技术特征:
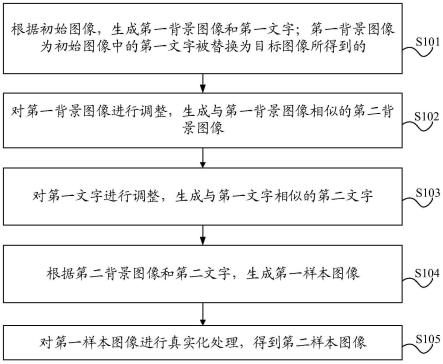
1.一种生成样本图像的方法,包括:根据初始图像,生成第一背景图像和第一文字;所述第一背景图像为所述初始图像中的所述第一文字被替换为目标图像所得到的;对所述第一背景图像进行调整,生成与所述第一背景图像相似的第二背景图像;对所述第一文字进行调整,生成与所述第一文字相似的第二文字;根据所述第二背景图像和所述第二文字,生成第一样本图像;对所述第一样本图像进行真实化处理,得到第二样本图像。2.根据权利要求1所述的方法,其中,所述根据初始图像,生成第一背景图像和第一文字,包括:获取所述第一文字在所述初始图像中的第一位置信息;根据所述第一位置信息,提取所述第一文字;在所述初始图像中去除所述第一文字,得到中间图像;在所述第一位置信息处填充所述目标图像,得到所述第一背景图像。3.根据权利要求2所述的方法,其中,所述获取所述第一文字在所述初始图像中的第一位置信息,包括:确定所述第一文字的多个矩形框;在所述矩形框中确定面积最小的矩形框的矩形框位置;根据所述矩形框位置确定所述第一位置信息。4.根据权利要求1-3任一项所述的方法,其中,所述对所述第一背景图像进行调整,生成与所述第一背景图像相似的第二背景图像,包括:根据所述第一背景图像在预设的第三背景图像中确定第二背景图像,所述第二背景图像与所述第一背景图像之间的相似度大于预定相似度。5.根据权利要求4所述的方法,其中,所述根据所述第一背景图像在预设的第三背景图像中确定第二背景图像,包括:提取所述第一背景图像的第一图像特征和所述第三背景图像的第二图像特征;其中,所述第一图像特征为基于预设特征提取模型所得到的数据特征,所述第二图像特征为基于所述预设特征提取模型所得到的数据特征;或者,所述第一图像特征为基于颜色直方图所得到的颜色特征,所述第二图像特征为基于颜色直方图所得到的颜色特征;根据所述第一图像特征和所述第二图像特征,确定所述相似度;将相似度大于预定相似度的第三背景图像,确定为所述第二背景图像。6.根据权利要求1-3任一项所述的方法,其中,所述对所述第一背景图像进行调整,生成与所述第一背景图像相似的第二背景图像,包括:对所述第一背景图像进行图像增强处理,生成所述第二背景图像。7.根据权利要求1-6任一项所述的方法,其中,所述对所述第一文字进行调整,生成与所述第一文字相似的第二文字,包括:调整所述第一文字的文字颜色和文字字体,生成所述第二文字。8.根据权利要求1-7任一项所述的方法,其中,所述第一文字具有第一位置信息,所述第一位置信息表征所述第一文字在所述初始图像中的位置;
所述根据所述第二背景图像和所述第二文字,生成第一样本图像,包括:获取所述第一文字在所述初始图像中的位置信息;根据所述第一位置信息,将所述第二文字填充至所述第二背景图像中,得到所述第一样本图像。9.根据权利要求1-8任一项所述的方法,其中,所述对所述第一样本图像进行真实化处理,得到第二样本图像,包括:对所述第一样本图像进行高斯模糊处理,得到第三样本图像;基于预设的渲染模型对所述第三样本图像进行真实化处理,得到所述第二样本图像。10.根据权利要求9所述的方法,其中,所述预设的渲染模型为基于第一待训练图像和第二待训练图像,对预设的生成器和预设的判别器进行训练所得到的;其中,所述第一待训练图像具有第一标签,所述第一标签表征所述第一待训练图像为合成的图像;所述第二待训练图像具有第二标签,所述第二标签表征所述第二待训练图像为真实的图像;所述预设的生成器为用于对所述第一待训练图像进行真实性增强处理的模型,所述预设的判别器为用于对真实性增强处理后的第一待训练图像和所述第二待训练图像进行识别的模型。11.