1.本公开涉及实体识别技术领域,尤其涉及一种实体识别方法、装置、设备及存储介质。
背景技术:
2.短视频即短片视频,是一种互联网内容传播媒介。随着移动终端和各类短视频应用的普及,通过短视频获取及传播内容,逐渐获得越来越多用户的青睐。对于短视频平台而言,对视频内容的理解精度和深度则对用户兴趣收集、短视频推荐等功能实现至关重要。
3.相关技术中,根据用户上传短视频时设置的视频描述信息分析视频内容,其中,视频描述信息诸如视频标题、视频简介等,存在对视频内容的理解精度和深度不足的问题,导致无法准确地从视频内容中识别出命名实体。
技术实现要素:
4.本公开提供一种实体识别方法、装置、设备及存储介质,以至少解决相关技术对视频内容的理解精度和深度不足的问题。本公开的技术方案如下:
5.根据本公开实施例的第一方面,提供一种实体识别方法,包括:获取目标视频的视频特征信息,所述视频特征信息包括从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息和所述目标视频的描述文本;从所述视频特征信息中识别出预设类别的指称项和所述指称项的上下文信息;确定所述指称项对应的候选实体;利用所述指称项的上下文信息和检索到的候选实体,对所述指称项执行消歧处理,得到消歧处理结果;根据消歧处理结果确定所述指称项对应的目标实体。
6.结合第一方面,在第一方面的一种实现方式中,所述利用所述指称项的上下文信息和所述候选实体,对所述指称项执行消歧处理,得到消歧处理结果,包括:获取每个所述候选实体关联的实体信息;利用预先训练的特征匹配模型确定包含所述上下文信息的所述视频特征信息与所述实体信息的匹配度,作为所述指称项与所述候选实体的匹配度。
7.结合第一方面,在第一方面的一种实现方式中,所述特征匹配模型包括特征提取部分和特征匹配部分,所述特征提取部分是通过使用指定样本集训练语义表示模型得到的,所述语义表示模型是通过使用通用语料数据训练初始神经网络模型得到的;所述利用预先训练的特征匹配模型确定包含所述上下文信息的所述视频特征信息与所述实体信息的匹配度,包括:利用所述特征提取部分,从视频特征信息中提取视频特征向量,以及,从所述实体信息中提取实体特征向量;所述视频特征信息为从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息与所述目标视频的描述文本拼接后的信息;利用所述特征匹配部分,确定所述视频特征向量和所述实体特征向量的匹配度。
8.结合第一方面,在第一方面的一种实现方式中,所述获取目标视频的视频特征信息,包括:从所述图像信息中提取图像文本;拼接所述图像文本与所述描述文本,得到所述视频特征信息。
9.结合第一方面,在第一方面的一种实现方式中,所述获取目标视频的视频特征信息,包括:从所述图像信息中提取人脸信息;通过将所述人脸信息与预置人脸特征库进行匹配,确定所述人脸信息对应的人物关键词;拼接所述人物关键词与所述描述文本,得到所述视频特征信息。
10.结合第一方面,在第一方面的一种实现方式中,所述确定所述指称项对应的候选实体,包括:在预置知识库中检索所述指称项的多个相关实体,并抽取每个所述相关实体的实体信息;根据所述相关实体的所述实体信息中是否包含所述人物关键词,则对所述相关实体进行过滤,以从所述多个相关实体中确定出所述指称项对应的候选实体。
11.结合第一方面,在第一方面的一种实现方式中,所述获取目标视频的视频特征信息,包括:将所述音频信息转换成音频文本;拼接所述音频文本与所述描述文本,得到所述视频特征信息。
12.结合第一方面,在第一方面的一种实现方式中,所述获取目标视频的视频特征信息,包括:从所述音频信息中提取声纹特征和/或频谱特征;从预设音频特征库中检索与所述声纹特征和/或频谱特征匹配的音频关键词,其中,所述音频关键词包括根据所述声纹特征和/或频谱特征确定的歌手关键词和/或歌曲关键词;拼接所述音频关键词与所述描述文本,得到所述视频特征信息。
13.结合第一方面,在第一方面的一种实现方式中,所述确定所述指称项对应的候选实体,包括:在预置知识库中检索所述指称项的多个相关实体,并抽取每个所述相关实体的实体信息;根据所述相关实体的所述实体信息中是否包含所述音频关键词,对所述相关实体进行过滤,以从所述多个相关实体中确定出所述指称项对应的候选实体。
14.结合第一方面,在第一方面的一种实现方式中,所述方法还包括:从所述预置知识库中抽取所述目标实体关联的实体信息;基于所述目标实体关联的实体信息,确定用于描述所述目标视频的视频关键信息。
15.结合第一方面,在第一方面的一种实现方式中,所述根据消歧处理结果确定所述指称项对应的目标实体,包括:确定与所述指称项的匹配度大于预设阈值的目标候选实体;将与所述指称项的匹配度最高的目标候选实体确定为所述目标实体。
16.根据本公开实施例的第二方面,提供一种实体识别装置,包括包括视频特征提取单元,指称识别单元,候选实体检索单元和目标实体确定单元;所述视频特征提取单元,用于获取目标视频的视频特征信息,所述视频特征信息包括从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息和所述目标视频的描述文本;所述指称识别单元,用于从所述视频特征信息中识别出预设类别的指称项和所述指称项的上下文信息;所述候选实体确定单元,用于确定所述指称项对应的候选实体;所述目标实体确定单元,用于利用所述指称项的上下文信息和检索到的候选实体,对所述指称项执行消歧处理,得到消歧处理结果;根据消歧处理结果确定所述指称项对应的目标实体。
17.结合第二方面,在第二方面的一种实现方式中,所述目标实体确定单元,具体用于:获取每个所述候选实体关联的实体信息;利用预先训练的特征匹配模型确定包含所述上下文信息的所述视频特征信息与所述实体信息的匹配度,作为所述指称项与所述候选实体的匹配度。
18.结合第二方面,在第二方面的一种实现方式中,所述特征匹配模型包括特征提取
