1.本发明涉及音频处理领域,特别涉及一种基于多模态的沉浸声生成方法及装置。
背景技术:
2.随着科学技术的发展,人们对高质量音频的需求越来越大。相比传统的单声道(mono)音频,stereo(立体声)、5.1声道等音频信号。
3.现有技术中,输入音频经过上混处理,得到输出音频,包含stereo上混到5.1声道、5.1声道上混到更多声道的沉浸声等,仅仅是基于音频信号进行上混处理,由于缺乏视频信息的指导,上混处理后的音频在影院播放时,音效还有一定的欠缺,且会存在音视频内容不一致的现象。
技术实现要素:
4.基于此,本技术实施例提供了一种基于多模态的沉浸声生成方法及装置,能够结合视频信息进行上混处理,可以有效提升沉浸声的音效,且保证视音视频播放内容的一致性,进而有效提升沉浸声播放效果。
5.第一方面,提供了一种基于多模态的沉浸声生成方法,该方法包括:
6.获取样本视频的视频信息和音频信息;其中,所述音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;
7.将所述样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到所述上混处理模型的模型参数,并基于所述模型参数对上混处理模型进行更新;
8.将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声,其中所述视频信息中至少包括运动信息和位置信息。
9.可选地,该方法还包括:
10.将直接声源作为中置声道进行声像平移处理,得到左声道信号和右声道信号;
11.根据背景声进行去相关处理,获得后置左环绕声道信号和后置右环绕声道信号;并将直接声源进行低通处理得到重低音声道信号;
12.将左声道信号、右声道信号、后置左环绕声道信号、后置右环绕声道信号、重低音声道信号合并得到5.1声道音频信号。
13.可选地,将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,包括:
14.结合左右声道音频信号进行立体声参数提取,得到立体声参数;其中,所述立体声参数信息包括声道间时间差和声道间能量差;
15.根据左右声道频域信号、立体声参数信息及视频信息进行声源分离,得到直接声源和背景声;其中,所述视频信息包括运动信息和位置信息;
16.基于直接声源和背景声,经过音频处理,得到5.1声道音频信号。
17.可选地,所述声道间时间差通过第一公式进行确定,所述第一公式具体包括:
18.itd=argmax{φ
lr
(m)}
19.其中,
20.φ
lr
为归一化互相关函数。
21.可选地,所述声道间能量差通过第二公式进行确定,所述第二公式具体包括:
[0022][0023]
其中,x
l
为左声道音频信号,xr为右声道音频信号。
[0024]
可选地,该方法还包括:
[0025]
针对左声道音频信号和右声道音频信号基于快速傅立叶变换进行处理,得到左右声道音频频域信号;
[0026]
基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,所述cnn处理包括针对视频信息中的rgb和flow参数分别进行处理;
[0027]
针对所述左右声道频域信号输入至unet网络,并将包含运动信息的特征图添加到瓶颈层,并进行分离处理和方位处理,得到一阶ambisonics信号中x、y和z信号;
[0028]
基于左右声道音频信号进行下混处理,得到mono信号;
[0029]
将mono信号作为w信号,结合得到的x、y、z信号得到foa音频信号。
[0030]
可选地,该方法还包括:
[0031]
基于左右声道音频信号进行下混处理,得到单声道音频和立体声参数;其中,所述立体声参数信息包括声道间时间差和声道间能量差;
[0032]
针对左声道音频信号和右声道音频信号基于快速傅立叶变换进行处理,得到左右声道音频频域信号;
[0033]
基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,所述cnn处理包括针对视频信息中的rgb和flow参数分别进行处理;
[0034]
针对所述左右声道频域信号输入至unet网络,并将基于视频提取的包含运动信息的特征图与所述立体声参数添加到瓶颈层,并进行分离处理和方位处理,得到一阶ambisonics信号中x、y和z信号;
