1.本发明属于生物信号处理、机器学习与智能控制领域,具体的说是一种基于面颈部表面肌电的无声语音解码方法。
背景技术:
2.语音是人类日常生活中必不可少的有效便利的交流方式。在过去几十年中,以自动语音识别(automatic speech recognition,asr)技术为代表的语音相关的人机交互技术发展迅速,一般场景下已表现出非常高的性能。然而,由于依赖发声的语音,asr的缺点非常明显。如在高噪声背景下无法保证有效工作,无法满足私密性交互需求,并且发声障碍人群无法凭借asr进行日常交流。
3.为了克服上述缺点,研究人员探索了非声学语音识别方法。在人们说话和默读的过程中,与发音相关的面部和颈部肌肉群被激活,产生生物电信号,称为表面肌电图(surface electromyogram,semg)。因此,基于semg的无声语音识别(silent speech recognition,ssr)已成为某些特殊场景下的一种asr的重要补充方式。基于semg的ssr技术经过几十年的发展,取得了一些进展。早期的ssr主要使用经典的模式分类方法,如支持向量机、共轭梯度网络等;用通道数量较少的分立式电极记录受试者面部和颈部的semg,对词语数量有限的语料库进行识别。之后的研究倾向于使用刻画semg时序信息的隐马尔可夫模型(hidden markov model,hmm)对词汇数量较多的语料库进行识别。随着数据采集技术的发展,高密度(high-density,hd)电极阵列被设计用于同时记录目标肌肉或一组肌肉在相对大的区域内的大量通道表面肌电信号。高密度表面肌电信号(hd-semg)阵列的使用有助于捕捉珍贵的空间信息,表征肌肉活动的异质性,从而提高肌电模式识别的性能。
4.虽然上述研究证明了模式分类技术在实现令人满意的ssr性能方面的可用性,但仍存在一些不足。如1)依赖模式分类方法,简单地将短语或单词于semg模式特征之间进行映射,忽略了时序关联的语义信息。2)分类技术的性能受到语料库中词汇数量的限制。3)常用的模式分类技术主要用于孤立词的识别,无法实现自然连贯的无声语音交互。
技术实现要素:
5.本发明是为了解决上述现有技术存在的不足之处,提出一种基于面颈部表面肌电的无声语音解码方法,以期能识别语音序列的更细粒度结构并理解语音内容,从而提高发音相似的短语的识别性能,最终能实现准确自然的无声语音交互。
6.本发明为达到上述发明目的,采用如下技术方案:
7.本发明一种基于面颈部表面肌电的无声语音解码方法的特点在于,包括如下步骤:
8.步骤一、构建一个包含n个中文短语的指令集p={p1,
…
,pn,
…
,pn},pn表示指令集p中第n个中文短语,且n个中文短语共包含l类音节;
9.使用高密度电极阵列采集用户默读中文短语时面部和颈部肌肉所产生的表面肌
电信号,并使用基于短时能量和过零率的双阈值检测方法标注所述表面肌电信号中的静息信号段和短语对应的表面肌电信号段,从而形成带有标注的各个短语信号段并构成训练短语数据集s
p
;
10.步骤二、用一系列前后具有时间重叠的信号窗分割所述训练短语数据集s
p
,得到m个信号窗样本,并按照所述短语信号段包含的音节数量均分各个短语信号段,再结合各个短语信号段的音节顺序,对每个信号窗样本进行细粒度的音节的标注,从而得到具有音节标注的m个信号窗样本组成的一批训练数据集;
11.步骤三、改变信号窗的切分时刻,以调整每个信号窗的分窗边界后,按照步骤二的过程进行处理,从而得到k批具有音节标注的训练数据集其中,表示第k批具有音节标注的训练数据集,且表示第k批具有音节标注的训练数据集,且表示第k批数据的第m个信号窗样本,表示对应的音节标注,且采用独热编码表示,的尺寸为[1,l];s
origin
共包含m
×
k个信号窗样本;
[0012]
步骤四、提取训练数据集s
origin
的肌电特征:
[0013]
步骤4.1、使用连续不重叠的帧对每个信号窗样本进行切分处理,得到d帧的信号窗数据;
[0014]
步骤4.2、根据高密度电极阵列的信号通道相对的位置,将高密度电极阵列所采集的表面肌电信号转换为二维电极通道阵列的表面肌电数据矩阵,其尺寸记为[e,g];
[0015]
