一种基于rowpa优化算法的多智能体集群路径寻优方法
技术领域
1.本发明涉及多智能体协同控制技术领域,尤其涉及一种基于rowpa优化算法的多智能体集群路径寻优方法。
背景技术:
2.随着当今工程优化问题的不断发展,大量工序形成的关系越来越错综复杂,特别是在多智能体集群路径寻优领域中,采用经典的优化方法求解几乎得不到理想的结果,于是通常采用狼群算法(wolf pack algorithm,wpa算法)进行多个无人智能体(例如无人机和无人艇)路径寻优和协作围捕,狼群算法作为一种元启发式的群智能算法,虽然诞生时间比较晚,但突破了目标函数特性的限制,对初值不敏感,且能弥补经典优化方法的缺陷,使得多智能体集群路径寻优速度快、收敛能力强、搜索精度高和鲁棒性强等,狼群算法成为了解决优化问题的新高地,在信息科学、计算机科学和控制科学等领域日益展现出强大的生命力,拥有广阔的研究前景。
3.然而,目前对wpa算法的研究尚浅,wpa算法主要应用在高维问题的求解上,对二维和三维等低维问题的关注较少,另一方面,在wpa算法的设计上,主要是通过增加和融合新的步骤来提高狼群算法的精确度,而忽略了算法本身的缺陷,如设置较多参数导致性能下降,现有的wpa算法对狼群的移动状态研究较细致,根据狼群在觅食活动的不同阶段,提出了游猎步长、奔袭步长和围捕步长这三种步长,但实际上这三个步长都是固定步长公式,没有应对外界变化的反馈机制,缺乏灵活性;易陷入局部最优解;头狼的位置不断变换导致算法无序问题,现有的wpa算法在第一次首领狼召唤,其他游猎狼赶赴奔袭的过程中,存在某匹狼突然探寻到更优的气味浓度因子从而转变为新的首领狼,重新发起召唤行为的可能性。但若在一次觅食活动中存在多次频繁的召唤行为,此时对首领狼(即目标猎物位置)和游猎狼在解空间中进行反复的位置认定,不仅会付出更多狼群捕食的代价,还会引发首领狼和各游猎狼在二维环境中的位置突变问题,延长响应时间,致使wpa算法可能陷入无序状态,即在多智能体协同控制的路径规划领域中,采用wpa算法会发生陷入局部最优解的问题,且智能体在围捕过程中还会发生相互碰撞和信息共享问题,因此,需要一种能够克服以上问题的多智能体集群路径寻优方法。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于rowpa优化算法的多智能体集群路径寻优方法。
5.本发明的目的可以通过以下技术方案来实现:
6.一种基于rowpa优化算法的多智能体集群路径寻优方法,该方法包括以下步骤:
7.步骤1:初始化狼群,狼群即多个无人智能体,对rowpa优化算法的参数进行预设;
8.步骤2:浓度判定因子判断是否有个体狼达到首领狼的判断条件,若否,则狼群在解空间中进行游走搜寻,即狼群进入游走阶段,若是,则产生首领狼,即目标,并发起召唤;
9.步骤3:首领狼发起召唤后,狼群中的其他游猎狼根据a*算法和首领狼替换机制进行路径规划,向首领狼位置聚集;
10.步骤4:除首领狼外的其余游猎狼转入围攻行为,对目标实施围捕,获得目标的位置;
11.步骤5:基于淘汰更新机制对狼群进行更新,并判断狼群寻优的精度是否达到预设精度或达到最大迭代次数,若是,则输出首领狼的位置,即目标的位置,若否,则返回步骤2。
12.所述的步骤1中,在rowpa优化算法中,对狼群的阶级制度进行修改,狼群中的阶级制度为首领狼和游猎狼,改变首领狼的产生规则,融合侦察狼和猛狼的定义,暂时淘汰侦察狼和猛狼,融合二者功能,从而产生游猎狼,在首领狼未产生的情况下,狼群中的所有狼均为游猎狼,以提高狼群的利用率,提升狼群聚集效率。
13.所述的步骤1中,初始化狼群的过程具体包括以下步骤:
14.步骤101:假设狼群中所有狼的数量为a,最大迭代次数为v
max
,由于是在二维空间,狼群在猎捕活动中的总方向数目为2,游猎狼最大的搜索次数为t
max
