1.本发明涉及一种基于样本失衡的深度学习矿产资源分类预测方法及系统,属于地球信息科学领域和计算机视觉领域。
背景技术:
2.随着我国经济的飞速发展,各种矿产资源在工业界的需求也逐渐增加,如何准确高效的探测矿产资源已成为当今学术界的热潮。随着人工智能理论与技术的飞速发展,人工智能也逐渐走进地球科学领域,借助计算机视觉处理的方法,矿靶区的预测也从最初的传统方法转变为基于人工智能的智能预测,使得预测结果更加精准和可靠。
3.尽管借助人工智能来预测矿靶区的方法能够取得一定的成功,但是矿区数量少、区域小和背景区面积占比相对很大等关键问题对智能预测矿靶区的准确率有着直接的影响,并且传统的化探数据异常分析方法难以深入分析隐藏在复杂地质环境下的微弱异常。
技术实现要素:
4.发明目的:针对现有技术的不足,本发明目的在于提出一种基于样本失衡的深度学习矿产资源分类预测方法及系统,以更加全面且客观的寻找出化探数据与矿化之间的关系,在较少的矿靶区地球化学数据中找出矿化规律以在新的地球化学数据中预测矿化概率。
5.技术方案:为实现上述发明目的,本发明所述的一种基于样本失衡的深度学习矿产资源分类预测方法,包括如下步骤:
6.步骤1:经由地理位置信息和地球化学元素信息形成矿靶区地质图像数据;
7.步骤2:将研究区域分为矿床区、成矿远景区和背景区;
8.步骤3:通过变分自编码器分析成矿远景区内化探数据的特征分布并确定成矿远景区内化探数据异常的区域,若成矿远景区中存在化探数据异常的区域,则将该区域的类别标记为与其距离最近的矿床区类别相同;
9.步骤4:将矿床区和所得化探异常区的样本进行数据增强;
10.步骤5:构造卷积神经网络模型,用于学习化探数据与矿化之间的规律,为防止神经网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习化探数据的成矿特征,引入损失权重和惩罚损失改进传统交叉熵损失函数;
11.步骤6:将训练样本数据输入到神经网络模型中进行迭代,然后更新神经网络的参数;
12.步骤7:将训练好的网络模型对待预测区域的化探数据进行矿化概率预测,生成该区域矿产资源的概率预测分布图。
13.进一步地,所述步骤1中的地理位置信息包括已知矿靶区的经纬度坐标,地球化学元素信息包括已知矿靶区的各种地球化学元素的含量;在arcgis软件中输入地理位置信息和地球化学元素信息,经过基于地学统计的克里金插值法,最终得到已知矿靶区域的地质
图像。
14.进一步地,所述步骤2中利用arcgis软件对化探数据进行迭代自组织聚类,选取已知矿床区为聚类中心,将研究区域分为成矿远景区和背景区,成矿远景区占研究面积的a%,成矿远景区中包含已知矿床区;背景区占研究面积的(100-a)%,a为预设的占比。
15.进一步地,所述步骤3具体包括如下步骤:
16.步骤31:将成矿远景区拆分为若干个正方形区域,每个区域的化探数据x从矩阵格式展开为n维向量[x1,x2,
…
,xn],xa∈(0,1),a=1,2,
…
,n,假定成矿远景区化探数据的各种属性特征满足隐藏空间的概率分布z;
[0017]
步骤32:用神经网络构造一个编码器q
φ
,φ为训练参数,编码器以变分推断的方式产生i维的均值向量m=[μ1,μ2,
…
,μi]和i维的标准差向量ν=[σ1,σ2,
…
,σi],由这两个向量可表示一个混合高斯分布q
φ
(z|x)用于逼近隐藏空间的概率分布z;然后在分布q
φ
(z|x)上随机采样,生成化探数据的隐含特征向量
[0018]
为满足均值为0方差为1的i维随机数向量;
[0019]
步骤33:用神经网络构造一个解码器p
θ
,θ为训练参数,解码器的作用是用隐含特征向量γ生成数据并且使得尽可能的与x相似;
[0020]
步骤34:为了使编码器q
φ
所得的分布q
φ
(z|x)逼近概率分布z和提高解码器p
θ
重构隐含特征向量γ为化探数据x的几率,构建损失函数
[0021][0022]
步骤35:使用成矿远景区的数据以最小化损失函数为目标训练编码器q
φ
和解码器p
θ
;
[0023]
步骤36:训练结束后,依次排查成矿远景区各区域的化探数据,若某个区域的重构交叉熵的值低于平均值,表示该区域的数据被重构的几率较小,空间数据特征也和周围区域相异,视为化探异常区域;
[0024]
步骤37:将化探异常区与其距离最近的已知矿床区视为具有高度相似的空间数据特征。
[0025]
进一步地,所述步骤4具体包括如下步骤:
[0026]
步骤41:将地质图像转为数字矩阵x0;
[0027]
步骤42:创建一个与地质图像宽高尺寸、通道数和数据类型相同的数字矩阵x1,矩阵x1的每一个元素为随机数值且服从正态分布;
