1.本技术涉及计算机视觉领域,尤其涉及一种图像分类模型构建方法、图像分类方法及装置、电子设备。
背景技术:
2.图像分类,即给定输入图像和分类标签集合,利用计算机算法把分类标签集合中的一个标签分配给输入图像,是计算机视觉领域的基础任务之一,在包括如智慧医疗、智能农业、自动驾驶等众多领域都有广泛应用。
3.深度神经网络的快速发展使得图像分类模型的性能得以大幅度提升。现有的神经网络系统大多建立在独立同分布的假设基础上,即假设训练数据(源域数据)和测试数据(目标域数据)具有相同的统计学分布。然而在实际应用场景中,这一假设往往由于各种因素而难以成立,导致训练良好的模型在具有不同分布的测试数据上,出现大幅度的性能下降。而域泛化图像分类方法可以有效解决以上问题。
4.现有的域泛化图像分类方法主要可以分为两类。一类是基于数据操纵的方法,另一类是基于对齐的方法。前者旨在通过不同的图像变换对源域数据进行增强,或者生成新的源域数据来模拟目标域数据,其缺点在于:一方面,数据增强是对输入图像进行简单的扩充、变换或者随机化,难以较为准确地模拟目标域数据,导致训练的模型泛化能力有限;另一方面,数据生成模型在面对特定任务时往往需要特定的参数,这导致其不具备泛化能力,且生成的伪源域样本需要特定的约束来确保语义的一致性。后者则致力于在特定空间中减小多个源域之间的表征差异,并为目标域学习域不变的潜在表示。但这种方式会混淆域特有信息和域不变信息,从而出现负迁移,导致模型在目标域上的分类准确率降低。
技术实现要素:
5.本技术实施例的目的是提供一种图像分类模型构建方法、图像分类方法及装置、电子设备,通过使用多个特定源域学习的多个学生模型进行知识蒸馏,相互传递包含丰富类间关系的特定域知识,并学习总结来自多个源域之间的域不变表示,进而提升模型在目标域数据上的分类精度,提升模型泛化能力。
6.根据本技术实施例的第一方面,提供一种图像分类模型构建方法,包括:
7.使用多个源域分别各自训练对应的辅助学生模型;
8.使用所述多个源域混合训练一个学生组长模型;
9.对多个所述辅助学生模型的预测输出进行互相蒸馏,得到第一蒸馏损失;
10.根据所述第一蒸馏损失,更新多个所述辅助学生模型;
11.将更新后的多个所述辅助学生模型的预测输出蒸馏给所述学生组长模型,得到第二蒸馏损失;
12.根据所述第二蒸馏损失,更新所述学生组长模型,所述学生组长模型用于对待分类的图像进行分类。
13.进一步地,在使用多个源域分别各自训练对应的辅助学生模型之后,在对多个所述辅助学生模型的预测输出进行互相蒸馏之前,还包括:
14.将所有辅助学生模型的预测输出与真实标签进行比对,正确的预测输出被保留,错误的预测输出则被直接剔除。
15.进一步地,使用多个源域分别各自训练对应的辅助学生模型,包括:
16.按照相同的类别获取多个源域的图像数据;
17.调整所述多个源域图像的尺寸并编码,得到多个源域图像的编码矩阵;
18.将所述多个编码矩阵分别输入至多个预训练的辅助学生模型,得到多个预测输出;
19.根据所述预测输出和真实标签,计算分类损失;
20.根据所述分类损失,更新对应的辅助学生模型的参数。
21.进一步地,使用所述多个源域混合训练一个学生组长模型,包括:
22.按照类别获取多个源域随机混合的图像数据;
23.调整所述混合图像的尺寸并编码,获得混合图像的编码矩阵;
24.将所述编码矩阵输入至一个预训练的学生组长模型,得到预测输出;
25.根据所述预测输出和真实标签,计算分类损失;
26.根据所述分类损失,更新学生组长模型的参数。
27.进一步地,对多个所述辅助学生模型的预测输出进行互相蒸馏,得到第一蒸馏损失,包括:
28.按照顺序依次选取一个辅助学生模型的预测输出作为临时的教师分布;
29.将剩下所有的辅助学生模型的预测分布的均值作为学生分布;
30.根据所述教师分布和学生分布,利用对齐损失函数,依次计算相应的蒸馏损失;
31.将所述所有蒸馏损失之和作为第一蒸馏损失。
32.进一步地,将更新后的多个所述辅助学生模型的预测输出蒸馏给所述学生组长模型,得到第二蒸馏损失,包括:
33.将所述所有辅助学生模型的预测输出的均值作为教师分布;
34.将所述学生组长模型的预测输出作为学生分布;
35.根据所述教师分布和学生分布,利用对齐损失函数计算第二蒸馏损失。
36.根据本发明实施例的第二方面,提供一种图像分类模型构建方法,包括:
