1.本发明属于模式识别技术领域,具体涉及一种动态时域卷积网络驱动的多模态情感识别方法。
背景技术:
2.情感识别,是一个通过分析个人对某些事物表达看法、观点、情感和态度等,进而识别出主观情感的研究领域。随着生活水平的提高,人们越来越注重精神层面的质量,而情感作为人类的一种心理反应,是最能直接体现个人精神质量的研究对象。此外,情感识别已经广泛地应用于医疗、教育、自动驾驶、人机交互等领域并发挥了重要作用。因此,情感识别具有很大的应用前景和商业价值。
3.传统的单模态情感识别方法虽取得了不错的效果,但单一模态所包含的情感信息往往是稀疏的,导致提取到的特征存在信息不全面的问题,因此基于单模态信息的情感识别方法在一些复杂场景下很难实现鲁棒的识别效果,而多模态情感识别方法通过分析不同模态之间的差异和建模它们之间的相关性,提取模态间的互补信息,使提取的特征所包含的情感信息更丰富,识别准确率更高。
技术实现要素:
4.本发明的目的是提供一种动态时域卷积网络驱动的多模态情感识别方法,相关的卷积核可随特征动态变化,能更灵活地建模多模态特征之间的交互作用,从而可以更准确地识别出用户的情感状态。
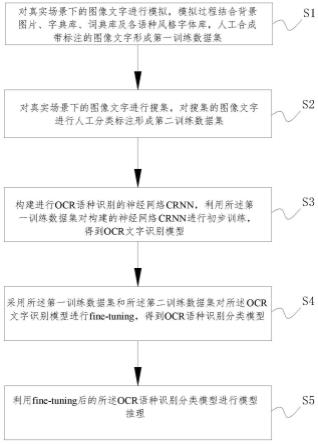
5.本发明所采用的技术方案是动态时域卷积网络驱动的多模态情感识别方法,具体按照以下步骤实施:
6.步骤1、从视频数据库中提取多个视频样本,通过多模态软件开发工具包从每个视频样本中分别提取音频模态特征xa、图像模态特征xv和文本模态特征x
l
,以及对应的情感类别标签;
7.步骤2、分别建立三个时域卷积神经网络,将每个视频样本的音频模态特征xa、图像模态特征xv和文本模态特征x
l
送入对应的时域卷积神经网络中,滤除各模态特征的冗余噪声,对各模态特征做时域关系上的建模,得到包含上下文信息的音频特征图像特征和文本特征
8.步骤3、构建具有动态卷积特性的时域卷积网络,将音频特征图像特征和文本特征按特征向量维度拼接在一起,并输入具有动态卷积特性的时域卷积网络进行压缩,得到一个压缩特征x
key
;
9.步骤4、将音频特征图像特征和文本特征作为输入特征,并将压缩特征x
key
作为查询向量,分别执行一个注意力操作,得到注意力音频特征注意力图
像特征和注意力文本特征
10.步骤5、将注意力音频特征注意力图像特征和注意力文本特征分别送入一个自注意力网络,输出自注意力音频特征自注意力图像特征和自注意力文本特征
11.步骤6、将自注意力音频特征自注意力图像特征和自注意力文本特征按特征向量维度拼接,得到拼接特征将拼接特征输入具有动态卷积特性的时域卷积网络进行特征融合,得到一个多模态融合特征x
fusion
;
12.步骤7、将多模态融合特征x
fusion
送入一个三层的全连接神经网络进行情感分类;
13.步骤8、将模型预测到的情感类别与步骤1中的情感类别标签进行对比,并通过反向传播算法去更新三个时域卷积神经网络、具有动态卷积特性的时域卷积网络、自注意力网络和三层全连接神经网络中的参数,然后不断重复步骤1-步骤7,直至模型能正确预测出情感类别,输出更新后的三个时域卷积神经网络、具有动态卷积特性的时域卷积网络、自注意力网络和三层全连接神经网络;
14.步骤9、通过更新后的三个时域卷积神经网络、具有动态卷积特性的时域卷积网络、自注意力网络和三层全连接神经网络从视频中识别人物的情感。
15.本发明的特点还在于:
16.步骤1中视频数据库包括cmu-mosei和iemocap两种多模态情感分析数据集。
17.步骤3具有动态卷积特性的时域卷积网络由五个卷积层堆叠组成,每个卷积层由两个卷积神经网络组成,每个卷积神经网络的卷积核由动态卷积网络生成。
18.步骤3中输入具有动态卷积特性的时域卷积网络进行压缩具体过程为:
19.步骤a、将输入特征x
input
输入动态卷积网络,得到动态卷积核其中d
out
为输出的特征向量维度,3d为输入的特征向量维度,k
size
为卷积核大小;
20.步骤b、以x
input
作为输入特征,k作为卷积核,进行一次膨胀卷积操作,得到输出特征
21.步骤c、以作为输入特征重复步骤a、步骤b,重复4次之后将得到的输出特征作为压缩特征x
key
。
22.步骤4中执行一个注意力操作具体过程为:
