1.本发明属于计算机视觉领域,具体涉及一种基于多时间分辨率时态语义聚合网络的时序动作定位方法。
背景技术:
2.近年来,互联网上的多媒体正在迅速发展,导致每分钟共享的视频数量越来越多。为了应对信息爆炸,理解和分析这些视频是必要的,以便于用于各种目的,如搜索,推荐,排名等。视频理解旨在通过智能分析技术,自动化地对视频中的内容进行识别和解析,涉及生活的多个方面,已经发展成一个十分广阔的学术研究和产业应用方向,主要有动作识别和时序动作定位等基础领域。
3.在时序动作定位领域,视频往往没有被剪辑,时长较长,且动作通常只发生在视频中的一小段时间内,视频可能包含多个动作,也可能不包含动作,即为背景类。时序动作定位不仅要预测视频中包含了什么动作,还要预测动作的起始和终止时刻。现有方法证明,使用视频上下文来检测动作是有效的。上下文指的是不属于目标动作但携带有价值指示性信息的框架。现有技术一般仅使用时态上下文,缺点是往往携带的信息比较单一,或将语义上下文和时态上下文结合为基于图卷积网络的子图定位问题,但仍不能适应时间跨度变化较大的时序行为片段,生成的代码特性包含信息不够丰富多样,使得预测的候选时序区间边界不够灵活,时序边界不够精确。因此,如何更好的处理时间与语义信息以及如何处理大跨度时序行为片段是提升时序动作定位准确率的关键之一。
技术实现要素:
4.本发明的目的在于针对上述问题,提出一种基于多时间分辨率时态语义聚合网络的时序动作定位方法,通过将时间与语义上下文结合到视频特征中,同时对每个时序点进行局部与全局的联合建模,得到更灵活更具鲁棒性的上下文关系表达,提高了时序动作定位的准确性。
5.为实现上述目的,本发明所采取的技术方案为:
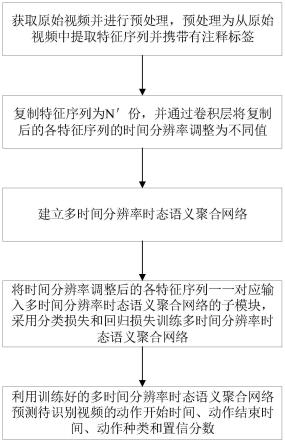
6.本发明提出的基于多时间分辨率时态语义聚合网络的时序动作定位方法,包括如下步骤:
7.s1、获取原始视频并进行预处理,预处理为从原始视频中提取特征序列特征序列x携带有注释标签其中,时间分辨率t=s/σ,s为原始视频的总帧数,σ为不同片段xi之间间隔的帧数,c为片段xi的特征维度,kn为第n个动作,t
s,n
、t
e,n
和cn依次为第n个动作的开始时间、结束时间和动作种类;
8.s2、复制特征序列x为n'份,并通过卷积层将复制后的各特征序列x的时间分辨率调整为不同值;
9.s3、建立多时间分辨率时态语义聚合网络,多时间分辨率时态语义聚合网络包括依次连接的第一特征提取单元、第二特征提取单元、第三特征提取单元和后处理模块,第一特征提取单元包括n'个并行的子模块,子模块包括依次连接的第一时态语义上下文融合模块和第一注意力单元,第二特征提取单元用于将各第一注意力单元的输出特征图进行相加聚合,第三特征提取单元包括依次连接的第二注意力单元、第七特征提取单元和第二时态语义上下文融合模块,其中:
10.各时态语义上下文融合模块,包括第四特征提取单元、以及并行的第一分支单元、第二分支单元和第三分支单元,第一分支单元用于输出对应时态语义上下文融合模块的原始输入特征图,第二分支单元包括依次连接的自注意力模块、第五特征提取单元和第一分组卷积单元,第五特征提取单元还与自注意力模块的输入端连接,用于进行相加聚合,第三分支单元包括依次连接的动态图卷积网络、第一involution卷积层、第二involution卷积层、第六特征提取单元、第一mobilenet网络、第二分组卷积单元和第二mobilenet网络,第六特征提取单元还与动态图卷积网络的输出端连接,用于进行相加聚合,第四特征提取单元用于将第一分支单元、第二分支单元和第三分支单元的输出特征图进行相加聚合;
11.各注意力单元基于八头注意力机制进行局部特征和全局特征提取;
12.第七特征提取单元用于将第二注意力单元的输出特征图与超参数1/n'进行相乘操作;
13.后处理模块包括依次连接的上采样模块、concat层和全连接层,上采样模块还与第二时态语义上下文融合模块的动态图卷积网络的输出端连接;
14.s4、将时间分辨率调整后的各特征序列x一一对应输入子模块,采用分类损失和回归损失训练多时间分辨率时态语义聚合网络;