,其游猎步长设为step
x
,求解空间内目标的最优位置;
15.步骤102:假设某一匹狼在位置p嗅到的气味浓度因子为c,则第i匹狼所处位置的气味浓度因子为ci,最优气味浓度因子的判定值为c
lead
,障碍物处的气味浓度因子为0,气味浓度因子的计算公式为:
[0016][0017]
其中,c为气味浓度因子,p为位置向量;
[0018]
步骤103:每一匹狼的位置用向量p表示,定义在二维空间中p=(p1,p2),p1为其在一维空间的分量,p2为其在二维空间的分量,则狼群中第i匹狼的位置的表达式为:
[0019]
pi=(p
i1
,p
i2
),1≤i≤a
[0020]
其中,a为狼群的总数,pi为第i匹狼的位置向量,p
i1
为第i匹狼的在一维空间的分量,p
i2
为第i匹狼在二维空间的分量;
[0021]
步骤104:设初始迭代数t=0,对狼群的位置初始化,随机生成狼群中第i匹狼的初始位置,狼群位置初始化的公式为:
[0022]
p
i0
=p
min
(p
max-p
min
)rand(
·
)
[0023]
其中,p
i0
为第i匹狼所在初始位置的位置向量,p
min
为狼群在二维空间中的取值下限,即最小取值,p
max
为狼群在二维空间的取值上限,即最大取值,rand(
·
)为一个在[0,1]范围内生成随机数的随机函数。
[0024]
所述的步骤2中,狼群在解空间中进行游走搜寻的过程具体包括以下步骤:
[0025]
步骤201:若在狼群初始化后没有个体狼达到判断条件转变为首领狼发起号召,则游猎狼开始在解空间中进行游走搜寻,寻找目标,游走阶段由于未知最优解的位置,狼群处于动态搜寻状态;
[0026]
步骤202:将反馈调节机制加入到游走公式中,并提出自适应游走的步长公式,在已知最大游走搜索次数为t
max
的情况下,游走阶段的自适应控制公式为:
[0027][0028]
其中,β用以为搜索提供多个方向选择,使游走步长step
x
不局限于一个方向,能够更全面地搜寻周围环境,保证机器人在搜寻过程中通过感知外部变化调整围攻步长,为第i匹狼在第n维空间移动后的位置向量,为第i匹狼在第n维空间移动后的位置向量,r为空间维度的数量;
[0029]
步骤203:判断是否有狼达到浓度判定因子c
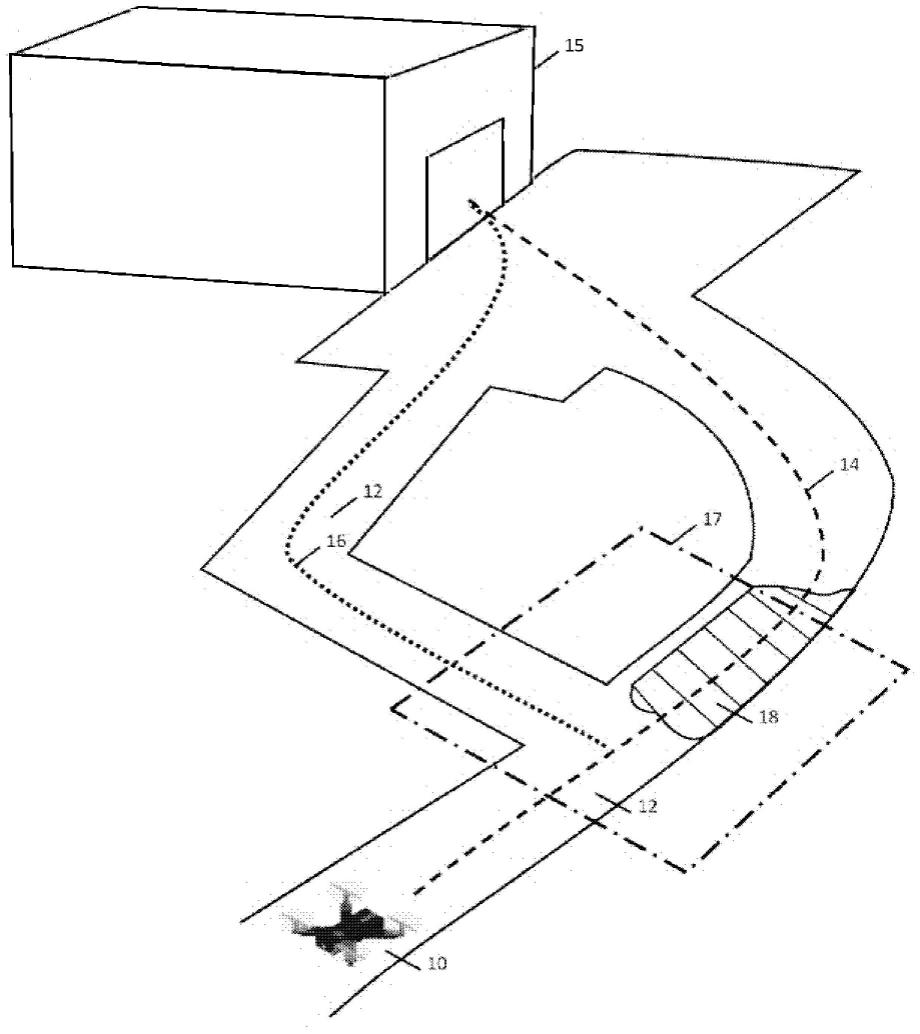
lead
,若是,则转变为首领狼并发起召唤,狼群游猎阶段结束,转入奔袭阶段,若否,则继续执行新一轮的游走行为,直到某一匹游猎狼率先感知到气味浓度因子cn≥c
lead
或游猎次数t达到最大游走搜索次数t
max
。
[0030]
所述的步骤2中,产生首领狼的过程具体为:
[0031]
计算出每一匹狼所处位置的猎物的气味浓度因子,并形成气味浓度因子集c,第i匹狼所处位置的气味浓度因子为ci,首领狼所处位置的气味浓度因子为c
lead
,设定一个最优气味浓度因子的判定值c
lead
,即浓度判断因子,根据气味浓度因子c的大小,判断气味浓度因子集c中最大的气味浓度因子是否大于等于c
lead
,若是,则该狼转变为首领狼,并将所在位置记为p
best
。
[0032]
所述的步骤2中,首领狼是可变的,在狼群迭代过程中,每次进化中具有最优气味浓度因子的狼与当前首领狼的气味浓度因子进行比较,若此狼的气味浓度因子更优,则成为新的首领狼,首领狼在猎捕活动中无需执行游猎、奔袭和围捕三种智能行为,仅仅触发召唤功能,成为狼群猎捕活动的标志,且首领狼产生规则中设有约束条件,以解决出现首领狼在几匹游猎狼间反复变换的无序情况,约束条件包括:
[0033]
第一约束条件:规定狼群在每次的围捕过程中,一匹狼仅有一次转变为首领狼的机会,即在一次围捕中一匹狼仅能发出一次召唤行为;
[0034]
第二约束条件:设立历史首领狼集h,过去成为过首领狼的狼序号将计入历史首领狼集h中,第i匹狼成为首领狼的前提条件是第i匹狼不属于历史首领狼集h;