37.第一训练模块,用于使用多个源域分别各自训练对应的辅助学生模型;
38.第二训练模块,用于使用所述多个源域混合训练一个学生组长模型;
39.第一蒸馏模块,用于对多个所述辅助学生模型的预测输出进行互相蒸馏,得到第一蒸馏损失;
40.第一更新模块,用于根据所述第一蒸馏损失,更新多个所述辅助学生模型;
41.第二蒸馏模块,用于将更新后的多个所述辅助学生模型的预测输出蒸馏给所述学生组长模型,得到第二蒸馏损失;
42.第二更新模块,用于根据所述第二蒸馏损失,更新所述学生组长模型,所述学生组长模型用于对待分类的图像进行分类。
43.根据本发明实施例的第三方面,提供一种图像分类方法,包括:
44.获取待分类的目标域图像;
45.将所述获取待分类的图像输入到第一方面所构建的更新后的学生组长模型中,得到预测输出概率;
46.将所述概率最大值所对应的类别设置为所述目标域图像的类别。
47.根据本发明实施例的第四方面,提供一种图像分类装置,包括:
48.获取模块,用于获取待分类的目标域图像;
49.预测输出模块,用于将所述获取待分类的图像输入到第一方面所构建的更新后的学生组长模型中,得到预测输出概率;
50.设置模块,用于将所述概率最大值所对应的类别设置为所述目标域图像的类别。
51.根据本发明实施例的第五方面,提供一种电子设备,包括:
52.一个或多个处理器;
53.存储器,用于存储一个或多个程序;
54.当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面、第三方面所述的方法。
55.本技术的实施例提供的技术方案可以包括以下有益效果:
56.(1)基于知识蒸馏及多学生网络的域泛化图像分类网络。通过多学生模型间的知识蒸馏充分利用多源域的互补信息,并学习域不变表征,进而提升多学生网络的泛化能力。
57.(2)二阶段知识蒸馏。采用两个阶段的知识蒸馏,第一阶段蒸馏通过辅助学生模型之间的知识交换提升模型的泛化能力,第二阶段知识蒸馏通过辅助学生模型集合与学生组长模型之间的知识交换,提升模型预测的稳定性。
58.应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
附图说明
59.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本技术的实施例,并与说明书一起用于解释本技术的原理。
60.图1是根据一示例性实施例示出的一种图像分类模型构建方法的流程图。
61.图2是根据一示例性实施例示出的步骤s11的流程图。
62.图3是根据一示例性实施例示出的步骤s12的流程图。
63.图4是根据一示例性实施例示出的步骤s13的流程图。
64.图5是根据一示例性实施例示出的步骤s15的流程图。
65.图6是根据一示例性实施例示出的另一种图像分类模型构建方法的流程图。
66.图7是根据一示例性实施例示出的域泛化图像分类网络结构示意图。
67.图8是根据一示例性实施例示出的步骤s17的流程图。
68.图9是根据一示例性实施例示出的辅助学生模型错误预测剔除流程示意图。
69.图10是根据一示例性实施例示出的一种图像分类模型构建装置的框图。
70.图11是根据一示例性实施例示出的另一种图像分类模型构建装置的框图。
71.图12是根据一示例性实施例示出的一种图像分类方法的流程图。
72.图13是根据一示例性实施例示出的一种图像分类装置的框图。
具体实施方式
73.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的装置和方法的例子。
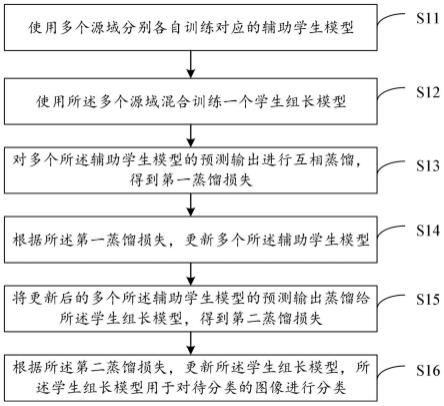
74.在本技术使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本技术。在本技术和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
75.应当理解,尽管在本技术可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本技术范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