[0028]
步骤43:令y1=x0 x1,将数字矩阵y1转为图像数据格式即得到新的地质图像。
[0029]
进一步地,所述步骤5具体包括如下步骤:
[0030]
步骤51:构造卷积神经网络模型,模型的数据输入格式为c
×h×
w的矩阵,c代表地球化学数据的图像通道个数,每个通道包含一种化探元素的信息,总共c个化探信息,h、w代表图像的高和宽,卷积神经网络的数据输出格式为代表着各个矿型或背景区的概率向量;
[0031]
步骤52:数据集的各类样本标签分别为i,共有i类样本,各类训练样本总数量分别为ni,训练样本总数量为每一类样本在训练过程中的损失权重
样本数量较多的类别对应的权重较小,使得网络在推断时不会对该类样本过拟合;
[0032]
步骤53:样本xi,i为其对应的标签,通过神经网络输出得到的向量为p=[p1,p2,
…
,pi],取出其标签i对应的概率pi,pi∈(0,1],令该项表示交叉熵,交叉熵越小则神经网络的输出结果越靠近对应标签i的分布,令该项表示信息熵,信息熵越小则数据p的分布不确定性就越低,令该项表示样本xi的惩罚损失;
[0033]
步骤54:神经网络的损失函数为m个样本的平均惩罚损失,m为同一批次的训练样本数,以最小化损失函数为目标训练神经网络可有效防止网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习复杂化探数据的成矿特征。
[0034]
进一步地,所述步骤7中得到训练好的网络模型后,将需要预测的矿区化探数据输入到系统中,通过滑动窗口算法,得到每个窗口区的成矿概率,最终形成整个矿区的成矿概率预测分布图。
[0035]
基于相同的发明构思,本发明提供的一种基于样本失衡的深度学习矿产资源分类预测系统,包括:
[0036]
预处理模块,用于经由地理位置信息和地球化学元素信息形成矿靶区地质图像数据;
[0037]
分区模块,用于将研究区域分为矿床区、成矿远景区和背景区;
[0038]
化探异常区识别模块,用于通过变分自编码器分析成矿远景区内化探数据的特征分布并确定成矿远景区内化探数据异常的区域,若成矿远景区中存在化探数据异常的区域,则将该区域的类别标记为与其距离最近的矿床区类别相同;
[0039]
数据增强模块,用于将矿床区和所得化探异常区的样本进行数据增强;
[0040]
分类模型模块,用于构造卷积神经网络模型,用于学习化探数据与矿化之间的规律,为防止神经网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习化探数据的成矿特征,引入损失权重和惩罚损失改进传统交叉熵损失函数;
[0041]
模型训练模块,用于将训练样本数据输入到神经网络模型中进行迭代,然后更新神经网络的参数;
[0042]
分类预测模块,用于将训练好的网络模型对待预测区域的化探数据进行矿化概率预测,生成该区域矿产资源的概率预测分布图。
[0043]
基于相同的发明构思,本发明提供的一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的一种基于样本失衡的深度学习矿产资源分类预测方法的步骤。
[0044]
基于相同的发明构思,本发明提供的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的一种基于样本失衡的深度学习矿产资源分类预测方法的步骤。
[0045]
有益效果:本发明提供了一种基于样本失衡的深度学习矿产资源分类预测方法及系统。为了更加全面且客观的寻找出化探数据与矿化之间的关系,本发明分析并获取了成
矿远景区内化探异常的数据,相较于传统的化探异常提取方法,本发明提出的方法能识别出隐藏于复杂地质环境下的微弱异常,能更有效的获取化探数据中的异常值;另外,通过对地球科学数据增加噪声来克服矿区样本数量少的问题;通过引入损失权重和惩罚损失技术,有效防止网络模型对背景区的空间数据特征产生过拟合并优化网络模型学习复杂化探数据的成矿特征。
附图说明
[0046]
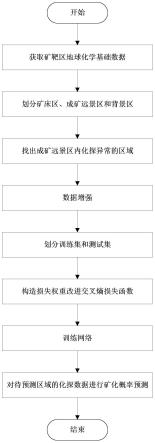
图1为本发明实施例的整体流程图;
[0047]
图2为本发明化探数据异常分析过程示意图;
[0048]
图3为本发明卷积神经网络的模型结构图;
[0049]
图4为本发明基于卷积神经网络的矿产资源分类预测方法示意图。
具体实施方式
[0050]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0051]