[0035]
第三约束条件:每次的召唤行为后,浓度判定因子c
lead
发生变化,即狼群中每一次发起的召唤行为后,新的最优解是原先c
lead
的1.5倍,再次发起召唤行为的条件将更苛刻,以在运行过程中大大减少算法的无序性,并保证最优解的质量。
[0036]
所述的第二约束条件和第三约束条件的表达式为:
[0037][0038]
其中,c'
lead
为当前的浓度判定因子,c
lead
为变化前的浓度判定因子,pi为第i匹狼的位置向量,p
best
为首领狼的所在位置向量,n为狼群中游猎狼的数量,h为历史首领狼集。
[0039]
所述的步骤3中,狼群中的其他游猎狼根据a*算法和首领狼替换机制进行路径规划的过程具体包括以下步骤:
[0040]
步骤301:首领狼发起召唤,此时首领狼的位置即为目标位置,且保持不变,狼群中剩下的n匹游猎狼向目标发起奔袭,此过程实际上是一个起点为各匹游猎狼,终点为目标的
路径规划问题,基于转角优化后的启发式a*算法进行路径寻优,a*算法的总代价动态衡量计算公式为:
[0041]
f(p)=g(p) w(p)*h(p),w(p)≥1
[0042]
其中,w(p)为影响评估值的调节函数,即w(p)越大,则此时a*算法就越趋近于bfs算法,而w(p)越小,则a*算法越趋近于dijkstra算法;
[0043]
步骤302:游猎狼在向首领狼奔袭的过程中,若存在第i匹狼的气味浓度因子ci大于当前首领狼的气味浓度因子c
lead
,那么该游猎狼就会变为新的首领狼,原先的首领狼则转变为游猎狼,随着新的首领狼发起召唤,各游猎狼朝着新的目标位置重新奔袭,若在奔袭过程中,各游猎狼拥有的气味浓度因子一直小于c
lead
,则会持续向目标位置奔袭,直至与目标位置之间的距离小于设定的距离阈值d
limited
,游猎狼停止奔袭,并进入围捕阶段,距离阈值d
limited
的计算公式为:
[0044][0045]
其中,ω为距离的判定因子,p
nmin
为狼群在第n维空间中的取值下限,p
nmax
为狼群在第n维空间的取值上限。
[0046]
所述的步骤4中,对目标实施围捕的过程具体包括以下步骤:
[0047]
步骤401:在所有游猎狼离首领狼的距离满足小于等于阈值d
limited
后,各游猎狼通过合作对目标进行围捕;
[0048]
步骤402:在已知最大迭代次数为v
max
情况下,构造并得到围捕阶段的自适应控制公式,以使得围捕行为具备对环境的反馈调节机制,围捕阶段的自适应控制公式为:
[0049][0050]
其中,为迭代次数为t时第s匹狼在第n维空间预计移动后的位置向量,为迭代次数为t时第s匹狼在第n维空间的位置向量,为迭代次数为t时首领狼的位置向量,v为当前迭代次数,t为迭代次数,根据围捕步长step3设定,α为一个从0到1的随机数,以避免在迭代次数t趋近于最大迭代次数v
max
时算法寻优变化不明显,β用以为搜索提供多个方向选择,使围捕步长step3不局限于一个方向,能够更全面地搜寻周围环境,保证智能体在围捕过程中能够感知外部变化来调整围捕步长;
[0051]
步骤403:基于游猎狼互相没有信息交流导致的避障问题,在每次执行围捕步长后进行信息交流,提高游猎狼在空间中的搜索效率,信息交流的公式为:
[0052][0053]
其中,p
in
为第i匹狼移动前在第n维空间的位置向量,pi'n为第i匹狼此时在第n维空间的位置向量,为第i匹狼在第n维空间中与其相邻的第k匹狼和第g匹狼保持安全距离的影响因子,φ
in
∈[-1,1]为第i匹狼在第n维空间中与首领狼保持安全距离的影响因子;
[0054]
步骤404:若游猎狼遇到障碍物,则进行编队避障,若无障碍物,则进行编队构型,并保持队形;
[0055]
步骤405:当迭代次数t达到狼群的最大迭代次数v