步骤4.3、提取每帧信号窗数据的c个肌电特征,从而得到每帧的三维肌电特征图;进而获得所有信号窗样本的三维肌电特征图集表示第k批数据的第m个信号窗样本的d帧三维肌电特征图,的尺寸记为[d,e,g,c],表示第k批数据的第m个信号窗样本的音节标注;
[0016]
步骤五、构建基于刻画时空信息的深度神经网络,包括:a个包含时间分布层的扩张卷积块、压平层、a个双向门控循环单元块和a个全连接层,并将三维肌电特征图集s
input
按k个批次输入所述深度神经网络;
[0017]
步骤5.1、任意第a个扩张卷积块包括一个扩张卷积层,一个批归一化层和一个dropout层;且第a个扩张卷积层采用ha个维度为h
×
h的二维卷积核,并采用tanh激活函数;
[0018]
当a=1时,第k批的三维肌电特征图集输入所述第a个扩张卷积块中进行处理,输出第k批的第a个特征图为表示第k批三维肌电特征图集中第m个信号窗样本输出的特征图,尺寸为[d,e,g,ha];
[0019]
当a=2,3,
…
,a时,将第k批的第a-1个特征图输入所述第a个扩张卷积块中进行处理,输出第k批的第a个特征图从而由第a个扩张卷积块输出最终的特征图
[0020]
步骤5.2、所述特征图经过所述压平层的处理后,得到第k批的压平特征集
其中,表示第k批第m个特征图经过所述压平层后输出的特征图,尺寸为[d,e
×g×
ha];
[0021]
步骤5.3、任意第a个双向门控循环单元块包括一个采用relu激活函数的双向门控循环单元层和一个dropout层,所述双向门控循环单元层中的隐藏节点的维度均为b;
[0022]
当a=1时,所述第k批的压平特征集输入所述第a个双向门控循环单元块中进行处理,并输出第k批的第a个门控特征集表示特征图经过第a个双向门控循环单元块处理后输出的门控特征,尺寸为[d,2
×
b];
[0023]
当a=2,3,
…
,a-1时,将第k批的第a-1个特征集输入所述第a个双向门控循环单元块中进行处理,并输出第k批的第a个门控特征集从而由第a-1个双向门控循环单元块输出第k批的第a-1个门控特征集尺寸为[d,2
×
b];
[0024]
当a=a时,第k批的第a-1个门控特征集输入所述第a个双向门控循环单元块中进行处理,并输出第k批的第a个门控特征集尺寸为[1,2
×
b];
[0025]
步骤5.4、令前a-1个全连接层的激活函数采用tanh,且各连接一个dropout层,第a个全连接层的激活函数是softmax;
[0026]
由第a个双向门控循环单元块输出的门控特征集依次经过a个全连接层的处理后,输出音节决策序列的得分矩阵其中,表示第k批数据的第m个信号窗样本分别被预测为l个音节的概率,且其中,表示第k批数据的第m个样本被预测为第j类音节的概率;
[0027]
步骤5.5、利用式(1)建立交叉熵损失函数loss:
[0028][0029]
式(1)中,为第k批数据的第m个信号窗样本对应的音节标注中第j个位置的取值;
[0030]
步骤5.6、训练神经网络:
[0031]
采用adam优化器更新所述深度神经网络的权重参数,设置最大迭代次数step并动态改变网络学习率lr,在损失函数loss达到最小或迭代次数等于step时,停止训练,从而得到最优音节分类模型;
[0032]
步骤六、根据中文短语的指令集p构建统计语言模型,从而对最优音节分类器结果进行后处理:
[0033]
步骤6.1、建立音节标签序列到中文短语的多对一映射关系θ;
[0034]
步骤6.2、将待解码的一个中文短语p'按照步骤二的过程进行处理,得到具有音节标注的u个待解码的信号窗样本;再对u个待解码的信号窗样本按照步骤四的过程进行处
理,得到待解码的三维肌电特征图集;
[0035]
步骤6.3、所述待解码的三维肌电特征图集输入最优音节分类模型中,并输出中文短语p'的音节标签序列的得分矩阵其中,表示中文短语p'的第u个音节的得分概率矩阵,u表示音节序列的长度;
[0036]
步骤6.4、令每个音节的搜索深度为depth,并利用多集束搜索算法对进行处理,从而获得u
depth
种音节标签序列以及u
depth
个得分;
[0037]
步骤6.5、判断u
depth