15.s5、利用训练好的多时间分辨率时态语义聚合网络预测待识别视频的动作开始时间、动作结束时间、动作种类和置信分数。
16.优选地,步骤s2中,n'=3,调整后的各特征序列x的时间分辨率分别为t、t/2、256。
17.优选地,各分组卷积单元采用32条路径。
18.优选地,第五特征提取单元、第二involution卷积层、第四特征提取单元的输出端均连接有relu激活函数。
19.优选地,第五特征提取单元将80%的原始输入特征图和20%的自注意力模块的输出特征图进行相加聚合。
20.优选地,注意力单元分别采用四头注意力机制进行局部特征和全局特征提取。
21.优选地,分类损失lc和回归损失ln,计算公式如下:
22.lc=l
wce
(ps,d
ss
) l
wce
(pe,d
se
)
23.ln=l
wce
(p
cls
,1{ψc》0.5}) ω1·
l
mse
(p
reg
,ψc)
24.其中,l
mse
为均方误差损失,l
wce
为加权交叉熵损失,ps为每个片段对应的预测开始概率,pe为每个片段对应的预测结束概率,d
ss
为每个片段对应的ps的训练目标,d
se
为每个片段对应的pe的训练目标,p
cls
为分类损失对应的得分,p
reg
为回归损失对应的得分,ω1为权衡系数,ψc为最大的iou。
25.与现有技术相比,本发明的有益效果为:
26.本发明通过将不同时间分辨率的特征序列进行融合获得含有信息更丰富的特征
图,通过时态语义上下文融合模块,将时间上下文分配不同的注意力权重并与多层次语义结合到视频特征中,并针对视频中不同动作之间时间跨度差异大的问题,通过注意力单元对每个时序点结合局部和全局时序依赖关系,以得到更灵活更具鲁棒性的上下文关系表达,通过使用involution卷积和mobilenet网络减少卷积核的冗余表达,大大提高计算能力和时序动作定位的准确性。
附图说明
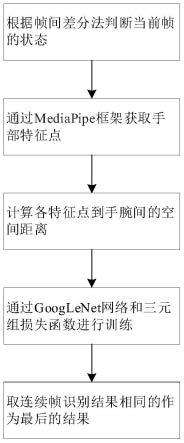
27.图1为本发明的时序动作定位方法流程图;
28.图2为本发明的多时间分辨率时态语义聚合网络的结构示意图;
29.图3为本发明的时态语义上下文融合模块结构示意图;
30.图4为本发明的注意力单元结构示意图。
具体实施方式
31.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
32.需要说明的是,除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同。本文中在本技术的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本技术。
33.如图1-4所示,基于多时间分辨率时态语义聚合网络的时序动作定位方法,包括如下步骤:
34.s1、获取原始视频并进行预处理,预处理为从原始视频中提取特征序列特征序列x携带有注释标签其中,时间分辨率t=s/σ,s为原始视频的总帧数,σ为不同片段xi之间间隔的帧数,c为片段xi的特征维度,kn为第n个动作,t
s,n
、t
e,n
和cn依次为第n个动作的开始时间、结束时间和动作种类。
35.s2、复制特征序列x为n'份,并通过卷积层将复制后的各特征序列x的时间分辨率调整为不同值。
36.在一实施例中,步骤s2中,n'=3,调整后的各特征序列x的时间分辨率分别为t、t/2、256。需要说明的是,特征序列x还可根据实际需求复制为任意数量,并可对应调整时间分辨率。
37.s3、建立多时间分辨率时态语义聚合网络,多时间分辨率时态语义聚合网络包括依次连接的第一特征提取单元、第二特征提取单元、第三特征提取单元和后处理模块,第一特征提取单元包括n'个并行的子模块,子模块包括依次连接的第一时态语义上下文融合模块和第一注意力单元,第二特征提取单元用于将各第一注意力单元的输出特征图进行相加聚合,第三特征提取单元包括依次连接的第二注意力单元、第七特征提取单元和第二时态语义上下文融合模块,其中:
38.各时态语义上下文融合模块,包括第四特征提取单元、以及并行的第一分支单元、第二分支单元和第三分支单元,第一分支单元用于输出对应时态语义上下文融合模块的原始输入特征图,第二分支单元包括依次连接的自注意力模块、第五特征提取单元和第一分组卷积单元,第五特征提取单元还与自注意力模块的输入端连接,用于进行相加聚合,第三分支单元包括依次连接的动态图卷积网络、第一involution卷积层、第二involution卷积层、第六特征提取单元、第一mobilenet网络、第二分组卷积单元和第二mobilenet网络,第六特征提取单元还与动态图卷积网络的输出端连接,用于进行相加聚合,第四特征提取单元用于将第一分支单元、第二分支单元和第三分支单元的输出特征图进行相加聚合;
39.各注意力单元基于八头注意力机制进行局部特征和全局特征提取;
40.第七特征提取单元用于将所述第二注意力单元的输出特征图与超参数1/n'进行相乘操作;
41.后处理模块包括依次连接的上采样模块、concat层和全连接层,上采样模块还与第二时态语义上下文融合模块的动态图卷积网络的输出端连接。
42.在一实施例中,各分组卷积单元采用32条路径。
43.在一实施例中,第五特征提取单元、第二involution卷积层、第四特征提取单元的输出端均连接有relu激活函数。
44.在一实施例中,第五特征提取单元将80%的原始输入特征图和20%的自注意力模块的输出特征图进行相加聚合。
45.在一实施例中,注意力单元分别采用四头注意力机制进行局部特征和全局特征提取。
46.其中,多时间分辨率时态语义聚合网络的结构如图2所示,第一特征提取单元包括3个并行的子模块,各子模块包括依次连接的第一时态语义上下文融合模块(tscf1)和第一注意力单元(lgam1),第三特征提取单元包括依次连接的第二注意力单元(lgam2)和第二时态语义上下文融合模块(tscf2),各时态语义上下文融合模块的结构相同,如图3所示,各注意力单元的结构相同,如图4所示,注意力单元用于将输入数据同时进行局部(localprocess)和全局(glocalprocess)的时序依赖关系捕获。后处理模块即post process。
47.时态语义上下文融合模块包含第四特征提取单元、以及并行的第一分支单元、第二分支单元和第三分支单元,如图3所示,其中:
48.1)第一分支单元用于输出对应时态语义上下文融合模块的原始输入特征图(即固定流不做任何处理)。
49.2)第二分支单元(tprocess),通过自注意力模块加入自注意力机制,学习不同时间尺度的注意力权重。将对应时态语义上下文融合模块的输入特征图分三步进行处理。首先,选取时间步长t∈[1,t]内围绕中心元素x
it
的元素将其提取出来形成一个代表向量x
′
it
,这种特征表示基于内核大小ks和膨胀率d,中心元素x
it
可根据实际需求选取,将内核大小ks设置为3,即可提取膨胀率d为2的t,t 2,t-2的局部元素,作为代表向量x
′
it
。引入自注意力机制,时间步长t的注意力操作的输出如下所示:
[0050]
s(x
it
)=γ(x
′
it
)[softmax(α(x
it
)β(x
′
it
))]
t
[0051]
其中,α(x
it
)=w
α
x
it
,β(x
′
it
)=w
β
x
′
it
,γ(x
′
it
)=w
γ
x
′
it
,w
α
∈rc×c,w
β
∈rc×c,w
γ
∈rc×c,softmax为softmax函数,t为转置操作。
[0052]
将对应特征序列x中所有时间步长的输出串联得到i
th
块的输出a(xi),公式如下:
[0053]
a(xi)=[s(x
i1
)
t
,s(x
i2
)
t
,
…
,s(x
it
)
t
]。
[0054]
其次,将80%的基础信息xi和20%的复杂信息a(xi)通过第五特征提取单元进行相加聚合输出e
′
t
,公式如下:
[0055]e′
t
=0.2
×
a(xi) 0.8
×
xi[0056]
其中,xi是对应时态语义上下文融合模块的输入特征图。
[0057]
最后,将e
′
t
