要。在航空运输的持续发展过程中,流量增长与飞行安全之间的矛盾凸显的更为明显,人工智能技术逐渐融入空管,如管制员指令与飞行员复诵一致性监视,事后语音分析等。新技术的研究与应用能有效减轻管制员工作负荷,提升运行效率与安全水平。
3.自动语音识别技术(asr)早在90年代初被引入atc领域。wang j等使用开源的英文数据集librispeech预训练模型,再利用atc数据集微调模型,以解决民航数据稀缺的问题;ajay等人提出基于深度学习的算法对航空指令实施转录,为了扩大训练集,融入非航空语音提升泛化性。y.wang等人将dnn应用到语音分离,考虑到语音的时间动态特性,引入结构化感知机和条件随机场来优化模型,显著提升了带噪asr的鲁棒性;d.wang等探索了时频掩蔽、频谱映射以及端到端的时域映射方法等,取得了更好的增强性能;zhou k等利用卷积不变性克服语音信号本身的多样性,解决数据的噪声问题,并利用hybrid ctc-attention模型在atc数据上取得了较好的识别效果。lin y等利用多尺度卷积网络提取频谱图局部特征并设计了基于三个级联模块的单框架,解决了中英文混合的asr问题。helmke等利用asr技术与雷达技术构建基于助手的语音识别系统,能显著地降低管制员的任务压力。helmke等人以asr工具包kaldi为基础,对陆空通话内容进行转录,经过测试发现,使用该技术来协助管制员工作,可以有效减少飞机非计划飞行时间,提高管制效率与经济效益。
4.尽管开展了很多的研究,但空管中的语音识别在识别率、整体性能、技术集成等方面仍有待提升,主要包括:
5.(1)大多数具有高准确率的语音识别系统,都需要大量带有文本标注的语音数据来训练模型,数据规模性往往需要达到数百乃至数千小时,而在产业界训练数据甚至可以达到数万乃至数十万小时。然而这样的数据规模在面对一个特定领域如民航领域时很难获取到,因为对民航语音数据进行标注需要专业人员来进行,要得到一个大规模且高质量的数据集代价太大。
6.(2)目前最先进的语音识别系统在实验条件下已经可以实现极高的识别准确率,但在实际应用中往往很难保证一直处于理想的环境中,因此很多系统常常在一些复杂环境下效果明显衰减,造成这一现象的关键原因之一是噪声干扰的存在。没有进行噪声鲁棒性优化的识别算法,即使微弱的噪声也可能导致性能的明显下降。
7.(3)端到端语音识别系统同时训练声学和语言模型简化了训练过程,但由于解码器代替了传统架构中的语言模型,训练时又仅用有限成对的音频文本数据,不足以完整覆盖民航领域带有专业名词和指令的全方位场景。
技术实现要素:
8.为解决上述问题,本发明提供了一种基于resnet-gau模型的pcvcs端到端语音识别方法,其中resnet利用cnn的平移不变性和局部相关性提取语音信号的时频域信息;gau利用门控的单头注意力机制不仅能更好地捕获序列长距离依赖关系来获得更大的感受野和上下文信息,同时也拥有更快的训练收敛速度;ctc利用引入blank和产生重复token解决了语音信号和文本标签硬对齐的问题。技术方案如下:
9.基于resnet-gau模型的pcvcs端到端语音识别方法,包括以下步骤:
10.采用resnet提取待识别的语音信号的时频域特征;
11.通过多个串联的gaumodule,捕捉时频域特征的词序信息;
12.将词序信息传入denselayer,在特征空间上进行线性变化后通过softmax层获得最终的分类预测概率。
13.优选地,所述采用resnet提取待识别的语音信号的时频域特征,包括以下步骤:
14.输入待识别语音,经过7
×
7convlayer,卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量;
15.输出的特征图被传递至maxpoolinglayer进行特征选择和信息过滤;poolinglayer包含预设定的池化函数,将特征图中单个点的结果替换为其相邻区域的特征图统计量;
16.将最大池化后的特征向量依次经过由不同数量的residualblock组成的堆,得到高度提纯的特征,其中block内部,堆与堆均引入shortcutconnections,将输入跨层传递并与卷积的结果相加,缓解了在cnn中增加深度带来的梯度消失问题;
17.通过flattenlayer将resnet最终输出的特征进行降维处理,作为多个串联的gaumodule的输入。
18.优选地,还包括:
19.对输入添加绝对位置编码,保证在时间维度上的一致性;将gaumodule与gaumodule之间同样进行residualconnections。
20.优选地,所述捕捉时频域特征的词序信息,包括以下步骤:
21.输入的时频域特征经过layernorm,再分别经过denselayer与非线性变换得到门控矩阵u与计算注意力的value,query和key;
22.u=φu(xwu)v=φv(xwv)∈r
t
×e23.q&k=φ
q&k
(xw
q&k
)∈r
t
×s24.其中,x∈r
t
×d,t表示序列长度,d表示modelsize;wu,wv∈rd×e,e表示expandedintermediatesize;w
q&k
∈rd×s,s表示headsize;表示激活函数;
25.计算attentionscore采用relu2激活函数并加入relativepositionbias:
26.a=relu2(qk
t
b)∈r
t
×
t
27.o=(u
⊙
av)wo∈r
t
×d28.其中,a是attention矩阵,负责融合token之间的信息;
⊙
表示element-wisemultiplication;
29.通过dropoutlayer防止模型训练过程出现过拟合现象。
30.优选地,还包括,对resnet以及多个串联的gaumodule构成的语音识别模型进行
训练,包括以下步骤:
31.对源领域语音数据库中的语音数据采用特征增强技术,获得增强后的源领域语音数据库;
32.引入迁移学习,将在增强后的源领域语音数据库中训练后的语音识别模型,在目标领域空中交通管制语音数据库中进行微调,获得训练好的语音识别模型。
33.优选地,所述语音识别模型在大规模的源领域aishell corpus上训练模型,然后在小规模的目标领域atc corpus上继续微调训练模型。
34.优选地,所述对源领域语音数据库中的语音数据采用特征增强技术,包括以下步骤:
35.采用specaugment中的时频掩蔽技术,设定时间、频域轴方向连续掩码的最大范围是250ms、100hz,在源领域aishell corpus的[0,250]、[0,100]范围内进行均匀采样一个t(f),在[0,τ-t]、[0,τ-f]范围内随机确定一个点t0(f0),从t0(f0)位置开始沿着时间、频域轴方向连续进行t(f)次掩码,其中,τ表示时间维度,v表示频域维度;
[0036]
在源领域aishell corpus中添加一定信噪比的高斯白噪声;
[0037]
在源领域aishell corpus中进行语速增强操作。
[0038]
优选地,还包括根据时序分类算法将不等长的输入和输出的序列自动对齐,通过引入特殊字符blank使语音序列每帧能一一对应的预测其在输出标签序列上的条件概率分布。
[0039]
优选地,还包括:
[0040]
用语音增强技术从待识别的电磁干扰噪声背景中提取有用的语音信号作为待识别的语音信号。
[0041]
本发明的有益效果:
[0042]
本发明,设计了一种新的端到端语音识别模型resnet-gau-ctc,其中resnet提取语音信号的时频域特征,gau module捕捉序列之间全局交互信息和ctc将不等长的输入输出序列自动对齐。针对atc中文语音识别所面临的挑战,这里是两种方法被提出,迁移学习和数据增强技术。前者解决了atc领域标定数据稀缺和部分用语特殊发音等问题;后者扩充了源领域数据,丰富了数据特征的多样性,减小了不同领域之间数据分布的差异性和提升了迁移学习后模型的泛化能力。该模型在源任务,测试集上的cer是11.1%;在目标任务上,resnet50_gau@48取得了最优的识别性能,cer下降到8.0%。
附图说明
[0043]
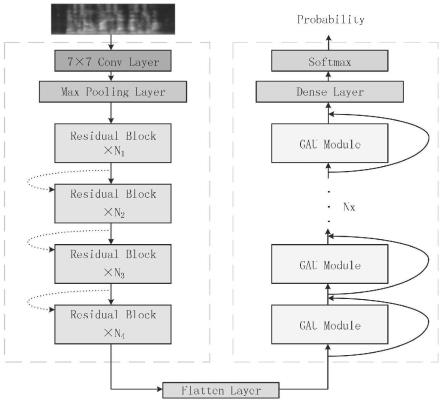
图1为本发明方法的识别模型整体架构图;
[0044]
图2为本发明实施例的迁移学习的过程示意图;
[0045]
图3为本发明实施例的时长分布图;
[0046]
图4为本发明实施例的语音信号可视化示意图;
[0047]
图5为本发明实施例的gau模型示意图;
[0048]
图6为本发明实施例的不同层数resnet中的residual block;
[0049]
图7为本发明实施例的beam search(beam width=2);
[0050]
图8为本发明实施例的不同模型的预训练损失;
[0051]
图9为本发明实施例的不同模型的预训练cer;
[0052]
图10为本发明实施例的不同层数的gaumodule在atccorpus的训练损失;
[0053]
图11为本发明实施例的不同层数的gaumodule在atccorpus的cer。
具体实施方式
[0054]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0055]
实施例1
[0056]