部分和特征匹配部分,所述特征提取部分是通过使用指定样本集训练语义表示模型得到的,所述语义表示模型是通过使用通用语料数据训练初始神经网络模型得到的;所述目标实体确定单元,具体用于:利用所述特征提取部分,从视频特征信息中提取视频特征向量,以及,从所述实体信息中提取实体特征向量;所述视频特征信息为从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息与所述目标视频的描述文本拼接后的信息;利用所述特征匹配部分,确定所述视频特征向量和所述实体特征向量的匹配度。
19.结合第二方面,在第二方面的一种实现方式中,所述视频特征提取单元,具体用于:从所述图像信息中提取图像文本;拼接所述图像文本与所述描述文本,得到所述视频特征信息。
20.结合第二方面,在第二方面的一种实现方式中,所述视频特征提取单元,具体用于:从所述图像信息中提取人脸信息;通过将所述人脸信息与预置人脸特征库进行匹配,确定所述人脸信息对应的人物关键词;拼接所述人物关键词与所述描述文本,得到所述视频特征信息。
21.结合第二方面,在第二方面的一种实现方式中,所述候选实体确定单元,具体用于:在预置知识库中检索所述指称项的多个相关实体,并抽取每个所述相关实体的实体信息;根据所述相关实体的所述实体信息中是否包含所述人物关键词,则对所述相关实体进行过滤,以从所述多个相关实体中确定出所述指称项对应的候选实体。
22.结合第二方面,在第二方面的一种实现方式中,所述视频特征提取单元,具体用于:将所述音频信息转换成音频文本;拼接所述音频文本与所述描述文本,得到所述视频特征信息。
23.结合第二方面,在第二方面的一种实现方式中,所述视频特征提取单元,具体用于:从所述音频信息中提取声纹特征和/或频谱特征;从预设音频特征库中检索与所述声纹特征和/或频谱特征匹配的音频关键词,其中,所述音频关键词包括根据所述声纹特征和/或频谱特征确定的歌手关键词和/或歌曲关键词;拼接所述音频关键词与所述描述文本,得到所述视频特征信息。
24.结合第二方面,在第二方面的一种实现方式中,所述候选实体确定单元,具体用于:在预置知识库中检索所述指称项的多个相关实体,并抽取每个所述相关实体的实体信息;根据所述相关实体的所述实体信息中是否包含所述音频关键词,对所述相关实体进行过滤,以从所述多个相关实体中确定出所述指称项对应的候选实体。
25.结合第二方面,在第二方面的一种实现方式中,所述装置还包括视频关键信息确定单元,用于:获取所述目标实体关联的实体信息;基于所述目标实体关联的实体信息,确定用于描述所述目标视频的视频关键信息。
26.结合第二方面,在第二方面的一种实现方式中,所述目标实体确定单元,具体用于:确定与所述指称项的匹配度大于预设阈值的目标候选实体;将与所述指称项的匹配度最高的目标候选实体确定为所述目标实体。
27.根据本公开实施例的第三方面,提供一种电子设备,包括:处理器、用于存储处理器可执行的指令的存储器;其中,处理器被配置为执行指令,以实现如第一方面及其任一种可能的设计方式所提供的实体识别方法。
28.根据本公开实施例的第四方面,提供一种计算机可读存储介质,当计算机可读存
储介质中的指令由服务器的处理器执行时,使得服务器能够执行如第一方面及其任一种可能的设计方式所提供的实体识别方法。
29.根据本公开实施例的第五方面,提供一种计算机程序产品,该计算机程序产品包括计算机指令,当计算机指令在服务器上运行时,使得该服务器执行如第一方面及其任一种可能的设计方式所提供的实体识别方法。
30.本公开的实施例提供的技术方案至少带来以下有益效果:对于待处理的目标视频,通过从目标视频的多种模态的信息中提取视频特征信息,并基于该视频特征信息识别预设类别的指称项,并利用视频特征信息中包含的指称项的上下文信息和指称项对应的候选实体,对指称项进行消歧。由于视频特征信息是从目标视频的多种模态的信息中提取出的,因此其信息量丰富度及与视频内容相关度较高。这样,针对该视频特征信息进行指称项识别,可以保证指称项识别的全面性;并且,利用指称项的丰富的上下文信息和候选实体对指称项进行消歧处理,可以提高消歧处理结果的准确度,从而保证实体链接的准确性,避免实体错连。
31.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
32.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。
33.图1是根据一示例性实施例示出的一种视频内容实体识别系统结构示意图;
34.图2是根据一示例性实施例示出的一种短视频应用界面示意图;
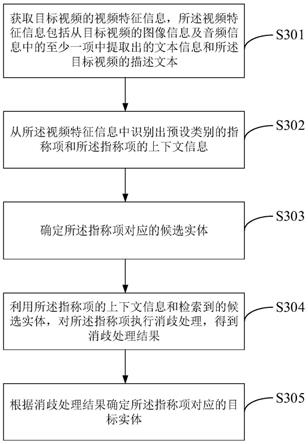
35.图3是根据一示例性实施例示出的一种实体识别方法流程图;
36.图4是根据一示例性实施例示出的另一种实体识别方法流程图;
37.图5是根据一示例性实施例示出的一种特征匹配模型结构示意图;
38.图6是根据一示例性实施例示出的另一种特征匹配模型结构示意图;
39.图7是根据一示例性实施例示出的实体识别装置框图;
40.图8是根据一示例性实施例示出的一种服务器的结构示意图。
具体实施方式
41.为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。
42.需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
43.另外,在本公开实施例的描述中,除非另有说明,“/”表示或的意思,例如,a/b可以表示a或b。本文中的“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关
系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,在本公开实施例的描述中,“多个”是指两个或两个以上。