经过relu激活函数和第一分组卷积单元输出最终数据e
t
,公式如下:
[0058]et
=γ[relu(e
′
t
)]
r=32
[0059]
其中,γ为分组卷积,relu为relu激活函数,r=32表示分组卷积中采用32条路径来提高转换的多样性。
[0060]
3)第三分支单元(sprocess),根据动态图卷积(dynamic edge conv)定义动态聚合语义相似的片段,将对应时态语义上下文融合模块的输入特征图分三步进行处理。首先,以i
th
块为例:在此特征空间内,对于每个元素xi,通过knn算法找到l个距离最近的元素并将它们按升序排列,得到:计算出l个特征后加入全连接层更新,最后用最大池化操作(max pool)将l个特征整合为xi的新特征xs。
[0061][0062]
其中,代表元素xi的第k个最近邻居节点。
[0063]
其次,将xs依次经过第一involution卷积层、第二involution卷积层和激活函数并通过第六特征提取单元实现与原数据xs的融合,第一involution卷积层的输入端还可设有依次连接的两个二维卷积层。将融合后的数据经过第一mobilenet网络和第二分组卷积单元输出得到e
′s。
[0064]
最后,将e
′s经过第二mobilenet网络输出得到最终数据es,分组卷积中选择r=32条路径,并且在分组卷积前后使用mobilenet网络。公式如下:
[0065]e′s=γ{m[relu(i(i(xs)) xs]}
r=32
[0066]es
=m(e
′s)
[0067]
其中,γ为分组卷积,relu为relu激活函数,i代表involution卷积,m代表mobilenet网络。其中,动态图卷积、involution卷积和mobilenet网络均为现有技术,在此不再赘述。通过involution卷积和mobilenet网络减少卷积核的冗余表达,减少计算量。
[0068]
第四特征提取单元用于将三个分支单元对应的tprocess流、sprocess流和固定流聚合,并通过激活函数获得y(x,m,w),公式如下:
[0069]
y(x,m,w)=relu(τ(x,m
tprocess
,w
tprocess
) τ(x,m
sprocess
,w
sprocess
) x)
[0070]
其中,τ(x,m
tprocess
,w
tprocess
)为第二分支单元的输出特征图,τ(x,m
sprocess
,w
sprocess
)为第三分支单元的输出特征图,m={m
tprocess
,m
sprocess
},m
tprocess
为对应于e
t
的邻接矩阵,m
sprocess
为对应于es的邻接矩阵,w={w
tprocess
,w
sprocess
},w
tprocess
为对应于e
t
的可训练权重,w
sprocess
为对应于es的可训练权重,relu为非线性激励函数。
[0071]
注意力单元通过八头自注意力机制,将输入数据同时进行局部和全局的时序依赖关系捕获。如图4所示,八头注意力机制,各分一半采用不同的查询矩阵、键矩阵和值矩阵分
别处理输入数据代表局部上下文信息与全局上下文信息,得到输入x
′i对应的输出x
″i。注意力单元为本领域技术人员熟知的现有技术,在此不再赘述。通过设置不同的掩码信息赋予新的权重,标识数据中的关键特征,可通过训练优化让网络学到局部与全局中各自需要关注的区域,提高了时序特征的鲁棒性和多样性。
[0072]
将经过三个第一注意力单元处理的数据融合,再次进入第二注意力单元并乘以超参数q后进入第二时态语义上下文融合模块再次进行特征融合,超参数q为1/n’。
[0073]
后处理模块包括依次连接的上采样模块、concat层和全连接层,上采样模块还与第二时态语义上下文融合模块的动态图卷积网络的输出端连接。
[0074]
其中,上采样模块基于线性插值进行上采样,将第二时态语义上下文融合模块输出的y(x,m,w)和第二时态语义上下文融合模块的动态图卷积网络输出的xs作为输入,进入后处理模块。对于y(x,m,w)采样θ1得到各片段对应的特征对于xs采样θ2得到各片段对应的特征θ1、θ2为对齐量。基于线性插值采样j点,最终分别对应输出为对齐量。基于线性插值采样j点,最终分别对应输出和