max
或得到的最优个体达到预设精度时,围捕阶段结束。
[0056]
所述的步骤5中,基于淘汰更新机制对狼群进行更新的过程具体为:
[0057]
在一次围捕阶段结束后,淘汰气味浓度因子最小的b匹狼,即适应度值最差的b匹狼,同时随机生成b匹人工狼,淘汰更新机制的种群优化公式为:
[0058][0059]
其中,b为淘汰的狼的数量,β为狼群的进化比例因子,a为狼群中所有狼的数量,n为狼群中游猎狼的数量。
[0060]
与现有技术相比,本发明具有以下优点:
[0061]
1、本发明通过对wpa算法中狼群的阶级制度进行修改,提高了狼群的利用率,提升了狼群聚集效率,在rowpa优化算法中,狼群中的阶级制度被精简为首领狼和游猎狼,融合了侦察狼和猛狼二者的定义,首领狼的定义不变,即在猎捕活动中拥有最优猎物气味浓度因子c
lead
的狼,能够通过召唤功能聚集周围的狼聚集围捕猎物,改变了首领狼的产生规则,即c
lead
不再是从狼群中选出的最优值,而是预设的一个判定值,只有达到判定值的游猎狼才能成为首领狼并发起召唤,使得首领狼的产生更客观,而游猎狼则为既能完成搜寻目标任务,同时也能完成围捕目标猎物任务的狼,兼具现有的wpa算法中侦察狼和猛狼的行为功能,本发明还通过减少wpa算法中涉及的步长因子等一些参数设定,优化了参数配置,放宽了对狼群移动的限制,一定程度上提升了wpa算法的运行效率,提高了多智能体集群路径寻优的速率;
[0062]
2、本发明结合了转角优化的动态权值启发a*算法,在rowpa优化算法中,将现有的wpa算法过程中隐含的路径规划问题细化后进行了研究,当其中一只游猎狼拥有最优的气味浓度因子c
lead
转变为首领狼,发起召唤后,在默认首领狼等于目标的条件下,对于空间中的其他游猎狼而言,此时已知解的位置,问题可转变为静态空间下已知起点和终点的路径规划问题,结合转角优化后的启发式a*算法进行路径寻优,以加快无人智能体聚拢围攻目标的速度,减少目标的响应时长;
[0063]
3、本发明通过设置约束条件使得再次发起召唤行为的条件将更苛刻,解决了可能由于位置突变造成的无序问题,以在算法运行过程中大大减少算法的无序性,也能保证最优解的质量,有效避免在多智能体协同控制的路径规划中陷入局部最优解,提高了寻优精度;
[0064]
4、本发明通过在rowpa优化算法中设置信息交流机制和自适应的分布式控制策略,实现了在多智能体进行协同围捕时有效防止无人智能体在围捕过程中的碰撞和信息共享问题,多个无人智能体能够高效且无冲突地围捕环境中的目标。
附图说明
[0065]
图1为本发明中实施例的研究框架图。
[0066]
图2为本发明的rowpa狼群等级制度示意图。
[0067]
图3为本发明的方法流程图。
[0068]
图4为本发明的围捕详细流程图。
[0069]
图5为本发明wpa和rowpa在wine集上的分类结果示意图。
[0070]
图6为本发明wpa和rowpa对参数c的寻优过程示意图。
[0071]
图7为本发明wpa和rowpa对参数g的寻优过程示意图。
[0072]
图8为本发明的二维平面围捕环境示意图。
[0073]
图9为本发明针对mcst问题四次求解效果图,其中,图(9a)为本发明针对mcst问题第一次求解效果图,图(9b)为本发明针对mcst问题第二次求解效果图,图(9c)为本发明针对mcst问题第三次求解效果图,图(9d)为本发明针对mcst问题第四次求解效果图。
[0074]
图10为本发明针对mcst问题四次实验输出结果示意图,其中,图(10a)为本发明针对mcst问题第一次实验输出结果示意图,图(10b)为本发明针对mcst问题第二次实验输出结果示意图,图(10c)为本发明针对mcst问题第三次实验输出结果示意图,图(10d)为本发明针对mcst问题第四次实验输出结果示意图。