44.本公开实施例中提供的实体识别方法,可以应用于视频内容实体识别系统,该视频内容实体识别系统用于针对视频进行实体识别。示例性的,图1为一种视频内容实体识别系统示意图,如图1所示,该视频内容实体识别系统包括实体识别装置11及与实体识别装置11通信连接的服务器12。
45.实体识别装置11用于执行本公开实施例提供的实体识别方法,以通过该实体识别方法确定与视频内容相关的实体。
46.需要说明的是,本公开实施例提及的“实体”是指命名实体。命名实体即人名、机构名、地名以及其他所有以名称为标识的实体。在信息的基础上,建立实体之间的联系,便形成“知识”。一条条知识则构成知识图谱。在知识图谱中,每条知识均可表示为一个三元组,如(实体1,关系,实体2)、(实体、属性,属性值)。换句话说,知识图谱是一种揭示实体之间关系的语义网络,其包括实体及实体关系。另外,基于实体和实体关系,对于每个实体,都可以从相应知识图谱中抽取出实体的实体信息,某个实体的实体信息即与该实体关联的三元组。例如,实体1的实体信息包括(实体1,关系,实体2)、(实体1、属性,属性值)等。
47.实体识别装置11可以与服务器12进行数据交互。例如,实体识别装置11可以从服务器12中获取目标视频及其描述文本。又如,实体识别装置11还可以将视频内容的实体识别结果发送给服务器12。其中,视频的描述文本是指独立于视频文件本身(包括图像信息和音频信息)的文本信息,包括但不限于视频标题、视频内容说明信息、视频简介、视频内容标签等。
48.服务器12用于接收用户上传的视频文件,还可以接收用户上传的视频文件的描述文本。此外,服务器12还可以用于接收实体识别装置11发送的实体识别结果。服务器12还可以基于实体识别结果标注视频、推荐视频或者检索视频。
49.需要说明的,实体识别装置11和服务器12可以为相互独立的设备,也可以集成于同一设备中,本发明对此不作具体限定。
50.当实体识别装置11和服务器12集成于同一设备时,实体识别装置11和服务器12之间的通信方式为该设备内部模块之间的通信。这种情况下,二者之间的通信流程与“实体识别装置11和服务器12之间相互独立的情况下,二者之间的通信流程”相同。
51.在本发明提供的以下实施例中,主要以实体识别装置11和服务器12相互独立设置为例进行说明。
52.本公开实施例中提供的实体识别方法,还可以应用于短视频应用平台相关的各类系统,如视频搜索系统、视频推荐系统等。相应的,该实体识别方法还可以应用到视频搜索方案、视频推荐方案中,作为这些方案涉及的具体实现方式或者前置数据处理方案。例如,在视频搜索方案中,利用本公开实施例中的实体识别方法针对视频内容进行实体识别,根据对视频内容的实体识别结果确定用于描述视频内容的视频关键信息,在已知搜索条件的情况下,通过分析各视频内容的视频关键信息是否满足搜索条件,得到搜索结果。又如,在视频推荐方案中,在已知用户兴趣标签的情况下,通过分析各视频内容的视频关键信息与用户兴趣标签是否匹配,向用户推荐其喜欢的视频。
53.一示例性的,上述服务器12可以用于接收用户的用户设备发送的搜索请求,并根
据搜索请求中的搜索词,确定与搜索词匹配的视频关键信息,从而确定与搜索词匹配的视频,并向用户设备返回这些视频的资源信息。
54.另一示例性的,上述服务器12可以用于获取用户的兴趣标签,确定与搜索词匹配的视频相关信息,从而确定与搜索词匹配的视频,并向用户设备下发这些视频的资源信息。
55.本公开实施例中,将待处理的视频称为目标视频。目标视频可以是特定类别的短视频。如影视类视频,包括影视剧或者综艺节目的片段、花絮、片花、预告、对影视剧或者综艺节目的介绍或者解说视频、影视剧的片头或者片尾等。如音乐类视频,包括歌曲mv、歌曲的现场表演视频、歌曲串烧视频等。如科普类视频,包括各个领域知识的科普、分享视频。应理解的是,可以根据场景需求设置对视频的分类规则。同一个视频在不同分类规则下可能被归类到不同的类别。
56.本公开实施例中,目标视频的描述文本可以是其视频标题及简介内容。例如,图2示出一种短视频应用界面20,该应用界面显示有短视频播放画面21。此外,诸如用于触发“关注”、“喜欢”、“评论”等操作的交互式界面对象221-223浮于短视频播放画面21显示。值得注意的是,发布该短视频的用户的用户昵称及用户提交的视频描述文本也显示在短视频播放画面21的上方。具体的,该视频描述文本的具体内容为“中的这些场面,你看懂了吗?”。不难理解的是,基于从该视频描述文本可以得知,该视频的内容与描述文本中的指称项“天龙八部”有关。
57.需要说明的是,本公开实施例提及的“指称项”即实体指称项,它被用来指代知识库中的实体。例如,图2中视频描述文本包含的“天龙八部”即为一个实体指称项。值得注意的是,指称项可以对应到知识库中的多个实体,为便于说明,本公开实施例将这些实体称为候选实体。通过消除指称项与候选实体之间的歧义,可以最终确定指称项所指向的真正实体,为便于说明,本公开实施例将通过消歧处理确定的指称项所指向的真正实体称为目标实体。
58.将视频相关的指称项链接到知识库中的实体,有助于机器对视频内容的深度理解。这里的机器包括但不限于视频平台涉及的各类功能系统中的装置、设备、处理器或服务器。在一些实施例中,首先从目标视频的描述文本中识别出实体指称项,再在相应知识库中检索与该实体指称项对应的候选实体,并通过分析实体指称项与每个候选实体之间的语义相似度,确定该实体指称项对应的真正实体。
59.以上述图2示出的短视频为例,首先对其描述文本“天龙八部中的这些场面,你看懂了吗?”进行影视类指称的识别,可以识别出指称项“天龙八部”。接着,在相应知识库中检索与“天龙八部”对应的候选实体,可以得到多个叫做“天龙八部”的候选实体,包括如不同版本的影视剧《天龙八部》、小说《天龙八部》等。再通过这些候选实体对指称项“天龙八部”进行消歧处理,得到“天龙八部”对应的目标实体。需要说明的是,本公开实施例中,将包含指称项识别步骤、候选实体检索步骤以及候选实体消歧步骤的处理过程称为实体识别过程。