本发明的基于resnet-gau模型的pcvcs端到端语音识别方法。
[0057]
包括以下步骤:
[0058]
s1:采用resnet提取待识别的语音信号的时频域特征。
[0059]
输入待识别语音,经过7
×
7convlayer,卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量;
[0060]
输出的特征图被传递至maxpoolinglayer进行特征选择和信息过滤;poolinglayer包含预设定的池化函数,将特征图中单个点的结果替换为其相邻区域的特征图统计量;
[0061]
将最大池化后的特征向量依次经过由不同数量的residualblock组成的堆,得到高度提纯的特征,其中block内部,堆与堆均引入shortcutconnections,将输入跨层传递并与卷积的结果相加,缓解了在cnn中增加深度带来的梯度消失问题;
[0062]
通过flattenlayer将resnet最终输出的特征进行降维处理,作为多个串联的gaumodule的输入。
[0063]
s2:通过多个串联的gaumodule,捕捉时频域特征的词序信息。
[0064]
对输入添加绝对位置编码,保证在时间维度上的一致性;将gaumodule与gaumodule之间同样进行residualconnections。
[0065]
每个所述gaumodule的处理过程,包括以下步骤:
[0066]
输入的时频域特征经过layernorm,再分别经过denselayer与非线性变换得到门控矩阵u与计算注意力的value,query和key;
[0067]
u=φu(xwu)v=φv(xwv)∈r
t
×e[0068]
q&k=φ
q&k
(xw
q&k
)∈r
t
×s[0069]
其中,x∈r
t
×d,t表示序列长度,d表示modelsize;wu,wv∈rd×e,e表示expandedintermediatesize;w
q&k
∈rd×s,s表示headsize;表示激活函数;
[0070]
计算attentionscore采用relu2激活函数并加入relativepositionbias:
[0071]
a=relu2(qk
t
b)∈r
t
×
t
[0072]
o=(u
⊙
av)wo∈r
t
×d[0073]
其中,a是attention矩阵,负责融合token之间的信息;
⊙
表示element-wisemultiplication;
[0074]
通过dropoutlayer防止模型训练过程出现过拟合现象。
[0075]
s3:将词序信息传入denselayer,在特征空间上进行线性变化后通过softmax层
获得最终的分类预测概率。
[0076]
进一步的,还包括对resnet以及多个串联的gau module构成的语音识别模型进行训练,包括以下步骤:
[0077]
对源领域语音数据库中的语音数据采用特征增强技术,获得增强后的源领域语音数据库;引入迁移学习,将在增强后的源领域语音数据库中训练后的语音识别模型,在目标领域空中交通管制语音数据库中进行微调,获得训练好的语音识别模型。即,大规模的源领域aishell corpus上训练模型,然后在小规模的目标领域atc corpus上继续微调训练模型。
[0078]
其中,对源领域语音数据库中的语音数据采用特征增强技术,包括以下步骤:
[0079]
采用specaugment中的时频掩蔽技术,设定时间、频域轴方向连续掩码的最大范围是250ms、100hz,在源领域aishell corpus的[0,250]、[0,100]范围内进行均匀采样一个t(f),在[0,τ-t]、[0,τ-f]范围内随机确定一个点t0(f0),从t0(f0)位置开始沿着时间、频域轴方向连续进行t(f)次掩码,其中,τ表示时间维度,v表示频域维度;
[0080]
在源领域aishell corpus中添加一定信噪比的高斯白噪声;
[0081]
在源领域aishell corpus中进行语速增强操作。
[0082]
进一步的,根据时序分类算法将不等长的输入和输出的序列自动对齐,通过引入特殊字符blank使语音序列每帧能一一对应的预测其在输出标签序列上的条件概率分布。
[0083]
优选的,用语音增强技术从待识别的电磁干扰噪声背景中提取有用的语音信号作为待识别的语音信号。
[0084]
本实施例中,
[0085]
1数据分析与处理:
[0086]
提出两种方法提高模型在目标任务上的泛化能力。
[0087]
1.1迁移学习
[0088]
迁移学习放宽了传统机器学习中训练数据和测试数据必须服从独立同分布的约束,因而能够在彼此不同但又相互关联的两个领域间挖掘领域不变的本质特征和结构,使得标注数据等有监督信息可以在领域间实现迁移和复用。