[0075]
图11为本发明针对mcst问题四次实验狼群奔袭的原始路径复现图,其中,图(11a)为本发明针对mcst问题第一次实验狼群奔袭的原始路径复现图,图(11b)为本发明针对mcst问题第二次实验狼群奔袭的原始路径复现图,图(11c)为本发明针对mcst问题第三次实验狼群奔袭的原始路径复现图,图(11d)为本发明针对mcst问题第四次实验狼群奔袭的原始路径复现图。
[0076]
图12为本发明针对mcst问题四次实验狼群奔袭的转角优化路径复现图,其中,图(12a)为本发明针对mcst问题第一次实验狼群奔袭的转角优化路径复现图,图(12b)为本发明针对mcst问题第二次实验狼群奔袭的转角优化路径复现图,图(12c)为本发明针对mcst问题第三次实验狼群奔袭的转角优化路径复现图,图(12d)为本发明针对mcst问题第四次实验狼群奔袭的转角优化路径复现图。
[0077]
图13为本发明求解mcst问题中狼群发生二次奔袭的情况示意图。
具体实施方式
[0078]
下面结合附图和具体实施例对本发明进行详细说明。
[0079]
实施例
[0080]
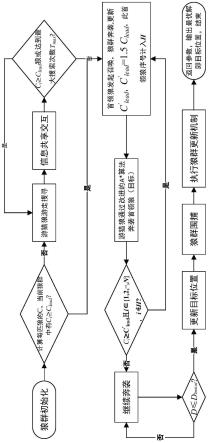
如图1所示,本发明提供了一种基于rowpa优化算法的多智能体集群路径寻优方法,该方法包括以下步骤:
[0081]
步骤1:初始化狼群,假设狼群的总数目为a,a∈{3,4,5},最大迭代次数为v
max
,由于是在二维空间,狼群在猎捕活动中的总方向数目为2,游猎狼最大的搜索次数为t
max
,其游猎步长设为step
x
,求解空间内目标猎物的最优位置,假设某一匹狼在位置p嗅到的猎物的气味浓度因子为c,则第i匹狼所处位置的气味浓度因子为ci,最优气味浓度因子的判定值为c
lead
,障碍物处的气味浓度因子为0,气味浓度因子的计算公式为:
[0082][0083]
其中,c为气味浓度因子,p为位置向量;
[0084]
每一匹狼的位置用向量p表示,定义在二维空间中p=(p1,p2),p1为其在一维空间的分量,p2为其在二维空间的分量,则狼群中第i匹狼的位置的表达式为:
[0085]
pi=(p
i1
,p
i2
),1≤i≤a
[0086]
其中,a为狼群的总数,pi为第i匹狼的位置向量,p
i1
为第i匹狼的在一维空间的分量,p
i2
为第i匹狼在二维空间的分量;
[0087]
之后,设初始迭代数t=0,对狼群的位置初始化,生成狼群中第i匹狼的随机初始化位置,狼群位置初始化的公式为:
[0088]
p
i0
=p
min
(p
max-p
min
)rand(
·
)
[0089]
其中,p
i0
为第i匹狼所在初始位置的位置向量,p
min
为狼群在二维空间中的取值下限,即最小取值,p
max
为狼群在二维空间的取值上限,即最大取值,rand(
·
)为一个在[0,1]范围内生成随机数的随机函数,用以保证每匹狼随机分散在环境中,有利于对解空间进行充分搜索;
[0090]
步骤2:游走阶段,若在狼群初始化后没有个体狼达到判断条件转变为首领狼发起号召,则游猎狼开始在解空间中进行游走搜寻,寻找目标,游走阶段由于未知最优解的位置,狼群处于动态搜寻状态,为了让狼群在游走阶段拥有更好的灵活性和自由性,把反馈调节机制加入到执行的游走公式中,提出自适应游走的步长公式,在已知最大游走搜索次数为t
max
情况下,游走阶段的自适应控制公式为:
[0091][0092]
其中,β用以为搜索提供多个方向选择,使游走步长step
x
不局限于一个方向,能够更全面地搜寻周围环境,保证机器人在搜寻过程中通过感知外部变化调整围攻步长,为第i匹狼在第n维空间移动后的位置向量,为第i匹狼在第n维空间移动后的位置向量,r为空间维度的数量;
[0093]
一旦有狼达到c
lead