60.上述实施例在进行消歧处理时,可以基于描述文本挖掘实体指称项的语义信息,利用指称项的语义信息消除指称项与候选实体之间的歧义。然而,由于视频的描述文本中记载的信息量有限甚至贫乏,因此难以基于描述文本挖掘出实体指称项的真实语义,导致消歧结果不准确,极易出现实体错连的情况。例如,将“天龙八部”影视剧解说视频的描述文
本中出现的“天龙八部”链接到知识库中的小说“天龙八部”,即表现为“同名不同类型”的实体错连。或者将1997版“天龙八部”链接到知识库中2003版“天龙八部”,即表现为“同名不同版本”的实体错连。
61.需要说明的是,上述实体错连的情况,包括但不限于表现为上文中提及的情况。例如,还可以表现为“不同不同季”,如将实际与某个影视作品的第一季对应的指称项链接到该影视作品的第二季。
62.另外,对于有些视频,其描述文本压根与视频内容无关。那么从此类描述文本中获得的指称项,则与视频内容本身毫无关系,从而导致实体识别错误的问题。例如,某个实质内容为解说“天龙八部”剧情的视频,其描述信息却是“本期视频是博主继《神雕侠侣》系列之后的呕心沥血之作,点开不亏”。基于该描述文本,将识别出指称项“神雕侠侣”,并链接到知识库中的某个叫做“神雕侠侣”的实体,该实体实际上与视频内容大相径庭。
63.此外,对于一些特定类别的视频,其描述文本中并未谈及特定类别指称项。对于此类描述文本,将无法从中识别出该特定类别的实体指称项,进而无法进一步进行实体链接,也就无法从视频内容中识别出任何实体。例如,某个实质内容为解说“天龙八部”剧情的影视类视频,其描述文本却是“这部经典武侠剧的名场面,永远无法被超越”。可以看出,由于该描述文本中并未提及与“天龙八部”对应的指称项,因此基于该描述文本识别出与视频内容相关的实体。
64.为了解决上述问题,本公开实施例中的实体识别方法,对于待处理的目标视频,从目标视频的多种模态的信息中提取视频特征。基于该多模态的视频特征信息,识别与目标视频内容相关的实体。
65.需要说明的是,每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉、听觉、视觉、嗅觉;信息的媒介,有语音、视频、文字等;多种多样的传感器,如雷达、红外、加速度计等。以上的每一种都可以称为一种模态。而本公开提及的视频的多种模态的信息则可以包括视频的描述文本、图像信息及音频信息。图3为本公开示例性实施例示出的实体识别方法流程图,该方法可以应用于电子设备,该电子设备可以是上述实体识别装置11或服务器12。如图3所示,该方法可以包括下述步骤:
66.s301,获取目标视频的视频特征信息,所述视频特征信息包括从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息和所述目标视频的描述文本。
67.本公开实施例中,视频特征信息是文本形式的特征信息,例如,可以是多个单词、句子或者段落。根据场景需求的不同,可以从图像信息及描述文本两者中提取视频特征信息。或者,从音频信息和描述文本两者中提取视频特征信息。或者,从图像信息、音频信息及描述文本三者中提取视频特征信息。应理解,这里的从两种或者两种以上模态的信息中提取视频特征信息,是指分别从该两种或者两种以上模态的信息中提取特征信息,并对来源于该两种或者两种以上模态信息的特征信息进行融合,得到视频特征信息。
68.本公开实施例中,由于视频特征信息是从目标视频的多种模态的信息中提取出的,因此其信息量丰富度及与视频内容相关度较高。这样,基于该视频特征信息进行实体链接,可以保证指称项识别的全面性,避免信息丢失;并且,由于该视频特征信息包含指称项的丰富的上下文信息,因此利用该视频特征信息消除指称项与指称项对应的候选实体之间的歧义,可以提高消歧处理结果的准确度,从而保证实体链接的准确性,避免实体错连。
69.实际上,图像信息中隐含的视频特征信息可以是图像中的文字信息,即图像文本。示例性的,在一些应用场景中,短视频平台上的视频博主会在视频图像上添加与视频内容极为相关的关键性文字信息,并且,视频图像本身可能也包括文字信息,比如对于影视类视频,其中可能会穿插影视剧片段,影视剧片段中可能会出现字幕。因此,本公开实施例将视频图像中的文本信息作为视频特征信息的一部分,来提高视频特征信息的信息密度/丰富度,从而提高实体识别结果的准确性。例如,图2中示出的视频画面中的文字内容:“天龙八部名场面之一,乔峰大战聚贤庄”。
70.基于此,在一些可能的实现方式中,利用光学字符识别(optical character recognition,ocr)技术识别视频图像中的图像文本,得到包含图像文本的视频特征信息。更为具体的,可以根据预设抽帧规则从视频图像序列中抽取多个关键帧,然后识别关键帧中的文本信息。其中,预设抽帧规则可以是基于时间戳的规则,如等间隔地从视频图像序列中抽取关键帧。应理解,预设抽帧规则也可以是其他规则,此处不予限定。
71.此外,图像信息中隐含的视频特征信息还可以是图像中出现的人脸。例如图2中示出的视频画面中出现的饰演“乔峰”的演员“黄某华”的脸。容易理解的是,当图像中出现著名人物(如演员)的脸时,根据人脸信息可以确定对应的人物关键词,人物关键词包括但不限于人物名称,例如人物姓名、别名、艺名、曾用名等。本公开将视频图像中的人脸信息匹配的人物关键词作为视频特征信息的一部分,有利于消除候选实体的版本歧义,从而提高实体识别结果的准确性。当然,根据场景需求的不同,还可以将与人脸信息匹配的人物信息介绍作为视频特征信息。
72.在一些可能的实现方式中,利用人脸识别技术识别视频图像中的人脸信息。通过将识别出的人脸信息与预设人脸特征库进行匹配,得到与人脸信息匹配的人物关键词。容易理解的是,预设人脸特征库由大量的相对应的人脸信息和人物关键词构成。与上述实现方式类似的,可以从视频的多个关键帧中识别人脸信息。