[0089]
这里是两个概念被提出,领域和任务。领域由两个部分组成:特征空间x和特征空间的边缘分布p(x),其中,{x1,x2,
…
,xn}∈x。在给定一个领域d={x,p(x)}的情况下,任务由标签空间y和目标预测函数f(.)组成。在给定源领域ds和源领域学习任务ts、目标领域dt和目标领域任务tt的情况下(其中ds不等于dt或ts不等于tt),迁移学习使用源领域ds和ts中的知识提升或优化目标领域dt中目标预测函数f
t
(.)的学习效果。
[0090]
迁移学习的引入,解决了民航领域标注数据稀缺以及特殊发音问题,如图2所示,首先在大规模的源领域aishell corpus上训练模型,使模型具有较好的转录能力,然后在小规模的目标领域atc corpus上继续微调训练模型,最终使模型不仅在源任务上效果好,且保留了在目标任务上的泛化能力。
[0091]
1.2数据增强
[0092]
数据增强是在非实质性增加扩展数据的情形下,让有限的数据产生更多的等同于有效数据的价值。这种间接增加样本数量和丰富样本多样性的方法,可以降低模型对某些属性的依赖,从而提高模型的泛化能力。然而数据扩增倍数多并不能持续性的提升模型的
性能,只有在适当水平的数据扩增才可以对迁移学习模型产生积极效果。
[0093]
选取的源领域aishell corpus是在安静室内环境中录制,录音文本涉及智能家居、无人驾驶、工业生产等11个领域。我们对源领域数据集和目标域数据集的基本信息进行了整理与对比,如表1所示。
[0094]
表1数据集基本信息
[0095][0096]
其中,aishell corpus中样本数量大约是atc corpus的三倍,两种数据集语速分别为3.16字/秒,4.75字/秒。同时,考虑到atc corpus用语简洁,一个样本代表一条管制指令,因此,也对两种数据集中单样本时长分布进行了统计。如图3所示,两种不同类型的样本持续时间大多分布在2至8秒,可见样本时长分布近乎保持一致。
[0097]
为了减小来自不同领域的样本性质上的差异性,参考两种数据集的基本特征,我们采用了三种方式去扩充源领域的aishell corpus。如图4中(a),(b)所示,分别展示了atc corpus和aishell corpus中某个样本的语音信号可视化后的mel spectrogram。图4中(c)所示,采用了specaugment中的时频掩蔽技术,设定时间(频域)轴方向连续掩码的最大范围是250ms(100hz),在[0,250]([0,100])范围内进行均匀采样一个t(f),在[0,τ-t]([0,τ-f])范围内随机确定一个点t0(f0),从t0(f0)位置开始沿着时间(频域)轴方向连续进行t(f)次掩码。其中τ表示时间维度,v表示频域维度。
[0098]
在atc领域中,管制语音中存在不同来源信号干扰形成的噪音复合体。采用合成的高斯噪音融入源领域数据,是在处理这种复杂,且不知道噪音分布为何的情况下,一个既简单又不差的近似仿真。图4中(d)所示,展示了添加一定信噪比的高斯白噪声后生成的mel spectrogram。图4中(e)所示,进行了速度增强操作,参考了两种数据的平均语速,我们采用1.5x进行变换。基于以上三种变化后的语音信号称为improved aishell corpus。
[0099]
2方法
[0100]
2.1 gau模型
[0101]
transformer利用mhsa能够充分融合全局信息和强大的并行计算能力的优势在nlp和cv领域取得了很多突破。但大多数transformer因为输入长度的二次复杂度问题,仍然限于短上下文大小——由于记忆容量有限,不得不抛弃较早的信息。gau作为一种新的transformer变体,它依然具有二次复杂度,但是相比标准的transformer,它有着更快的训练速度、更低的显存占用以及更好的效果。其核心思路是将self-attention和glu作为一个统一层,并尽可能多地共享它们的计算。这样做不仅实现了更高的计算效率,而且自然地赋能一个强大的注意力门控机制。目前,gau已经在nlp任务中取得显著成功。因此,我们也尝试探究gau在asr领域的适用性,模型结构如图5所示。
[0102]
输入的时频域特征经过layer norm,再分别经过dense layer与非线性变换得到门控矩阵u与计算注意力的value,query和key;
[0103][0104][0105]
其中,t表示序列长度,d表示model size;e表示expanded intermediate size;s表示head size;表示激活函数;
