1.本发明属于社交网络探测领域,尤其涉及一种基于图论的分布式海量节点团体划分方法。
背景技术:
2.在社交网络探测领域,随着信息技术的发展,人们更倾向于线上的交流,这些交流的活动往往表现出团体特性,这便构成了网络上的社区,这些网络社区通联隐蔽、规模宏大、结构复杂。为了解决网络社区探测问题,人们提出了很多算法,例如随机块模型、聚类模型、基于图论度中心性的扩展模型、信息熵模型等,但这些模型往往在探测精度、运行效率、计算社区收敛性、评判划分准确度等方面存在缺陷。在面对海量复杂网络团体时,如何能快速精准划分出社区,是我们要解决的核心问题。
3.在复杂关系网络中,传统方式都是基于迭代外扩的方式进行全量切割,且对切割效果难以评判保证。
技术实现要素:
4.本发明所要解决的技术问题是针对目前该领域划分效率和精度的不足,提出一种基于图论的分布式海量节点团体划分方法,其保留对数加权关系权重和有限随机迭代的分布式切割,实现海量复杂网络的精准高效切割,最终利用小世界理论保证划分社区的聚类系数符合真实社交网络。
5.本发明为解决上述技术问题采用以下技术方案:
6.一种基于图论的分布式海量节点团体划分方法,保留对数加权关系权重和有限随机迭代gn的分布式切割,实现海量复杂网络的精准高效切割,利用ws小世界理论保证划分社区的聚类系数符合真实社交网络,具体包含如下步骤:
7.步骤1,随机抽样:将话单通联数据整理成带通联频次的无向关系数据;
8.步骤2,对数平滑:将通联频次直接作为边权重时,将边权重进行对数降级ln(ei),为避免取对数后为0的情况,对所有ln(ei) 0.1进行平滑处理;
9.步骤3,迭代去边:计算随机样本关系中每条边的加权中介中心性δ
st
(e),删除最大中介中心性的边;
10.步骤4,间隔抽样模块度;每删除m次边计算一次整个网络的模块度q,并保留当前网络探测结果;
11.步骤5,多核多进程分布式计算:迭代计算中介中心性后需要重新探测网布网络节点的最短路径;将最短路径封装为单独的方法,调用多核服务器的全部资源进行计算,并将全部节点作为任务分发到不同计算子机器进行分布式计算;在切割2/3边之后,选择最大模块度q对应的探测结果;
12.步骤6,ws小世界验证:探测后的每个子团体都需要符合真实世界社交结构,采用ws小世界聚类系数c来验证探测结果收敛性,。
13.作为本发明一种基于图论的分布式海量节点团体划分方法的进一步优选方案,所述步骤1具体如下:每次随机取m条边,计算边的中介中心性,每迭代删除m次边计算一次模块度,其中,k和m的取值与全部边数n有关,具体如下:
[0014][0015]
作为本发明一种基于图论的分布式海量节点团体划分方法的进一步优选方案,在步骤3中:计算随机样本关系中每条边的加权中介中心性δ
st
(e),具体计算如下:
[0016][0017]
其中,σ
st
(e)表示经过边e的s
→
t的最短路径条数,σ
st
表示s
→
t的最短路径条数。
[0018]
作为本发明一种基于图论的分布式海量节点团体划分方法的进一步优选方案,在步骤4中:模块度q的具体计算如下:
[0019][0020]
其中,e
ij
表示社区i和社区j之间的边的数量,ai=∑
ieij
,表示所有连接到社区i的边数量。
[0021]
作为本发明一种基于图论的分布式海量节点团体划分方法的进一步优选方案,所述步骤6具体如下:
[0022][0023]
其中,n为网络的节点数,ki为节点i与另外ki个节点相连,ei为这ki个节点之间的边数,当某子团体的聚类系数大于0.4时,则认为是符合真实结构的有效团体,对于聚类系数小于0.4的无效团体,则将该团体加入与该团体连接最多的有效团体中。
[0024]
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
[0025]
本发明通过对复杂网络关系的随机采样,结合加权对数gn算法进行切割,间隔计算模块度并分布式有限迭代,能在短时间内完成10万 量级节点关系的复杂网络切割,并对切割后的团体进行ws小世界验证,该方法能有效克服已存在方法的缺陷,能确保精准高效真实的社交网络探测。
附图说明
[0026]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0027]
图1展示的是含有5560个节点及23579条无向关系的复杂社区示意图;
