1.本发明涉及中医药人工智能技术领域,特别涉及一种基于网络爬虫和多模态特征的成分-靶点相互作用预测方法。
背景技术:
2.中医临床经验丰富、疗效显著,但对中药成分、治疗靶点的作用机制仍知之甚少,给临床精准治疗带来了极大挑战。从微观机理解释中药药效物质基础成为中医现代化重点研究内容,因此,在理解中药的作用机制中识别成分-靶点对相互作用(ingredient-target interaction,iti)至关重要。中药具有多成分、多靶点等特性,很多潜在中药与靶点间的关系尚未明确,通过生物实验分别从中药的各个成分研究其作用靶点花费的时间成本、经济成本巨大且难以实现,因此研究成分-靶点相互作用预测方法是中医药现代化的紧迫问题。
3.随着公开的中医药分析数据库的出现,近年来出现的成分靶点数据库有 tcmsp、symmap、herb、etcm、tcmid等,这些资源为iti的预测提供了数据支持。近年来,基于化学基因组学结合计算机技术的方法可以快速低成本的识别潜在的iti,在目前的研究方法中,基于化学基因组学的方法又可以分为三类:基于网络扩散、基于矩阵分解和基于分类的方法。基于网络扩散的方法将成分和靶点看作节点,成分-靶点之间的关系看作边,同时增加成分-成分、靶点-靶点之间的相似性关系等构建网络,在网络上使用随机游走等网络传播方法预测未知的成分-靶点相互作用关系;基于矩阵分解的方法利用矩阵分解将成分
‑ꢀ
靶点关联矩阵分解为两个低秩矩阵,对应与成分和靶点的特征空间。
4.在基于分类的方法中一般先构造成分-靶点的特征,然后利用机器学习的方法预测成分-靶点相互作用关系。该方法特征的提取决定了预测结果的好坏,现阶段研究特征的选取多样,有的使用分子描述符、蛋白质描述符作为特征;有的计算成分-成分和靶点-靶点之间的相似性作为特征;有的构建异构网络并将节点的网络结构作为特征。虽成分-靶点相互作用去的一定进展,但仍然存在一下问题:1、现有数据收集不完整,未能综合考虑多个数据库;2、对于成分-靶点相互作用的分类预测为二分类问题,只有已标记的正样本和未标记的样本,现阶段的研究常在未标记的样本中随机选取与正样本等量的作为负样本,预测结果假阴性的风险高。3、目前基于分类的方法特征考虑不全、选取单一,从而限制了有效计算方法的发展。
技术实现要素:
5.本发明为解决现有成分-靶点相互作用预测方法数据不全和特征单一导致的技术局限,提供了一种基于网络爬虫和多模态特征的成分-靶点相互作用预测方法,该方法较现有的成分靶点预测方法而言,获取了较为完整的数据,极大程度挖掘了中药成分和靶点的潜在特征,减少了单一特征的风险,同时提供了可靠负样本集,具有较高的实用价值。为了解决上述问题,其技术方案如下:
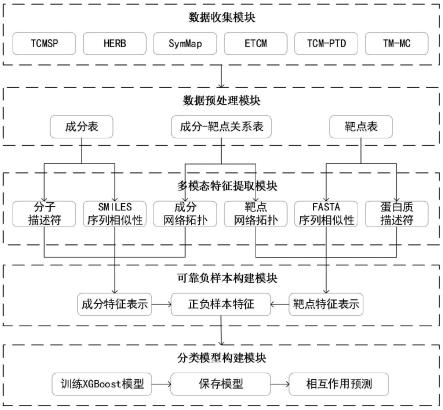
6.本发明的一种基于网络爬虫和多模态特征的成分-靶点相互作用预测方法,所述预测方法包括以下步骤:
7.s1,数据收集模块:利用网络爬虫自动获取中药的成分和靶点相关数据;
8.s2,数据预处理模块:融合成分和靶点相关数据,构建成分表、靶点表、成分-靶点关系表;
9.s3,多模态特征提取模块:分别将成分和靶点的描述符特征、序列相似性特征、网络拓扑特征进行跨模态融合,获取成分和靶点特征;
10.s4,可靠负样本构建模块:利用pu学习和已知的成分-靶点相互作用关系构建可靠负样本集;
11.s5,分类模型构建模块:成分-靶点特征结合正负样本集训练二分类模型。
12.进一步地,在步骤s1所述的数据收集模块中,利用网络爬虫技术从多个中药化学成分数据库和药物化学数据库自动获取成分和靶点的描述符、序列及相互作用数据。
13.进一步地,在步骤s2所述的数据预处理模块中,针对不同数据库中出现的中药成分、靶点、相互作用关系以及相应的描述符信息,制定相应的融合规则,构建成分表、靶点表、成分-靶点表。
14.进一步地,步骤s3所述的多模态特征提取模块还包括:
15.s31,根据成分的药理学和分子特性数据,计算成分的分子描述符特征;根据靶点的二肽组成、伪氨基酸组成、自相关性计算靶点的蛋白质描述符特征;
