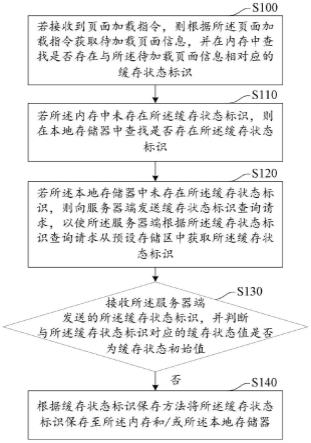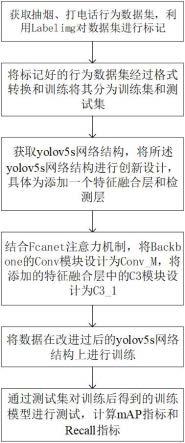
1.本发明属于计算机视觉图像识别技术领域,具体涉及一种基于改进yolov5s网络的行为检测方法。
背景技术:
2.目前,民众购车力度不断发展,根据最新数据表示,仅我国机动车保有量就已经达到3.95亿辆,机动车驾驶人达4.81亿人。但是随之而来的也是汽车事故案件的不断增长。由于机动车驾驶人的不规范操作,例如开车过程中玩手机、打电话、抽烟等,造成汽车事故案件。因此,研究机动车内人员是否有违规行为具有十分重要的意义。然而,玩手机、打电话和抽烟等行为中的行为对象(手机、烟)均属于小目标,如何能够实现对小目标物体的精准识别是当前亟需解决的技术问题。
技术实现要素:
3.解决的技术问题:针对前述技术问题,本发明公开了一种基于改进yolov5s网络的行为检测方法,增强了网络的特征提取能力,保证检测小目标物体的检测精度。
4.技术方案:一种基于改进yolov5s网络的行为检测方法,其特征在于,所述行为检测方法包括以下步骤:s1,采集违规行为图像,生成行为数据集,对行为数据集进行标注;将标注好的行为数据集转换成文本格式,并划分成训练集和测试集;s2,基于yolov5s网络构建行为识别模型,所述行为识别模型包括特征提取模块、特征融合模块和检测模块;所述特征提取模块包括依次连接的四个特征提取层,对导入的违规行为图像进行特征提取操作,依次得到第一特征图、第二特征图、第三特征图和第四特征图;所述特征融合模块对第四特征图依次进行三次上采样处理,在上采样过程中,三次上采样结果按照自下而上的顺序分别和第三特征图、第二特征图、第一特征图进行融合,分别得到第一融合特征图、第二融合特征图和第三融合特征图;第三融合特征图进行1*1且步长为1的卷积,再采用bottleneck模块对卷积结果进行处理后与第五特征图融合,融合结果依次通过bn层和卷积层,得到第一输出特征图,第一输出特征图结合fcanet注意力机制,进入检测模块;所述第一输出特征图再依次进行三次下采样处理,在下采样过程中,三次下采样结果按照自上而下的顺序分别与第二融合特征图、第二次上采样之前的特征图和第一次上采样之前的特征图进行融合,分别得到第二输出特征图、第三输出特征图和第四输出特征图,结合fcanet注意力机制,进入检测模块;所述检测模块结合第一输出特征图、第二输出特征图、第三输出特征图和第四输出特征图,识别得到违规行为类别和违规行为对象;s3,采用训练集对行为识别模型进行训练,在训练完成后,采用测试集对训练完成的行为识别模型进行测试,计算map指标和recall指标。
5.进一步地,步骤s1中,违规行为图像包括抽烟图像和打电话图像。
6.进一步地,步骤s2中,所述特征提取模块包括第一特征提取层、第二特征提取层、第三特征提取层和第四特征提取层;所述第一特征提取层包括依次连接的两个卷积层和一个c3模块;所述第二特征提取层、第三特征提取层和第四特征提取层分别包括相互连接的一个卷积层和一个c3模块。
7.进一步地,步骤s2中,所述特征提取模块采用的卷积层的激活函数为metaaconc函数。
8.进一步地,所述特征融合模块包括依次连接的第一卷积层、第一上采样层、第一融合层、第一c3层、第二卷积层、第二上采样层、第二融合层、第二c3层、第三卷积层、第三上采样层、第三融合层、第三c3层、第四卷积层、第四融合层、第四c3层、第五卷积层、第五融合层、第五c3层、第六卷积层、第六融合层和第六c3层;所述第一卷积层的输出端与第六融合层的输入端连接;所述第二卷积层的输出端与第五融合层的输入端连接;第三卷积层的输出端与第四融合层的输入端连接。