[0075]
concat层将y1和y2连接后输入全连接层,计算它和正确标注动作(即步骤s1中的注释标签k)的iou,并将最大的iou作为训练目标ψc。iou是一种测量在特定数据集中检测相应物体准确度的一个标准,为本领域技术人员熟知技术,在此不再赘述。
[0076]
s4、将时间分辨率调整后的各特征序列x一一对应输入子模块,采用分类损失和回归损失训练多时间分辨率时态语义聚合网络。
[0077]
在一实施例中,分类损失lc和回归损失ln,计算公式如下:
[0078]
lc=l
wce
(ps,d
ss
) l
wce
(pe,d
se
)
[0079]
ln=l
wce
(p
cls
,1{ψc》0.5}) ω1·
l
mse
(p
reg
,ψc)
[0080]
其中,l
mse
为均方误差损失,l
wce
为加权交叉熵损失,ps为每个片段对应的预测开始概率,pe为每个片段对应的预测结束概率,d
ss
为每个片段对应的ps的训练目标,d
se
为每个片段对应的pe的训练目标,p
cls
为分类损失对应的得分,p
reg
为回归损失对应的得分,ω1为权衡系数,ψc为最大的iou。p
cls
和p
reg
由全连接层输出,分别使用分类损失和回归损失对多时间分辨率时态语义聚合网络进行训练以匹配ψc。
[0081]
具体地,将第二注意力单元处理的数据乘以超参数1/3,经过第二时态语义上下文融合模块处理得到开始/结束概率(ps,pe),并使用(d
ss
,d
se
)来表示每个片段的相应训练目标。最后,使用加权交叉熵损失l
wce
来计算预测和目标之间的差异。利用均方误差损失l
mse
和加权交叉熵损失l
wce
,计算得到回归损失ln,计算权重来平衡正负样本的比率,权衡系数ω1设置为10。
[0082]
s5、利用训练好的多时间分辨率时态语义聚合网络预测待识别视频的动作开始时间、动作结束时间、动作种类和置信分数。
[0083]
其中,如从待识别视频中提取m个片段u
ε
,利用训练好的多时间分辨率时态语义聚合网络对m个片段u
ε
进行预测,构造进行预测,构造其中,代表预测的动作开始时间和结束时间,代表预测动作种类,pm代表预测置信
分数,α为模型训练中搜索得到的pm最高时对应的最优值。在α为最优值时,pm置信分数越高,预测动作种类准确度越高。
[0084]
通过在两个公共数据集上对本技术的多时间分辨率时态语义聚合网络进行实验验证。具体地,在公共数据集activitynet-1.3上,平均map为34.94%。在公共数据集hacs上,平均map达到28.46%,优于现有技术中的方法,验证了本技术能够提升时序动作定位的准确率。如表1、2所示,表中0.5、0.75、0.95代表map(mean average precision)即所有标签的平均精确率,avg.为平均值。mtscanet即本技术所述方法,scc、cdc、bsn、bmn、ssn和g-tad为现有技术所述方法。
[0085]
表1
[0086][0087]
表2
[0088][0089]
本发明通过将不同时间分辨率的特征序列进行融合获得含有信息更丰富的特征图,通过时态语义上下文融合模块,将时间上下文分配不同的注意力权重并与多层次语义结合到视频特征中,并针对视频中不同动作之间时间跨度差异大的问题,通过注意力单元对每个时序点结合局部和全局时序依赖关系,以得到更灵活更具鲁棒性的上下文关系表达,通过使用involution卷积和mobilenet网络减少卷积核的冗余表达,大大提高计算能力和时序动作定位的准确性。
[0090]
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0091]
以上所述实施例仅表达了本技术描述较为具体和详细的实施例,但并不能因此而理解为对申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。