1.本发明涉及爬虫算法、新闻大数据、深度学习,提供了一种基于深度学习的新闻文本摘要生成方法。
背景技术:
2.随着信息技术的快速发展,大量的文本数据如潮水般涌现,怎样从一段冗长的文本中快速有效地获取其中的关键信息,在这个快速发展的互联网时代显得尤为重要。自动生成摘要技术是自然语言处理领域重要研究内容之一,其通过计算机对文本或者文本集合,进行自动抽取、总结或是精炼文本中的关键信息,提炼出能概括源文档的简洁、语义连贯的短文。自动文摘技术大大提高了信息获取的速度,有效地减小了人们的信息负担,在文档总结、信息检索等领域有较高的研究价值。
3.早期的文本摘要工作大都依靠人工完成,近年来,文本数据量呈井喷式爆发,自动文摘技术得到了广泛的关注和研究,涌现出大量的模型算法。目前主流的方法有抽取式摘要(extractive)和生成式摘要(abstractive)。抽取式摘要方法是将自动文摘简单的看成二元分类任务,判断文档中的句子是否属于摘要内容;生成式摘要方法是对训练数据的文本——摘要对的学习,根据不同的算法生成摘要。这些工作方法在一定程度上都取得了较好的结果,在医学、新闻、金融等领域都有应用,比如社交媒体摘要的使用,可以帮助用户快速地了解其中的关键信息。目前研究最多,效果最显著的是基于深度学习的自动摘要生成技术,该方法利用计算机对文档进行编码向量化,获取文档上下文以及语义的向量表示,然后利用深层网络进行训练学习,在文本摘要任务上实现了许多最优结果。然而现有的模型算法生成的摘要还是远远达不到人工标注的效果,该任务还有巨大的提升空间,还需要不断探索。
4.在这种情况下,抽取式和生成式结合的模型算法,可以大大提高生成的摘要质量,既缓解了抽取式模型生成的摘要存在冗余、语义不连贯的问题,也避免了生成式模型生成的摘要与原文存在事实性错误的现象。
技术实现要素:
5.为了克服现有技术的不足,为了快速地获取其中的大致内容,本发明提出了一种基于深度学习的新闻文本摘要生成方法,在海量的新闻文本中,先用抽取式摘要模型抽取出文本中重要的句子,再通过生成式摘要模型生成语意连贯,言简意赅的摘要。
6.为了解决上述技术问题,本发明提供如下的技术方案:
7.一种基于深度学习的新闻文本摘要生成方法,所述方法包括以下步骤:
8.1)通过爬虫算法爬取新闻网站上的新闻标题和新闻文本,每一个新闻文本和新闻标题组成一个story文件,文本与标题之间用@highlight标识符分隔;
9.2)将上述的story文件用stanford corenlp工具包进行分句分词,通过贪婪算法,选择出新闻文本中与标题句子rouge-1/2指标分数最高的前三个句子打上label标签,最后
生成确定格式的标注文本作为训练数据和验证数据;
10.3)文本摘要生成方法使用的是抽取 生成的策略,先使用抽取式模型从新闻文本抽取出与标题相关度高的句子,然后将抽取出来的句子作为指导信号作用于另外一个生成式模型,去指导摘要的生成;
11.4)抽取式模型采用bert网络模型获取句子表示,inter-sentence transformer层作为摘要层,来对确定格式的标注文本作文本摘要抽取式的训练;同时,用另两个bert网络模型作为两个编码器,解码器采用transformer的decoder端,对输入文本和指导信号进行文本摘要生成式的训练,指导信号是打上label的关键句子,实现过程如下:
12.4.1)给定token化的文本x=[cls,x1,x2,
…
,xn,sep]其中cls和sep是每个句子的句首和句尾插入的token,x
t
是文本t位置上的token,将文本x输入bert模型后,得到文本的隐藏表示h=[h1,h2,
……hm
],进一步获取每个句子句首的clstoken的隐藏表示t=[t1,t2,
…
t
t
];
[0013]
4.2)将隐藏表示t传输给由两层transformer encoder layer组成的摘要层,输出得到h
l