[0035]
进行音频处理,将下混处理的单声道音频作为w信号,结合得到的x、y、z信号得到foa音频信号。
[0036]
可选地,该方法还包括:
[0037]
将5.1声道音频信号中的左声道信号、右声道信号、后置左环绕声道信号、后置右环绕声道信号、重低音声道信号进行快速傅立叶变换得到音频频域信号;
[0038]
基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,所述cnn处理包括针对视频信息中的rgb和flow参数分别进行处理;
[0039]
针对所述音频频域信号输入至unet网络,并将包含运动信息的特征图添加到瓶颈层,并进行分离处理和方位处理,得到一阶ambisonic信号中x、y和z信号;
[0040]
基于输入5.1声道音频和一阶ambisonic信号中x、y和z信号,得到包含高度信息的沉浸声音频信号。
[0041]
可选地,所述声源分离包括基于音频时域信号进行处理和/或基于音频频域信号进行处理。
[0042]
第二方面,提供了一种基于多模态的沉浸声生成装置,该装置包括:
[0043]
获取模块,用于获取样本视频的视频信息和音频信息;其中,所述音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;
[0044]
训练模块,用于将所述样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到所述上混处理模型的模型参数,并基于所述模型参数对上混处理模型进行更新;
[0045]
计算模块,用于将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声,其中所述视频信息中至少包括运动信息和位置信息。
[0046]
本技术实施例提供的技术方案中首先获取样本视频的视频信息和音频信息;其中,音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;然后将样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到上混处理模型的模型参数,并基于模型参数对上混处理模型进行更新;最后将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声。本发明的有益效果在于结合视频信息,针对多声道音频进行上混处理,可以有效提升沉浸声音效,保证视音视频播放内容的一致性,进而有效提升沉浸声播放效果。此外,本发明也可以为混音师提供协助信息,进一步提升混音效果。
附图说明
[0047]
为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。
[0048]
图1为本技术实施例提供的一种基于多模态的沉浸声生成方法的技术流程图;
[0049]
图2为本技术实施例提供的一种基于多模态的沉浸声生成方法的技术原理图;
[0050]
图3为本技术中实施例一的技术流程图;
[0051]
图4为本技术中实施例一中提供的另一种技术流程图;
[0052]
图5为本技术中实施例二的技术流程图;
[0053]
图6为本技术中实施例二中提供的另一种技术流程图;
[0054]
图7为本技术中实施例三的技术流程图。
具体实施方式
[0055]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
[0056]
在本发明的描述中,除非另有说明“多个”的含义是两个或两个以上。本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等旨在区别指代的对象。对于具有时序流程的方案,这种术语表述方式不必理解为描述特定的顺序或先后次序,对于装置结构的方案,这种术语表述方式也不存在对重要程度、位置关系的区分等。
[0057]
此外,术语“包括”、“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包括了一系列步骤或单元的过程、方法、装置、产品或设备不必限于已明确列出的那些步骤或单元,而是还可包含虽然并未明确列出的但对于这些过程、方法、产品或设备固有的其它步骤或单元,或者基于本发明构思进一步的优化方案所增加的步骤或单元。
[0058]
