1.本发明属于人工智能安全领域,更具体地,涉及一种对抗样本生成模型的构建方法及应用。
背景技术:
2.随着人工智能的大规模应用,人工智能的安全问题逐渐成为限制人工智能应用规模的瓶颈,而人工智能安全中的对抗样本问题是保障人工智能安全中的关键问题,充分并高效的实现对抗样本的生成是实现人工智能安全的前提与要义。
3.为了更高效地生成神经网络中的对抗样本,需要通过一些算法对输入样本进行修改。其中,基于梯度的方法是一种有效的对抗样本生成算法,通过目标模型的梯度方向,指导对抗样本的生成过程,直到生成模型能够输出造成目标模型产生错误分类但与输入视觉相似的样本,即对抗样本。这种生成对抗样本的方法存在以下几个方面的问题,第一,由于基于梯度的方法需要沿梯度方向迭代修改样本以到达逃逸目的,因此,生成对抗样本时存在大量的重复查询,计算时间较长,计算效率较低;第二,该方法需要预先知晓目标模型的梯度,对模型梯度的依赖性较强,而现实应用中,目标模型的梯度是不可获取的;第三,该方法忽略了不同类别的图像在对抗样本的发现过程中存在不同约束数值的情况,对抗样本范数约束的差异性过小,精确度较低。
技术实现要素:
4.针对现有技术的以上缺陷或改进需求,本发明提供了一种对抗样本生成模型的构建方法及应用,用以解决现有技术存在的计算效率较低的技术问题。
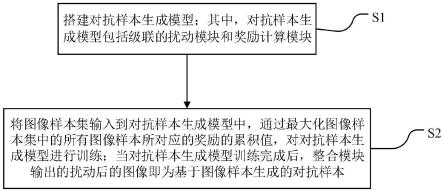
5.为了实现上述目的,第一方面,本发明提供了一种对抗样本生成模型的构建方法,包括以下步骤:
6.s1、搭建对抗样本生成模型;其中,对抗样本生成模型包括级联的扰动模块和奖励计算模块;
7.扰动模块用于对图像样本进行扰动,得到扰动后的图像;
8.奖励计算模块用于分别将扰动前和扰动后的图像输入到神经网络中进行目标检测,得到扰动前和扰动后的图像中的各目标类别及其对应的分类置信度;并计算扰动前和扰动后图像中各目标类别和对应分类置信度的变化,以及当前扰动前后和上一次扰动前后图像像素差异的比值,得到图像样本所对应的奖励;
9.s2、将图像样本集输入到对抗样本生成模型中,通过最大化图像样本集中的所有图像样本所对应的奖励的累积值,对对抗样本生成模型进行训练;当对抗样本生成模型训练完成后,扰动模块输出的扰动后的图像即为基于图像样本生成的对抗样本;
10.其中,图像样本集包括若干不同类别的图像样本及其对应的真实类别。
11.进一步优选地,上述扰动模块包括级联的奇异值分解模块、强化学习模型和整合模块;
12.奇异值分解模块用于对图像样本进行奇异值分解,得到图像样本的左奇异矩阵u、奇异值矩阵σ和右奇异矩阵v;
13.强化学习模型用于获取奇异值矩阵σ的扰动值;
14.整合模块用于基于奇异值矩阵σ的扰动值对奇异值矩阵σ进行扰动,得到扰动后的奇异值矩阵σ';计算uσ'v
t
,得到扰动后的图像。
15.进一步优选地,上述奇异值分解模块用于对图像样本按照通道进行奇异值分解,得到图像样本不同通道下的左奇异矩阵、奇异值矩阵和右奇异矩阵;
16.上述强化学习模型用于获取图像样本不同通道下的奇异值矩阵的扰动值;
17.上述整合模块用于基于图像样本不同通道下的奇异值矩阵的扰动值分别对对应通道下的奇异值矩阵进行扰动,得到不同通道下扰动后的奇异值矩阵;计算得到扰动后的图像;
18.其中,p为图像样本的通道数量;ui为图像样本第i个通道下的左奇异矩阵;σi'为图像样本第i个通道下扰动后的奇异值矩阵;vi为图像样本第i个通道下的右奇异矩阵。
19.进一步优选地,上述扰动模块包括级联的目标提取模块、奇异值分解模块、强化学习模型和整合模块;
20.目标提取模块用于提取图像样本中的目标区域,得到目标样本;
21.奇异值分解模块用于对目标样本进行奇异值分解,得到目标样本的左奇异矩阵u
t
、奇异值矩阵σ
t
和右奇异矩阵v
t
;
22.强化学习模型用于获取奇异值矩阵σ
t
的扰动值;
23.整合模块用于基于奇异值矩阵σ
t
的扰动值对奇异值矩阵σ
t
进行扰动,得到扰动后的奇异值矩阵σ'
t
;计算得到u
t
σ
t
'v
tt
后,替换图像样本中的目标区域,得到扰动后的图像。
24.进一步优选地,上述奇异值分解模块用于对目标样本按照通道进行奇异值分解,得到目标样本不同通道下的左奇异矩阵、奇异值矩阵和右奇异矩阵;
25.上述强化学习模型用于获取目标样本不同通道下的奇异值矩阵的扰动值;