23.将音频特征图像特征和文本特征分别送入一个注意力网络,其中注意力网络的查询向量由压缩特征x
key
进行替换,计算公式如下所示:
[0024][0025]
α=softmax(x
keykt
) (2)
[0026][0027]
其中,m∈{a、v、l},k、v表示键值对向量,wk表示键向量的权重矩阵,wv表示值向量
的权重矩阵,α表示注意力分数,softmax(
·
)表示softmax函数,k
t
为键向量k的转置。
[0028]
步骤6的具体过程为:
[0029]
步骤a、将拼接特征x
avl
输入动态卷积网络,得到动态卷积核其中为输出特征的向量维度,3d为输入特征的向量维度,为卷积核大小;
[0030]
步骤b、以拼接特征x
avl
作为输入特征,k
fusion
作为卷积核,进行一次膨胀卷积操作,得到输出特征
[0031]
步骤c、以作为输入特征重复步骤a、步骤b,重复4次之后将得到的输出特征作为多模态融合特征
[0032]
本发明给出的动态时域卷积网络驱动的多模态情感识别方法的有益效果是:
[0033]
1)本发明没有采用循环神经网络及其变体对多模态特征序列作时域关系上的建模,而是选择使用时域卷积网络建模时域关系,这样不仅能够大幅度减少网络的参数量,同时还能够对特征序列作并行处理,从而降低了网络计算时间。此外,卷积运算具有滤波的作用,能够有效滤除多模态特征中的冗余噪声;
[0034]
2)为了使模型能更充分地聚焦在与情感相关的信息上,本发明提出了一种动态时域卷积网络驱动的注意力机制。以往的研究方法所使用的注意力机制中查询向量大多采用一个简单的非线性变换得到。需要指出的是,作为注意力机制的核心组件,仅通过一个单层的全连接层来学习是明显不够的。因此,本发明通过一种具有动态卷积特性的时域卷积网络来学习查询向量,不仅使查询向量的学习过程更加充分合理,而且通过动态卷积,使查询向量的生成随输入特征动态变化,更贴合目标任务;
[0035]
3)本发明通过三个模态的特征来生成查询向量,然后通过注意力机制实现各模态特征的增强,能明确捕捉到各模态特征中与模态间交互作用相关的信息,从而使模型能更容易地建模不同模态之间的交互作用;
[0036]
4)本发明提出一种具有动态卷积特性的时域卷积网络来融合不同模态的特征,由于不同模态特征之间的交互作用是随时域动态变化的,而时域卷积网络在融合不同模态特征的同时,可以对不同模态特征进行时域关系上的建模,与现有其他研究方法分别建模多模态间的交互作用和时域关系的做法相比,本发明提出的融合方法更加有效。此外,常规时域卷积网络的卷积核的参数在模型训练完之后就固定不变,这样在识别一个新的样本时缺乏灵活性,而本发明给出的时域卷积网络通过动态卷积的方式来生成卷积核,使卷积核能随输入特征呈现动态变化,与输入特征更适配,有助于更灵活地建模多模态特征之间的交互作用;
[0037]
5)通过实验分析和验证,本发明给出的动态时域卷积网络合理有效,能够在多模态情感识别任务上取得很大的性能提升。
附图说明
[0038]
图1是本发明动态时域卷积网络驱动的多模态情感识别方法流程图;
[0039]
图2是时域卷积网络结构图;
[0040]
图3是动态卷积网络结构图。
具体实施方式
[0041]
下面结合附图和具体实施方式对本发明进行详细说明。
[0042]
本发明动态时域卷积网络驱动的多模态情感识别方法,如图1所示,具体按照以下步骤实施:
[0043]
步骤1、从cmu-mosei和iemocap两种数据集中提取多个视频样本,通过多模态软件开发工具包从每个视频样本中分别提取音频模态特征xa、图像模态特征xv和文本模态特征x
l
,以及对应的情感类别标签;
[0044]
步骤2、分别建立三个时域卷积神经网络,如图2所示,将每个视频样本的音频模态特征xa、图像模态特征xv和文本模态特征x
l
送入对应的时域卷积神经网络中,滤除各模态特征的冗余噪声,对各模态特征做时域关系上的建模,得到包含上下文信息的音频特征图像特征和文本特征
[0045]
步骤3、构建具有动态卷积特性的时域卷积网络,具有动态卷积特性的时域卷积网络由五个卷积层堆叠组成,每个卷积层由两个卷积神经网络组成,每个卷积神经网络的卷积核由动态卷积网络生成,动态卷积的结构如图3所示;
[0046]
将音频特征图像特征和文本特征按特征向量维度拼接在一起,作为输入特征x
input
