1.本发明属于电力系统分析领域,尤其涉及一种基于两阶段特征选择和格拉姆角场的拓扑辨识方法。
背景技术:
2.高比例分布式能源接入是未来配电网的基本形态。为应对分布式能源接入带来的不确定性,需要对配电网络进行实时、频繁的拓扑重构,以保证配电网安全可靠经济运行。配电网的拓扑信息是进行潮流计算、电压与无功优化、阻塞分析等工作的重要前提。频繁变化的拓扑对配电网的管理提出了严峻挑战,如何准确高效的辨识配电网拓扑已成为亟需解决的关键问题。
技术实现要素:
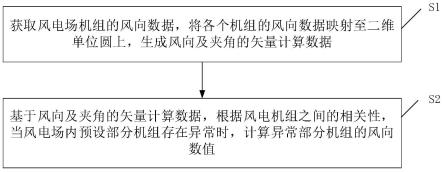
3.为了解决上述技术问题,本发明提供了一种基于两阶段特征选择和格拉姆角场的拓扑辨识方法,包括以下步骤:
4.s1、基于xgboost方法,计算所有候选节点量测的重要度;
5.s2、基于最大信息系数,判定所有不同节点量测之间的相关度;
6.s3、依据所有节点量测之间的相关度判断不同量测是否强相关,若两个候选量测强相关,则依据所有节点量测的重要度删除重要程度较低的量测;
7.s4、基于格拉姆角场特征变换,将一维的配电网时间断面量测数据变换为二维的格拉姆角场;
8.s5、根据三卷积层的神经网络模型,对格拉姆角场所蕴含的拓扑特征信息进行稳定提取,完成拓扑辨识。
9.进一步,所述步骤s1计算所有候选节点量测的重要度的步骤包括:
10.101、xgboost是由k棵决策树组成的加法集成模型:
[0011][0012]
其中,fk(xi)表示第i个样本xi在第k棵树所对应叶子节点的权重;xi∈rn,,表示k棵树组成的函数空间;表示样本xi的预测值;
[0013]
102、对于第k棵树而言,通过k个损失函数来衡量预测值与拓扑标签之间的差距,损失函数为:
[0014][0015]
其中,yi表示样本xi拓扑标签,表示样本xi的训练残差,ω表示惩罚项,反映模型复杂度;ns表示样本总数;
[0016]
103、xgboost的学习策略是采用贪心算法来寻找第k棵树式(5)的最优解,损失函
数需改写为:
[0017][0018]
其中,gi、hi分别是的一阶导数和二阶导数,t表示叶子节点个数,wj表示第j 个叶子节点的权重,γ表示惩罚项;xj表示叶子节点j的样本集合;
[0019]
104、确定第k棵树的结构,方法是从树的深度为0开始,每一节点都遍历所有的量测,最终选取信息增益最大的量测作为分裂量测,分裂叶子节点;信息增益的计算方式为:
[0020][0021]
其中,opt
l
、optr和opt
l r
分别表示叶子节点左子树、右子树、无分裂时式(6)的最优解,衡量叶子节点对总体损失的贡献,若g《0时,树停止分裂;
[0022]
105、遍历k棵树,将每个量测作为分裂量测时的得出的信息增益进行加和,作为该量测的重要程度。
[0023]
进一步,所述步骤s2中基于最大信息系数判定所有不同节点量测之间的相关度的步骤包括:
[0024]
201、设节点i、j的电压幅值为vi和vj,根据给定的网格栅,对vi和vj组成的二维空间进行划分,计算互信息值为:
[0025][0026]
其中,vi、vj分别是节点i,j所有时间断面量测值的集合,i
i,j,l
表示第l个网格栅下vi和vj的互信息值。p(vi)和p(vj)分别为vi和vj的边缘分布概率,p(vi,vj)是vi、vj的联合分布概率;
[0027]
202、将互信息值i
i,j,l
进行归一化处理为取值范围为[0,1]:
[0028][0029]
其中,a和b分别为vi、vj方向上的网格划分个数。ab《lm,lm为网格数上限,一般取 ns的0.6次方;
[0030]
203、改变网格栅,重新执行步骤1、2,取不同网格栅互信息值中的最大值作为最大信息系数mic:
[0031][0032]