9.进一步地,所述第二c3层和第三c3层采用改进的c3模块,用于对输入的原始特征图进行1*1且步长为1的卷积,再采用bottleneck模块对卷积结果进行处理后与原始特征图融合,融合结果依次通过bn层和卷积层,输出相应的特征图。
10.进一步地,所述行为识别模型的四个输出通道上一一对应地添加有fcanet注意力模块,fcanet注意力模块采用多光谱通道注意力机制。
11.进一步地,步骤s3中,计算map指标和recall指标的过程包括以下步骤:在模型训练完成后,保存生成的权重文件,采用生成的权重文件进行测试,生成对应的csv格式文件,从csv格式文件中提取得到map指标和recall指标。
12.进一步地,所述行为识别模型的损失函数为:式中,代表分类损失,代表矩形框损失,代表置信度损失;矩形框损失采用ciou_loss函数计算得到,分类损失和置信度损失采用bcewithlogitsloss函数计算得到。
13.有益效果:第一,本发明提出的基于改进yolov5s网络的行为检测方法,既可以监督车辆驾驶员不规范行为,也可以在公共场所,例如禁烟地点监督人群的不规范行为,以便管理。此外,本发明提出的基于改进的yolov5s网络结构具有轻量级效果,也可以部署在嵌入式设备上。
14.第二,本发明提出的基于改进yolov5s网络的行为检测方法,主要是检测打电话、抽烟行为,因为抽烟、打电话图片数据集存在面部阻挡或手指阻挡,所以对网络结构精度要求较高,而本发明提出的算法,在识别小目标物体上有着较高的精度和速度,并且在复杂天气或者多目标数据的识别上可以保持较高的识别精度和速度。
附图说明
15.图1为基于改进yolov5s网络的行为检测方法流程图。
16.图2为本发明实施例中手动标注数据集的示意图。
17.图3为本发明实施例中backbone中改进后的conv模块(conv_m层)的示意图。
18.图4为本发明实施例中第一特征融合层中改进后的c3模块(c3_1模块)的结构示意图。
19.图5为本发明实施例中改进yolov5s网络结构的结构示意图。
具体实施方式
20.下面的实施例可使本专业技术人员更全面地理解本发明,但不以任何方式限制本发明。
21.图1为基于改进yolov5s网络的行为检测方法流程图。参见图1,该行为检测方法包括以下步骤:s1,采集违规行为图像,生成行为数据集,对行为数据集进行标注;将标注好的行为数据集转换成文本格式,并划分成训练集和测试集。
22.s2,基于yolov5s网络构建行为识别模型,所述行为识别模型包括特征提取模块、特征融合模块和检测模块;所述特征提取模块包括依次连接的四个特征提取层,对导入的违规行为图像进行特征提取操作,依次得到第一特征图、第二特征图、第三特征图和第四特征图;所述特征融合模块对第四特征图依次进行三次上采样处理,在上采样过程中,三次上采样结果按照自下而上的顺序分别和第三特征图、第二特征图、第一特征图进行融合,分别得到第一融合特征图、第二融合特征图和第三融合特征图;第三融合特征图进行1*1且步长为1的卷积,再采用bottleneck模块对卷积结果进行处理后与第五特征图融合,融合结果依次通过bn层和卷积层,得到第一输出特征图,第一输出特征图结合fcanet注意力机制,进入检测模块;所述第一输出特征图再依次进行三次下采样处理,在下采样过程中,三次下采样结果按照自上而下的顺序分别与第二融合特征图、第二次上采样之前的特征图和第一次上采样之前的特征图进行融合,分别得到第二输出特征图、第三输出特征图和第四输出特征图,结合fcanet注意力机制,进入检测模块;所述检测模块结合第一输出特征图、第二输出特征图、第三输出特征图和第四输出特征图,识别得到违规行为类别和违规行为对象。
23.s3,采用训练集对行为识别模型进行训练,在训练完成后,采用测试集对训练完成的行为识别模型进行测试,计算map指标和recall指标。