[0106]
计算attention score采用relu2激活函数并加入relative position bias:
[0107][0108][0109]
其中,a是attention矩阵,负责融合token之间的信息;
⊙
表示element-wise multiplication;
[0110]
通过dropout layer防止模型训练过程出现过拟合现象。
[0111]
2.2模型整体架构
[0112]
mel spectrogram作为语音信号的可视化方式之一,同时包含着时域与频域信息。我们将它作为模型的输入,模型的整体结构由两部分组成,如图1所示。
[0113]
考虑到cnn能提供在时间和空间上的平移不变性卷积,将其思想应用到asr的声学建模中,则可以利用卷积的不变性来克服语音信号本身的多样性,因此第一部分由resnet构成。
[0114]
首先,输入经过7
×
7 conv layer,卷积核在工作时,会有规律地扫过输入特征,在感受野内对输入特征做矩阵元素乘法求和并叠加偏差量。其次,输出的特征图被传递至max pooling layer进行特征选择和信息过滤。pooling layer包含预设定的池化函数,将特征图中单个点的结果替换为其相邻区域的特征图统计量。最后,最大池化后的特征向量依次经过由不同数量的residual block(如图6所示)组成的堆,得到高度提纯的特征。其中block内部,堆与堆均引入shortcut connections,将输入跨层传递并与卷积的结果相加,缓解了在cnn中增加深度带来的梯度消失问题。flatten layer在模型的整体架构中起着桥梁作用,将resnet最终输出的特征进行降维处理作为第二部分的输入。
[0115]
第二部分主要由多个gau module串联而成,这种基于attention机制的module虽然解决了rnn不能并行计算的问题,但是无法捕捉词序信息。我们对输入添加了绝对位置编码,确保了在时间维度上的一致性。module与module之间同样进行residual connections,使信息前后向传播更加顺畅。输出传入dense layer在特征空间上进行线性变化后通过softmax层从而计算最终的分类预测概率。
[0116]
2.3训练与解码
[0117]
训练过程:ctc的引入解决了asr领域输入输出序列长度不同难以对齐的问题,通过引入特殊字符blank使语音序列每帧能一一对应的预测其在输出标签序列上的条件概率分布。给定长度为t的输入序列x(x1,x2,
…
,xt),v表示字典,在t时刻输出的向量y
t
通过softmax层,得到token k的概率:
[0118][0119]v~t
表示在v
~
定义的所有长度为t的路径集合。对于给定的输入序列x,v
~t
中任意路径a的条件概率计算公式为:
[0120][0121]
在路径概率的计算中,输入语音序列与输出路径的长度相等,这主要是通过在输出标签之间插入blank以及产生重token保证的。实际语音序列长度远大于标签序列长度,因此形成了输入到输出多对一的映射。而要得到预测序列,需要进行路径聚合(合并相同的连续标签,删除路径中的blank)并对所有路径概率求和。
[0122][0123]
其中,β-1
(y)表示集合v
~t
中与标签序列对应的所有路径。ctc最终的目标函数是所有标签的负对数概率和,可以通过反向传播多次迭代训练网络使损失最小化。
[0124]
ctc(x)=-logpr(y|x)
[0125]
解码过程:摈弃了传统的greedy algorithm,利用beam search。如图7所示,用广度优先策略建立搜索树,在树的每一层,按照启发代价对节点进行排序,然后仅留下预先确定的个数节点,这些节点在下一层次继续扩展,其他节点被剪掉。集束宽度可以是预先定好的,也可以是变动的,可以先按照一个最小的集束宽度进行搜索,如果没有找到合适的解,再扩大集束宽度找一遍。最后通过基于levenshtein距离的cer来评估搜索解与标准解的差异。
[0126]
本实施例中:
[0127]
本发明的输入统一为shape=(-1,3,64,512)的mel spectrogram,四个维度分别表示batch size,channel,height and width。batch size为64,训练阶段,利用前后向算法计算ctc目标函数损失,采用初始学习率设置为0.0001,超参数β1=0.9,β2=0.98,ε=10-9