73.基于此,在s301的一种具体实现方式中,首先从图像信息中提取图像文本;再拼接图像文本与目标视频的描述文本,得到视频特征信息。和/或,从图像信息中提取人脸信息;通过将人脸信息与预置人脸特征库进行匹配,确定人脸信息对应的人物关键词;拼接人物关键词与描述文本,得到视频特征信息。以图2示出的视频图像为例,基于该图像可以识别出图像文本“天龙八部名场面之一,乔峰大战聚贤庄”,及饰演“乔峰”的演员“黄某华”的人脸信息,进而得到包含“天龙八部名场面之一,乔峰大战聚贤庄;黄某华”的视频特征信息。
74.音频信息中隐含的视频特征信息可以是通过语音识别技术从音频中识别出的文本,即音频文本。例如,对于影视剧解说视频,可以从其音频信息中提取出解说内容文本。若解说视频中穿插有影视剧片段,则从其音频信息中还可以提取出影视剧台词。在一个例子中,将目标视频的音频信息转换成音频文本为:“多个版本的天龙八部中,最受观众喜爱的当属1997版了。要说天龙八部中的名场面,自然是乔峰大战聚贤庄。当时乔峰被人陷害杀害了多位武林前辈,甚至被人认为杀害了自己的养父母和授业恩师,从而导致乔峰丢掉了丐帮帮主的位置。后来武林中人决定共同讨伐乔峰,于是就发生了乔峰大战聚贤庄。”。那么,基于该音频信息,则可得到包含“多个版本的天龙八部中,最受观众喜爱的当属1997版了。要说天龙八部中的名场面,自然是乔峰大战聚贤庄。当时乔峰被人陷害杀害了多位武林前辈,甚至被人认为杀害了自己的养父母和授业恩师,从而导致乔峰丢掉了丐帮帮主的位置。
后来武林中人决定共同讨伐乔峰,于是就发生了乔峰大战聚贤庄”的视频特征信息。
75.一方面,考虑到视频内容的一大部分会通过其音频内容传播出来,而不仅限于其图像信息,另一方面,考虑到在一些应用场景中,视频平台上的视频博主,会为视频配音,如影视类视频的解说内容。因此,本公开将音频信息经转换得到的音频文本作为视频特征信息的一部分,提高视频特征信息的信息密度/丰富度,从而提高实体识别结果的准确性。
76.针对上述示例,若同时从图像信息、音频信息及描述文本中提取视频特征信息,则得到的视频特征信息内容为:
[0077]“天龙八部名场面之一,乔峰大战聚贤庄;黄某华;多个版本的天龙八部中,最受观众喜爱的当属1997版了。要说天龙八部中的名场面,自然是乔峰大战聚贤庄。当时乔峰被人陷害杀害了多位武林前辈,甚至被人认为杀害了自己的养父母和授业恩师,从而导致乔峰丢掉了丐帮帮主的位置。后来武林中人决定共同讨伐乔峰,于是就发生了乔峰大战聚贤庄”[0078]
可以看出,从图像信息和/或音频信息中提取视频特征信息,而不仅限于视频的描述文本,可以有效提高视频特征信息的信息密度。
[0079]
此外,音频信息中隐含的视频特征信息还可以是音频的声纹特征和/或频谱特征。基于音频的声纹特征和/或频谱特征,可以确定音频关键词,如歌手名称、歌曲名称。例如,对于音乐类短视频,通过提取音频中的声纹特征和/或频谱特征,来确定该音乐短视频相关的歌手名称、歌曲名称。其中,声纹特征可以包含于频谱特征,或者说,声纹特征可以是根据频谱特征得到的。除此之外,基于频谱特征还可以得到音频的检索特征,检索特征包括但不限于音频指纹,比如波峰能量点。
[0080]
基于此,在一些可能的实现方式中,首先从音频信息中提取声纹特征和/或频谱特征;再在预设音频特征库中检索与该声纹特征匹配的音频关键词。其中,预设音频特征库可以包括声纹特征库,声纹特征库包含大量相对应的声纹特征与人物名称。例如,可以筛选曲库中全部歌手的能够反映其声音特征的代表歌曲,利用筛选出的代表歌曲提取每个歌手的声纹特征,构建预设声纹特征库。通过在声纹特征库中检索与该声纹特征匹配的声纹特征,可以确定相应的歌手名称。具体实现时,可以提取音频的声学特征作为声纹特征,也可以利用预先训练得到的神经网络模型输出音频对应的嵌入向量特征,作为声纹特征。前述神经网络模型可以为卷积神经网络(convolutional neural networks,cnn)、循环神经网络(recurrent neural network,rnn)等,在此不做限制。
[0081]
在另一些可能的实现方式中,预设音频特征库还可以包括音频检索特征库,音频检索特征库中包括大量歌手的歌曲的检索特征及与检索特征对应的歌曲名称。具体实现中,可以针对曲库中所有歌曲,提取歌曲的检索特征,根据提取出的检索特征构建音频检索特征库。
[0082]
根据上述实现方式,对于一些特定类别的视频,如音乐类视频,通过其音频信息中提取声纹特征和/或频谱特征,并进一步匹配到音频关键词,将音频关键词也作为视频特征信息,进一步提高视频特征信息的信息密度及其与视频内容的相关度。
[0083]
综上所述,在s301的一种具体实现方式中,首先将音频信息转换成音频文本;然后拼接音频文本与目标视频的描述文本,得到视频特征信息。和/或,从音频信息中提取声纹特征和/或频谱特征;从预设音频特征库中检索与声纹特征和/或频谱特征匹配的音频关键词,其中,音频关键词包括根据声纹特征和/或频谱特征确定的歌手关键词和/或歌曲关键
词;拼接音频关键词与所述描述文本,得到视频特征信息。
[0084]
s302,从所述视频特征信息中识别出预设类别的指称项和所述指称项的上下文信息。
[0085]
本公开实施例中,由于视频特征信息是从目标视频的多种模态的信息中提取出的,因此其信息量丰富度及与视频内容相关度较高。从这样的视频特征信息中识别预设类别的指称项,可以保证指称项识别的全面性,避免信息丢失。
[0086]
本公开实施例中,可以根据场景需求预设期望识别的指称项的类别。针对视频特征信息中的指定类型的指称项进行识别,从而忽略无关的指称项。例如,对于影视类视频,从其视频特征信息中识别影视类别的指称项。对于读书类视频,从其视频特征信息中识别图书类别的指称项。
[0087]