[0028]
图2展示的是将通联关系数据进行对数加权并平滑处理示意图;
[0029]
图3展示的是在进行随机抽样的有限次迭代去边之后得到的社区子团体示意图;
[0030]
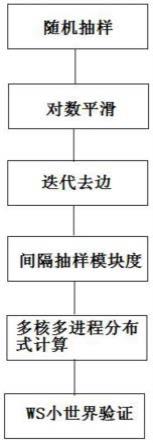
图4是本发明一种基于图论的分布式海量节点团体划分方法的方法流程图。
具体实施方式
[0031]
下面结合附图对本发明的技术方案做进一步的详细说明:
[0032]
如图1至4所示,下面结合附图,对本专利的具体实施方式做进一步的详细说明。对于所属技术领域的技术人员而言,从本专利的详细说明中,可知本专利的目的、特征和优点。
[0033]
图1展示的是含有5560个节点及23579条无向关系的复杂社区,每条关系代表这两个节点之间的在某段时间内的全部通联次数,同时设定抽样边数k=2358,计算q间隔m=20。
[0034]
如图2所示,我们取了对数后将权重进行了降量级,分布也更为平稳。针对取对数后
[0035]
可能为0的情况,我们对所有的ln(ei) 0.1,进行平滑处理。取对数ln是一个比较成熟降量级的操作,加0.1也是一种成熟的平滑操作,数据挖掘中是能直接理解的。
[0036]
图3展示的是在进行随机抽样的有限次迭代去边之后得到的社区子团体,并利用ws小世界聚类系数进行了验证补充。
[0037]
最终得到最好切割效果的模块度。共计得到完善后的94个子社区,经验证每个社区的通联关系都基本符合真实的社区关系。程序总计耗时约24分钟(在两台分布式机器资源下)。
[0038]
具体实施例如下:一种基于图论的分布式海量节点团体划分方法,如图4所示,具体包
[0039]
含如下步骤;步骤1,随机抽样:将话单通联数据整理成带通联频次的无向关系数据;具体如下:每次随机取m条边,计算边的中介中心性,每迭代删除m次边计算一次模块度,这是一个优化创新操作,相当于把全量操作变为了随机抽样操作,原理是在尽量保持原有效果的情况下,极大降低计算量。其中,k和m的取值与全部边数n有关,具体如下:
[0040][0041]
步骤2,对数平滑:将通联频次直接作为边权重时,频次较大的边影响肯定较大,但实际关系中只要频次超过一定值重要性是相差不大的,为优化边权重重要性,将边权重进行对数降级ln(ei),为避免取对数后为0的情况,对所有ln(ei) 0.1进行平滑处理;
[0042]
步骤3,迭代去边:计算随机样本关系中每条边的加权中介中心性δ
st
(e),删除最大中介中心性的边:
[0043][0044]
其中,σ
st
(e)表示经过边e的s
→
t的最短路径条数,σ
st
表示s
→
t的最短路径条数;
[0045]
步骤4,间隔抽样模块度;每删除m次边计算一次整个网络的模块度q,并保留当前网络探测结果;在海量边时,小间隔计算模块度基本不影响探测效果,但能极大降低计算时间复杂度:
[0046][0047]
其中,e
ij
表示社区i和社区j之间的边的数量,ai=∑
ieij
,表示所有连接到社区i的边数量。
[0048]
步骤5,多核多进程分布式计算:整个探测流程中最耗时的是每次迭代计算中介中心性后需要重新探测网布网络节点的最短路径;为充分利用集群计算机资源,提高计算效率,将最短路径封装为单独的方法,调用多核服务器的全部资源进行计算,并将全部节点作为任务分发到不同计算子机器进行分布式计算;把单机操作转为分布式操作(相当于应用创新),因为最短路径计算是整个模型最耗时的部分,通过优化这部分计算能极大降低模型计算的时间复杂度。在切割2/3边之后,选择最大模块度q的那一次探测结果,即为最佳社区探测结果。
[0049]
步骤6,ws小世界验证。探测后的每个子团体都需要符合真实世界社交结构,为了验证探测结果收敛性,采用ws小世界聚类系数c来验证:
[0050][0051]
其中,n为网络的节点数。ki为节点i与另外ki个节点相连。ei为这ki个节点之间的边数。当某子团体的聚类系数大于0.4时,就认为是符合真实结构的有效团体。对于聚类系数小于0.4的无效团体,将该团体加入与该团体连接最多的有效团体中。
[0052]
最后应说明的是:以上仅为发明的优选实施例而已,并不用于限制发明,尽管参照前述实施例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