一种文字识别模型的训练方法,包括:获取待训练的第二样本图像;其中,所述待训练的第二样本图像是通过对由第二背景图像和第二文字生成的第一样本图像进行真实化处理得到的;所述第二背景图像为对初始图像生成的第一背景图像进行调整,得到的与所述第一背景图像相似的图像,所述第二文字为对所述初始图像生成的第一文字进行调整,得到的与所述第一文字相似的文字;所述第一背景图像是通过将所述初始图像中的第一文字替换为目标图像所得到的;将所述待训练的第二样本图像输入至初始模型,得到所述初始模型识别出的第三文字;基于所述第三文字、所述第二文字以及预设损失函数,更新所述初始模型,得到文字识别模型;其中,所述文字识别模型用于识别待识别的图像中的文字。12.一种文字识别方法,包括:获取待识别的图像;将所述待识别的图像输入至所述文字识别模型,得到所述待识别的图像中的文字的第二位置信息;其中,所述文字识别模型是基于待训练的第二样本图像训练得到的;其中,所述待训练的第二样本图像是通过对由第二背景图像和第二文字生成的第一样本图像进行真实化处理得到的;所述第二背景图像为对初始图像生成的第一背景图像进行调整,得到的与所述第一背景图像相似的图像,所述第二文字为对所述初始图像生成的第一文字进行调整,得到的与所述第一文字相似的文字;所述第一背景图像是通过将所述初始图像中的第一文字替换为目标图像所得到的;根据所述第二位置信息,确定并输出所述待识别的图像中的文字。13.一种生成样本图像的装置,包括:第一生成单元,用于根据初始图像,生成第一背景图像和第一文字;所述第一背景图像为所述初始图像中的所述第一文字被替换为目标图像所得到的;
第一调整单元,用于对所述第一背景图像进行调整,生成与所述第一背景图像相似的第二背景图像;第二调整单元,用于对所述第一文字进行调整,生成与所述第一文字相似的第二文字;第二生成单元,用于根据所述第二背景图像和所述第二文字,生成第一样本图像;处理单元,用于对所述第一样本图像进行真实化处理,得到第二样本图像。14.根据权利要求13所述的装置,其中,所述第一生成单元,包括:第一获取模块,用于获取所述第一文字在所述初始图像中的第一位置信息;第一提取模块,用于根据所述第一位置信息,提取所述第一文字;去除模块,用于在所述初始图像中去除所述第一文字,得到中间图像;第一填充模块,用于在所述第一位置信息处填充所述目标图像,得到所述第一背景图像。15.根据权利要求14所述的装置,其中,所述第一获取模块,包括:第一确定子模块,用于确定所述第一文字的多个矩形框;第二确定子模块,用于在所述矩形框中确定面积最小的矩形框的矩形框位置;第三确定子模块,用于根据所述矩形框位置确定所述第一位置信息。16.根据权利要求13-15任一项所述的装置,其中,所述第一调整单元,具体用于:根据所述第一背景图像在预设的第三背景图像中确定第二背景图像,所述第二背景图像与所述第一背景图像之间的相似度大于预定相似度。17.根据权利要求16所述的装置,其中,所述第一调整单元,包括:第二提取模块,用于提取所述第一背景图像的第一图像特征和所述第三背景图像的第二图像特征;其中,所述第一图像特征为基于预设特征提取模型所得到的数据特征,所述第二图像特征为基于所述预设特征提取模型所得到的数据特征;或者,所述第一图像特征为基于颜色直方图所得到的颜色特征,所述第二图像特征为基于颜色直方图所得到的颜色特征;第一确定模块,用于根据所述第一图像特征和所述第二图像特征,确定所述相似度;第二确定模块,用于将相似度大于预定相似度的第三背景图像,确定为所述第二背景图像。18.根据权利要求13-15任一项所述的装置,其中,所述第一调整单元,具体用于:对所述第一背景图像进行图像增强处理,生成所述第二背景图像。19.根据权利要求13-18任一项所述的装置,其中,所述第二调整单元,具体用于:调整所述第一文字的文字颜色和文字字体,生成所述第二文字。20.根据权利要求13-19任一项所述的装置,其中,所述第一文字具有第一位置信息,所述第一位置信息表征所述第一文字在所述初始图像中的位置;所述第二生成单元,包括:第二获取模块,用于获取所述第一文字在所述初始图像中的第一位置信息;第二填充模块,用于根据所述第一位置信息,将所述第二文字填充至所述第二背景图像中,得到所述第一样本图像。21.根据权利要求13-20任一项所述的装置,其中,所述处理单元,包括:第一处理模块,用于对所述第一样本图像进行高斯模糊处理,得到第三样本图像;