26.上述整合模块用于基于目标样本不同通道下的奇异值矩阵的扰动值分别对对应通道下的奇异值矩阵进行扰动,得到不同通道下扰动后的奇异值矩阵;计算得到后,替换将目标样本中的目标区域,得到扰动后的图像;
27.其中,p为目标样本的通道数量;u
t_i
为目标样本第i个通道下的左奇异矩阵;σ
t_i’为目标样本第i个通道下扰动后的奇异值矩阵;v
t_i
为目标样本第i个通道下的右奇异矩阵。
28.进一步优选地,图像样本所对应的奖励包括:
29.r1=p1w130.r2=p2w231.[0032][0033]
其中,r1为当前扰动前和扰动后的图像中的目标类别不一致时的奖励;p1为当前扰动前和扰动后的图像中目标类别不一致的总数量;w1为当前扰动前和扰动后的图像中的目标类别不一致时的权重值;r2为当前扰动后的图像中存在未识别出类别的目标时的奖励;p2为当前扰动后的图像中所存在的未识别出类别的目标数量;w2为当前扰动后的图像中存在未识别出类别的目标时的权重值;r3为与当前扰动前相比,当前扰动后图像中目标的分类置信度下降时的奖励;k为图像样本中的目标数量;w3为与当前扰动前相比,当前扰动后图像中目标的分类置信度下降时的权重值;confj为当前扰动后图像中第j个目标的分类置信度;confj'为当前扰动前图像中第j个目标的分类置信度;r4为隐蔽性约束惩罚项;t为当前扰动所对应的扰动轮次;x
t-1
为当前扰动前的图像;x
t
为当前扰动后的图像;x
t-2
为当前扰动前的上一次扰动前的图像;||
·
||
p
表示p范数。
[0034]
进一步优选地,步骤s2包括:将图像样本集输入到对抗样本生成模型中,在满足图像样本的扰动值不超过其真实类别的扰动上界的条件下,通过最大化图像样本集中的所有图像样本所对应的奖励的累积值,对对抗样本生成模型进行训练。
[0035]
进一步优选地,类别l的扰动上界的获取方法包括:对真实类别为类别l的图像的奇异值进行重复扰动,直至扰动前后该图像出现像素级差异,此时,计算当前扰动前后图像像素的差异值作为类别l的扰动上界。
[0036]
进一步优选地,类别l的扰动上界的获取方法包括:分别对真实类别为类别l的若干图像分别执行如下操作:对图像的奇异值进行重复扰动,直至扰动前后该图像出现像素级差异,此时,计算当前扰动前后图像像素的差异值作为该图像的扰动上界;
[0037]
对所得各图像的扰动上界进行汇总,得到类别l的扰动上界。
[0038]
第二方面,本发明提供了一种对抗样本生成方法,包括:将图像输入到采用上述对抗样本生成模型的构建方法所构建的对抗样本生成模型中,得到该图像所对应的对抗样本。
[0039]
第三方面,本发明提供了一种对抗样本生成系统,包括:存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时执行本发明第二方面所提供的对抗样本生成方法。
[0040]
第四方面,本发明提供了一种对抗样本防御方法,包括:
[0041]
分别计算当前输入图像与对抗样本集中各对抗样本的相似度,若存在相似度小于预设阈值的情况,则将当前输入图像判定为对抗样本,将最小相似度所对应的对抗样本的原始图像类别作为当前输入图像的类别进行输出;
[0042]
其中,上述对抗样本集的获取方法,包括:采用上述对抗样本生成方法,生成不同类别的原始图像所对应的对抗样本。
[0043]
第五方面,本发明提供了一种对抗样本防御系统,包括:存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时执行本发明第四方面所提供的对抗样本防御方法。
[0044]
第六方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质
包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行本发明第一方面所提供的对抗样本生成模型的构建方法、本发明第二方面所提供的对抗样本生成方法、本发明第四方面所提供的对抗样本防御方法中的一种或多种。
[0045]
总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
[0046]