76.实施例1:
77.图1是根据一示例性实施例示出的一种图像分类模型构建方法的流程图,如图1所示,该方法应用于终端中,可以包括以下步骤:
78.步骤s11,使用多个源域分别各自训练对应的辅助学生模型;
79.步骤s12,使用所述多个源域混合训练一个学生组长模型;
80.步骤s13,对多个所述辅助学生模型的预测输出进行互相蒸馏,得到第一蒸馏损失;
81.步骤s14,根据所述第一蒸馏损失,更新多个所述辅助学生模型;
82.步骤s15,将更新后的多个所述辅助学生模型的预测输出蒸馏给所述学生组长模型,得到第二蒸馏损失;
83.步骤s16,根据所述第二蒸馏损失,更新所述学生组长模型,所述学生组长模型用于对待分类的图像进行分类。
84.由以上技术方案可知,本技术通过多学生模型间的知识蒸馏充分利用多源域的互补信息,并学习域不变表征,进而提升多学生网络的泛化能力。采用两个阶段的知识蒸馏,第一阶段蒸馏通过辅助学生模型之间的知识交换提升模型的泛化能力,第二阶段知识蒸馏通过辅助学生模型集合与学生组长模型之间的知识交换,提升模型预测的稳定性。
85.在步骤s11的具体实施中,使用多个源域分别各自训练对应的辅助学生模型;参考图2,该步骤可以包括以下子步骤:
86.步骤s111,按照相同的类别获取多个源域的图像数据;
87.具体地,获取具有相同标签y的多个源域图像数据xs={x1,x2,...,xn},采用相同标签的多源域图像能够确保后续知识蒸馏的有效性。
88.步骤s112,调整所述多个源域图像的尺寸并编码,得到多个源域图像的编码矩阵;
89.具体地,利用双线性差值算法将所有源域图像xs={x1,x2,...,xn}缩放成相同的尺寸,以符合预训练模型的输入规格;
90.将所述尺寸相同的源域图像xs={x1,x2,...,xn}中的所有像素值除以255,并利用
公式(1)对图像rgb三个通道的数值(val)进行归一化处理,得到源域图像的编码矩阵gs={g1,g2,...,gn},其中rgb三个通道的均值(mean)分别为0.485、0.456和0.406,标准偏差(std)分别为0.229、0.224和0.225。通过归一化处理,以防止神经网络模型在训练过程中发生梯度爆炸。
[0091][0092]
步骤s113,将所述多个编码矩阵分别输入至多个预训练的辅助学生模型,得到多个预测输出;
[0093]
具体地,多个预训练的辅助学生模型s={s1,s2,...,sn},每个辅助学生模型都包含一个共享的特征提取器f,和一个特有的分类器头ci,共享特征提取器能够减小对计算资源的需求,特有的分类器头则用于学习域特定的知识。其中f由一个将输出维度被改为d的预训练网络如alexnet、resnet 18、resnet 50等组成;每个分类器头ci都由一个全连接层(fully connected layer)和一个softmax激活函数组成。
[0094]
所述特征提取器f从所有图像编码矩阵中提取出其中表示第i个域中图像的编码矩阵gi通过f后提取出来的d维实数特征向量。
[0095]
所述每个分类器头ci中的全连接层都以特征提取器f的输出作为输入得到未归一化的预测概率li,然后使用公式(2)所示的softmax激活函数得到归一化的预测分布pi作为预测输出。
[0096][0097]
其中l
ij
为li第j个节点的输出值;c为输出的节点数,即为图像类别个数;t为蒸馏温度,是超参数,设置为3。较高的蒸馏温度t会平滑预测分布,使得预测分布蕴含更丰富的类间关系和语义信息。
[0098]
步骤s114,根据所述预测输出和真实标签,计算分类损失;
[0099]
具体地,根据所述的预测输出和真实标签的one-hot编码,使用公式(3)所示的交叉熵损失(cross entropy loss)计算每个辅助学生模型的分类损失用来评估辅助学生模型的预测值与真实值的差异程度。
[0100][0101]
其中当u为真实标签时,yu=1,反之yu=0;p
iu
是范围在0到1之间实数,表示图像属于类别u的概率。
[0102]
步骤s115,根据所述分类损失,更新对应的辅助学生模型参数。
[0103]
具体地,网络自动计算所述分类损失的梯度,并使用随机梯度下降(sgd)方法更新辅助学生模型的参数,进而提升辅助学生模型的分类准确率。
[0104]
