技术特征:
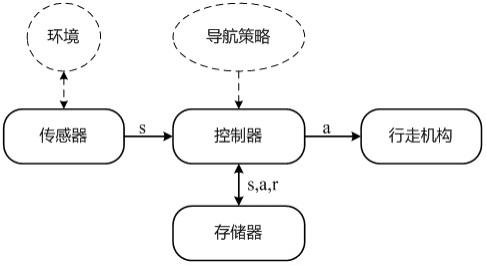
1.一种自主导航机器人,其特征在于,包括:传感器,其用于检测障碍物相对机器人的距离和角度,形成状态数据;控制器,其用于根据所述状态数据以及目标点相对位置对机器人所处的场景进行分类,若为简单场景,则执行pid控制策略;若为复杂场景,则执行强化模仿学习控制策略;若为紧急场景,则执行约束强化模仿学习控制策略;并且通过执行相应的控制策略计算出机器人行走的线速度和角速度;行走机构,其用于驱动机器人按照控制器计算出的线速度和角速度行走。2.根据权利要求1所述的自主导航机器人,其特征在于,在所述控制器中配置有碰撞预测模型,所述碰撞预测模型根据所述状态数据以及机器人的自身速度预测机器人能否发生碰撞。3.根据权利要求2所述的自主导航机器人,其特征在于,所述简单场景为机器人前方没有障碍物或者机器人到达目标点周围的场景;所述紧急场景为通过所述碰撞预测模型机器预测出机器人会发生碰撞的场景;所述复杂场景为所述简单场景和紧急场景以外的场景。4.根据权利要求1至3中任一项所述的自主导航机器人,其特征在于,所述控制器在执行pid控制策略时,将机器人前进正方向与目标点之间的夹角设置为偏差,代入pid计算公式,计算出机器人的角速度,并保持机器人的线速度不变。5.根据权利要求1所述的自主导航机器人,其特征在于,所述控制器所执行的强化模仿学习控制策略包括:模仿学习过程,其利用专家数据集中的数据对actor网络进行训练;强化学习过程,其利用经模仿学习过程训练后的actor网络以及critic网络,结合状态数据、机器人的自身速度以及目标点相对位置计算输出动作a,并根据所述动作a控制所述行走机构调整机器人行走的线速度和角速度。6.根据权利要求5所述的自主导航机器人,其特征在于,所述控制器在模仿学习过程中,配置模仿学习的目标优化函数为:其中,s
i
、a
i
为专家数据集中的数据,且s
i
表示机器人通过传感器所观察到的状态,a
i
表示在状态s
i
下机器人所执行的动作;π
θ
表示actor网络;n表示专家数据集中的样本数量;θ表示actor网络的权重;表示求结果最小值所对应的θ;所述控制器利用权重θ对actor网络进行优化。7.根据权利要求5所述的自主导航机器人,其特征在于,还包括:存储器,其用于存储控制器在执行强化模仿学习控制策略时计算输出的动作a、机器人在环境中执行了动作a后到达的状态s以及机器人执行动作a获得的奖赏r,并将所收集到的(s,a,r)数据存入经验池;其中,所述控制器在存入经验池中的数据的数量满足设定条件时,计算强化学习模型的损失值,进而对强化学习模型中的actor网络和critic网络进行更新。8.根据权利要求7所述的自主导航机器人,其特征在于,所述控制器对强化学习的奖赏
函数进行如下配置:初始化奖赏函数r=0;根据机器人在第t-1个时间步和第t个时间步的位置p
t-1
、p
t
以及目标点的位置g和机器人第t-1个时间步的角速度w
t
计算奖赏函数r,包括以下情况:若|p
t-g||<0.1,则r=r r
arrival
;否则r=r w
g
(||p
t-1-g||-||p
t-g||);若预测机器人会发生碰撞,则r=r r
collision
;若|w
t
|>0.7,则其中,|| ||表示取模运算;r
arrival
、r
collision
、w
g
、w
w
均为超参数。9.根据权利要求7所述的自主导航机器人,其特征在于,所述控制器在强化学习过程中,配置critic网络的目标优化函数为:其中,φ为critic网络的权重;γ为折扣因子;t为时间步;t为最大步数;s
t
表示机器人在第t个时间步的状态;r
t'
为机器人在第t'个时间步所获得的奖赏;v
φ
为critic函数,用于评估状态s的好坏;表示求结果最小值所对应的φ;配置actor网络的目标优化函数为:配置actor网络的目标优化函数为:配置actor网络的目标优化函数为:其中,θ为actor网络的权重;n表示回合数;t
n
表示第n回合的最大步数;a
t
表示机器人在第t个时间步的动作;ε表示超参数;π
θ
和π
old
分别表示当前的actor网络和更新前的actor网络;e
t
表示期望函数;表示求结果最大值所对应的θ;clip表示限制函数,且10.根据权利要求5至9中任一项所述的自主导航机器人,其特征在于,所述约束强化模仿学习控制策略与所述强化模仿学习控制策略中所使用的actor网络和critic网络相同;所述控制器所执行的约束强化模仿学习控制策略包括:判断机器人的线速度是否大于设定阈值;若大于设定阈值,则控制机器人停止行走;若小于等于设定阈值,则缩小传感器检测到的距离数据,并将缩小后的距离数据输入强化学习模型,使通过强化学习模型计算输出动作a中表示机器人速度的数值减小。
技术总结
本发明公开了一种自主导航机器人,包括传感器、控制器和行走机构;其中,传感器用于检测障碍物相对机器人的距离和角度,形成状态数据;控制器用于根据状态数据以及目标点的相对位置对机器人所处的场景进行分类,若为简单场景,则执行PID控制策略;若为复杂场景,则执行强化模仿学习控制策略;若为紧急场景,则执行约束强化模仿学习控制策略;控制器通过执行相应的控制策略控制行走机构驱动机器人行走,达到导航避障的目的。本发明面向各种具有动态和静态障碍物的复杂场景设计机器人的自主导航策略,可以弥补传统路径规划方法无法躲避动态障碍物,监督式学习方法泛化能力差,强化学习方法在简单以及紧急情况下输出策略不理想的缺陷。缺陷。缺陷。
技术研发人员:陶冶 王浩杰
受保护的技术使用者:青岛科技大学
技术研发日:2022.04.07
技术公布日:2022/7/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。