1、本发明提供了一种对抗样本生成模型的构建方法,构建了一个基于强化学习的对抗样本生成模型,考虑到扰动前后分类性能以及像素差异的变化来计算图像样本所对应的奖励,并通过最大化图像样本集中的所有图像样本所对应的奖励的累积值,对对抗样本生成模型进行训练,通过在对抗样本生成模型的训练过程中不断优化扰动值,使得查询朝向所期望的目标进行,规避了大量的重复查询,计算时间较短,计算效率较高。
[0047]
2、采用本发明所提供的对抗样本生成模型的构建方法所构建的对抗样本生成模型,并不需要预先知晓目标模型的梯度,能够高效地针对包括目标检测、图像识别等多种计算机视觉任务的神经网络生成对抗样本,适用于现实应用,实用性更强,适用范围更广。
[0048]
3、本发明所提供的对抗样本生成模型的构建方法,通过对奇异值矩阵进行扰动来对实现对输入图像的扰动,基于奇异值分解来获取结构化的特征,能够生成隐蔽性更强的对抗样本,所生成的对抗样本的质量较高。
[0049]
4、本发明所提供的对抗样本生成模型的构建方法,在对图像进行扰动时,首先通过目标提取模块提取图像样本中的目标区域,然后再对目标区域的奇异值矩阵进行针对性扰动,从而降低了生成对抗样本所需要的迭代次数,同时避免了图像整体奇异值变化对于部分小目标没有影响的情况。
[0050]
5、本发明所提供的对抗样本生成模型的构建方法,考虑到不同类别的图像在对抗样本的发现过程中存在不同约束数值,优先获取了图像不同类别的扰动上界,并在满足图像样本的扰动值不超过其真实类别的扰动上界的条件下,通过最大化图像样本集中的所有图像样本所对应的奖励的累积值,对对抗样本生成模型进行训练,该方法能够过滤明显不是对抗样本的图像,增加了对抗样本生成模型的精确度,同时也提高了对抗样本生成模型的训练效率。
[0051]
6、本发明提供了一种对抗样本防御方法,通过本发明所提供的基于上述对抗样本生成模型的对抗样本生成方法,生成不同类别的原始图像所对应的对抗样本,进而将当前输入图像与对抗样本集中各对抗样本进行相似度比对,从而确定当前输入图像是否为对抗样本,防御效率较高。
附图说明
[0052]
图1为本发明实施例1提供的对抗样本生成模型构建方法的流程图。
具体实施方式
[0053]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0054]
实施例1、
[0055]
一种对抗样本生成模型的构建方法,如图1所示,包括以下步骤:
[0056]
s1、搭建对抗样本生成模型;其中,对抗样本生成模型包括级联的扰动模块和奖励计算模块;
[0057]
扰动模块用于对图像样本进行扰动,得到扰动后的图像;
[0058]
奖励计算模块用于分别将扰动前和扰动后的图像输入到神经网络(本实施例优选为卷积神经网络)中进行目标检测,得到扰动前和扰动后的图像中的各目标类别及其对应的分类置信度;并计算扰动前和扰动后图像中各目标类别和对应分类置信度的变化,以及当前扰动前后和上一次扰动前后图像像素差异的比值,得到图像样本所对应的奖励;
[0059]
s2、将图像样本集输入到对抗样本生成模型中,通过最大化图像样本集中的所有图像样本所对应的奖励的累积值,对对抗样本生成模型进行训练;当对抗样本生成模型训练完成后,扰动模块输出的扰动后的图像即为基于图像样本生成的对抗样本;
[0060]
其中,图像样本集包括若干不同类别的图像样本及其对应的真实类别。
[0061]
通过上述方法所学习的优化扰动策略在对抗样本生成模型的训练过程中不断优化扰动值,使得查询朝向所期望的目标进行,规避了大量的重复查询,计算时间较短,计算效率较高;除此之外,对抗样本生成模型能够在无需目标模型梯度的前提下,高效地针对包括目标检测、图像识别等多种计算机视觉任务的神经网络生成对抗样本。
[0062]
具体地,图像样本所对应的奖励包括:
[0063]
r1=p1w1[0064]
r2=p2w2[0065][0066][0067]
其中,r1为当前扰动前和扰动后的图像中的目标类别不一致时的奖励;p1为当前扰动前和扰动后的图像中目标类别不一致的总数量;w1为当前扰动前和扰动后的图像中的目标类别不一致时的权重值;r2为当前扰动后的图像中存在未识别出类别的目标时的奖励;p2为当前扰动后的图像中所存在的未识别出类别的目标数量;w2为当前扰动后的图像中存在未识别出类别的目标时的权重值;r3为与当前扰动前相比,当前扰动后图像中目标的分类置信度下降时的奖励;k为图像样本中的目标数量;w3为与当前扰动前相比,当前扰动后图像中目标的分类置信度下降时的权重值;confj为当前扰动后图像中第j个目标的分类置信度;confj'为当前扰动前图像中第j个目标的分类置信度;r4为隐蔽性约束惩罚项;t为当前扰动所对应的扰动轮次;x