在步骤s12的具体实施中,使用所述多个源域混合训练一个学生组长模型;参考图3,该步骤可以包括以下子步骤:
[0105]
步骤s121,按照类别获取多个源域随机混合的图像数据;
[0106]
具体地,将所述多个源域图像进行随机混合,按照步骤s111所述类别获得混合图像x
mix
,并假设x
mix
为第n 1个源域的图像数据,即x
n 1
。该多源域混合图像用于学生组长模型的训练,能够提升学生组长模型的跨域分类能力。
[0107]
步骤s122,调整所述混合图像的尺寸并编码,获得混合图像的编码矩阵;
[0108]
具体地,利用步骤s112所述的统一尺寸和归一化方法,得到混合图像的编码矩阵g
n 1
。
[0109]
步骤s123,将所述编码矩阵输入至一个预训练的学生组长模型s
n 1
,得到预测输出;
[0110]
具体地,学生组长模型包含一个与辅助学生模型共享的特征提取器f,和一个特有的分类器头c
n 1
。
[0111]
所述特征提取器f从混合图像编码矩阵g
n 1
中提取出维度为d的特征向量
[0112]
分类器头c
n 1
中的全连接层以特征提取器f的输出作为输入得到未归一化的预测概率l
n 1
,然后通过softmax激活函数得到归一化的预测分布p
n 1
作为学生组长的预测输出。
[0113]
步骤s124,根据所述预测输出和真实标签,计算分类损失;
[0114]
具体地,根据所述的预测输出和真实标签的one-hot编码,使用交叉熵损失计算学生组长模型的分类损失用来评估学生组长模型的预测值与真实值的差异程度。
[0115]
步骤s125,根据所述分类损失,更新学生组长模型参数。
[0116]
具体地,网络自动计算所述分类损失的梯度,并使用随机梯度下降(sgd)方法更新学生组长模型的参数,进而提升学生组长模型的分类准确率。
[0117]
在步骤s13的具体实施中,对多个所述辅助学生模型的预测输出进行互相蒸馏,得到第一蒸馏损失;参考图4,该步骤可以包括以下子步骤:
[0118]
步骤s131,按照顺序依次选取一个辅助学生模型的预测输出作为临时的教师分布;
[0119]
具体地,多学生网络中的n个辅助学生模型s={s1,s2,...,sn}的预测输出分别为p={p1,p2,
…
,pn}。
[0120]
选择第i个辅助学生模型si的预测输出pi作为临时的教师分布,用于特定域知识的传递。
[0121]
步骤s132,将剩下所有的辅助学生模型的预测分布的均值作为学生分布;
[0122]
具体地,把剩下所有辅助学生模型的预测分布均值作为学生分布,这种协作学习的方式聚合了来自不同辅助学生模型的梯度,可以更好地利用不同来源之间的互补性。
[0123]
步骤s133,根据所述教师分布和学生分布,利用对齐损失函数依次计算相应的蒸馏损失;
[0124]
具体地,采用如kl散度(kullback-leibler divergence)、mse损失(mse loss)等对齐损失函数计算一阶段知识蒸馏的损失,如公式(4)所示。将所述辅助学生模型的预测输出分布以协作学习的方式互相对齐,实现模型之间的知识传递,进而学习域不变表征,提升辅助学生模型的泛化能力。
[0125][0126]
其中为对齐损失函数。
[0127]
步骤s134,将所述所有蒸馏损失之和作为第一蒸馏损失。
[0128]
具体地,将所述所有辅助学生模型之间的蒸馏损失之和作为第一蒸馏损失,如公式(5)所示。
[0129][0130]
在步骤s14的具体实施中,根据所述第一蒸馏损失,更新多个所述辅助学生模型;
[0131]
具体地,网络自动计算所述第一蒸馏损失的梯度,并使用随机梯度下降(sgd)方法更新辅助学生模型的参数,进而指导下一步的训练朝正确的方向进行。
[0132]
在步骤s15的具体实施中,将更新后的多个所述辅助学生模型的预测输出蒸馏给所述学生组长模型,得到第二蒸馏损失;参考图5,该步骤可以包括以下子步骤:
[0133]
步骤s151,将所述所有辅助学生模型的预测输出的均值作为教师分布;
[0134]
具体地,将所述多个辅助学生模型的预测的均值作为教师分布,以均值的形式能更好地利用不同源域数据之间的互补性。
[0135]
步骤s152,将所述学生组长模型的预测输出作为学生分布;
[0136]
具体地,将所述学生组长模型的预测输出p
n 1
作为学生分布。