种音节标签序列是否与所述多对一映射关系θ匹配成功,若匹配成功,则,从中选取与匹配且得分最高的音节标签序列所对应的短语并输出,否则,执行步骤6.6;
[0038]
步骤6.6、从中文短语p'的第u个音节的得分矩阵中选择得分概率最大的音节记为从而得到音节决策序列选择多对一映射关系映射θ中与音节决策序列的编辑距离最小的短语作为所述中文短语p'的解码结果。
[0039]
与现有技术相比,本发明的有益效果在于:
[0040]
1、本发明在原有短语semg数据的基础上进行数据分割得到细粒度音节表面肌电数据,建立了扩张卷积双向门控循环单元神经网络(dc-bigru)作为分类器,进一步地提出了统计语言模型刻画语义信息,对经训练的分类器的输出进行提炼和纠错,获得了对短语序列的准确预测,从而通过一种解码框架实现了准确自然的无声语音识别。
[0041]
2、本发明通过一种训练数据自动标注方法,有助于简化训练数据的准备过程;与此同时本发明提出一种基于调整分窗边界的数据增强方法,有效地缓解了深度网络的过拟合现象,提升了无声语音识别的性能。
[0042]
3、本发明在细粒度级别着手研究,提出了基于多集束搜索和编辑距离的统计语言模型,利用短语集合的语义时序关联信息,有助于理解短语的含义,提升了相似发音短语的识别性能。
[0043]
4、本发明按照实时系统的数据处理要求,实现了高性能自然连贯的无声语音识别,从而有助于本发明方法在肌电控制等领域的实际应用。
附图说明
[0044]
图1为本发明一种基于面颈部表面肌电的无声语音解码方法的流程图;
[0045]
图2为本发明涉及的中文发音短语集;
[0046]
图3为本发明采用的面颈部高密度电极阵列形状参数和贴放位置说明图;
[0047]
图4为本发明采用的数据分割、数据自动标注和数据增强方法示意图;
[0048]
图5为本发明高密度电极阵列中的空间位置分布及拼接结果的示意图;
[0049]
图6为本发明使用的基于扩张卷积双向门控循环单元(dc-bigru)的分类网络的结构示意图;
[0050]
图7为本发明得到的平均短语识别率和标准差示意图;
[0051]
图8a为本发明得到的基于dc-bigru短语分类的混淆矩阵示意图;
[0052]
图8b为本发明得到的基于所提的dcbimep解码方法的混淆矩阵示意图。
具体实施方式
[0053]
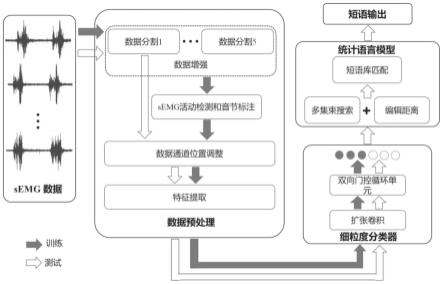
在本实施例中,一种基于面颈部表面肌电的无声语音解码方法,啊利用统计语言模型提取时序相关的语义信息不仅可以提高发音相似的短语的识别性能,还有助于理解semg活动对应的短语的含义,为无声语音识别方法提供了一个新思路,具体的说,如图1所示,包括以下步骤:
[0054]
步骤一、构建一个包含n个中文短语的指令集p={p1,
…
,pn,
…
,pn},pn表示指令集p中第n个中文短语,且n个中文短语共包含l类音节;如图2所示,中文发音词汇集由n=30个短语构成,包括79类中文音节和1类静息音节,l=80;
[0055]
使用高密度电极阵列采集用户默读中文短语时面部和颈部肌肉所产生的表面肌电信号,并使用基于短时能量和过零率的双阈值检测方法标注表面肌电信号中的静息信号段和短语对应的表面肌电信号段,从而形成带有标注的各个短语信号段并构成训练短语数据集sp。本实施例中,实验募集了7位男性一位女性共8名年龄在21~26岁、无听力或语言障碍的健康受试者,参加数据采集实验。每一个实验步骤和具体要求都明确告知每一位受试者。
[0056]
高密度电极阵列形状参数和贴放位置如图3所示。共有四片高密度柔性电极阵列,面部和颈部左右两侧各有两片对称的阵列。示例性的,两片面部电极阵列通道数均为16,电极直径为5mm,电极间距范围在10、15、18mm;两片颈部电极阵列通道数也均为16,电极直径为5mm,电极间距为18mm。面颈部电极阵列共同组成了64通道阵列。此外,左右两侧耳后各贴附一片电极,作为参考和地电极;
[0057]