如图1所示,本发明实施例公开的一种基于样本失衡的深度学习矿产资源分类预测方法,主要包括如下步骤:
[0052]
步骤1:经由地理位置信息和地球化学元素信息形成矿靶区地质图像数据。
[0053]
该步骤1具体包括:
[0054]
地理位置信息包括已知矿靶区的经纬度坐标,地球化学元素信息包括已知矿靶区的ag、as、au、bi、cu、hg、pb、sb、sn和zn等10种地球化学元素的含量;在arcgis软件中输入地理位置信息和地球化学元素信息等地球科学数据,经过基于地学统计的克里金插值法,最终得到已知矿靶区域的地质图像。
[0055]
步骤2:将研究区域分为矿床区、成矿远景区和背景区。
[0056]
该步骤2具体包括:
[0057]
利用arcgis软件对化探数据进行迭代自组织聚类,选取已知矿床区为聚类中心。将研究区域分为成矿远景区和背景区,成矿远景区占研究面积的10%,成矿远景区中包含已知矿床区;背景区占研究面积的90%。
[0058]
步骤3:通过变分自编码器分析成矿远景区内化探数据的特征分布并确定成矿远景区内化探数据异常的区域,由于矿化区域与非矿化区域的空间数据特征具有较大差异,若成矿远景区中存在化探数据异常的区域,则能够间接说明该区域具有较高的矿化概率且表现出与已知矿床的化探数据特征相似性更高,将该区域的类别标记为与其距离最近的矿床区类别相同。
[0059]
如图2所示,该步骤3具体包括如下步骤:
[0060]
步骤31:将成矿远景区拆分为若干个正方形区域,正方形区域覆盖到全部成矿远景区,每个区域的化探数据x从矩阵格式展开为n维向量[x1,x2,
…
,xn],xa∈(0,1),a=1,2,
…
,n,假定成矿远景区化探数据的各种属性特征满足隐藏空间的概率分布z;
[0061]
步骤32:用神经网络构造一个编码器q
φ
,φ为训练参数,编码器以变分推断的方式
产生i维的均值向量m=[μ1,μ2,
…
,μi]和i维的标准差向量ν=[σ1,σ2,
…
,σi],由这两个向量可表示一个混合高斯分布q
φ
(z|x)用于逼近隐藏空间的概率分布z;然后在分布q
φ
(z|x)上随机采样,生成化探数据的隐含特征向量
[0062]
eps为满足均值为0方差为1的i维随机数向量;
[0063]
步骤33:用神经网络构造一个解码器p
θ
,θ为训练参数,解码器的作用是用隐含特征向量γ生成数据并且使得尽可能的与x相似;
[0064]
步骤34:为了使编码器q
φ
所得的分布q
φ
(z|x)逼近概率分布z和提高解码器p
θ
重构隐含特征向量γ为化探数据x的几率,构建损失函数
[0065][0066]
步骤35:使用成矿远景区的数据以最小化损失函数为目标训练编码器q
φ
和解码器p
θ
;
[0067]
步骤36:训练结束后,依次排查成矿远景区各区域的化探数据,若某个区域的重构交叉熵的值低于平均值,表示该区域的数据被重构的几率较小,空间数据特征也和周围区域相异,视为化探异常区域;
[0068]
步骤37:将化探异常区与其距离最近的已知矿床区视为具有高度相似的空间数据特征。
[0069]
本发明实施例中成矿远景区被分为若干个10
×
10像素大小的正方形区域,对应10
×
10
×
10的数字矩阵x(前面两个10分别为宽和高,第三个10为化探元素个数),展开成1000维的向量输入到编码器中,编码器由三个线性层构成,采用relu激活函数,根据化探元素的个数最终输出两个维度为10的均值向量m和标准差向量n,用于逼近隐藏空间的特征概率分布z;解码器由两个线性层构成,采用relu激活函数,用于在概率分布q
φ
(z|x)上随机均匀采样重构化探数据x;编码器和解码器在学习提取化探异常的过程中,学习率保持在0.001。
[0070]
步骤4:将矿床区和所得化探异常区的样本进行数据增强。
[0071]
该步骤4具体包括如下步骤:
[0072]
步骤41:将地质图像转为数字矩阵x0;
[0073]
步骤42:创建一个与地质图像宽高尺寸、通道数和数据类型相同的数字矩阵x1,矩阵x1的每一个元素为随机数值且服从分布其中μ=0.1,σ=0.1;
[0074]
步骤43:令y1=x0 x1,将数字矩阵y1转为图像数据格式即得到新的地质图像。
[0075]
数据增强之后,把所有样本按照一定比例(如7:3)随机分成训练集和测试集,将数据增强后的图像全部归为训练集。
[0076]
步骤5:构造卷积神经网络模型,用于学习化探数据与矿化之间的规律,为防止神经网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习化探数据的成矿特征,引入损失权重和惩罚损失改进传统交叉熵损失函数。