16.s32,利用jaccard相似性系数计算成分的smiles序列相似性特征,利用 smith
–
waterman分数计算靶点的fasta序列相似性特征;
17.s33,由已知的成分-靶点相互作用关系构建异构网络,运用node2vec网络嵌入算法提取成分和靶点的网络拓扑特征;
18.s34,分别对成分和靶点的描述符特征、序列相似性特征以及网络拓扑特征拼接后采用主成分分析法进行前端跨模态特征融合。
19.进一步地,步骤s31中,成分的药理学和分子特性数据包括分子量、脂水分布系数、氢键的供体、氢键的受体、口服生物利用度、肠上皮渗透性、血脑屏障、类药性、负表面积、化合物极性、化合物中可旋转键的个数以及药物半衰期,将上述12种数据经过归一化后作为分子描述符特征
20.步骤s31中,靶点的蛋白质描述符特征包括二肽与预期平均值的偏差(dde),伪氨基酸组成(paac)、自相关性(moran)、间隔氨基酸对的组成(cksaap)和分组的三肽组合物(gtpc)等五种特征类,拼接后通过主成分分析降维至d维,将其作为靶点描述符特征向量
21.进一步地,步骤s32中,成分的smiles序列相似性特征的计算公式为:
[0022][0023]
式中,ci和cj为根据每种成分的smiles序列计算得到的成分摩根分子指纹向量,|ci∩cj|表示成分ci和cj之间的最大公共子图中原子的数量,|ci∪cj|表示ci和cj数量之和减去ci和cj之间的最大公共子图中原子的数量,即ci和cj的并集,计算出ci与所有成分的相似
性并通过主成分分析法降至d维,令其为成分相似性向量
[0024]
步骤s32中,靶点的fasta序列相似性特征的计算公式为:
[0025][0026]
式中,sw(ti,tj)表示原始两个靶点的smith-waterman分数,计算出tj与所有靶点的相似性并通过主成分分析法降至d维,令其为靶点相似性向量
[0027]
进一步地,步骤s33中,成分和靶点的网络拓扑特征计算方法包括:采用 node2vec方法生成每个成分和靶点节点的d维特征向量和具体如下:
[0028]
s331,已知iti矩阵y,nc表示成分的总数,n
t
表示靶点的总数,y(i,j)表示第i个成分和第j个靶点之间的相互作用关系,y(i,j)=1表示第 i个成分和第j个靶点之间存在相互作用关系,否则y(i,j)=0;
[0029]
s332,根据矩阵y构建无向无权值的图g=(v,e),v表示节点集合,|v|表示节点的数量,e表示边的集合,|e|表示边的数量;当 y(i,j)=1时,表示存在e
ij
使得vi与vj相连;
[0030]
s333,在图g上进行随机游走,以节点c0=u为例,对节点c0的邻域进行随机游走采样,假设当前由节点t游走至节点v,则游走至下一节点x的概率计算公式如下:
[0031][0032]
其中,z为归一化常数,π
vx
=α
pq
(t,x)为节点v和节点x的未归一化转移概率,α
pq
(t,x)的计算公式如下:
[0033][0034]
其中,d
tx
表示节点t到节点x的最短距离,因此通过参数p和q控制随机游走的偏好,生成节点u的随机游走序列
[0035]
s334,由随机游走获取每个节点的序列后,学习目标为使用低维向量表示节点u,并最大化序列ns(u)中邻居节点出现的概率,优化函数如下:
[0036][0037]
其中f(u)为最终的节点嵌入表示,以该方法对每个节点进行训练得到d维特征向量和
[0038]
进一步地,在步骤s4所述的可靠负样本构建模块中,利用已知的成分-靶点相互作用关系随机选择部分数据作为间谍样本,使用随机森林生成所有样本的预测概率并排序,将概率低于间谍样本的作为可靠负样本集。
[0039]
进一步地,在步骤s5所述的分类模型构建模块中,将s3得到的成分和靶点特征向量,根据正负样本集的组合情况进行拼接,得到成分-靶点特征向量,并使用极端梯度提升分类器训练二分类模型,训练完的模型可用于成分-靶点相互作用预测。