在贴附电极阵列之前,用酒精棉垫擦洗受试者面部和颈部的目标肌肉以清洁皮肤角蛋白,同时在电极探针上涂抹适量的导电凝胶以降低皮肤阻抗。示例性的,面部电极阵列用于采集颧肌、咬肌和降下唇肌等面部肌肉的semg,颈部电极阵列用于采集肩胛舌骨肌、胸骨舌骨肌和颈阔肌等颈部肌肉的semg。采集过程中,受试者以中等力度匀速无声表达每个短语,每个短语重复20次作为一次试验,短语每次重复间隔时间为t,示例性的,t设置为3s。在每次试验中,不允许如吞咽唾液和咳嗽等与采集任务无关的行为。为了避免受试者的肌肉疲劳,在两次试验之间有t的休息时间,示例性的,t取为30s;
[0058]
对原始数据进行semg活动检测,结果如图4中的a部分所示,在本实施例中,使用基于短时能量和过零率的双阈值检测方法对原始数据进行semg活动检测,获得静息信号段和每个短语对应信号段标注。首先,计算静息状态基线的短时能量和过零率作为初始能量和初始过零率,记为e_i和c_i;短时样本用于计算原始数据的短时能量和过零率,长度为s_length。该方法需要设定三个阈值,前两个阈值是由短期能量值设定的高、低阈值分别记为e_h和e_l,用于对起始位置和偏移位置进行初始判断;第三个是短期过零率的阈值sc,示例性的,s_length设置为64ms,e_h设置为8
×
e_i,e_l设置为3
×
e_i,sc设置为3
×
c_i;得到静息信号段和每个短语对应信号段的标注;
[0059]
步骤二、用一系列前后具有时间重叠的信号窗分割训练短语数据集s
p
,得到m个信号窗样本;如图4中的b部分所示,用于数据分割的滑动窗长为w_length,重叠率为overlap,示例性的,w_length设置为1000ms,overlap设置为50%;按照短语信号段包含的音节数量均分各个短语信号段,再结合各个短语信号段的音节顺序,对每个信号窗样本进行细粒度的音节的标注,结果见图4中的b部分,本实施例中,根据每个短语包含的音节个数平分检测
的信号段,标注相应的音节标签,其中79类音节标签分别记为1-79,静息样本标签记为0;根据信号窗样本在不同音节标注下的时间跨度,为信号窗标注相应的音节标签,得到具有音节标注的训练数据集;
[0060]
步骤三、改变信号窗的切分时刻,以调整每个信号窗的分窗边界后,按照步骤二的过程进行处理,从而得到k批具有音节标注的训练数据集其中,表示第k批具有音节标注的训练数据集,且且表示第k批数据的第m个信号窗样本,表示对应的音节标注,并采用独热编码表示,尺寸为[1,l];s
origin
共包含m
×
k个信号窗样本;本实施例中,如图4中的c部分所示,每批数据分割的初始位置在上批的基础上后移δ/5,由上述音节标注方法得到k批具有标注的信号窗样本,本实施例中,m=327,k=5,δ设置为500ms;
[0061]
步骤四、提取训练数据集s
origin
的肌电特征:
[0062]
步骤4.1、使用连续不重叠的帧对每个信号窗样本进行切分处理,得到d帧的信号窗数据;本实施例中,连续不重叠的帧的帧长为f_length=40ms;
[0063]
步骤4.2、如图5所示,根据高密度电极阵列的信号通道相对的位置,将高密度电极阵列所采集的表面肌电信号转换为二维电极通道阵列的表面肌电数据矩阵,其尺寸记为[e,g];本实施例中,设置e=8,g=8;
[0064]
步骤4.3、提取每帧信号窗数据的c个肌电特征,从而得到每帧的三维肌电特征图;进而获得所有信号窗样本的三维肌电特征图集表示第k批数据的第m个信号窗样本的d帧三维肌电特征图,的尺寸记为[d,e,g,c],表示第k批数据第m个信号窗样本的音节标注;本实施例中,c=4,提取的4个肌电时域特征,分别为平均绝对值(mean absolute value,mav)、波形长度(waveform length,wl)、过零点数(zero crossingpoints,zc)和斜率符号变化数(slope sign change number,ssc),每个信号窗样本特征图帧数为d=25,特征图尺寸为[25,8,8,4],最终得到所有信号窗样本的特征图所构成的数据库s
input
作为神经网络的输入。
[0065]
步骤五、构建基于刻画时空信息的深度神经网络,包括:a个包含时间分布层的扩张卷积块、压平层、a个双向门控循环单元块和a个全连接层,并将三维肌电特征图集s
input