在一些可能的实现方式中,将视频特征信息输入到预先训练的指称识别模型中,利用该指称识别模型从视频特征信息中识别出预设类别的指称项。实际应用中,当已知视频类型时,可以根据视频类型选择要识别的指称类型,并训练相应的指称识别模型。如对于影视类视频,则可以利用预先训练的影视类实体指称识别模型,对视频特征信息中的影视名称进行识别;对于音乐类视频,则可以利用预先训练的音乐类实体指称识别模型,对视频特征信息中的歌曲名称进行识别。
[0088]
上述指称识别模型可以是基于来自变换器的双向编码器表征量(bidirectionalencoder representations from transformer,bert)连接条件随机场(conditional random fields,crf)的神经网络模型。应理解的是,本领域技术人员根据本文的启示和教导,清楚如何对由bert模型和crf模型构成的初始指称识别模型进行训练,以得到用于识别预设类别的指称项的指称识别模型,而无需付出创造性劳动。因此,关于指称识别模型的训练过程,本文不予赘述。
[0089]
需要说明的是,具体实施中,可以从视频特征信息中识别出一个或者多个预设类别的指称项。对于同时识别出的多个指称项,可能均是用来指称同一实体的,也可能是分别指称不同实体的。需要注意的是,在识别出多个预设类别的指称项的情形中,针对每个指称项执行本公开中实体识别方法的后续步骤即可。下文将以一个指称项为例,对本公开实施例中实体识别方法的后续步骤进行介绍。
[0090]
s303,确定所述指称项对应的候选实体。
[0091]
在一种实现方式中,首先在预置知识库中检索指称项的多个相关实体,并抽取每个相关实体的实体信息;根据相关实体的实体信息中是否包含视频特征信息中的人物关键词,则对相关实体进行过滤,以从多个相关实体中确定出指称项对应的候选实体;或者,根据相关实体的实体信息中是否包含视频特征信息中的音频关键词,则对相关实体进行过滤,以从多个相关实体中确定出指称项对应的候选实体。
[0092]
预置知识库可以包括多种类别的知识图谱。在s303中,根据指称项所属的预设类别确定相应的知识图谱。在相应知识图谱中检索与该指称项对应的相关实体。
[0093]
相关实体关联的实体信息,即知识库中与该相关实体关联的一条条知识。示例性的,对于相关实体“天龙八部(1)”,其关联的知识包括“天龙八部(1)”的版本(播出年份)、导演信息、主演信息、编剧信息、出品信息等。对于相关实体“天龙八部(2)”,其关联的知识包括“天龙八部(2)”的作者信息、出版信息等。其中,前述“(1)”和“(2)”用于区分同名的相关
实体。
[0094]
从预置知识库中抽取某个相关实体的实体信息,即是抽取包含该相关实体的三元组。示例性的,包含实体1的三元组如:(实体1,关系,实体2)、(实体3,关系,实体1)、(实体1,属性1,属性值)、(实体1,属性2,属性值)。那么,包含“天龙八部(1)”的三元组如:(天龙八部1,类型,电视剧),(天龙八部1,版本,1997),(天龙八部1,导演,李某胜),(天龙八部1,主演,黄某华)、(天龙八部1,主演,陈某民)等。
[0095]
相对于其他数据源而言,从知识库中抽取出的候选实体的实体信息能更加准确的表达候选实体的语义,且由于这样的信息已经是结构化的信息,因此可以省去去停用词、切词等预处理步骤。
[0096]
根据上述实现方式,在从图像信息中识别出人脸信息并匹配到与人脸信息对应的人物关键词的情况下,先利用人物关联词过滤掉一部分相关实体,以确定指称项对应的候选实体。具体的,对于每个相关实体,判断其实体信息中是否包含人物关键词,若包含该人物关键词,则确定为指称项对应的候选实体;若不包含该人物关键词,则将该相关实体剔除,从而不再继续确定指称项与该相关实体的匹配度。利用人脸信息所匹配出的人物关键词,对相关实体进行前置处理,以预先过滤掉一部分相关实体,可以降低后续特征匹配过程的计算量。
[0097]
沿用上述示例,在从视频的图像信息中识别出饰演“乔峰”的演员的人脸信息,并匹配到该人脸信息对应的人物名称为“黄某华”的情况下,可以利用“黄某华”这一人物名称,过滤掉其他版本的电视剧“天龙八部”,保留演员“黄某华”参演的“天龙八部”。
[0098]
根据上述实现方式,在从音频信息中识别出声纹特征和/或曲目特征并匹配到对应的音频关键词的情况下,先利用音频关键词过滤掉一部分相关实体,以确定与指称项对应的候选实体。具体的,对于每个相关实体,判断实体信息中是否包含音频关键词,若包含该音频关键词,则确定为与指称项对应的候选实体;若不包含该音频关键词,则将该相关实体剔除,从而不再继续确定指称项与该相关实体的匹配度。利用声纹特征和/或频谱特征所匹配出的音频关键词,对相关实体进行前置处理,以预先过滤掉一部分相关实体,可以降低后续特征匹配过程的计算量。
[0099]
在一个例子中,从某个音乐类视频中提取出的视频特征信息为“明天你是否会想起,昨天你写的日记,明天你是否还惦记,曾经最爱哭的你,老师们都已想不起,猜不出问题的你
……
;同桌的你;
……
;罗大佑;”,该视频特征信息中的音乐关键词为“罗大佑”,从该视频特征信息中识别出的音乐类指称项为“同桌的你”,该音乐类指称项对应的候选实体包括电影“同桌的你”、歌手1演唱的“同桌的你”、歌手2演唱的“同桌的你”以及“罗大佑”演唱的“同桌的你”等。在这个例子中,利用音频关键词“罗大佑”,可以排除电影“同桌的你”、歌手1演唱的“同桌的你”、歌手2演唱的“同桌的你”,保留“罗大佑”演唱的“同桌的你”。
[0100]
s304,利用利用所述指称项的上下文信息和检索到的候选实体,对所述指称项执行消歧处理,得到消歧处理结果。
[0101]
本公开实施例中,由于视频特征信息是从目标视频的多种模态的信息中提取出的,因此其信息量丰富度及与视频内容相关度较高,例如,包含指称项的丰富的上下文信息。利用指称项的丰富的上下文信息和候选实体,对指称项进行消歧处理,可以提高消歧处理结果的准确度,从而保证实体链接的准确性,避免实体错连。其中,指称项的上下文信息