,然后经过一个sigmoid层,得到每个句子的分数y=[y1,y2,
…yn
],根据标注文本的label标签l=[l1,l2,
…
ln],然后使用二分类交叉熵损失函数对抽取式模型进行训练:
[0014][0015][0016]
yi=σ(w
ohl
bo)#(3)
[0017][0018]
ln=-[ln·
logyn (1-ln)
·
log(1-yn)]#(5)
[0019]
其中l表示transformer encoder layer的层数,mhatt是对transformer encoder layer层的输出h
l-1
做多头注意力运算,是经过层归一化操作ln之后的输出,然后对该输出做ffn前馈网络运算,生成第l层的输出向量h
l
,σ是sigmoid运算,wo是权重参数,bo是偏差,yi是第i个句子的预测分数,n是句子的个数,ln是第n个句子的标签,yn是第n个句子的预测分数;
[0020]
4.3)将token化的输入文本x=[x1,x2,
…
,xn]与token化的指导信号g=[g1,g2,
…
,gm]分别输入给生成式模型的两个编码器bert模型,分别得到隐藏表示h
x
=[h
x1
,h
x2
,
…
,h
xn
],hg=[h
g1
,h
g2
,
…
,h
gm
];
[0021]
4.4)生成式模型的解码器端首先对上一层的输出y做一次self attention操作,其次利用cross attention机制关注指导信号并生成相应表示y1,然后再经过一个cross attention层,根据y1来处理整个输入文本,得到表示y2,最后经过一个前馈网络层,得到中间输出y3,经过6层decoder layer之后,输出词的概率分布,计算损失,训练模型;
[0022]
y=ln(y selfatt(y)0#(6)
[0023]
y1=ln(y crossatt(y,g))#(7)
[0024]
y2=ln(y1 crossatt(y1,x))#(8)
[0025]
y3=ln(y2 ffn(y2))#(9)
[0026]
其中,ln是层归一化操作,selfatt是自注意力机制,crossatt是交叉注意力机制,ffn是前馈网络运算,y是解码器端上一层的输出向量,g是指导信号的向量表示,x是输入文档的向量表示,y1是在y的基础上融合了指导信号g的向量表示,y2是在y1的基础上融合了输入的文档向量x的向量表示,y3是解码器端decoder层的输出;
[0027]
5)训练完成后,将抽取式模型和生成式模型分别保存;
[0028]
6)生成摘要时将一段新闻文本先输入到抽取式模型中,抽取出模型认为的候选摘要,然后将候选摘要和新闻文本再输入至生成式模型,得到最终的摘要。
[0029]
本发明的有益效果为:结合了抽取式 生成式的摘要生成,互相弥补了各自的缺点,生成的摘要语义连贯,语句简短的同时保证了摘要与原文的事实一致性。
附图说明
[0030]
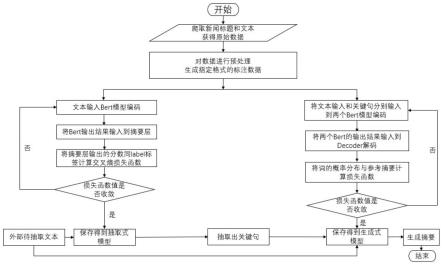
图1是基于深度学习的新闻文本摘要生成方法的逻辑流程图。
具体实施方式
[0031]
下面结合附图对本发明作进一步描述。
[0032]
参照图1,一种基于深度学习的新闻文本摘要生成方法,所述方法包括以下步骤:
[0033]
1)通过爬虫算法爬取新闻网站上的新闻标题和新闻文本,每一个新闻文本和新闻标题组成一个story文件,文本与标题之间用@highlight标识符分隔;
[0034]
2)将上述的story文件用stanford corenlp工具包进行分句分词,通过贪婪算法,选择出新闻文本中与标题句子rouge-1/2指标分数最高的前三个句子打上label标签,最后生成确定格式的标注文本作为训练数据和验证数据;
[0035]
3)文本摘要生成方法使用的是抽取 生成的策略,先使用抽取式模型从新闻文本抽取出与标题相关度高的句子,然后将抽取出来的句子作为指导信号作用于另外一个生成式模型,去指导摘要的生成;