按k个批次输入深度神经网络;如图6所示,刻画时空信息的深度神经网络由a个包含时间分布层的扩张卷积块、压平层、a个双向门控循环单元块和全连接层构成;本实施例中,a=2;
[0066]
步骤5.1、任意第a个扩张卷积块包括一个扩张卷积层,一个批归一化层和一个dropout层;
[0067]
步骤5.1、任意第a个扩张卷积块包括一个扩张卷积层,一个批归一化层和一个dropout层;且第a个扩张卷积层采用ha个维度为h
×
h的二维卷积核,并采用tanh激活函数;
[0068]
当a=1时,第k批的三维肌电特征图集输入第a个扩张卷积块中进行处理,输出第k批的第a个特征图为表示第k批三维肌电特征图集中第m个信号窗样本输出的特征图,尺寸为[d,e,g,ha];
[0069]
当a=2,3,
…
,a时,将第k批的第a-1个特征图输入第a个扩张卷积块中进行处理,输出第k批的第a个特征图从而由第a个扩张卷积块输出最终的特征图本实施例中,第一个扩张卷积层由h1=32个3
×
3的滤波器组成,扩张率为1,第二个扩张卷积层由h2=8个3
×
3的滤波器组成,扩张率为3,两个dropout层比率均为0.5;尺寸为[25,8,8,32],尺寸为[25,8,8,8];
[0070]
步骤5.2、特征图经过压平层的处理后,得到第k批的压平特征集经过压平层的处理后,得到第k批的压平特征集其中,表示第k批第m个特征图经过压平层后输出的特征图,尺寸为[d,e
×g×
ha];本实施例中,尺寸为[25,512];
[0071]
步骤5.3、任意第a个双向门控循环单元块包括一个采用relu激活函数的双向门控循环单元层和一个dropout层,双向门控循环单元层中的隐藏节点的维度均为b;
[0072]
当a=1时,第k批的压平特征集输入第a个双向门控循环单元块中进行处理,并输出第k批的第a个门控特征集表示特征图经过第a个双向门控循环单元块处理后输出的门控特征,尺寸为[d,2
×
b];
[0073]
当a=2,3,
…
,a-1时,将第k批的第a-1个特征集输入第a个双向门控循环单元块中进行处理,并输出第k批的第a个门控特征集从而由第a-1个双向门控循环单元块输出第k批的第a-1个门控特征集尺寸为[d,2
×
b];
[0074]
当a=a时,第k批的第a-1个门控特征集输入第a个双向门控循环单元块中进行处理,并输出第k批的第a个门控特征集尺寸为[1,2
×
b];本实施例中,每个双向门控循环单元块包括1个采用relu激活函数的双向门控循环单元层和1个dropout层,两层双向门控循环单元的隐藏节点维度均为b=64,dropout比率为0.4;尺寸为[25,128],尺寸为[1,128];
[0075]
步骤5.4、前a-1个全连接层的激活函数采用tanh,且各连接一个dropout层,第a个全连接层的激活函数是softmax;
[0076]
由第a个双向门控循环单元块输出的门控特征集依次经过a个全连接层的处理后,输出音节决策序列的得分矩阵其中,表示第k批数据的第m个信号窗样本分别被预测为l个音节的概率,且其中表示网络将第k批数据的第m个样本预测为第j类音节的概率;本实施例中,第1个全连接层的激活函数采用tanh,隐藏节层维度为200,连接1个比率为0.2的dropout层,第2个全连接层的隐藏节点维度为80;
[0077]
步骤5.5、利用式(1)建立交叉熵损失函数loss:
[0078][0079]
式(1)中,为第k批数据的第m个信号窗样本对应的音节标注中第j个位置的取值;本实施例中,独热编码长度为80,且只有一个位置的值为1,其余为0,每个批次包含m个样本,损失函数由k个批次样本交叉熵加权求和得到;
[0080]
步骤5.6、训练神经网络:
[0081]
采用adam优化器更新深度神经网络的权重参数,设置最大迭代次数step并动态改变网络学习率lr,在损失函数loss达到最小或迭代次数等于step时,停止训练,从而得到最优音节分类模型;本实施例中,step=300,初始学习率lr=0.01,每迭代100次,学习率变为lr=0.1
×
lr。
[0082]
步骤六、根据中文短语的指令集p构建统计语言模型,从而对最优音节分类器结果进行后处理:
[0083]