,则转变为首领狼发起号召,游走阶段结束,转入奔袭阶段,否则,继续执行新一轮的游走行为,直到某匹狼率先感知到气味浓度因子cn≥c
lead
或游猎次数t达到最大限制t
max
;
[0094]
步骤3:狼群的召唤与奔袭阶段,首领狼触发召唤功能,此时首领狼与目标默认在同一位置,且保持不变,狼群中剩下的n-1匹游猎狼向目标位置发起奔袭,此过程实际上是一个已知起点为各游猎狼,终点为目标的路径规划问题,为了提高游猎狼的奔袭速度,减少首领狼的响应时长,可结合转角优化后的启发式a*算法进行路径寻优,根据a*算法的总代价动态衡量计算公式:
[0095]
f(p)=g(p) w(p)*h(p),w(p)≥1
[0096]
其中,w(p)为影响评估值的调节函数,即w(p)越大,则此时a*算法就越趋近于bfs算法,而w(p)越小,则a*算法越趋近于dijkstra算法;
[0097]
游猎狼在向首领狼奔袭的过程中,如果存在第i匹狼的气味浓度因子ci比当前首领狼更优,那么此游猎狼就会变为新的首领狼,原先的首领狼则回到游猎狼状态,随着新的首领狼发起召唤,各游猎狼朝着新最优位置重新奔袭,否则,如果在奔袭过程中,各游猎狼拥有的气味浓度因子一直小于c
lead
,则会持续向目标位置奔袭,直到与目标之间的距离小于设定的距离阈值d
limited
时,猛狼停止奔袭,进入围捕阶段,距离阈值的计算公式为:
[0098][0099]
其中,ω为距离的判定因子,p
nmin
为狼群在第n维空间中的取值下限,p
nmax
为狼群在第n维空间的取值上限;
[0100]
步骤4:狼群围捕阶段,围捕流程如图4所示,在所有游猎狼离首领狼的距离满足小于等于阈值d
limited
后,狼群通过合作对猎物进行围捕,直到算法迭代次数t达到狼群的最大迭代次数v
max
,或算法运行中获得的最优个体达到预设精度时,算法结束。
[0101]
为了使猎捕行为具备对环境的反馈调节机制,在已知最大迭代次数为v
max
情况下,围捕阶段的自适应控制公式为:
[0102][0103]
其中,为迭代次数为t时第s匹狼在第n维空间预计移动后的位置向量,为迭代次数为t时第s匹狼在第n维空间的位置向量,为迭代次数为t时首领狼的位置向量,v为当前迭代次数,α为一个从0到1的随机数,以避免在迭代次数t趋近于最大迭代次数v
max
时算法寻优变化不明显,β用以为搜索提供多个方向选择,使围捕步长step3不局限于一个方向,能够更全面地搜寻周围环境,保证智能体在围捕过程中能够感知外部变化来调整围捕步长;
[0104]
对于互相没有信息交流导致的避障问题,为提高侦察狼在空间中的搜索效率,以第i匹侦察狼为例,在每次执行围捕步长后增加信息交流行为,信息交流的公式为:
[0105][0106]
其中,p
in
为第i匹狼移动前在第n维空间的位置向量,pi'n为第i匹狼此时在第n维空间的位置向量,为第i匹狼在第n维空间中与其相邻的第k匹狼和第g匹狼保持安全距离的影响因子,φ
in
∈[-1,1]为第i匹狼在第n维空间中与首领狼保持安全距离的影响因子,该公式不仅考虑了相邻狼所在位置的信息,而且同时依赖首领狼位置的信息,起到了狼与狼之间的信息交流作用;
[0107]
步骤5:基于淘汰更新机制更新狼群,rowpa优化算法中的淘汰更新机制实则是一种基于胜者为王,论功行赏原则的分配制度,原理是狼群中的个体按照从强及弱的排序依次分配食物,这样将导致弱小的狼饿死,本发明的rowpa优化算法中的狼群更新机制为在一次围捕活动结束后,淘汰气味浓度因子最小,即适应度值最差的b匹狼,同时随机生成b匹人工狼,淘汰更新机制的狼群优化公式为:
[0108][0109]
其中,b为淘汰的狼的数量,β为狼群的进化比例因子,a为狼群中所有狼的个数,n为狼群中游猎狼的数量。
[0110]
产生首领狼的规则具体为:
[0111]
计算出每一匹狼所处位置的猎物的气味浓度因子,并形成气味浓度因子集c,第i