24.步骤一,生成行为数据集,对行为数据集进行标注示例性地,违规行为图像包括抽烟图像和打电话图像。应当理解,烟和电话是其中两个小目标对象,本发明的行为检测方法可以推广应用在更多的目标行为识别任务中,例如在特殊场景下对人员携带的违规物品的识别等等。图2为其中一种手动标注数据集的效果示意图。图中的驾驶员正在抽烟,此时,烟是行为识别模型的识别目标,抽烟行为是行为识别模型得到的行为分类。图2中的字符是软件参数,与本实施例的技术方案无关。
25.在开源数据集上获取更多的抽烟、打电话数据集,将数据集通过labelimg进行标记,标记为calling和smoking两类。但是由于抽烟、打电话等行为数据集属于小目标数据集,且改进yolov5s网络结构模型旨在识别小目标数据,所以需要利用无人机拍取一些行为密集数据,从而得到改进yolov5s网络结构的优缺点。当抽烟、打电话行为检测数据集用labelimg进行标记过后会变为voc格式,但是这一格式不能直接通过改进yolov5s网络结构进行训练,因此还需要将其进行格式转换,例如转换为txt格式,再将其分为训练集和测试集。
26.步骤二,行为识别模型本实施例的行为识别模型基于yolov5s网络构建,为了适配本实施例的应用场景,本实施例对原始yolov5s网络结构进行改进创新。图5为本发明实施例中改进yolov5s网络结构的结构示意图。
27.具体的,本实施例从以下几个方面对原始yolov5s网络结构进行了改进:第一,在yolov5s网络结构中,添加一个特征融合层,添加了新的特征融合层之后将backbone网络的特征信息和新的特征融合层结合,获得用于小目标检测的较大特征图,因此,新添加的融合层能够提升模型特征融合能力,改进的yolov5s网络结构中有4个融合层,目的是能够更好的识别小目标特征信息。
28.参见图5,行为识别模型包括特征提取模块(backbone模块)、特征融合模块(neck模块)和检测模块(head模块)。
29.特征提取模块包括第一特征提取层、第二特征提取层、第三特征提取层和第四特征提取层;所述第一特征提取层包括依次连接的两个卷积层和一个c3模块;所述第二特征提取层、第三特征提取层和第四特征提取层分别包括相互连接的一个卷积层和一个c3模块。所述特征融合模块包括依次连接的第一卷积层、第一上采样层、第一融合层、第一c3层、第二卷积层、第二上采样层、第二融合层、第二c3层、第三卷积层、第三上采样层、第三融合层、第三c3层、第四卷积层、第四融合层、第四c3层、第五卷积层、第五融合层、第五c3层、第六卷积层、第六融合层和第六c3层;所述第一卷积层的输出端与第六融合层的输入端连接;所述第二卷积层的输出端与第五融合层的输入端连接;所述第二融合层的输出端与第四c3层的输入端连接;第三卷积层的输出端与第四融合层的输入端连接。
30.第二c3层、第三卷积层、第三上采样层、第三融合层、第三c3层、第四卷积层、第四融合层是新增特征融合层,新增特征融合层的作用是将骨干网中产生的特征图和经过3次上采样产生的特征图进行融合,并且经过c3_1和conv之后再进行一次下采样(下采样过程不在网络结构中单独示意)与第三次上采样之前产生的特征图进行融合连接,通过第三次上采样之后通过c3_1模块结合fcanet注意力机制,进入检测模块。
31.第二,将yolov5s网络结构中backbone中conv模块换为conv_m模块,具体表现为将原本conv模块的激活函数变为metaaconc,目的是提升网络精度。图3为本发明实施例中backbone中改进后的conv模块(conv_m模块或者conv_m层)的示意图。
