1.本发明涉及表情识别技术,尤其涉及一种基于稀疏化自注意力机制的微表情识别方法及系统。
背景技术:
2.微表情是人类试图隐藏或抑制内心真实情绪时,不经意间露出的面部表情,不受人主观意识的控制。微表情是检测人类隐藏情绪时重要的非语言信号,通常能够有效揭示一个人的真实心理状态,被认为是识别谎言的关键线索,对更好地理解人类情感,有着重要作用。因此,微表情的有效运用,对社会生产生活有着重要作用。在刑侦方面,经过一定微表情识别能力训练的审讯员,可以更好地识别犯罪嫌疑人的谎言;在社会治安方面,通过观察微表情可以判断潜伏在日常生活中的危险分子,防恐防暴;在临床医疗方面,通过微表情,医生更好地了解患者的真实想法,例如隐藏病情等等,从而更加有效地与患者交流,更加准确地分析病情,改进治疗方案。但是,人工识别微表情培训成本较高,难以大规模推广。因此近年来,利用计算机视觉技术和人工智能方法,进行微表情识别地需求日益增加。
3.由于微表情涉及运动强度低的特性,传统的识别任务在特征提取之前会利用放大手段放大微表情的强度,如欧拉视频放大,拉格朗日放大等。这些方法在放大过程中容易引入噪声和斑点,对图像其他区域的恢复效果并不理想,近年来,深度网络的发展进入到图像,语音,自然语言处理等各个方面,基于学习的运动放大方法也逐渐增加,相比于传统的手工方法,深度学习的方法对图像的重建效果更好。
4.无论是传统的放大方式还是基于深度学习的放大方式,都面临这样一个问题:人与人之间的面部构造差异很大,表情与表情的呈现所涉及的肌肉运动也不尽相同,如果对于所有样本都应用统一的放大强度,很可能造成有的微表情放大不充分,有的放大程度过大导致脸部变形,这样获得的放大图像很大可能影响后续的识别结果,识别准确率有待提高。
技术实现要素:
5.发明目的:本发明针对现有技术存在的问题,提供一种识别准确率更高的基于稀疏化自注意力机制的微表情识别方法及系统。
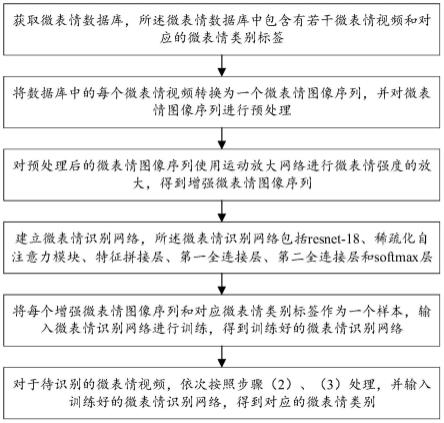
6.技术方案:本发明所述的基于稀疏化自注意力机制的微表情识别方法包括:
7.(1)获取微表情数据库,所述微表情数据库中包含有若干微表情视频和对应的微表情类别标签;
8.(2)将数据库中的每个微表情视频转换为一个微表情图像序列,并对微表情图像序列进行预处理;
9.(3)对预处理后的微表情图像序列使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列;
10.(4)建立微表情识别网络,所述微表情识别网络包括resnet-18、稀疏化自注意力
模块、特征拼接层、第一全连接层、第二全连接层和softmax层,其中,所述resnet-18用于从增强微表情图像序列中提取空间特征,所述稀疏化自注意力模块用于从空间特征中获取运动变化特征,所述特征拼接层用于将空间特征和运动变化特征拼接为综合特征后输入至第一全连接层,第一全连接层和第二全连接层用于依次将综合特征降维,所述softmax层用于根据降维后的综合特征进行识别分类,得到微表情类别;
11.(5)将每个增强微表情图像序列和对应微表情类别标签作为一个样本,输入微表情识别网络进行训练,得到训练好的微表情识别网络;
12.(6)对于待识别的微表情视频,依次按照步骤(2)、(3)处理,并输入训练好的微表情识别网络,得到对应的微表情类别。
13.进一步的,步骤(2)中所述预处理包括人脸配准和面部区域剪切。
14.进一步的,步骤(3)具体包括:
15.提取预处理后的微表情图像序列的起始帧i
onset
和峰值帧i
apex
,并根据起始帧i
onset
和峰值帧i
apex
使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列i
mag
:
16.i
mag
={i
mag,i
}
17.i
mag,i
=f(i
onset
(1 αi)|i
apex-i
onset
|)
18.i
mag,i
为预处理后微的表情图像序列中第i帧图像放大之后的图像,f(
·
)为运动放大网络,αi为第i帧图像的放大倍数,放大倍数按照微表情图像序列的排列顺序从前到后依次递增。
19.进一步的,所述稀疏化自注意力模块具体包括:
20.基本矩阵生成单元,用于根据空间特征f
t
采用下式计算自注意力矩阵的查询矩阵q、键矩阵k、值矩阵v:
21.q=f
t
×
wq22.k=f
t
×
wk23.v=f
t
×
wv24.式中,wq、wk、wv分别为对应的权重矩阵;
25.超平面生成单元,用于在空间中随机地生成n_rounds个超平面{h