匹狼所处位置的气味浓度因子为ci,首领狼所处位置的气味浓度因子为c
lead
,但与现有wpa算法不同的是,首领狼的产生规则不是根据狼群中各游猎狼在游走阶段搜寻到相对群体的最大值,而是事先已经明确给出的判定值c
lead
,因此,在初始化后不一定马上产生首领狼,在搜捕过程中也不一定会出现首领狼,并且根据气味浓度因子c的大小,判断气味浓度因子集c中最大的那匹狼是否大于等于c
lead
,若满足此条件,则转变为首领狼,所在位置记为p
best
,发起召唤,其他游猎狼开始奔袭行为,聚集后对猎物目标即首领狼所在位置展开围捕。首领狼在猎捕活动中,同样无需执行游猎、奔袭和围捕三种智能行为,仅仅可以触发召唤功能而成为狼群猎捕活动的标志。而首领狼也不是固定不变的,在狼群迭代过程中,每次进化中具有最优气味浓度因子的狼都会与当前首领狼的c
lead
比较,若此狼的气味浓度因子c更优,则该狼将当前首领狼取而代之。
[0112]
但需要指出现有wpa算法存在的缺陷是,在狼群越靠近首领狼附近时,其他游猎狼越容易感知到更优的气味浓度因子c,从而转变首领狼,可能出现首领狼在几匹游猎狼间反复变换的无序情况,导致wpa算法运行出错,为了解决由于位置突变造成的无序问题,做出以下规定:
[0113]
规定狼群在每次的围捕过程中,一匹狼仅有一次转变为首领狼的机会,即在一次围捕中一个机器人仅能发出一次召唤行为;
[0114]
设立历史首领狼集h,过去成为过首领狼的狼序号将计入历史首领狼h中,第i匹狼成为首领狼的前提条件是i不属于历史首领狼h;
[0115]
浓度判定因子c
lead
也在每次的召唤行为后进行变化,即狼群中每一次发起的召唤行为后,新的最优解是原先c
lead
的1.5倍,再次发起召唤行为的条件将更苛刻,这样可以在运行过程中大大减少算法的无序性,也能保证最优解的质量,约束条件的表达式为:
[0116][0117]
其中,c
lead
为浓度判定因子。
[0118]
根据上述步骤,进行一系列仿真实验,操作系统为64位windows 10,ram为4.00gb,matlab版本号为matlab-2019a。
[0119]
实验1为rowpa优化算法与现有的wpa算法性能对比试验:
[0120]
wine(红酒)数据集是matlab中经典的分类测试数据集,其样本总数为178,其中每一个样本有13种数值属性,这些样本被随机分为3类,其中一类为待测集,另外两类为测试集,一类中的数量都不相同,接下来将以wine数据集为实验数据对象,完成rowpa优化算法和wpa算法的对比仿真实验,以分析rowpa优化算法的性能。
[0121]
本实验采用的是支持向量机(support vector machines,svm)算法,狼群算法在其中的作用就是在svm训练模型中,对惩罚参数c和核函数中参数g进行优化,选取二者的最优值,以助其对wine数据集的样本精准无误地完成分类,在相同分类条件下,将现有的wpa算法思想和本发明提出的rowpa优化算法分别对其进行惩罚参数c和核函数中参数g的寻优,运行matlab代码,得到的实验结果,如图5所示,从图中可知分类结果准确率达100%,证明对于wine数据集的二分类问题上,rowpa优化算法保持与wpa算法一样的高寻优精度。
[0122]
观察具体的参数寻优实现过程,实曲线代表的是rowpa优化算法,而虚曲线代表的
是wpa算法,由图6和图7的实验结果,得出下列结论:
[0123]
(1)从收敛速度方面看,在惩罚参数c和核函数中参数g的寻优过程中,rowpa优化算法明显都快于wpa算法,且在相同的5次迭代周期下,rowpa优化算法能更快速地搜索到全局最优值附近,拥有更好的启发性,同时从对参数g的寻优过程可看出,rowpa优化算法比现有的狼群算法在避免陷入局部最优解的陷阱上具备更强的能力。