[0137]
步骤s153,根据所述教师分布和学生分布,利用对齐损失函数计算第二蒸馏损失。
[0138]
具体地,采用步骤s133所述的对齐损失函数作为二阶段知识蒸馏的损失函数,将所述学生分布与教师分布进行对齐,实现知识传递,如公式(6)所示。由于n个辅助学生模型之间存在一定差异,随机选择一个辅助学生模型用于预测难以确保模型的鲁棒性,因此进行二阶段蒸馏,将学生组长模型作为最终预测模型,以确保模型分类结果的稳定性。
[0139][0140]
在步骤s16的具体实施中,根据所述第二蒸馏损失,更新所述学生组长模型。
[0141]
具体地,网络自动计算所述第二蒸馏损失的梯度,并使用随机梯度下降(sgd)方法更新学生组长模型的参数,进而指导下一步的训练朝正确的方向进行。
[0142]
参考图6和图7,还包括步骤s17,根据所述所有分类损失和蒸馏损失,加权计算域泛化总损失,并通过迭代上述模型参数,直至域泛化总损失达到预设的收敛条件。
[0143]
通过以上步骤s17迭代更新,使得模型分类更加准确,精度更高,将所述域泛化总损失收敛后的学生组长模型用于对待分类的图像进行分类,可获得更加准确,精度更高的分类结果。
[0144]
在步骤s17的具体实施中,根据所述所有分类损失和蒸馏损失,加权计算域泛化总损失,并通过迭代上述所有模型参数,直至域泛化总损失达到预设收敛条件;参考图8,该步
骤可以包括以下子步骤:
[0145]
步骤s171,将所述所有的分类损失和蒸馏损失的加权和作为域泛化总损失;
[0146]
具体地,将所述所有的分类损失和蒸馏损失的加权和作为域泛化总损失,如公式7所示
[0147][0148]
其中,α为超参数,用于平衡两种类型的损失对总损失的影响,这里设置为0.2。
[0149]
步骤s172,迭代上述所有模型参数,直至域泛化总损失达到预设收敛条件;
[0150]
具体地,对于其余的源域图像,重复执行步骤s11-s17,直至域泛化总损失达到预设收敛条件。
[0151]
将域泛化总损失收敛之后的学生组长模型用于对待分类的图像进行分类;具体地,将所述获取待分类的目标域图像输入到域泛化总损失收敛之后的学生组长模型中,得到预测输出概率,并将所述概率最大值所对应的类别设置为所述目标域图像的类别。
[0152]
本实施例中,优选地,参考图9,在使用多个源域分别各自训练对应的辅助学生模型之后,在对多个所述辅助学生模型的预测输出进行互相蒸馏之前,还包括:
[0153]
将所有辅助学生模型的预测输出与真实标签进行比对,正确的预测输出被保留,错误的预测输出则被直接剔除。在一阶段蒸馏过程中,将辅助学生模型的预测输出与真实标签进行比对,正确的预测被保留并执行传递,错误的预测则被直接剔除,以确保辅助学生模型之间知识传递的正确性和高效性。
[0154]
与前述的图像分类模型构建方法的实施例相对应,本技术还提供了图像分类模型构建装置的实施例。
[0155]
图10是根据一示例性实施例示出的一种图像分类模型构建装置框图。参照图10,该装置包括:第一训练模块11、第二训练模块12、第一蒸馏模块13、第一更新模块14、第二蒸馏模块15、第二更新模块16。
[0156]
第一训练模块11,用于使用多个源域分别各自训练对应的辅助学生模型;
[0157]
第二训练模块12,用于使用所述多个源域混合训练一个学生组长模型;
[0158]
第一蒸馏模块13,用于对多个所述辅助学生模型的预测输出进行互相蒸馏,得到第一蒸馏损失;
[0159]
第一更新模块14,用于根据所述第一蒸馏损失,更新多个所述辅助学生模型;
[0160]
第二蒸馏模块15,用于将更新后的多个所述辅助学生模型的预测输出蒸馏给所述学生组长模型,得到第二蒸馏损失;
[0161]
第二更新模块16,用于根据所述第二蒸馏损失,更新所述学生组长模型,所述学生组长模型用于对待分类的图像进行分类。
[0162]
参考图11,还包括迭代更新模块17,用于根据所述所有分类损失和蒸馏损失,加权计算域泛化总损失,并通过迭代上述模型参数,直至域泛化总损失达到预设的收敛条件。
[0163]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0164]
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件