(1)
,h
(2)
,
…
,h
(n_rounds)
},n_rounds为大于2的正整数;h
(*)
为第*个超平面;
26.特征哈希单元,用于基于超平面将空间分为2(n_rounds)个哈希桶,采用下式分别计算q、k中每一个特征向量所落入的哈希桶;
[0027][0028][0029][0030][0031]
式中,qu、kv表示q、k中第u、v个特征向量,length表示增强微表情图像序列的帧数,h(qu)、h(kv)表示qu、kv所落入的哈希桶的二进制标号,a
(j)
、b
(j)
表示h(qu)、h(kv)的第j个比特值;
[0032]
特征稀疏单元,用于只保留q、k中落入同一哈希桶的特征向量的索引号,存入稀疏后的特征索引集合ω
u,v
中:
[0033]
ω
u,v
={(u,v)|h(qu)=h(kv)},u,v=1,2,
…
,length
[0034]
稀疏注意力矩阵计算单元,用于根据特征索引集合ω
i,j
计算稀疏注意力矩阵attention(q,k,v):
[0035][0036]
式中,d
l
为q、k、v的维度,attention(q,k,v)即为运动变化特征。
[0037]
进一步的,步骤(5)中训练时采用的损失函数为:
[0038][0039]
式中,c为类别数,c=1,2,
…
,c,yc为微表情的类别标签,pc为属于类别c的概率。
[0040]
本发明所述的基于稀疏化自注意力机制的微表情识别系统包括:
[0041]
微表情数据库,包含有若干微表情视频和对应的微表情类别标签;
[0042]
预处理模块,用于将数据库中的每个微表情视频转换为一个微表情图像序列,并对微表情图像序列进行预处理;
[0043]
强度放大模块,用于对预处理后的微表情图像序列使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列;
[0044]
微表情识别网络建立模块,用于建立微表情识别网络,所述微表情识别网络包括resnet-18、稀疏化自注意力模块、特征拼接层、第一全连接层、第二全连接层和softmax层,其中,所述resnet-18用于从增强微表情图像序列中提取空间特征,所述稀疏化自注意力模块用于从空间特征中获取运动变化特征,所述特征拼接层用于将空间特征和运动变化特征拼接为综合特征后输入至第一全连接层,第一全连接层和第二全连接层用于依次将综合特征降维,所述softmax层用于根据降维后的综合特征进行识别分类,得到微表情类别;
[0045]
网络训练模块,用于将每个增强微表情图像序列和对应微表情类别标签作为一个样本,输入微表情识别网络进行训练,得到训练好的微表情识别网络;
[0046]
微表情识别模块,用于对于待识别的微表情视频,依次预处理和强度放大,并输入训练好的微表情识别网络,得到对应的微表情类别。
[0047]
进一步的,所述预处理模块具体用于将数据库中的每个微表情视频转换为一个微表情图像序列,并进行人脸配准和面部区域剪切。
[0048]
进一步的,所述强度放大模块具体用于提取预处理后的微表情图像序列的起始帧i
onset
和峰值帧i
apex
,并根据起始帧i
onset
和峰值帧i
apex
使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列i
mag
:
[0049]imag
={i
mag,i
}
[0050]imag,i
=f(i
onset
(1 αi)|i
apex-i
onset
|)
[0051]imag,i
为预处理后微的表情图像序列中第i帧图像放大之后的图像,f(
·
)为运动放大网络,ei为第i帧图像的放大倍数,放大倍数按照微表情图像序列的排列顺序从前到后依次递增。
[0052]
进一步的,所述稀疏化自注意力模块具体包括:
[0053]
基本矩阵生成单元,用于根据空间特征f
t
采用下式计算自注意力矩阵的查询矩阵q、键矩阵k、值矩阵v:
[0054]
q=f
t
×
wq[0055]
k=f
t
×
wk[0056]
v=f
t
×
wv[0057]
式中,wq、wk、wv分别为对应的权重矩阵;
[0058]
超平面生成单元,用于在空间中随机地生成n_rounds个超平面{h
(1)
,h
(2)
,
…
,h
(n_rounds)
},n_rounds为大于2的正整数;h
(*)
为第*个超平面;
[0059]
特征哈希单元,用于基于超平面将空间分为2
(n_rounds
)个哈希桶,采用下式分别计算q、k中每一个特征向量所落入的哈希桶;