[0040]
本发明提供的基于网络爬虫和多模态特征的成分-靶点相互作用预测方法,有益效果在于:
[0041]
一、本发明提供的预测方法,通过网络爬虫收集了多个中药化学成分数据库和药物化学数据库的数据,并融合了成分表、靶点表及其它们的关系表,确保数据的完整性。
[0042]
二、单一的特征可能会存在特征缺失或表征能力不足的问题,本发明基于描述符特征、序列相似性特征、网络拓扑特征的多模态特征融合方法能有效的解决该问题。
[0043]
三、在成分-靶点相互作用预测问题中,仅存在具有相互作用的正样本和未知样本,没有经过实验验证过的负样本,现有方法通常随机选择与正样本等量的未知样本作为负样本,假阳性风险高,本发明基于pu学习的技术能从未知样本中筛选出可靠负样本。
附图说明
[0044]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0045]
图1是本发明的基于网络爬虫和多模态特征的成分-靶点相互作用预测方法的流程示意图;
[0046]
图2是本发明的基于网络爬虫和多模态特征的成分-靶点相互作用预测方法可靠负样本模块中,以pu学习的间谍技术为例,获取可靠负样本的流程示意图。其中u表示未知样本集,p表示正样本集,s表示间谍样本集,rf为随机森林分类模型,n表示可靠负样本集。
具体实施方式
[0047]
为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式作进一步的说明。
[0048]
在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
[0049]
请参考图1和图2,本实施例的一种基于网络爬虫和多模态特征的成分-靶点相互作用预测方法,该预测方法包括以下步骤:
[0050]
s1,数据收集模块:利用网络爬虫自动获取中药的成分和靶点相关数据;
[0051]
s2,数据预处理模块:融合成分和靶点相关数据,构建成分表、靶点表、成分-靶点关系表;
[0052]
s3,多模态特征提取模块:分别将成分和靶点的描述符特征、序列相似性特征、网络拓扑特征进行跨模态融合,获取成分和靶点特征;
[0053]
s4,可靠负样本构建模块:利用pu学习和已知的成分-靶点相互作用关系构建可靠
负样本集;
[0054]
s5,分类模型构建模块:成分-靶点特征结合正负样本集训练二分类模型。
[0055]
作为优选的实施方式,在步骤s1所述的数据收集模块中,利用网络爬虫技术从多个中药化学成分数据库和药物化学数据库自动获取成分和靶点的描述符、序列及相互作用数据。
[0056]
其中,网络爬虫具有速度快、效率高的特点,可以高效的完成复杂网页结构的结构化数据提取,由于各数据库的网站结构不同,因此在数据获取前,需要对于网页的结构深入分析,找到相应的数据文件。
[0057]
爬取的相关数据库及其数量统计如表1所示,查询选取表中数据的url,将数据id编码拼接加入url中或通过抓包分析找到数据传递的接口,利用 requests库文件向服务器发起请求,获取相应的html或json数据文件,利用 xpath、selector、正则表达式等解析数据文件提取网页中希望获取的特定数据,最终通过多次请求和url迭代获得所有的数据。例如tcmsp数据库的成分表需要提取的字段包括成分名、分子量、脂水分布系数、氢键的供体、受体等17个字段的数据,分析该数据库中的成分url规律,获取每个成分的url,通过网络爬虫获取和解析相应的网页及字段,再传入新的url进行下一轮的数据爬取,直至爬取所有成分数据为止。
[0058]
表1相关数据库
[0059][0060]
优选地,在步骤s2所述的数据预处理模块中,针对不同数据库中出现的中药成分、靶点、相互作用关系以及相应的描述符信息,制定相应的融合规则,构建成分表、靶点表、成分-靶点表。
[0061]