[0077]
该步骤5具体包括如下步骤:
[0078]
步骤51:构造卷积神经网络模型,模型的数据输入格式为c
×h×
w的矩阵,c代表地
球化学数据的图像通道个数,每个通道包含一种化探元素的信息,总共c个化探信息,h、w代表图像的高和宽,卷积神经网络的数据输出格式为代表着各个矿型或背景区的概率向量;
[0079]
步骤52:数据集的各类样本标签分别为i,共有i类样本,各类训练样本总数量分别为ni,训练样本总数量为每一类样本在训练过程中的损失权重样本数量较多的类别对应的权重较小,使得网络在推断时不会对该类样本过拟合;
[0080]
步骤53:样本xi,i为其对应的标签,通过神经网络输出得到的向量为p=[p1,p2,
…
,pi],取出其标签i对应的概率pi,pi∈(0,1],令该项表示交叉熵,交叉熵越小则神经网络的输出结果越靠近对应标签i的分布,令该项表示信息熵,信息熵越小则数据p的分布不确定性就越低,令该项表示样本xi的惩罚损失;
[0081]
步骤54:神经网络的损失函数为m个样本的平均惩罚损失,m为同一批次的训练样本数,以最小化损失函数为目标训练神经网络可有效防止网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习复杂化探数据的成矿特征。
[0082]
步骤6:将训练样本数据输入到神经网络模型中进行迭代,然后更新神经网络的参数。
[0083]
该步骤6具体包括:
[0084]
训练样本数据包含样本增强后的训练数据,每次更新参数后对测试样本的数据进行测试获取准确率,保存准确率最高的一组模型参数。
[0085]
步骤7:将训练好的网络模型对待预测区域的化探数据进行矿化概率预测,生成该区域矿产资源的概率预测分布图。
[0086]
该步骤7具体包括:
[0087]
得到训练好的网络模型后,将需要预测的矿区化探数据输入到系统中,通过滑动窗口算法,得到每个窗口区的成矿概率,最终形成整个矿区的成矿概率预测分布图。
[0088]
为了防止矿区样本的特征随着卷积神经网络卷积层数的增加而逐渐消失从而导致参数无法正常优化最终影响分类器的性能,本发明实施例引入了残差网络的结构并且组合不同尺寸的卷积核大小从不同的角度提取出矿区的特征,充分且有效的利用了宝贵的样本资源。如图3所示,本发明实施例中卷积神经网络的模型由29个卷积层构成,卷积核的大小和特征维度已在图中注明,为了防止随着卷积层数的增加样本的特征逐渐消失,引入了14个残差块;模型的迭代次数确定为100次,训练批次数据量为16,学习率从最开始的0.01经过迭代的进行线性衰减为0.0001。
[0089]
神经网络模型训练完毕后将需要预测区域的化探数据输入进系统,系统经由滑动窗口算法遍历整个区域的地球化学数据,在每个窗口中模型会输出成矿概率,最终系统会预测并输出该区域的矿产概率分布图,参见图4。
[0090]
基于相同的发明构思,本发明实施例公开的一种基于样本失衡的深度学习矿产资源分类预测系统,包括:预处理模块,用于经由地理位置信息和地球化学元素信息形成矿靶区地质图像数据;分区模块,用于将研究区域分为矿床区、成矿远景区和背景区;化探异常
区识别模块,用于通过变分自编码器分析成矿远景区内化探数据的特征分布并确定成矿远景区内化探数据异常的区域,若成矿远景区中存在化探数据异常的区域,则将该区域的类别标记为与其距离最近的矿床区类别相同;数据增强模块,用于将矿床区和所得化探异常区的样本进行数据增强;分类模型模块,用于构造卷积神经网络模型,用于学习化探数据与矿化之间的规律,为防止神经网络模型对背景区的空间数据特征产生过拟合以及优化网络模型学习化探数据的成矿特征,引入损失权重和惩罚损失改进传统交叉熵损失函数;模型训练模块,用于将训练样本数据输入到神经网络模型中进行迭代,然后更新神经网络的参数;分类预测模块,用于将训练好的网络模型对待预测区域的化探数据进行矿化概率预测,生成该区域矿产资源的概率预测分布图。
[0091]
基于相同的发明构思,本发明实施例公开的一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的一种基于样本失衡的深度学习矿产资源分类预测方法的步骤。
[0092]
基于相同的发明构思,本发明实施例公开的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现所述的一种基于样本失衡的深度学习矿产资源分类预测方法的步骤。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