随着科学技术的发展,人们对高质量音频的需求越来越大。相比传统的单声道(mono)音频,stereo(立体声)、5.1声道等音频信号,ambisonics由于包含了空间信息,极大提升了人们的听感。
[0059]
其中,立体声信号包含左声道和右声道,由于两个声道之间存在时间差、能量差等,因此具有各声源的方位感和分布感,能够有效提高信息的可懂度,进而可以提高节目的力量感、临场感、层次感和解析度,公知的立体声由直接音源和环境声组成。
[0060]
5.1声道包含l(左声道)、c(中置声道)、r(右声道)、ls(后置左环绕声道)、rs(后置右环绕声道)以及sub(重低音声道)等音频信号,其中,l、c、r、ls、rs这五个声道是相互独立的,sub则可以产生频响范围20~120hz的超低音。中置声道,主要是负责人物对白的部分;左、右声道,则是用来弥补在屏幕中央以外或不能从屏幕看到的动作及其他声音;后置左环绕和后置右环绕,则是负责外围及整个背景音乐,让人感觉置身于整个场景的正中央,比如,万马奔腾的震撼、飞机从头顶呼啸而过的效果等等;重低音则主要产生马达声、轰炸机的声音或是大鼓等震人心弦的声音。
[0061]
ambisonics是一种拾取和播放声音的技术,专门用来模拟原始三维声场效果的声音系统,它通过拾音“四面体阵列”实现三维度全覆盖的360度沉浸式全景环绕声音。与普通环绕声不同,播放效果除了水平环绕声音,还包括拾音位置或者听众上下的声源。
[0062]
现有技术中,输入音频经过上混处理,得到输出音频,包含stereo上混到5.1声道、5.1声道上混到更多声道的沉浸声等,仅仅是基于音频信号进行上混处理,由于缺乏视频信息的指导,上混处理后的音频在影院播放时,音效还有一定的欠缺,且会存在音视频内容不一致的现象。而本发明技术提出一种基于多模态的沉浸声生成方法和装置,结合视频信息进行上混处理,可以有效提升沉浸声的音效,且保证视音视频播放内容的一致性,进而有效提升沉浸声播放效果。
[0063]
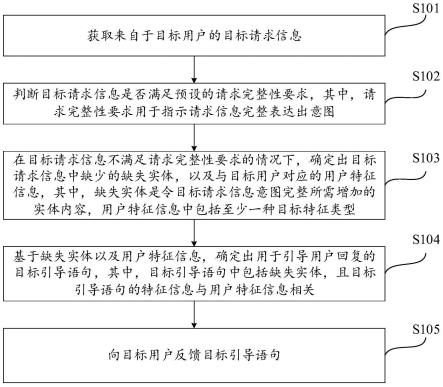
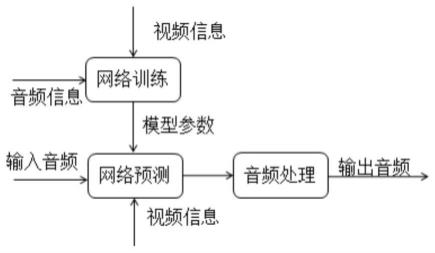
具体地,请参考图1,其示出了本技术实施例提供的一种基于多模态的沉浸声生成方法的流程图,图2为本发明技术原理图,具体地,可以包括以下步骤:
[0064]
步骤101,获取样本视频的视频信息和音频信息。
[0065]
其中,音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;
[0066]
步骤102,将样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到上混处理模型的模型参数,并基于模型参数对上混处理模型进行更新。
[0067]
在本技术实施例中,网络训练时需要结合音频信息和视频信息进行训练得到模型参数;基于该模型参数,输入音频经过网络预测(结合视频信息)处理并进一步经过音频处理,可以得到输出音频(输出音频的沉浸声效果优于输入音频)。其中,由于输入音频是多声
道(multi-channel),包含一定的方位信息,网络训练时,也可以根据音频和视频信息的主次进行权重调整。
[0068]
步骤103,将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声。其中,视频信息中至少包括运动信息和位置信息。
[0069]
如图3,给出了基于上述方法具体进行应用的实施例一,其根据多声道(stereo)音频信号,结合视频信息进行声源分离,提取直接声源和背景声,进一步经过音频处理得到多声道(5.1声道)音频信号,具体地:
[0070]
step1:根据左右声道以及视频信息(例如,运动信息和位置信息)进行声源分离,得到直接声源和背景声;
[0071]
其中,网络模型为unet,该模型包含u型结构和跳跃连接(skip-connection),u结构中编码器(encoder)进行下采样处理,解码器(decoder)进行上采样处理,并在同一个stage使用了跳跃连接,而不是直接在高级语义特征上进行监督和损失反(loss)传,这样就保证了最后恢复出来的特征图融合了更多的初级的特征,也使得不同尺度的特征得到了的融合,从而可以进行多尺度预测和监督。将图像的特征图(基于视频信息得到,可以采用resnet等网络得到运动信息和位置信息等)添加到bottleneck(瓶颈)位置,可以有效提升分离效果。