其中,mic
i,j
衡量vi和vj的相关程度。当mic
i,j
>τ,认为vi和vj强相关,τ表示强相关阈值。
[0033]
进一步,所述步骤s3中判断不同量测是否强相关的步骤包括:
[0034]
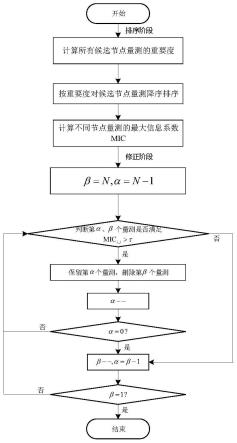
301、将量测按重要程度降序排序,将排序结果记为量测组合m;令β=n,α=n-1;
[0035]
302、对m进行修正;对于m中第α个量测和β个量测,α<β,若二者强相关,则删除第β个量测,保留第α个量测,α自减1;若α=0,β自减1,α=β-1;
[0036]
303、重复执行步骤2,直到β=1结束,即排序结果中不再存在冗余量测。
[0037]
进一步,所述步骤s4中格拉姆角场特征变换的步骤包括:
[0038]
401、对每个时间断面t的节点电压量测数据进行归一化:
[0039][0040]
其中,表示归一化后节点i的电压幅值,v
max
和v
min
分别是当前时间断面节点电压量测数据的最大值和最小值;
[0041]
402、极坐标变换,使用极坐标系表征归一化后节点电压幅值量测数据:
[0042][0043][0044]
其中,φi(t)和ri分别是在极坐标系下对应的角度值和半径值,φi(t)∈[0,π/2] i=1,2,...,n;
[0045]
403、对极坐标系下不同节点的电压幅值数据进行三角变换,从而构建格拉姆角场:
[0046][0047]
其中,是一种新的内积运算。若采用两角和的cos函数关系来计算不同节点的内积,此时的格拉姆场称为格拉姆角求和场:
[0048][0049]
若采用两角差的sin函数关系来计算不同节点的内积,此时的格拉姆角场称为格拉姆角差分场:
[0050][0051]
其中,φi(t) φj(t)∈[0,π],cos(φi(t) φj(t))∈[-1,1],φi(t)-φj(t)∈[-π/2,π/2], sin(φi(t)-φj(t))∈[-1,1];格拉姆角场是以主对角线元素为中轴、上三角元素与下三角元素互为对称的二维表示;若要同时包括格拉姆角求和场、格拉姆角差分场中所表征的拓扑特征信息,只需保留格拉姆角差分场的上三角元素和格拉姆角求和场的下三角元素;其中,格拉姆角场二维表示:
[0052][0053]
其中,主对角元素采用cos函数关系,以保留节点电压分布规律,此时i=j,和φi(t) 的值可以通过cos函数关系互相转换;上三角元素cos函数关系来表征相对关系,由于cos 值在[0,π]区间单调递减,表明不同节点的相对关系大小随φ值增大越减弱;下三角元素采用sin函数关系来表征相对关系,由于sin值在[-π/2,π/2]区间单调递增,表明不同节点的相对关系大小随φ值增大而增强。
[0054]
进一步,所述步骤s5拓扑辨识的三卷积层的神经网络模型提取格拉姆角场所蕴含的拓扑特征信息的步骤包括:
[0055]
501、输入到输出自上而下,输入是格拉姆角场;
[0056]
502、神经网络模型为3conv.32/relu表示卷积层,卷积核尺寸为3,个数为32,采用relu函数加速模型收敛,增强模型的稀疏表示;其中:
[0057]
卷积层后有池化层连接,maxpool和globalmaxpool表示池化层,3次卷积和池化操作有效弱化工程范围内的噪声数据的影响,并高度抽象了拓扑特征信息;
[0058]
fc.128/dropout表示在全连接层中,神经元个数为128个,采用dropout函数提升模型的泛化能力,fc.e/softmax表示采用softmax函数将拓扑辨识结果输出。
[0059]
与现有技术相比,本发明的有益效果是:
[0060]