[0124]
(2)从收敛精度方面看,rowpa优化算法和现有的wpa算法最终都能收敛到最优值,证明rowpa优化算法在收敛精度上与wpa算法保持一致的高水准;且收敛情况也较为稳定,说明rowpa优化算法也拥有较明显的全局寻优特性。
[0125]
实验2为rowpa优化算法对mcst问题的仿真求解:
[0126]
如图8所示,mcst问题的求解效果是狼群高效且无冲突地围捕环境中的目标。在游猎狼与目标(即首领狼)的距离小于最大围捕半径后,游猎狼停止继续向目标靠近,意味本次围捕成功,根据前文理论优化和仿真工作,接下来在matlab平台上将其理论知识最终应用到根据狼群捕食行为产生的mcst问题上,验证其合理性和有效性,并对结果进行分析。
[0127]
由图9到图12的实验结果,得出下列结论:
[0128]
(1)采用rowpa优化算法和围捕策略编写的代码能有效求解mcst问题,给出的四次围捕活动中,狼群与目标点位置都比较分散,尽量让狼群的搜索过程覆盖了大部分解空间,且均得到了成功求解,这首先证明本发明对mcst问题的求解具有说服力,具备很强的应用能力,另外,对于50
×
50的二维空间环境,面对可能存在较大的搜索量,每次围捕活动所花费的时间依次为2.46、2.43、2.57和2.47秒,基本保持在2.5秒左右,这证明rowpa优化算法的搜索效率是高效且稳定的,同时也说明rowpa优化算法具备较强的收敛能力。
[0129]
(2)游猎狼向目标(即首领狼)奔袭的方向和过程具有很强的目的性和启发性,从游猎狼的奔袭路径来看,其循迹在没有障碍物的情况下,向目标点的移动保持的是倾向性的直线,这是rowpa优化算法全局寻优能力的明显体现,也证明了wpa算法和a*算法都具备的启发性在rowpa优化算法得到了优良传承。
[0130]
(3)rowpa优化算法的转角优化功能得到了很好地体现,对比图11和图12,我们发现在转角处rowpa优化算法的奔袭轨迹表现出平滑的特性,且amend_count值的输出值依次为32、58、10和28,证明在每次路径寻优的转角处,转角优化函数均有效地发挥了作用。
[0131]
(4)在搜捕过程中实现了高效且无冲突围捕猎物的要求,四次实验均输出了“rowpa优化算法preyed successfully!”的返回值,事实上,进行多次反复实验,rowpa优化算法应用于三个无人智能体猎捕目标的mcst问题上围捕成功率可达100%,另外,观察无人智能体对目标猎物整个的围捕路径,并没有出现与障碍物相交叠的点出现,结合输出的搜寻时间,这证明达到了对围捕过程提出的高效且无冲突的要求。
[0132]
另外,在实验过程中,由于针对mcst问题,rowpa优化算法对首领狼产生规则进行改进,使首领狼的更换机制更为严苛,新的首领狼拥有的气味浓度因子必须相比当前首领狼有较大的差距,所以在多次实验中首领狼被替换的情况很少发生,求解过程基本能够一步到位,一定程度上提高了狼群算法的运行效率,这也使得搜捕过程中出现首领狼更换,多次奔袭的情况是偶发性的,为了证明rowpa优化算法的有效性,经过大量重复实验,得到具有二次奔袭情况的结果,如图13所示,这也证明多次奔袭情况对wpa算法具有一定的消极影响,而rowpa优化算法由于做出了相关规定解决了此问题,证明相比现有的wpa算法,具有更
高的目标搜索精度以及跳出局部最优解的能力,例如应用于多个无人机协作围捕过程中,能够使得无人机集群路径寻优过程的效率更快、稳定性更强、寻优精度更高、跳出局部最优解的能力更强以及在围捕过程中能够避免出现碰撞和信息共享的问题。
[0133]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的工作人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。