[0072]
本实施例中,声源分离处理过程中,可以基于音频时域信号进行处理,也可以基于音频频域信号进行处理,也可以基于时域信号和频域信号进行处理;
[0073]
step2:基于直接声源和背景声,经过音频处理,得到5.1声道音频信号;
[0074]
a、将直接声源作为c(中置声道);
[0075]
b、根据直接音源进行panning处理,得到l(左声道)和r(右声道);
[0076]
c、据环境音做去相关得出ls(后置左环绕声道)和rs(后置右环绕声道);
[0077]
d、根据音源进行低通处理得到sub(重低音声道)。
[0078]
如图4,给出了实施例一另外一种流程图,具体为:
[0079]
step1:结合左右声道音频信号进行立体声参数提取,得到立体声参数(声道间时间差itd、声道间能量差参数ild);
[0080]
itd是通过相关函数的峰值检测(第一公式)得到的:
[0081]
itd=argmax{φ
lr
(m)}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0082]
其中,
[0083]
φ
lr
为归一化互相关函数。
[0084]
声道间能量差通过第二公式进行确定,所述第二公式具体包括:
[0085][0086]
其中,x
l
为左声道音频信号,xr为右声道音频信号。
[0087]
step2:根据左右声道频域信号、立体声参数信息(itd、ild)及视频信息(运动信息
和位置信息)进行声源分离,得到直接声源和背景声;
[0088]
其中,将图像的特征图和立体声参数(itd、ild)添加到bottleneck位置,进行声源分离。
[0089]
step3:基于直接声源和背景声,经过音频处理,得到5.1声道音频信号;
[0090]
该实施例中,声源分离部分,结合了立体声参数和视频信息,由于立体声参数中包含了音频信号一定的空间方位信息,因而能够得到更好的声源分离效果。
[0091]
实施例二:根据多声道(stereo)音频信号,结合视频信息提取空间参数,得到沉浸声音频信号(ambisonics音频信号),如图5,结合视频信息,根据左声道和右声道信息进行上混处理,得到各个分量信号;根据左右声道下混处理后得到mono信号(作为w),结合各个分量信号得到ambisonics音频信号,输出为一阶ambisonics(foa)时,具体步骤为:
[0092]
step1、针对左声道音频信号和右声道音频信号基于fft(fast fourier transform,快速傅立叶变换)进行处理,得到左右声道音频频域信号;
[0093]
step2、基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,针对视频中的rgb和flow参数分别进行处理;
[0094]
step3:针对左右声道频域信号进行unet处理,并将基于视频提取的包含运动信息的特征图添加到bottleneck位置,进一步进行分离处理和方位处理,得到一阶ambisonics信号中x、y和z;
[0095]
其中,分离处理中,基于unet中的街解码器处理得到k(k是不小于2的正整数,即k≥2)个信号的mask参数,结合左右声道频域信号进行处理,进一步进行ifft(inverse fast fourier transform,快速傅立叶逆变换),得到k个音频时域信号;方位处理中,结合音频特征和视频特征得到的k个音频信号的方位信息;最后基于k个音频信号以及对应的方位信息,重构得到x、y和z音频信号;
[0096]
step4:基于左右声道音频信号进行下混(downmix)处理,得到mono信号;其中,mono信号通过m=(x
l
xr)/2得到。
[0097]
step5:将mono信号作为w信号,结合step3得到的x、y、z信号,得到foa音频信号。
[0098]
该实施例中,不限于一阶ambisonics,经过上混处理也可以得到高阶ambisonics。由于ambisonics信号包含水平和垂直方位信息,可以明显提升沉浸声效果。
[0099]
图6为实施例二另外一种流程图,在下混处理的时候,得到mono和立体声参数(ild、itd),在上混处理中进一步结合立体声参数预测x、y、z分量。
[0100]
step1、基于左右声道音频信号进行下混(downmix)处理,得到单声道音频和立体声参数(itd、ild);