第二处理模块,用于基于预设的渲染模型对所述第三样本图像进行真实化处理,得到所述第二样本图像。22.根据权利要求21所述的装置,其中,所述预设的渲染模型为基于第一待训练图像和第二待训练图像,对预设的生成器和预设的判别器进行训练所得到的;其中,所述第一待训练图像具有第一标签,所述第一标签表征所述第一待训练图像为合成的图像;所述第二待训练图像具有第二标签,所述第二标签表征所述第二待训练图像为真实的图像;所述预设的生成器为用于对所述第一待训练图像进行真实性增强处理的模型,所述预设的判别器为用于对真实性增强处理后的第一待训练图像和所述第二待训练图像进行识别的模型。23.一种文字识别模型的训练装置,包括:第一获取单元,用于获取待训练的第二样本图像;其中,所述待训练的第二样本图像是通过对由第二背景图像和第二文字生成的第一样本图像进行真实化处理得到的;所述第二背景图像为对初始图像生成的第一背景图像进行调整,得到的与所述第一背景图像相似的图像,所述第二文字为对所述初始图像生成的第一文字进行调整,得到的与所述第一文字相似的文字;所述第一背景图像是通过将所述初始图像中的第一文字替换为目标图像所得到的;第二获取单元,用于将所述待训练的第二样本图像输入至初始模型,得到所述初始模型识别出的第三文字;更新单元,用于基于所述第三文字、所述第二文字以及预设损失函数,更新所述初始模型,得到文字识别模型;其中,所述文字识别模型用于识别待识别的图像中的文字。24.一种文字识别装置,包括:第三获取单元,用于获取待识别的图像;第四获取单元,用于将所述待识别的图像输入至所述文字识别模型,得到所述待识别的图像中的文字的第二位置信息;其中,所述文字识别模型是基于待训练的第二样本图像训练得到的;其中,所述待训练的第二样本图像是通过对由第二背景图像和第二文字生成的第一样本图像进行真实化处理得到的;所述第二背景图像为对初始图像生成的第一背景图像进行调整,得到的与所述第一背景图像相似的图像,所述第二文字为对所述初始图像生成的第一文字进行调整,得到的与所述第一文字相似的文字;所述第一背景图像是通过将所述初始图像中的第一文字替换为目标图像所得到的;确定单元,用于根据所述第二位置信息,确定并输出所述待识别的图像中的文字。25.一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1-12中任一项所述的方法。26.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据权利要求1-12中任一项所述的方法。27.一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现权利要
求1-12中任一项所述方法的步骤。
技术总结
本公开提供了生成样本图像的方法以及文字识别模型的训练方法,涉及人工智能领域,尤其涉及深度学习、图像处理、计算机视觉等技术领域,可应用于光学字符识别等场景。具体实现方案为:根据初始图像,生成第一背景图像和第一文字;其中,第一背景图像为初始图像中的所述第一文字被替换为目标图像所得到的。对第一背景图像进行调整,生成与第一背景图像相似的第二背景图像;对第一文字进行调整,生成与第一文字相似的第二文字。根据第二背景图像和第二文字,生成第一样本图像;对第一样本图像进行真实化处理,得到第二样本图像,进而增加最终得到的第二样本图像,提高训练得到的文字识别模型的准确度。别模型的准确度。别模型的准确度。
技术研发人员:徐杨柳 谢群义 陈毅 钦夏孟 章成全 姚锟
受保护的技术使用者:北京百度网讯科技有限公司
技术研发日:2022.06.13
技术公布日:2022/9/2
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。