1.本发明属于医疗卫生技术领域,特别涉及一种基于最值限定的人工耳蜗语音信号净化方法。
背景技术:
2.人工耳蜗是目前世界上仅有的一种帮助重度听力损失患者恢复听力和具有耳聋基因的先天耳聋患者产生听力的仿生设备。它通过在患者的耳蜗内植入电极阵列直接刺激听觉神经来代替缺失的毛细胞以实现听力感知,对患者正常进行社会生活具有重要的意义。
3.现有的人工耳蜗系统已经能够让植入者在相对安静的环境下进行交谈,但是在噪声环境中,语音信号噪声值较高,人工耳蜗植入者的使用感不佳,对语音的感知效果依然较差一些,这对其社会交往有着严重的制约。因此,对噪声环境中的含噪声的语音信号进行更深度的净化处理从而来提高人工耳蜗植入者在噪声环境中的语音感知能力是目前人工耳蜗研究的关键问题之一。
技术实现要素:
4.本发明提出了一种基于最值限定的人工耳蜗语音信号净化方法,目的是通过对人工耳蜗采集到的语音信号中的噪声信号进行消噪处理,从而让人工耳蜗的语音编码器获得更为纯净的语音信号进而提升人工耳蜗植入者的语音感知力。
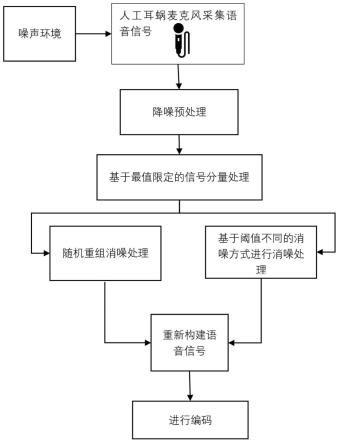
5.本发明所述的一种基于最值限定的人工耳蜗语音信号净化方法包括以下步骤:
6.s1首先对通过人工耳蜗外机麦克风采集的带有噪声的语音信号进行适应变换,得到初始降噪后的语音信号;
7.s2对进行过步骤s1降噪预处理后的语音信号进行基于最值限定的信号分量处理;
8.s3将含噪声程度低的信号分量与含噪声程度高的信号分量采用不同的消噪方法进行消噪处理;
9.s4对分别通过随机重组消噪和通过基于信号分量阈值不同的消噪方式进行消噪处理后的信号分量进行组合,重新构建完整的语音信。
10.进一步,所述步骤s1包括:
11.将由人工耳蜗的麦克风在噪音环境下采集到的带噪声的语音信号记为y(t),t表示时间。用x(t)表示带噪声语音信号中的纯净语音信号,b(t)表示带噪声语音信号中的噪声信号。则可用下列表达式来表示y(t)、x(t)、b(t)三者之间的关系:
12.y(t)=x(t) μb(t),μ是系数,μ=log
y(t)
x(t)。
13.对带噪声语音信号进行适应变换,则y(t)的适应变换为ε表示适应变换因子。则x(t)的适应变换为μb(t)的适应变换为
14.本发明所使用的适应变换公式与现有变换公式相比较大程度的减少对语音信号的损伤,进而防止信号的失真,且具有更好的降噪效果。
15.设立x(t)和μb(t)相互独立,所以经过适应变换后的和也是相互独立的,且假定噪声服从零均值高斯分布。
16.则通过上述适应变换可得到:则得到
[0017][0018][0019]
通过模的近似预算得到:
[0020][0021]
根据无语音信号逼近有语音信号的噪声信号,得到:
[0022]
由此得到纯净语音信号的估计值为:对估计的纯净语音信号进行回归适应变换即得到降噪后的语音信号为f(t),具体运算方式如下所示:
[0023][0024]
本发明所采用的对人工耳蜗麦克风所采集到的原始语音信号进行预处理降噪的方法适用的信噪比范围较宽,较大程度的提前减小了后续进行信号分解对信号的质量产生的影响。
[0025]
进一步,所述步骤s2包括:
[0026]
s21将语音信号f(t)作为待分量信号,求出每个周期为t的信号的有效值,得到待分量信号的有效信号h0(t),h0(t)的具体计算公式如下所示:
[0027]
[]表示取整数,d为语音信号f(t)的步长。
[0028]
本发明所创建的求周期信号有效值的方法对信号进行分量处理与现有技术相比计算简单且迅速,很大程度的提升了信号分量的速度进而进一步提升对人工耳蜗的噪声消除效果。
[0029]
判断f0(t)=f(t)-h0(t)是否满足下列条件:
[0030]
条件
①
:在一个闭合信号波形周期t内f0(t)=f0(t-t);
[0031]
条件
②
:在整段f0(t)信号中,|num[最值点]-num[f0(t)=0]|≤1,num[最值点]表示信号f0(t)中最值点的数量,num[f0(t)=0]表示信号f0(t)中过零点值的数量。
[0032]
若满足则将f0(t)=f1(t),作为第一个信号分量,否则将f0(t)作为新的待分量信号,重复上述步骤,得到新的f0(t),并对其进行上述步骤的条件判断。直到满足条件
①
和条
件
②
,将此时的f0(t)记作第一个信号分量的阈值θ1,并且得到第一个信号分量f1(t)。
[0033]