semantic models,dssm)确定指称项与候选实体的匹配度。而由于dssm模型中采用词袋模型,损失了指称项的上下文信息,导致匹配结果不准确。相对于前述相关技术,本公开实施例采用bert模型确定指称项与候选实体的匹配度,充分考虑指称项的上下文信息,因此匹配结果更准确。
[0111]
s305,根据消歧处理结果确定所述指称项对应的目标实体。
[0112]
在一些可能的实现方式中,首先确定与指称项的匹配度大于预设阈值的目标候选实体。然后将这些目标候选实体中的与指称项的匹配度最高的确定为目标实体。或者,首先确定与指称项的匹配度最高的候选实体,再判断该候选实体与指称项的匹配度是否大于预设阈值,若该候选实体与指称项的匹配度大于预设阈值,则将该候选实体确定为目标实体。
[0113]
在上述实现方式中,如果每个候选实体与指称项的匹配度均不大于预设预置,则确定该指称项对应的目标实体为空实体(即nil实体)。
[0114]
示例性的,预设特征匹配模型的输出为一个1
×
2的向量,例如可以表示为(p1,p2),p1 p2=1。其中,p1代表该候选实体与指称项相关的概率,p2则代表该候选实体与指称项不相关的概率。那么,p1即为该候选实体与指称项的匹配度。实际应用中,可以根据场景需求,通过调整预设阈值的方式,设置实体识别的目标精度。
[0115]
由以上实施例可以看出,由于视频特征信息是从目标视频的多种模态的信息中提取出的,因此其信息量丰富度及与视频内容相关度较高。针对该视频特征信息进行指称项识别,可以保证指称项识别的全面性,避免信息丢失;并且,由于该视频特征信息还包括指称项的丰富的上下文信息,因此利用指称项的丰富的上下文信息和候选实体关联的实体信息,对指称项进行消歧处理,可以提高消歧处理结果的准确度,从而保证实体链接的准确性,避免实体错连。
[0116]
在一些实施例中,本公开实施例中的实体识别方法还包括:
[0117]
s306,获取目标实体关联的实体信息,基于所述目标实体关联的实体信息,确定用于描述所述目标视频的视频关键信息。
[0118]
例如,对于目标实体1,将其关联的三元组确定为目标视频的视频关键信息,如(实体1,关系,实体2)、(实体3,关系,实体1)、(实体1,属性1,属性值)、(实体1,属性2,属性值)。
[0119]
根据链接到的目标实体获得目标视频的关键信息,提高了视频内容的理解精度、广度和深度。一方面,可以基于视频的视频关键信息标注视频、推荐视频或者检索视频,另一方面,由于目标实体的实体信息是知识库中的结构化的知识,因此将目标实体的实体信息作为视频关键信息,还实现了对视频内容的结构化表达,为后续标注视频、推荐视频以及检索视频提供便利。
[0120]
图7是根据一示例性实施例示出的一种实体识别装置框图,如图7所示,本公开实施例提供的实体识别装置70,包括视频特征提取单元71,指称识别单元72,候选实体确定单元73和目标实体确定单元74;
[0121]
视频特征提取单元71,用于获取目标视频的视频特征信息,所述视频特征信息包括从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息和所述目标视频的描述文本。例如,如图3所示,视频特征提取单元71可以用于执行s301。
[0122]
指称识别单元72,用于从所述视频特征信息中识别出预设类别的指称项和所述指称项的上下文信息。例如,如图3所示,指称识别单元72可以用于执行s302。
[0123]
候选实体确定单元73,用于确定所述指称项对应的候选实体。例如,如图3所示,候选实体确定单元73可以用于执行s303。
[0124]
目标实体确定单元74,用于利用所述指称项的上下文信息和检索到的候选实体,对所述指称项执行消歧处理,得到消歧处理结果;根据消歧处理结果确定所述指称项对应的目标实体。例如,如图3所示,目标实体确定单元74可以用于执行s304和s305。
[0125]
在一些实施例中,目标实体确定单元74具体用于:获取每个所述候选实体关联的实体信息;利用预先训练的特征匹配模型确定包含所述上下文信息的所述视频特征信息与所述实体信息的匹配度,作为所述指称项与所述候选实体的匹配度。例如,如图4所示,目标实体确定单元74可以用于执行s3041-s3042。
[0126]
在一些实施例中,所述特征匹配模型包括特征提取部分和特征匹配部分,所述特征提取部分是通过使用指定样本集训练语义表示模型得到的,所述语义表示模型是通过使用通用语料数据训练初始神经网络模型得到的;所述目标实体确定单元74,具体用于:利用所述特征提取部分,从视频特征信息中提取视频特征向量,以及,从所述实体信息中提取实体特征向量;所述视频特征信息为从目标视频的图像信息及音频信息中的至少一项中提取出的文本信息与所述目标视频的描述文本拼接后的信息;利用所述特征匹配部分,确定所述视频特征向量和所述实体特征向量的匹配度。
[0127]
在一些实施例中,视频特征提取单元71具体用于:从所述图像信息中提取图像文本;拼接所述图像文本与所述描述文本,得到所述视频特征信息。
[0128]
在一些实施例中,视频特征提取单元71具体用于:从所述图像信息中提取人脸信息;通过将所述人脸信息与预置人脸特征库进行匹配,确定所述人脸信息对应的人物关键词;拼接所述人物关键词与所述描述文本,得到所述视频特征信息。
[0129]
在一些实施例中,候选实体确定单元73具体用于:在预置知识库中检索所述指称项的多个相关实体,并抽取每个所述相关实体的实体信息;根据所述相关实体的所述实体信息中是否包含所述人物关键词,对所述相关实体进行过滤,以从所述多个相关实体中确定出所述指称项对应的候选实体。
[0130]
在一些实施例中,视频特征提取单元71具体用于:将所述音频信息转换成音频文本;拼接所述音频文本与所述描述文本,得到所述视频特征信息。
[0131]