[0101]
step2:针对左声道音频信号和右声道音频信号基于fft进行处理,得到左右声道音频频域信号;
[0102]
step3、基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,针对视频中的rgb和flow分别进行处理;
[0103]
step4:针对左右声道音频频域信号进行unet处理,并将基于视频提取的包含运动信息的特征图、立体声参数(itd、ild)添加到bottleneck位置,进一步进行分离处理和方位处理,得到一阶ambisonics信号中x、y和z;
[0104]
其中,分离处理中,基于unet中的解码处理得到k(k是不小于2的正整数,即k≥2)
个信号的mask参数,结合左右声道频域进行处理,进一步进行ifft,得到k个音频时域信号;方位处理中,结合音频特征和视频特征得到的k个音频信号的方位信息;最后基于k个音频信号以及对应的方位信息,重构得到x、y和z音频信号;
[0105]
step5:进行音频处理,将downmix处理的单声道音频作为w信号,结合step4得到的x、y、z,得到foa音频信号。
[0106]
实施例三:根据多声道(5.1声道)音频信号,结合视频信息提取空间参数,得到包含高度信息的沉浸声音频信号;图7为实施例三流程图,当ambisonics为一阶(foa)时,具体为:基于5.1声道的c音频信号,结合视频信息,进行上混处理,得到ambisonics分量(x、y、z);进一步结合5.1声道音频信号,得到包含高度信息的沉浸声。
[0107]
step1、基于5.1声道中的l、c、r、ls、rs进行fft变换,得到音频频域信号;
[0108]
step2、基于视频信息进行cnn处理,得到包含运动信息的特征图,其中,针对视频中的rgb和flow分别进行处理;
[0109]
step3:针对音频频域信号进行unet处理,并将基于视频提取的包含运动信息的特征图添加到bottleneck位置,进一步进行分离处理和方位处理,得到一阶ambisonic信号中x、y和z;
[0110]
step4:基于输入5.1声道音频和ambisonics分量进一步处理,得到包含高度信息的沉浸声音频信号。
[0111]
其中,5.1声道音频信号包含了水平的方位信息,ambisonics中的z分量包含了高度信息。
[0112]
本发明一种基于多模态的沉浸声生成方法和装置;其中,多模态包含视频和音频等信息;在沉浸声生成方法和装置中,可以基于stereo信号,也可以基于5.1声道音频信号;视频信息,包含声源的运动信息和位置信息等。可以看出,本发明结合视频信息,针对多声道音频进行上混处理,可以有效提升沉浸声音效,保证视音视频播放内容的一致性,进而有效提升沉浸声播放效果。此外,本发明也可以为混音师提供协助信息,进一步提升混音效果。
[0113]
本技术实施例还提供的一种基于多模态的沉浸声生成装置。装置包括:
[0114]
获取模块,用于获取样本视频的视频信息和音频信息;其中,所述音频信息为多声道音频信息,包括左声道音频信号和右声道音频信号;
[0115]
训练模块,用于将所述样本视频的视频信息和音频信息输入至上混处理模型中进行训练,得到所述上混处理模型的模型参数,并基于所述模型参数对上混处理模型进行更新;
[0116]
计算模块,用于将目标视频的视频信息、左声道音频信号以及右声道音频信号输入更新后的上混处理模型中进行声源分离,得到直接声源和背景声,其中所述视频信息中至少包括运动信息和位置信息。
[0117]
本技术实施例提供的基于多模态的沉浸声生成装置用于实现上述基于多模态的沉浸声生成方法,关于基于多模态的沉浸声生成装置的具体限定可以参见上文中对于基于多模态的沉浸声生成方法的限定,在此不再赘述。上述基于多模态的沉浸声生成装置中的各个部分可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于设备中的处理器中,也可以以软件形式存储于设备中的存储器中,以便于处理器
调用执行以上各个模块对应的操作。
[0118]
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0119]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。