通过第一个信号分量的处理得到语音信号f(t)的剩余信号l1(t),则l1(t)=f(t)-f1(t)。
[0034]
s22将剩余信号l1(t)作为待分量信号,进行本发明所述的s21步骤的处理,得到满足条件
①
和条件
②
的f0(t),将此时的f0(t)记作θ2,进而得到第二个信号分量f2(t)。如此反复进行,直到剩余信号lm(t)小于终止阈值则信号分量结束。
[0035]
将进行了m次信号分解后的信号分量记为{f1(t),f2(t),f3(t),
…
,fm(t)},任意一个信号分量可以用fm(t)进行表示,m={1,2,3,...,m},用lm(t)表示进行第m次信号分量后的剩余信号。
[0036]
将进行m次信号分量的阈值记为{θ1,θ2,θ3,
…
,θm},任意一个信号分量的阈值用θm进行表示。
[0037]
本发明所采用的基于最值限定的信号分量处理方法与现有技术相比更好的自适应性,较大程度的减少了有用信号的丢失,较好的保持了各个信号分量的完整性。
[0038]
s23计算任意一个信号分量的自体关联系数的函数表达式为:
[0039]039]
为参数,表示fm(t)的均值,表示的均值。
[0040]
设置阈值作为衡量分量信号的含噪声程度,当mm(t)小于阈值,将fm(t)视为含噪声程度低的信号分量,任意一个含噪声程度低的信号分量记为fi(t);当mm(t)大于或者等于阈值,将fm(t)视为含噪声程度高的信号分量,任意一个含噪声程度高的信号分量记为fj(t)。i∈[1,k],j∈[k 1,m],且k∈m。
[0041]
本发明所采用的对信号的含噪声程度进行阈值分类的方法简便迅速,且对噪声程度的分类更加明确,更有益于接下来的消噪工作。
[0042]
进一步,所述步骤s3包括:
[0043]
s31对含噪声程度低的信号分量fi(t)采用本发明所创建的随机重组的方式进行消噪处理。
[0044]
对信号分量fi(t)的特征元素的序列进行随机重组得到{f
i2
(t),f
i3
(t),...,f
in
},n表示第n次随机重组。任意一个随机重组后的信号分量用f
in
(t)表示,n={2,3,...,n}。
[0045]
对进行随机重组处理后的信号分量fi(t)进行消噪处理,得到消噪后的信号分量fi(t)
′
。具体的消噪处理方式如下所示:
[0046][0047]
max{f
in
(t)}表示fi(t)进行n次的随机重组f
in
(t)中的最大值,min{f
in
(t)}表示fi(t)进行n次的随机重组f
in
(t)中的最小值。通过噪声能量特性可知n越大,fi(t)
′
越小,噪声能量越小。
[0048]
重复上述步骤依次对f1(t)~fk(t)进行随机重组处理,进一步得到消噪处理后的f1(t)~fk(t),记为f1(t)
′
~fk(t)
′
。
[0049]
本发明采用的对含噪声程度低的信号分量进行随机重组的方式进行信号处理使
信号在较低的信噪比下对语音的可懂度损伤较小,兼顾了语音的可懂度和自然度。
[0050]
s32分别对含噪声程度高的不同信号分量fj(t)进行本发明创建的基于信号分量阈值不同的消噪方法进行消噪处理。
[0051]
根据信号分量阈值的不同对信号分量进行消噪处理,其消噪函数如下所示:
[0052][0053]
θj∈θm,表示第j信号分量的阈值,γ为可变的参数值,且γ∈[0,1],β为消噪函数的常数。θj的值不同,fj(t)采用不同的消噪函数进行消噪处理,得到消噪后的信号分量f
j*
(t)。
[0054]
本发明采用根据信号分量阈值的不同对信号分量进行消噪处理的方法区别对待了不同的信号分量,有效的防止了信号的过度处理导致信号的丢失和混乱,较好的保持了信号的完整性。
[0055]
进一步,所述步骤s4包括:
[0056]
对进行消噪处理后的信号分量进行组合,重新构建完整的语音信号,得到表示重新构建后的语音信号。
[0057]
重新构建完整语音信号的具体公式如下所示:
[0058][0059]
将重新构建后的语音信号作为人工耳蜗语言编码器的编码目标,对人工耳蜗植入者来说在较大噪声环境下也能够感知到较为清晰的语音,实现语音信号净化,较大程度的提升了人工耳蜗植入者的语言感知力。
[0060]
本发明至少具有以下有益效果:
[0061]
1、本发明所采用的对人工耳蜗麦克风所采集到的原始语音信号进行预处理降噪的方法适用的信噪比范围较宽,较大程度的提前减小了后续进行信号分解对信号的质量产生的影响。
[0062]