[0060][0061][0062][0063][0064]
式中,qu、kv表示q、k中第u、v个特征向量,length表示增强微表情图像序列的帧数,h(qu)、h(kv)表示qu、kv所落入的哈希桶的二进制标号,a
(j)
、b
(j)
表示h(qu)、h(kv)的第j个比特值;
[0065]
特征稀疏单元,用于只保留q、k中落入同一哈希桶的特征向量的索引号,存入稀疏后的特征索引集合ω
u,v
中:
[0066]
ω
u,v
={(u,v)|h(qu)=h(kv)},u,v=1,2,
…
,length
[0067]
稀疏注意力矩阵计算单元,用于根据特征索引集合ω
i,j
计算稀疏注意力矩阵attention(q,k,v):
[0068][0069]
式中,d
l
为q、k、v的维度,attention(q,k,v)即为运动变化特征。
[0070]
进一步的,所述网络训练模块中训练时采用的损失函数为:
[0071][0072]
式中,c为类别数,c=1,2,
…
,c,yc为微表情的类别标签,pc为属于类别c的概率。
[0073]
有益效果:本发明与现有技术相比,其显著优点是:本发明识别准确率更高,且减少人为设定的超参数,更方便。
附图说明
[0074]
图1是本发明提供的基于稀疏化自注意力机制的微表情识别方法的一个实施例的
流程示意图;
[0075]
图2是微表情识别示意图;
[0076]
图3是注意力矩阵稀疏化过程的示意图;
[0077]
图4是一个局部敏感哈希算法划分超平面和分配哈希桶的示意图。
具体实施方式
[0078]
本实施例提供了一种基于稀疏化自注意力机制的微表情识别方法,如图1所示,包括如下步骤:
[0079]
(1)获取微表情数据库,所述微表情数据库中包含有若干微表情视频和对应的微表情类别标签。
[0080]
其中,数据库可以采用casme ii,samm,smic-hs这三个常用数据库。
[0081]
(2)将数据库中的每个微表情视频转换为一个微表情图像序列,并对微表情图像序列进行预处理。
[0082]
其中,所述预处理包括人脸配准和面部区域剪切。
[0083]
(3)对预处理后的微表情图像序列使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列。
[0084]
该步骤提取预处理后的微表情图像序列的起始帧i
onset
和峰值帧i
apex
,并根据起始帧i
onset
和峰值帧i
apex
使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列i
mag
:
[0085]imag
={i
mag,i
}
[0086]imag,i
=f(i
onset
(1 αi)|i
apex-i
onset
|)
[0087]imag,i
为预处理后微的表情图像序列中第i帧图像放大之后的图像,f(
·
)为运动放大网络,αi为第i帧图像的放大倍数,放大倍数按照微表情图像序列的排列顺序从前到后依次递增,这样得到的运动变化会更加明显,比如α1=1,α2=1.375,α3=1.75,
…
,α
32
=13,可以得到32张图像的增强微表情图像序列。
[0088]
(4)建立微表情识别网络,如图2所示,所述微表情识别网络包括resnet-18、稀疏化自注意力模块、特征拼接层、第一全连接层、第二全连接层和softmax层,其中,所述resnet-18用于从增强微表情图像序列中提取空间特征,所述稀疏化自注意力模块用于从空间特征中获取运动变化特征,所述特征拼接层用于将空间特征和运动变化特征拼接为综合特征后输入至第一全连接层,第一全连接层和第二全连接层用于依次将综合特征降维,所述softmax层用于根据降维后的综合特征进行识别分类,得到微表情类别。
[0089]
原始的自注意力机制中主要由三个特征矩阵起作用:q用来匹配其他的信息,k作为被匹配的键值,v用来计算最终获取的信息,注意力矩阵的获得可以表示如下:
[0090][0091]
其中为q,k,v三个特征向量的维度。
[0092]
但是本发明中由于个体差异所带来的放大程度无法统一的问题,对所有序列使用一致的放大程度不可避免会出现面部图像严重变形的情况,为了解决这一问题,本发明摒
弃传统的注意力机制算法,在注意力矩阵计算时引入稀疏化限制,采用稀疏化自注意力模块提取运动变化特征,将严重的变形视为噪声信息,如图3所示。稀疏化自注意力模块从空间特征f
t
中获取运动变化特征,具体包括:
[0093]
基本矩阵生成单元,用于根据空间特征f
t
采用下式计算自注意力矩阵的查询矩阵q、键矩阵k、值矩阵v:
[0094]
q=f
t
×
wq[0095]
k=f
t
×
wk[0096]
v=f
t
×
wv[0097]
式中,wq、wk、wv分别为对应的权重矩阵;
[0098]
超平面生成单元,用于在空间中随机地生成n_rounds个超平面{h
(1)
,h
(2)
,
…
,h
(n_rounds)
},n_rounds为大于2的正整数;h
(*)
为第*个超平面;例如,当n
rounds
=3,用python中自带的随机数生成函数,如np.random.randn(3,1024)表示生成三个大小为1
×
1024的向量;
[0099]
特征哈希单元,用于基于超平面将空间分为2
(n_rounds)
个哈希桶,如图4所示,采用下式分别计算q、k中每一个特征向量所落入的哈希桶;
[0100][0101][0102][0103][0104]
式中,qu、kv表示q、k中第u、v个特征向量,大小为1
×
1024,length表示增强微表情图像序列的帧数,h(qu)、h(kv)表示qu、kv所落入的哈希桶的二进制标号,a
(j)
、b
(j)
表示h(qu)、h(kv)的第j个比特值;例如,当n
rounds
=3,共有8个哈希桶,如果q
ut
h1>0,q
ut
h2<0,q
ut
h3>0,则h(qu)可以记为101;
[0105]
特征稀疏单元,用于只保留q、k中落入同一哈希桶的特征向量的索引号,存入稀疏后的特征索引集合ω
u,v
中:
[0106]
ω
u,v
={(u,v)|h(qu)=h(kv)},u,v=1,2,
…
,length
[0107]
稀疏后的特征索引集合是为了形成稀疏化的注意力矩阵qk
t
,只计算落入同一个哈希桶中的计算结果,根据局部敏感哈希算法的特性,在这一过程中,由于放大产生的噪声与其他携带运动信息的特征向量之间的相似度很低,在空间上可以表示为两个特征向量间的距离会比较远,因此,噪声的特征向量很可能被哈希到离散的哈希桶中,如果该哈希桶中没有与之对应的向量,在最终的注意力矩阵上会表现为零值。所以,最终保留落入同一哈希桶的特征向量的索引号;
[0108]
稀疏注意力矩阵计算单元,用于根据特征索引集合ω
i,j
计算稀疏注意力矩阵attention(q,k,v):
[0109][0110]
式中,d
l
为q、k、v的维度,attention(q,k,v)即为运动变化特征。
[0111]
得到运动变化特征后,特征拼接层将空间特征和运动变化特征拼接为综合特征,记直接在空间特征后加上运动变化特征,之后输入至第一全连接层,第一全连接层和第二全连接层先后对综合特征降维,之后softmax层根据降维后的综合特征进行识别分类,得到微表情类别。
[0112]
(5)将每个增强微表情图像序列和对应微表情类别标签作为一个样本,输入微表情识别网络进行训练,得到训练好的微表情识别网络。
[0113]
训练时采用的损失函数为:
[0114][0115]
式中,c为类别数,c=1,2,
…
,c,yc为微表情的类别标签,pc为属于类别c的概率。
[0116]
(6)对于待识别的微表情视频,依次按照步骤(2)、(3)处理,并输入训练好的微表情识别网络,得到对应的微表情类别。
[0117]
本实施例还提供了一种基于稀疏化自注意力机制的微表情识别系统,包括:
[0118]
微表情数据库,包含有若干微表情视频和对应的微表情类别标签;
[0119]
预处理模块,用于将数据库中的每个微表情视频转换为一个微表情图像序列,并对微表情图像序列进行预处理;
[0120]
强度放大模块,用于对预处理后的微表情图像序列使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列;
[0121]
微表情识别网络建立模块,用于建立微表情识别网络,所述微表情识别网络包括resnet-18、稀疏化自注意力模块、特征拼接层、第一全连接层、第二全连接层和softmax层,其中,所述resnet-18用于从增强微表情图像序列中提取空间特征,所述稀疏化自注意力模块用于从空间特征中获取运动变化特征,所述特征拼接层用于将空间特征和运动变化特征拼接为综合特征后输入至第一全连接层,第一全连接层和第二全连接层用于依次将综合特征降维,所述softmax层用于根据降维后的综合特征进行识别分类,得到微表情类别;
[0122]
网络训练模块,用于将每个增强微表情图像序列和对应微表情类别标签作为一个样本,输入微表情识别网络进行训练,得到训练好的微表情识别网络;
[0123]