t-1
为当前扰动前的图像;x
t
为当前扰动后的图像;x
t-2
为当前扰动前的上一次扰动前的图像;||
·
||
p
表示p范数;这里的p范数可以为0范数、2范数和无穷范数,优选为2范数。
[0068]
需要说明的是,r1和r2分别是两种对抗样本的直接发现途径,即原始分类和目标分类不一致或目标分类不存在;r3为潜在的对抗样本发现途径,即当原始分类的置信度出现下降的情况;r4为对抗样本的隐蔽性约束惩罚项,即使用发现的对抗样本与原始样本的p范
数作为负的奖励值。
[0069]
需要说明的是,扰动模块基于奇异值分解来获取图像样本的结构化特征,通过对图像样本或者其上的目标样本的奇异值矩阵进行扰动来对实现对图像样本的扰动;其中,对抗样本生成模型的具体扰动目标,可以是完整的图像样本,也可以是图像样本中包含的目标部分(即目标样本)。
[0070]
在一种可选实施方式一下,上述扰动模块包括级联的奇异值分解模块、强化学习模型和整合模块;其中,奇异值分解模块用于对图像样本进行奇异值分解,得到图像样本的左奇异矩阵u、奇异值矩阵σ和右奇异矩阵v;强化学习模型用于获取奇异值矩阵σ的扰动值;整合模块用于基于奇异值矩阵σ的扰动值对奇异值矩阵σ进行扰动,得到扰动后的奇异值矩阵σ';计算uσ'v
t
,得到扰动后的图像。优选地,在上述可选实施方式一下,在对图像样本进行奇异值分解与整合时,上述奇异值分解模块用于对图像样本按照通道进行奇异值分解,得到图像样本不同通道下的左奇异矩阵、奇异值矩阵和右奇异矩阵。上述强化学习模型用于获取图像样本不同通道下的奇异值矩阵的扰动值。上述整合模块用于基于图像样本不同通道下的奇异值矩阵的扰动值分别对对应通道下的奇异值矩阵进行扰动,得到不同通道下扰动后的奇异值矩阵;计算得到扰动后的图像;其中,p为图像样本的通道数量;ui为图像样本第i个通道下的左奇异矩阵;σi'为图像样本第i个通道下扰动后的奇异值矩阵;vi为图像样本第i个通道下的右奇异矩阵。
[0071]
在另一种可选实施方式二下,为了利于加强目标物体的针对性扰动,降低生成对抗样本所需要的迭代次数,以及避免图像整体奇异值变化对于部分小目标没有影响的情况,上述扰动模块包括级联的目标提取模块、奇异值分解模块、强化学习模型和整合模块;其中,目标提取模块用于提取图像样本中的目标区域,得到目标样本;奇异值分解模块用于对目标样本进行奇异值分解,得到目标样本的左奇异矩阵u
t
、奇异值矩阵σ
t
和右奇异矩阵v
t
;强化学习模型用于获取奇异值矩阵σ
t
的扰动值;整合模块用于基于奇异值矩阵σ
t
的扰动值对奇异值矩阵σ
t
进行扰动,得到扰动后的奇异值矩阵σ'
t
;计算得到u
t
σ
t
'v
tt
后,替换将图像样本中的目标区域,得到扰动后的图像。需要说明的是,上述目标提取模块可以通过已知标签或着目标检测器来标定目标样本的大小和位置,以提取图像样本中的目标区域。具体地,在给定的标签的情况下,目标样本的位置和大小通过标签标定的位置和大小获取;而在没有给定标签的情况下,目标样本的大小和位置可以通过现有的预训练好的目标检测器对图像样本进行检测获取。优选地,在上述可选实施方式二下,在对图像样本进行奇异值分解与整合时,上述奇异值分解模块用于对图像样本按照通道进行奇异值分解,得到图像样本不同通道下的左奇异矩阵、奇异值矩阵和右奇异矩阵。上述奇异值分解模块用于对目标样本按照通道进行奇异值分解,得到目标样本不同通道下的左奇异矩阵、奇异值矩阵和右奇异矩阵;上述强化学习模型用于获取目标样本不同通道下的奇异值矩阵的扰动值;上述整合模块用于基于目标样本不同通道下的奇异值矩阵的扰动值分别对对应通道下的奇异值矩阵进行扰动,得到不同通道下扰动后的奇异值矩阵;计算得到后,替换将目标样本中的目标区域,得到扰动后的图像;其中,p为目标样本的通道数量;u
t_i
为
分别为三维图像不同通道所对应的奇异值矩阵的扰动值;按通道将奇异值矩阵与其对应的扰动值相加得到σ'=[σ1',σ2',σ3'];通过奇异值分解的逆向操作,得到新的图像即扰动后的状态。