的adam优化器更新模型权重。推理过程,采用宽度为5的集束搜索方法得到最后的预测文本。在extended aishell corpus比较了resnet34结合bilstm,bigru,mhsa glu和gau的实验结果;在atc corpus中,通过改变gau module的层数和使用不同的卷积结构进行了实验结果分析。
[0128]
1、不同模型在extended aishell corpus预训练实验结果
[0129]
我们的模型架构以resnet34_gau@24为例,参数设置如表2所示。对比模型中,bilstm与bigru模型堆叠层数均为4,每层隐藏单元数量为512。mhsa glu堆叠层数为24,其中每层采用8头自注意力,每头注意力维度为64。
[0130]
表2.details of architecture
[0131][0132]
具体训练过程损失曲线如图8所示,迭代轮数为20个epoch,一共74980step,其中每个step包含64个样本。前9000step,bilstm收敛速度明显过慢,bigru、mhsa glu相似,而gau的损失曲线在1000step之后斜率更大,下降更快,收敛速度明显更优于其他三种模型。最后9000step,bilstm与bigru收敛效果近似,训练损失波动范围较大;而mhsa glu与gau损失曲线振幅相对更小。
[0133]
每轮训练结束,对各个模型进行验证与测试。其中bilstm与bigru在图9中(a),(b)中展示了最低的cer分别是15.5%,17.6%和15.6%,17.4%;mhsa glu与gau取得的最低cer分别为10.9%,12.5%和10.3%,11.1%。在验证集上,我们的模型相对于基于循环神经网络的模型cer降低了33.5%,相对于基于多头注意力的模型降低了5.5%;在测试集上,相对降低了36.4%,11.2%。
[0134]
四类模型在cer,参数总量、运行时间和训练时间方面的对比如表3所示,模型参数总量为63.3m,分别是bilstm、bigru和mhsa glu的1.35、1.54和0.68倍同时在训练过程中每个step以及总时间更少的情况下,相较于其他模型,在识别效果上具有更强的竞争力。
[0135]
表3.不同模型的评估指标
[0136][0137]
2、不同层数的gau module在atc corpus实验结果
[0138]
我们的模型结构已经在源任务上取得了很好的效果,为了探究层数改变对目标任务最终识别结果的影响,我们保存了不同层数的gau module在extended aishell corpus测试过程中最优权重作为atc corpus数据集上训练的初始化参数。训练过程如图10所示,迭代轮数为10个epoch,一共15760step,其中每个step包含64个样本。12、24、36和48层的gau module都拥有较快的收敛速度。从15000step到迭代结束,展示了不同层数收敛效果,可以发现随着层数增加,收敛效果更加稳定。
[0139]
如图11中(a),(b)所示,不同层数的gau module在atc corpus验证与测试集上的cer对比。可以发现,当迭代完一轮后,12层gau module的cer已经达到了19%左右,而24、36和48层在15%左右。随着迭代轮数增加,最终12、24、36和48层gau module的最低cer分别为9.0%,8.5%,7.7%,7.4%和9.7%,9.2%,8.6%,8.2%,其中48层比12层的cer相对降低了17.8%和15.5%。
[0140]
如表4所示,随着层数的累积,模型的总参数量,训练时间呈线性增加。这种通过残差连接的gau module数量的增加对识别精度有显著提升。
[0141]
表4.不同层数的gau module在atc corpus的评估指标
[0142][0143]
3、不同卷积结构在atc corpus实验结果
[0144]
我们也尝试探究了不同卷积结构对目标任务实验结果的影响,如表5所示。为了保证总参数量近似,gau module采用48层并选取vgg16,vgg19,resnet34和resnet50作为实验对照。其中各个网络架构的训练花费时间差距不大,每个step分别为1.88s,2.31s,1.76s和2.01s并且训练总耗时保持在5h以内。各个模型在验证和测试集上的cer分别为8.0%,7.8%,7.9%,7.7%和8.3%,8.2%,8.2%,8.0%,虽然基于resnet结构的模型略优于vgg结构,但是不同的卷积结构对最终的识别率提升不大。
[0145]
表5、不同卷积结构在atc corpus的评估指标
[0146]
[0147]
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