32.第三,对第二c3层和第三c3层进行改进,初始yolov5s网络结构的c3模块是将特征图输出到两个分支中,分支一是大小为1*1且步长为1的卷积,分支二是先进行1*1且步长为1的卷积,之后经过bottleneck模块,之后再将分支一和分支二进行concat,最后依次通过bn层和卷积层,最终得到输出特征图,输出特征图的大小为160*160*255。改进过后的c3模块将分支一的卷积部分去掉,直接与经过卷积和bottleneck模块的分支二进行concat。改进过后的c3模块减少了卷积模块的运算,加快了一定的速度。图4为本发明实施例中新添加的特征融合层中改进后的c3模块(c3_1模块)的结构示意图。
33.第四,在yolov5s网络结构中添加fcanet注意力机制,该注意力机制是多光谱通道注意力机制,将添加的fcanet注意力机制与新添加的特征融合层相结合,目的是更好的提取目标信息特征和提高模型特征融合能力。如图5所示,行为识别模型的四个输出通道上一一对应地添加有fcanet注意力模块,fcanet注意力模块采用多光谱通道注意力机制。
34.步骤s3,行为识别模型训练和测试训练过程:提前下载好yolov5s网络预训练模型,根据基于yolov5s网络结构的改进部分在下载好的yolov5s预训练模型中进行对应修改,具体表现为将nc修改为2,将backbone中conv的激活函数变为metaaconc,将head部分中添加新的卷积、上采样以及c3_m部分。
35.结合前述步骤可以得到训练过程为:一开始输入大小为640*640*3,经过两次conv_m以及一次c3后输出大小为160*160*64特征图,将其与新添加的特征融合层结合,此外,将大小为160*160*64特征图经过一次conv_m和一次c3之后输出大小为80*80*128特征图,之后再次将大小为80*80*128特征图作为输入,经过一次conv_m和一次c3之后输出大小为40*40*256特征图,之后将大小为40*40*256特征图经过一次conv_m、c3和sppf生成大小为20*20*512特征图,并且每次生成不同大小的特征。
36.测试过程:步骤s3中,计算map指标和recall指标的过程包括以下步骤:经过训练过程后,会保存训练数据过后生成的权重文件。利用生成的权重文件进行测试,测试完成后会生成csv格式文件,就可以看到recall和map指标。
37.在本实施例中,改进后的yolov5网络的损失函数为:式中,代表分类损失、代表矩形框损失、代表置信度损失,矩形框损失采用ciou_loss计算,分类损失和置信度损失采用bcewithlogitsloss计算:矩形框损失采用ciou_loss计算,分类损失和置信度损失采用bcewithlogitsloss计算:矩形框损失采用ciou_loss计算,分类损失和置信度损失采用bcewithlogitsloss计算:矩形框损失采用ciou_loss计算,分类损失和置信度损失采用bcewithlogitsloss计算:矩形框损失采用ciou_loss计算,分类损失和置信度损失采用bcewithlogitsloss计算:式中,是sigmoid函数,可以把x映射到0-1区间内;iou代表候选边界框和真实边界框的交并比;v代表衡量长宽比一致性的参数;代表用于权衡的参数,即为v的影响因子,取值范围为0-1;代表框a和框b两个中心点之间的欧氏距离;c为框a和框b的最小包围矩形的对角线的欧式距离;是真实边界框的宽度,是真实边界框的高度,w是预测边界框的宽度,h是预测边界框的高度。
[0038][0038][0038][0038]38.代表准确率,代表漏检率;代表单个类别的查准率;ap代表没过类别的平均精度;代表所有图片之和;代表类别数;是所有类别ap的平均值;tp代表真正例,tn代表真反例,fp代表假正例,fn代表假反例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。