[0081]
上述强化学习智能体根据自身包含的值函数网络ν(
·
)和q网络进行更新:
[0082][0083]
其中,λ是折扣因子,其取值通常为0.99,r
t
为t时刻智能体获得的奖励值,s
t 1
为t 1时刻强化学习智能体的状态。值函数网络ν(
·
)的更新方法为:
[0084][0085]
值函数的含义是在时序步骤t 1、在状态s上执行动作a所获得的预期奖励,因此,用于优化策略的损失函数的计算方式为:
[0086][0087]
其中,h0是熵的阈值,通常取值为-2;α是温度超参数,用于优化策略的随机性。
[0088]
本实施例通过依次更新策略网络p
φ
和值函数网络q
λ
来更新深度强化学习智能体。当深度强化学习智能体的迭代轮次超过某一阈值(本实施例中设置为1000)时,终止迭代终止。
[0089]
实施例2、
[0090]
一种对抗样本生成方法,包括:将图像输入到采用本发明实施例1所提供的对抗样本生成模型的构建方法所构建的对抗样本生成模型中,得到该图像所对应的对抗样本。
[0091]
相关技术方案同实施例1,这里不做赘述。
[0092]
实施例3、
[0093]
一种对抗样本生成系统,包括:存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时执行本发明实施例2所提供的对抗样本生成方法。
[0094]
相关技术方案同实施例2,这里不做赘述。
[0095]
实施例4、
[0096]
一种对抗样本防御方法,包括:
[0097]
分别计算当前输入图像与对抗样本集中各对抗样本的相似度,若存在相似度小于预设阈值的情况,则将当前输入图像判定为对抗样本,并对当前输入图像进行标记并拒绝当前输入图像进入目标系统,同时将最小相似度所对应的对抗样本的原始图像类别作为当前输入图像的类别进行输出;否则,将当前输入图像输入到神经网络中进行目标检测;本实施例中,上述预设阈值取值为0.1;
[0098]
其中,上述对抗样本集的获取方法,包括:采用本发明实施例2所提供的对抗样本生成方法,生成不同类别的原始图像所对应的对抗样本。
[0099]
需要说明的是,计算当前输入图像与对抗样本集中各对抗样本的相似度的方法有多种,本实施例中,通过计算当前输入图像与对抗样本集中各对抗样本的余弦相似度来对
二者之间的相似程度进行度量。具体地,余弦相似度的度量公式为:其中,x1和x2分别为当前输入图像和对抗样本集中的某一对抗样本。通过计算新的输入图像与已有对抗样本的余弦相似度实现对抗样本的防御。
[0100]
相关技术方案同实施例2,这里不做赘述。
[0101]
实施例5、
[0102]
一种对抗样本防御系统,包括:存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时执行本发明实施例4所提供的对抗样本防御方法。
[0103]
相关技术方案同实施例4,这里不做赘述。
[0104]
实施例6、
[0105]
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行本发明实施例1所提供的对抗样本生成模型的构建方法、本发明实施例2所提供的对抗样本生成方法、本发明实施例4所提供的对抗样本防御方法中的一种或多种。
[0106]
相关技术方案同实施例1、实施例2和实施例4,这里不做赘述。
[0107]
综上本发明的实施例1-实施例6可知,本发明在测量图像类别的扰动边界时,通过对照实验和极值过滤的方法获取恰当的扰动边界值。在输入图像奇异值分解时,对三通道的输入分别做三次奇异值分解,并将获取的奇异值进行存储,有效增强了视觉隐蔽性强的对抗样本发现。在循环扰动图像奇异值矩阵时,应用深度强化学习训练得到一个优化的扰动策略,从而降低每发现一个对抗样本所需的查询次数。在对抗样本生成与防御时,通过设置合适的奖励函数以优化生成的过程,并通过奇异值矩阵的相似度比较方法来防御已发现的样本。理论和实验证明,与现有的dpatch、autoattacker、zoo等方法相比,本发明所提供的对抗样本生成模型在对抗样本生成精度,样本迁移能力,查询次数等方面均有更优的表现。
[0108]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