微表情识别模块,用于对于待识别的微表情视频,依次预处理和强度放大,并输入训练好的微表情识别网络,得到对应的微表情类别。
[0124]
进一步的,所述预处理模块具体用于将数据库中的每个微表情视频转换为一个微表情图像序列,并进行人脸配准和面部区域剪切。
[0125]
进一步的,所述强度放大模块具体用于提取预处理后的微表情图像序列的起始帧i
onset
和峰值帧i
apex
,并根据起始帧i
onset
和峰值帧i
apex
使用运动放大网络进行微表情强度的放大,得到增强微表情图像序列i
mag
:
[0126]imag
={i
mag,i
}
[0127]imag,i
=f(i
onset
(1 αi)|i
apex-i
onset
|)
[0128]imag,i
为预处理后微的表情图像序列中第i帧图像放大之后的图像,f(
·
)为运动放大网络,αi为第i帧图像的放大倍数,放大倍数按照微表情图像序列的排列顺序从前到后依次递增。
[0129]
进一步的,所述稀疏化自注意力模块具体包括:
[0130]
基本矩阵生成单元,用于根据空间特征f
t
采用下式计算自注意力矩阵的查询矩阵q、键矩阵k、值矩阵v:
[0131]
q=f
t
×
wq[0132]
k=f
t
×
wk[0133]
v=f
t
×
wv[0134]
式中,wq、wk、wv分别为对应的权重矩阵;
[0135]
超平面生成单元,用于在空间中随机地生成n_rounds个超平面{h
(1)
,h
(2)
,
…
,h
(n_rounds)
},n_rounds为大于2的正整数;h
(*)
为第*个超平面;
[0136]
特征哈希单元,用于基于超平面将空间分为2
(n_rounds)
个哈希桶,采用下式分别计算q、k中每一个特征向量所落入的哈希桶;
[0137][0138][0139][0140][0141]
式中,qu、kv表示q、k中第u、v个特征向量,length表示增强微表情图像序列的帧数,h(qu)、h(kv)表示qu、kv所落入的哈希桶的二进制标号,a
(j)
、b
(j)
表示h(qu)、h(kv)的第j个比特值;
[0142]
特征稀疏单元,用于只保留q、k中落入同一哈希桶的特征向量的索引号,存入稀疏后的特征索引集合ω
u,v
中:
[0143]
ω
u,v
={(u,v)|h(qu)=h(kv)},u,v=1,2,
…
,length
[0144]
稀疏注意力矩阵计算单元,用于根据特征索引集合ω
i,j
计算稀疏注意力矩阵attention(q,k,v):
[0145][0146]
式中,d
l
为q、k、v的维度,attention(q,k,v)即为运动变化特征。
[0147]
进一步的,所述网络训练模块中训练时采用的损失函数为:
[0148][0149]
式中,c为类别数,c=1,2,
…
,c,yc为微表情的类别标签,pc为属于类别c的概率。
[0150]
为验证本发明的有效性,在came2微表情数据库、samm微表情数据库和smic数据库的hs子数据库之间做了微表情识别,验证结果及与其他最新方法的比较如表1所示:
[0151]
表1
[0152]
方法年份casme2sammsmic-hslbp-sip201445.3636.7642.12
magga201863.30n/an/adssn201970.7857.3563.41tscnn-i202074.0563.5372.74lbpa
cc
p
u2
202169.03n/a76.59本方法202181.0677.6179.88
[0153]
表1中,n/a表示没有相关记录。
[0154]
对casme2数据库的表情做如下处理:将样本个数少于10个的类别省略,避免样本严重不平衡问题。完成5种类别的识别任务,分别是happy、regression、disgust、fear和surprise对samm数据库的表情做如下处理:将样本个数少于10个的类别省略,避免样本严重不平衡问题,完成5种类别的识别任务,分别是、happiness、angry、disgust、fear和surprise。smic数据库本身类别为positive、negative、surprise,完成三分类的识别任务。
[0155]
实验结果表明,基于本发明提出的微表情识别方法取得了较高的微表情识别率。相较于传统的微表情放大方式,本发明可以免去部分超参数人为设置的繁琐,对个体的适应性更强,更方便。
[0156]
以上所揭露的仅为本发明一种较佳实施例而已,不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。