其中,通过网络爬虫获取数据库的数据后,融合成分和靶点相关数据,构建成分表、靶点表、成分-靶点关系表。将爬取的数据按不同的数据库和数据库表分开存储,由于不同的数据库包含的字段和关系数据有所差异,需制定规则对各数据库的数据进行融合,以确保数据的完整性。以tcmsp和herb成分表融合为例,经两个数据库的成分表字段分析,当两个数据库中的成分数据满足成分名相同(不区分大小写)、pubchem_id相同、tcmsp_id相同、cas_id相同四个条件的其中一个即可确定为同一个成分,同时有的字段名不同但表示的是同一种数据,这就需要人工识别处理。筛除一些实验用不到的id字段后数据库的所有字段在融合过程中取并集,表2为融合后成分表、靶点表及成分-靶点关系字段。
[0062]
表2字段设置
[0063][0064]
优选地,步骤s3所述的多模态特征提取模块还包括:
[0065]
s31,根据成分的药理学和分子特性数据,计算成分的分子描述符特征;根据靶点的二肽组成、伪氨基酸组成、自相关性计算靶点的蛋白质描述符特征;
[0066]
s32,利用jaccard相似性系数计算成分的smiles序列相似性特征,利用 smith
–
waterman分数计算靶点的fasta序列相似性特征;
[0067]
s33,由已知的成分-靶点相互作用关系构建异构网络,运用node2vec网络嵌入算法提取成分和靶点的网络拓扑特征;
[0068]
s34,分别对成分和靶点的描述符特征、序列相似性特征以及网络拓扑特征拼接后采用主成分分析法进行前端跨模态特征融合。
[0069]
优选地,步骤s31中,成分的药理学和分子特性数据包括分子量、脂水分布系数、氢键的供体、氢键的受体、口服生物利用度、肠上皮渗透性、血脑屏障、类药性、负表面积、化合物极性、化合物中可旋转键的个数以及药物半衰期,将上述12种数据经过归一化后作为分子描述符特征
[0070]
步骤s31中,使用ifeature工具提取序列蛋白质描述符特征,该工具常用于靶点、rna和dna序列的特征工程分析及建模,能够利用fasta序列中从多方面表达蛋白质的性质,将提取二肽与预期平均值的偏差(dde),伪氨基酸组成 (paac)、自相关性(moran)、间隔氨基酸对的组成(cksaap)和分组的三肽组合物(gtpc)五种特征类,拼接后通过主成分分析降维至d维,令其为靶点描述符特征向量
[0071]
优选地,步骤s32中,成分的smiles序列相似性特征的计算公式为:
[0072][0073]
式中,ci和cj为根据每种成分的smiles序列计算得到的成分摩根分子指纹向量,|ci∩cj|表示成分ci和cj之间的最大公共子图中原子的数量,|ci∪cj|表示ci和cj数量之和减去ci和cj之间的最大公共子图中原子的数量,即ci和cj的并集,计算出ci与所有成分的相似性并通过主成分分析法降至d维,令其为成分相似性向量
[0074]
步骤s32中,靶点的fasta序列相似性特征的计算公式为:
[0075][0076]
式中,sw(ti,tj)表示原始两个靶点的smith
–
waterman分数,计算出tj与所有靶点
的相似性并通过主成分分析法降至d维,令其为靶点相似性向量
[0077]
优选地,步骤s33中,成分和靶点的网络拓扑特征计算方法包括:采用node2vec方法生成每个成分和靶点节点的d维特征向量和具体如下:
[0078]
s331,已知iti矩阵y,nc表示成分的总数,n
t
表示靶点的总数,y(i,j)表示第i个成分和第j个靶点之间的相互作用关系,y(i,j)=1表示第 i个成分和第j个靶点之间存在相互作用关系,否则y(i,j)=0;
[0079]
s332,根据矩阵y构建无向无权值的图g=(v,e),v表示节点集合,|v|表示节点的数量,e表示边的集合,|e|表示边的数量;当 y(i,j)=1时,表示存在e
ij
使得vi与vj相连;
[0080]
s333,在图g上进行随机游走,以节点c0=u为例,对节点c0的邻域进行随机游走采样,假设当前由节点t游走至节点v,则游走至下一节点x的概率计算公式如下:
[0081][0082]