2、本发明所采用的基于最值限定的信号分量处理方法与现有技术相比更好的自适应性,较大升读的减少了有用信号的丢失,较好的保持了各个信号分量的完整性。
[0063]
3、本发明采用的对含噪声程度低的信号分量进行随机重组的方式进行信号处理使信号在较低的信噪比下对语音的可懂度损伤较小,兼顾了语音的可懂度和自然度。
[0064]
4、本发明采用根据信号分量阈值的不同对信号分量进行消噪处理区别对待了不同的信号分量,有效的防止了信号的过度处理导致信号的丢失和混乱,较好的保持了信号的完整性,实现语音信号净化。
附图说明
[0065]
图1本发明所述的一种基于最值限定的人工耳蜗语音信号净化方法流程图;
[0066]
图2本发明所述的基于最值限定进行信号分量的步骤图。
具体实施方式
[0067]
为了更清楚的说明本发明,下面将结合说明书附图和具体实施例来做详细说明。
[0068]
参考图1,本发明提出了一种基于最值限定的人工耳蜗语音信号净化方法,包括以下步骤:
[0069]
s1首先对通过人工耳蜗外机麦克风采集的带有噪声的语音信号进行适应变换,得到初始降噪后的语音信号。
[0070]
将由人工耳蜗的麦克风在噪音环境下采集到的带噪声的语音信号记为y(t),t表示时间。用x(t)表示带噪声语音信号中的纯净语音信号,b(t)表示带噪声语音信号中的噪声信号。则可用下列表达式来表示y(t)、x(t)、b(t)三者之间的关系:
[0071]
y(t)=x(t) μb(t),μ是系数,μ=log
y(t)
x(t)。
[0072]
对带噪声语音信号进行适应变换,则y(t)的适应变换为ε表示适应变换因子。则x(t)的适应变换为μb(t)的适应变换为
[0073]
本发明所使用的适应变换公式与现有变换公式相比较大程度的减少对语音信号的损伤,进而防止信号的失真,且具有更好的降噪效果。
[0074]
假设x(t)和μb(t)相互独立,所以经过适应变换后的和也是相互独立的,且假定噪声服从零均值高斯分布。
[0075]
则通过上述适应变换可得到:则得到
[0076][0077][0078]
通过模的近似预算得到:
[0079][0080]
根据无语音信号逼近有语音信号的噪声信号,得到:由此得到纯净语音信号的估计值为:对估计的纯净语音信号进行回归适应变换即得到降噪后的语音信号为f(t),具体运算方式如下所示:
[0081][0082]
本发明所采用的对人工耳蜗麦克风所采集到的原始语音信号进行预处理降噪的方法适用的信噪比范围较宽,较大程度的提前减小了后续进行信号分解对信号的质量产生的影响。
[0083]
s2参考图2,对进行过步骤s1降噪预处理后的语音信号进行基于最值限定的信号分量处理。
[0084]
s21将语音信号f(t)作为待分量信号,求出每个周期为t的信号的有效值,得到待分量信号的有效信号h0(t),h0(t)的具体计算公式如下所示:
[0085]
[]表示取整数,d为语音信号f(t)的步长。
[0086]
本发明所创建的求周期信号有效值的方法对信号进行分量处理与现有技术相比计算简单且迅速,很大程度的提升了信号分量的速度进而进一步提升对人工耳蜗的噪声消除效果。
[0087]
判断f0(t)=f(t)-h0(t)是否满足下列条件:
[0088]
条件
①
:在一个闭合信号波形周期t内f0(t)=f0(t-t);
[0089]
条件
②
:在整段f0(t)信号中,|num[最值点]-num[f0(t)=0]|≤1,num[最值点]表示信号f0(t)中最值点的数量,num[f0(t)=0]表示信号f0(t)中过零点值的数量。
[0090]
若满足则将f0(t)=f1(t),作为第一个信号分量,否则将f0(t)作为新的待分量信号,重复上述步骤,得到新的f0(t),并对其进行上述步骤的条件判断。直到满足条件
①
和条件
②
,将此时的f0(t)记作第一个信号分量的阈值θ1,并且得到第一个信号分量f1(t)。
[0091]
通过第一个信号分量的处理得到语音信号f(t)的剩余信号l1(t),则l1(t)=f(t)-f1(t)。
[0092]
s22将剩余信号l1(t)作为待分量信号,进行本发明所述的s21步骤的处理,得到满足条件
①
和条件
②
的f0(t),将此时的f0(t)记作θ2,进而得到第二个信号分量f2(t)。如此反复进行,直到剩余信号lm(t)小于终止阈值则信号分量结束。
[0093]
将进行了m次信号分解后的信号分量记为{f1(t),f2(t),f3(t),...,fm(t)},任意一个信号分量可以用fm(t)进行表示,m={1,2,3,...,m},用lm(t)表示进行第m次信号分量后的剩余信号。