步骤6.1、建立音节标签序列到中文短语的多对一映射关系θ;本实施例中,不同受试者的语速有一定差异,且难以保证重复默读同一个短语时的语速相同,导致相同短语的信号窗样本的个数不同,因此,音节标签序列到短语是多对一的映射。
[0084]
步骤6.2、将待解码的一个中文短语p'按照步骤二的过程进行处理,得到具有音节标注的u个待解码的信号窗样本;再对u个待解码的信号窗样本按照步骤四的过程进行处理,得到待解码的三维肌电特征图集;
[0085]
步骤6.3、待解码的三维肌电特征图集输入最优音节分类模型中,并输出中文短语p'的音节标签序列的得分矩阵其中,表示中文短语p'的第u个音节的得分概率矩阵,u表示音节序列的长度;
[0086]
步骤6.4、令每个音节的搜索深度为depth,并利用多集束搜索算法对进行处理,从而获得u
depth
种音节标签序列以及u
depth
个得分;
[0087]
步骤6.5、判断u
depth
种音节标签序列是否与多对一映射关系θ匹配成功,若匹配成功,则,从中选取与匹配且得分最高的音节标签序列所对应的短语并输出,否则,执行步骤6.6;
[0088]
步骤6.6、从中文短语p'的第u个音节的得分矩阵中选择得分概率最大的音节记为从而得到音节决策序列选择多对一映射关系映射θ中与音节标签序列的编辑距离最小的短语作为中文短语p'的解码结果。
[0089]
本实施例中,depth设置为5,由式(2)从与多对一映射关系θ匹配成功的标签序列中选取得分最高的音节标签序列所对应的短语
[0090][0091]
式(2)中,表示匹配成功的短语对应的得分,max{
·
}返回得分最大值对应的短语短语表示短语指令集p中的一个短语。由式(3)得到音节标签序列式(3)中,argmax{
·
}返回每一个音节得分矩阵得分最高的音节。
[0092][0093]
在本实施例中,为了量化评估本发明的效果,将本发明的解码方法与传统分类方法进行比较,本发明解码方法记为dcbimep。对比实验中,共采用四种常用短语分类方法,与本发明的dcbimep形成对比。四种分类方法分别记为hmm、扩张卷积神经网络(dilated convolutional neural network,dcnn)、双向门控循环单元(bidirectional gated recurrent unit,bigru)和dc-bigru。四种方法的数据准备过程是:对原始肌电数据进行semg活动检测,提取每个短语对应的semg活动数据,并标记上相应的短语标签,对带标签的短语数据进行特征提取,获得所有短语的特征数据。此外,为了验证数据增强对本发明方法的有效性,本发明方法按是否进行数据增强推导出两种方法,分别记为dcbimep和aug-dcbimep,后者表示进行数据增强后的本发明方法。图7为上述6种方法在8名受试者数据上短语识别准确度(phrase recognition accuracy,pra)结果,4种传统短语分类方法的pra分别为(82.74
±
7.48)%,(83.06
±
7.31)%,(87.92
±
5.82)%和(90.49
±
5.47)%,可以看出,刻画时空信息的dc-bigru性能最好。本发明方法dcbimep的pra是(97.27
±
1.44)%,性能明显优于4种对比短语分类方法。aug-dcbimep的pra在本发明方法的基础上提升0.91%,达到(98.18
±
1.44)%,证明了所提的数据增强对于本发明方法的有效性。
[0094]
图8a和图8b显示了4种分类对比方法中表现最好的dc-bigru和本发明方法在受试者2数据上的短语识别混淆矩阵。可以明显地看出,dc-bigru对于发音相似短语如“减速”和“加速”以及“左转”和“右转”的识别性能不如本发明方法。
[0095]
结合上述的对比实验以及识别结果,可以得到以下结论,包括:1)本发明提出的解码方法能高效识别发音相似的短语,提升无声语音系统的性能。2)本发明提出的调整分窗边界的数据增强方法能在原有方法基础上进一步提升性能。3)统计语言模型有效利用短语的语义时序关联信息,有助于理解短语的含义,实现高精度的自然连续的无声语音交互。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。