其中,z为归一化常数,π
vx
=α
pq
(t,x)为节点v和节点x的未归一化转移概率,α
pq
(t,x)的计算公式如下:
[0083][0084]
其中,d
tx
表示节点t到节点x的最短距离,因此通过参数p和q控制随机游走的偏好,生成节点u的随机游走序列
[0085]
s334,由随机游走获取每个节点的序列后,学习目标为使用低维向量表示节点u,并最大化序列ns(u)中邻居节点出现的概率,优化函数如下:
[0086][0087]
其中f(u)为最终的节点嵌入表示,以该方法对每个节点进行训练得到d维特征向量和
[0088]
优选地,步骤s34中,分别对成分和靶点的描述符特征、序列相似性特征及网络拓扑特征进行横向拼接前端跨模态特征融合。将成分相关特征进行组合得到将靶点相关特征进行组合得到
[0089]
优选地,在步骤s4所述的可靠负样本构建模块中,利用已知的成分-靶点相互作用关系随机选择部分数据作为间谍样本,使用随机森林生成所有样本的预测概率并排序,将概率低于间谍样本的作为可靠负样本集。由于在成分-靶点相互作用预测中没有经过试验验证的负样本,大多数人随机选择一部分未知关系的样本作为负样本,具有较高的假阳性风险,因此本发明采用pu学习中的间谍技术筛选潜在的成分-靶点负样本构建可靠负样本集;
[0090]
当成分-靶点邻接矩阵y中的y
ij
=1时,将ci与tj视为中药成分-靶点对正例样本,当y
ij
=0时,则将其视为未知样本,并构建正样本集p和未知样本集u。为了从未知样本集u中选取可靠的负样本,将采用间谍技术构造可靠负样本集n,首先从p中随机选取15%的正样本作为集合s,放入集合u中作为间谍样本(spy),此时正样本集和未知样本集变成了p-s和u s;其次将p-s和u s利用随机森林算法进行分类,训练出一个分类器,并给出所有样本的预测概率;最后以spy 样本中预测的最小值作为阈值,u中所有低于这个阈值的样本认为是可靠负样本,将其y
ij
改为-1,最终得到可靠负样本集n。由正样本集p和可靠负样本集n 得到成分-靶点的特征向量β
ij
=[ci,tj]。
[0091]
优选地,在步骤s5所述的分类模型构建模块中,将s3得到的成分和靶点特征向量,根据正负样本集的组合情况进行拼接,得到成分-靶点特征向量,并使用极端梯度提升分类器训练二分类模型,训练完的模型可用于成分-靶点相互作用预测。本发明中采用的是集成学习算法极端梯度提升(extreme gradient boosting,xgboost)模型,xgboost的基学习器采用cart决策树,应用了k个树并行构成集成树模型,优化目标函数由损失函数和正则化项组成,如下公式所示:
[0092][0093]
其中k为树的数量,t为叶子的数量,w为节点的数值,从树的根节点开始,该模型采用贪心算法计算β
ij
的收益,根据每个样本特征向量β
ij
将训练集数据进行排序,并选择收益最大的β
ij
作为分裂特征映射至相应的叶子节点,采用递归的方式生成叶子节点构建决策树,然后由优化目标函数计算得到决策树叶子节点的权值,每棵树不断的拟合上一棵树预测的残差并赋予每棵树不同权重,训练完后,所有树的预测分数之和为节点ci与tj具有相互作用的概率;
[0094]
采用十折交叉法及roc曲线下面积(area under the roc curve,auc)值评估模型,保存效果最好的模型model_best,将所需预测数据的成分-靶点信息输入模型中,判断成分和靶点是否存在相互作用关系。
[0095]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其它实施例的不同之处。
[0096]
以上结合附图对本发明的实施方式作出详细说明,但本发明不局限于所描述的实施方式。对本领域的技术人员而言,在不脱离本发明的原理和精神的情况下对这些实施例进行的多种变化、修改、替换和变型均仍落入在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。