;
[0047]
步骤a、将输入特征x
input
输入动态卷积网络,得到动态卷积核其中d
out
为输出的特征向量维度,3d为输入的特征向量维度,k
size
为卷积核大小;
[0048]
步骤b、以x
input
作为输入特征,k作为卷积核,进行一次膨胀卷积操作,得到输出特征
[0049]
步骤c、以作为输入特征重复步骤a、步骤b,重复4次之后将得到的输出特征作为压缩特征x
key
。
[0050]
步骤4、将音频特征图像特征和文本特征作为输入特征,并将压缩特征x
key
作为查询向量,分别执行一个注意力操作,得到注意力音频特征注意力图像特征和注意力文本特征具体为:
[0051]
将音频特征图像特征和文本特征分别送入一个注意力网络,其中注意力网络的查询向量由压缩特征x
key
进行替换,计算公式如下所示:
[0052][0053]
α=softmax(x
keykt
) (2)
[0054][0055]
其中m∈{a、v、l},k、v表示键值对向量,wk表示键向量的权重矩阵,wv表示值向量的权重矩阵,α表示注意力分数,softmax(
·
)表示softmax函数,k
t
为键向量k的转置。
[0056]
步骤5、将注意力音频特征注意力图像特征和注意力文本特征分别送入一个自注意力网络,输出自注意力音频特征自注意力图像特征和自注意力文本特征
[0057]
步骤6、将自注意力音频特征自注意力图像特征和自注意力文本特征按特征向量维度拼接,得到拼接特征将拼接特征输入具有动态卷积特性的时域卷积网络进行特征融合,得到一个多模态融合特征x
fusion
;
[0058]
步骤a、将拼接特征x
avl
输入动态卷积网络,得到动态卷积核其中为输出特征的向量维度,3d为输入特征的向量维度,为卷积核大小;
[0059]
步骤b、以拼接特征x
avl
作为输入特征,k
fusion
作为卷积核,进行一次膨胀卷积操作,得到输出特征
[0060]
步骤c、以作为输入特征重复步骤a、步骤b,重复4次之后将得到的输出特征作为多模态融合特征
[0061]
步骤7、将多模态融合特征x
fusion
送入一个三层全连接神经网络执行情感分类。
[0062]
步骤8、将模型预测到的情感类别与步骤1中的情感类别标签进行对比,并通过反向传播算法去更新三个时域卷积神经网络、具有动态卷积特性的时域卷积网络、自注意力网络和三层全连接神经网络中的参数,然后不断重复步骤1-步骤7,直至模型能正确预测出情感类别(迭代收敛),输出更新后的三个时域卷积神经网络、具有动态卷积特性的时域卷积网络、自注意力网络和三层全连接神经网络;
[0063]
步骤9、按照步骤1-7中的方法,将待识别的视频替代视频样本,通过更新后的三个时域卷积神经网络、具有动态卷积特性的时域卷积网络、自注意力网络和三层全连接神经网络识别待识别的视频情感。
[0064]
本发明开展的实验在cmu-mosi、cmu-mosei两个数据集上进行,并对本发明的性能进行评估与分析。
[0065]
实验结果对比如下:
[0066]
针对模型预测的情感类别与原始情感类别,分别计算f1分数(f1 score)、两类准确率(acc2)、平均绝对误差损失(mae)和皮尔逊相关系数(corr),然后与已有的方法进行比较。在cmu-mosi、cmu-mosei两个数据集上分别对不同的情感识别模型进行性能对比,在cmu-mosi数据集上不同网络模型的性能对比结果如表1所示,在cmu-mosei数据集上不同网络模型的性能对比如表2所示:
[0067]
表1
[0068][0069]
表2
[0070][0071]
由以上实验数据可知,本发明动态时域卷积网络驱动的多模态情感识别方法整体上是优于现有经典方法的。这验证了本发明能够有效地缓解多模态特征中冗余噪声的干扰,使模型充分提取到不同模态之间的关键情感信息,更有效地实现多模态情感识别。
[0072]
通过上述方式,本发明动态时域卷积网络驱动的多模态情感识别方法,更准确地识别出用户的情感状态。此外,本发明通过动态时域卷积网络来融合不同模态的特征,能有效地缓解特征中冗余噪声的干扰。同时,卷积核随特征动态变化,能更灵活地建模多模态特征之间的交互作用。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。