在一些实施例中,视频特征提取单元71具体用于:从所述音频信息中提取声纹特征和/或频谱特征;从预设音频特征库中检索与所述声纹特征和/或频谱特征匹配的音频关键词,其中,所述音频关键词包括根据所述声纹特征和/或频谱特征确定的歌手关键词和/或歌曲关键词;拼接所述音频关键词与所述描述文本,得到所述视频特征信息。
[0132]
在一些实施例中,候选实体确定单元73具体用于:在预置知识库中检索所述指称项的多个相关实体,并抽取每个所述相关实体的实体信息;根据所述相关实体的所述实体信息中是否包含所述音频关键词,对所述相关实体进行过滤,以从所述多个相关实体中确定出所述指称项对应的候选实体。
[0133]
在一些实施例中,还包括视频关键信息确定单元75,用于:获取所述目标实体关联的实体信息;基于所述目标实体关联的实体信息,确定用于描述所述目标视频的视频关键信息。
[0134]
在一些实施例中,目标实体确定单元74具体用于:确定与所述指称项的匹配度大
于预设阈值的目标候选实体;将与所述指称项的匹配度最高的目标候选实体确定为所述目标实体。
[0135]
基于本公开实施例提供的实体识别装置,由于视频特征信息是从目标视频的多种模态的信息中提取出的,因此其信息量丰富度及与视频内容相关度较高。针对该视频特征信息进行指称项识别,可以保证指称项识别的全面性,避免信息丢失;并且,由于该视频特征信息还包括指称项的丰富的上下文信息,因此利用指称项的丰富的上下文信息和候选实体关联的实体信息,对指称项进行消歧处理,可以提高消歧处理结果的准确度,从而保证实体链接的准确性,避免实体错连。
[0136]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0137]
图8是本公开提供的一种服务器的结构示意图。如图8,该服务器80可以包括至少一个处理器801以及用于存储处理器可执行指令的存储器803。其中,处理器801被配置为执行存储器803中的指令,以实现上述实施例中的实体识别方法。
[0138]
另外,服务器80还可以包括通信总线802以及至少一个通信接口804。
[0139]
处理器801可以是一个处理器(central processing units,cpu),微处理单元,asic,或一个或多个用于控制本公开方案程序执行的集成电路。
[0140]
通信总线802可包括一通路,在上述组件之间传送信息。
[0141]
通信接口804,使用任何收发器一类的装置,用于与其他设备或通信网络通信,如以太网,无线接入网(radio access network,ran),无线局域网(wireless local area networks,wlan)等。
[0142]
存储器803可以是只读存储器(read-only memory,rom)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,ram)或者可存储信息和指令的其他类型的动态存储设备,也可以是电可擦可编程只读存储器(electrically erasable programmable read-only memory,eeprom)、只读光盘(compact disc read-only memory,cd-rom)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器可以是独立存在,通过总线与处理单元相连接。存储器也可以和处理单元集成在一起。
[0143]
其中,存储器803用于存储执行本公开方案的指令,并由处理器801来控制执行。处理器801用于执行存储器803中存储的指令,从而实现本公开方法中的功能。
[0144]
作为一个示例,结合图7,实体识别装置70中的视频特征提取单元71,指称识别单元72,候选实体确定单元73和目标实体确定单元74实现的功能与图8中的处理器801的功能相同。
[0145]
在具体实现中,作为一种实施例,处理器801可以包括一个或多个cpu,例如图8中的cpu0和cpu1。
[0146]
在具体实现中,作为一种实施例,服务器80可以包括多个处理器,例如图8中的处理器801和处理器807。这些处理器中的每一个可以是一个单核(single-cpu)处理器,也可以是一个多核(multi-cpu)处理器。这里的处理器可以指一个或多个设备、电路、和/或用于
处理数据(例如计算机程序指令)的处理核。
[0147]
在具体实现中,作为一种实施例,服务器80还可以包括输出设备805和输入设备806。输出设备805和处理器801通信,可以以多种方式来显示信息。例如,输出设备805可以是液晶显示器(liquid crystal display,lcd),发光二级管(light emitting diode,led)显示设备,阴极射线管(cathode ray tube,crt)显示设备,或投影仪(projector)等。输入设备806和处理器801通信,可以以多种方式接受用户的输入。例如,输入设备806可以是鼠标、键盘、触摸屏设备或传感设备等。
[0148]
本领域技术人员可以理解,图8中示出的结构并不构成对服务器80的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
[0149]
另外,本公开还提供一种计算机可读存储介质,当计算机可读存储介质中的指令由服务器的处理器执行时,使得服务器能够执行如上述实施例所提供的实体识别方法。
[0150]
另外,本公开还提供一种计算机程序产品,包括计算机指令,当计算机指令在服务器上运行时,使得服务器执行如上述实施例所提供的实体识别方法。
[0151]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由权利要求指出。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。