[0036]
4)抽取式模型采用bert网络模型获取句子表示,inter-sentence transformer层作为摘要层,来对确定格式的标注文本作文本摘要抽取式的训练;同时,用另两个bert网络模型作为两个编码器,解码器采用transformer的decoder端,对输入文本和指导信号进行文本摘要生成式的训练,指导信号是打上label的关键句子,实现过程如下:
[0037]
4.1)给定token化的文本x=[cls,x1,x2,
…
,xn,sep]其中cls和sep是每个句子的句首和句尾插入的token,x
t
是文本t位置上的token,将文本x输入bert模型后,得到文本的隐藏表示h=[h1,h2,
……hm
],进一步获取每个句子句首的clstoken的隐藏表示t=[t1,t2,
…
t
t
];
[0038]
4.2)将隐藏表示t传输给由两层transformer encoder layer组成的摘要层,输出得到h
l
,然后经过一个sigmoid层,得到每个句子的分数y=[y1,y2,
…yn
],根据标注文本的label标签l=[l1,l2,
…
ln],然后使用二分类交叉熵损失函数对抽取式模型进行训练:
[0039][0040][0041]
yi=σ(w
ohl
bo)#(3)
[0042][0043]
ln=-[ln·
logyn (1-ln)
·
log(1-yn)]#(5)
[0044]
其中l表示transformer encoder layer的层数,mhatt是对transformer encoder layer层的输出h
l-1
做多头注意力运算,是经过层归一化操作ln之后的输出,然后对该输出做ffn前馈网络运算,生成第l层的输出向量h
l
,σ是sigmoid运算,wo是权重参数,bo是偏差,yi是第i个句子的预测分数,n是句子的个数,ln是第n个句子的标签,yn是第n个句子的预测分数;
[0045]
4.3)将token化的输入文本x=[x1,x2,
…
,xn]与token化的指导信号g=[g1,g2,
…
,gm]分别输入给生成式模型的两个编码器bert模型,分别得到隐藏表示h
x
=[h
x1
,h
x2
,
…
,h
xn
],hg=[h
g1
,h
g2
,
…
,h
gm
];
[0046]
4.4)生成式模型的解码器端首先对上一层的输出y做一次self attention操作,其次利用cross attention机制关注指导信号并生成相应表示y1,然后再经过一个cross attention层,根据y1来处理整个输入文本,得到表示y2,最后经过一个前馈网络层,得到中间输出y3,经过6层decoder layer之后,输出词的概率分布,计算损失,训练模型;
[0047]
y=ln(y selfatt(y))#(6)
[0048]
y1=ln(y grossatt(y,g))#(7)
[0049]
y2=ln(y1 grossatt(y1,x))#(8)
[0050]
y3=ln(y2 ffn(y2))#(9)
[0051]
其中,ln是层归一化操作,selfatt是自注意力机制,crossatt是交叉注意力机制,ffn是前馈网络运算,y是解码器端上一层的输出向量,g是指导信号的向量表示,x是输入文档的向量表示,y1是在y的基础上融合了指导信号g的向量表示,y2是在y1的基础上融合了输入的文档向量x的向量表示,y3是解码器端decoder层的输出;
[0052]
5)训练完成后,将抽取式模型和生成式模型分别保存;
[0053]
6)生成摘要时将一段新闻文本先输入到抽取式模型中,抽取出模型认为的候选摘要,然后将候选摘要和新闻文本再输入至生成式模型,得到最终的摘要。
[0054]
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。