说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本技术方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0165]
实施例2:
[0166]
图12是根据一示例性实施例示出的一种图像分类方法的流程图,如图12所示,该方法应用于终端中,可以包括以下步骤:
[0167]
步骤s21,获取待分类的目标域图像;
[0168]
步骤s22,将所述获取待分类的图像输入到实施例1所构建的学生组长模型中,得到预测输出概率;
[0169]
步骤s23,将所述概率最大值所对应的类别设置为所述目标域图像的类别。
[0170]
本发明使用域泛化图像分类中常用的pacs数据集对本发明的性能进行评估。该数据集中的图像包含art painting、cartoon、photo以及sketch四个域,每个域中所有图像都分成相同的7个类别。实验时,每次选择其中一个域作为无法访问的目标域,选择剩下的三个域作为源域,因此一共可以组成4个任务。本发明使用域泛化图像分类中常用的准确率作为评价指标,该指标可以从总体上衡量一个模型预测的性能。
[0171]
如下表所示,表中的art painting表示使用art painting域作为目标域,剩下的三个域作为源域的任务,其他3个表示方法与此相同,最后一列的avg表示模型在4个任务上的平均准确率。可以看到,本发明在pacs数据集的photo和sketch两个任务上均取得最高的准确率,且在4个任务的平均准确率也达到最高,相较于不使用域泛化的deepall的方法提升了5.58%。另外,在sketch任务上,本发明比其他最好的mixstyle方法提升了8.26%,sketch作为唯一的无颜色的域,更能说明本发明能够通过多学生模型的知识蒸馏学习域不变表征。总之,本发明通过基于知识蒸馏的多学生网络方案有效地解决了图像分类的域泛化问题,在域泛化图像分类的准确率上胜过现有方法。
[0172]
表1 pacs数据集上的域泛化图像分类实验结果
[0173][0174]
[0175]
与前述的图像分类方法的实施例相对应,本技术还提供了图像分类装置的实施例。
[0176]
图13是根据一示例性实施例示出的一种图像分类装置框图。参照图13,该装置包括:获取模块21、预测输出模块22、设置模块23。
[0177]
获取模块21,用于获取待分类的目标域图像;
[0178]
预测输出模块22,用于将所述获取待分类的图像输入到权利要求1-6任一项所构建的更新后的学生组长模型中,得到预测输出概率;
[0179]
设置模块23,用于将所述概率最大值所对应的类别设置为所述目标域图像的类别。
[0180]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0181]
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本技术方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0182]
相应的,本技术还提供一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述的图像分类模型构建方法、图像分类方法。
[0183]
相应的,本技术还提供一种计算机可读存储介质,其上存储有计算机指令,其特征在于,该指令被处理器执行时实现如上述的图像分类模型构建方法、图像分类方法。
[0184]
本领域技术人员在考虑说明书及实践这里公开的内容后,将容易想到本技术的其它实施方案。本技术旨在涵盖本技术的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本技术的一般性原理并包括本技术未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本技术的真正范围和精神由权利要求指出。
[0185]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本技术的范围仅由所附的权利要求来限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。