绝大多数研究未能对时间断面的拓扑特征信息进行有效且充分挖掘,一般需要全部量测来保证方法的有效性与适应性。而目前,量测设备成本高昂,在配电网中配置不足。本发明仅需要部分节点电压幅值量测的时间断面数据,适用于分布式能源接入、辐射状拓扑和环网拓扑混合运行的配电网。
附图说明
[0061]
图1本发明中三卷积层拓扑辨识模型结构示意图。
[0062]
图2本发明基于两阶段特征选择和gaf-cnn的配电网拓扑辨识方法框架。
[0063]
图3是本发明提供基于xgboost和最大信息系数的两阶段特征选择方法流程图。
[0064]
图4改造的ieee33节点系统示意图。
[0065]
图5量测重要程度降序排序结果。
[0066]
图6不同量测之间的相关系数热图。
[0067]
图7gaf-cnn的f1值与强相关阈值τ的关系。
具体实施方式
[0068]
下面结合附图和具体实施算例对本发明技术方案作进一步详细描述。
[0069]
如图1-图3所示:本发明一种基于两阶段特征选择和格拉姆角场的拓扑辨识方法,详细说明如下:
[0070]
步骤一:
[0071]
采用改造的ieee33节点测试系统验证本发明所提方法的有效性与正确性,初始拓扑如图4所示,两台光伏和风机的接入位置分别为7、14和10、33。使用matpower软件仿真获得所有节点的电压量测数据。假设光伏和风机的出力曲线服从高斯分布,均值为每一时刻的实际出力,方差为实际出力的10%。假设负荷出力曲线也满足高斯分布,均值为每一时刻的实际出力,方差设为实际出力的5%,负荷功率因数服从均匀分布u(0.75,0.85)。假设风机能够维持机端电压恒定,将接入风机的节点设置为pv节点,将接入光伏的节点设置为 pq节点。借助python编程实现了相关算法,计算机的配置为:intel core i7-10875处理器, 32g内存。
[0072]
在系统正常运行下,以初始拓扑为基准,生成307种拓扑,包括213种辐射状结构和 94种环状结构,样本总数为240574。每个样本添加0.01%的零均值高斯噪声。数据缺失比率
设置为5%,使用k近邻法(k nearest neighbor,knn)填补缺失值。训练集、验证集、测试集占样本比例为8:1:1。采用xgboost计算量测的重要性,图5表示量测按重要程度降序排序结果
[0073]
步骤二:基于最大信息系数,计算33个量测之间的相关关系,图6是不同量测之间的相关系数热图。
[0074]
步骤三:图7表示gaf-cnn测试集的f1值与τ的关系。若采用全部特征进行训练,测试集的f1值为99.03%。当τ≥0.7时,f1值趋于稳定。当τ<0.7时,f1值则开始大幅下降。可见,当τ=0.7时所筛选的量测组合{v
25
,v
18
,v1,v
22
,v
14
,v
33
,v
10
,v7,v5,v
29
}已不含冗余拓扑特征信息,量测个数为10,测试集的f1值为97.16%。若未对量测组合进行修正,直接选用降序排序结果中前10的量测{v
25
,v
18
,v1,v
22
,v
14
,v
33
,v
10
,v
12
,v9,v7},测试集的f1值为 95.29%。其中,v
14
和v
12
、v
10
和v9强相关。
[0075]
步骤四:
[0076]
在未进行特征变换之前,cnn的f1值最高,为85.63%。dnn比cnn低4.85%,为 80.78%。svm的f1值比cnn低13.07%,为85.63%。在进行特征变换之后,gasf-cnn、gadf-cnn和gafi-cnn的f1值分别为94.64%、95.01、97.16%,相较于不采用特征变换的cnn,分别提升了9.01%、9.38%、11.53%。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。