[0094]
将进行m次信号分量的阈值记为{θ1,θ2,θ3,
…
,θm},任意一个信号分量的阈值用θm进行表示。
[0095]
本发明所采用的基于最值限定的信号分量处理方法与现有技术相比更好的自适应性,较大程度的减少了有用信号的丢失,较好的保持了各个信号分量的完整性。
[0096]
s23计算任意一个信号分量的自体关联系数的函数表达式为:
[0097][0097]
为参数,表示fm(t)的均值,表示的均值。
[0098]
设置阈值作为衡量分量信号的含噪声程度,当mm(t)小于阈值,将fm(t)视为含噪声程度低的信号分量,任意一个含噪声程度低的信号分量记为fi(t);当mm(t)大于或者等于阈值,将fm(t)视为含噪声程度高的信号分量,任意一个含噪声程度高的信号分量记为fj(t)。i∈[1,k],j∈[k 1,m],且k∈m。
[0099]
本发明所采用的对信号的含噪声程度进行阈值分类的方法简便迅速,且对噪声程
度的分类更加明确,更有益于接下来的消噪工作。
[0100]
s3将含噪声程度低的信号分量与含噪声程度高的信号分量采用不同的消噪方法进行消噪处理;
[0101]
s31对含噪声程度低的信号分量fi(t)采用本发明所创建的随机重组的方式进行消噪处理。
[0102]
对信号分量fi(t)的特征元素的序列进行随机重组得到{f
i2
(t),f
i3
(t),...,f
in
},n表示第n次随机重组。任意一个随机重组后的信号分量用f
in
(t)表示,n={2,3,...,n}。
[0103]
对进行随机重组处理后的信号分量fi(t)进行消噪处理,得到消噪后的信号分量fi(t)
′
。具体的消噪处理方式如下所示:
[0104][0105]
max{f
in
(t)}表示fi(t)进行n次的随机重组f
in
(t)中的最大值,min{f
in
(t)}表示fi(t)进行n次的随机重组f
in
(t)中的最小值。通过噪声能量特性可知n越大,fi(t)
′
越小,噪声能量越小。
[0106]
重复上述步骤依次对f1(t)~fk(t)进行随机重组处理,进一步得到消噪处理后的f1(t)~fk(t),记为f1(t)
′
~fk(t)
′
。
[0107]
本发明采用的对含噪声程度低的信号分量进行随机重组的方式进行信号处理使信号在较低的信噪比下对语音的可懂度损伤较小,兼顾了语音的可懂度和自然度。
[0108]
s32分别对含噪声程度高的不同信号分量fj(t)进行本发明创建的基于信号分量阈值不同的消噪方法进行消噪处理。
[0109]
根据信号分量阈值的不同对信号分量进行消噪处理,其消噪函数如下所示:
[0110][0111]
θj∈θm,表示第j信号分量的阈值,γ为可变的参数值,且γ∈[0,1],β为消噪函数的常数。θj的值不同,fj(t)采用不同的消噪函数进行消噪处理,得到消噪后的信号分量f
j*
(t)。
[0112]
本发明采用根据信号分量阈值的不同对信号分量进行消噪处理的方法区别对待了不同的信号分量,有效的防止了信号的过度处理导致信号的丢失和混乱,较好的保持了信号的完整性。
[0113]
s4对分别通过随机重组消噪和通过基于信号分量阈值不同的消噪方式进行消噪处理后的信号分量进行组合,重新构建完整的语音信号。
[0114]
对进行消噪处理后的信号分量进行组合,重新构建完整的语音信号,得到表示重新构建后的语音信号。
[0115]
重新构建完整语音信号的具体公式如下所示:
[0116]
[0117]
将重新构建后的语音信号作为人工耳蜗语言编码器的编码目标,对人工耳蜗植入者来说在较大噪声环境下也能够感知到较为清晰的语音,实现语音信号净化,较大程度的提升了人工耳蜗植入者的语言感知力。
[0118]
综上所述,实现了本发明所述的一种基于最值限定的人工耳蜗语音信号净化方法。
[0119]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0120]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0121]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0122]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
