1.本发明涉及大数据技术领域,具体的涉及一种基于模型组合的商品销量预测方法、装置及存储介质。
背景技术:
2.销量预测是零售业经营中的重要环节,但由于未来市场需求和销量来源等存在诸多不确定性,为企业销量预测提升了难度。企业进行销量预测的传统方法是基于人工经验估计,也可以称为专家法,这种专家法能够结合人的长时间积累的业务经验和逻辑判断能力。但是,完全依赖专家法有一定的局限性,人工经验可能存在偏见,忽略或放大某些影响销量的因素,并且专家法有较高的时间成本,无法对大量商品进行预测,预测的效果也参差不齐,进而导致了整个零售业供应链的效率低下。
3.随着机器学习的广泛应用,销量预测问题被定义为时间序列预测问题,通常采用传统时间序列模型,对单序列进行建模。由于在实际销售的过程中,销量会受到多种因素的影响,例如销售价格、商品特征、促销活动等,因此,树模型也是销量预测领域中常见的基础算法模型。但是,在实际应用场景中,销量预测问题通常包含线性和非线性时间序列的成分,单一的一种预测方法无法很好的捕获时间序列的复合特征,从而导致无法达到较高的销量预测准确性。
4.有鉴于此,特提出本发明专利。
技术实现要素:
5.本发明为了解决上述技术问题,提出了一种基于模型组合的商品销量预测方法、装置及存储介质,在模型建立过程中提出了时间序列模型与树模型组合的新方法,该方法能够合理准确的预测零售商门店中每种商品的销售数据,有利于减少需求的不确定性,合理安排补货量,减少库存成本,提高零售门店的利润。
6.本发明公开了一种基于模型组合的商品销量预测方法,具体技术方案如下:
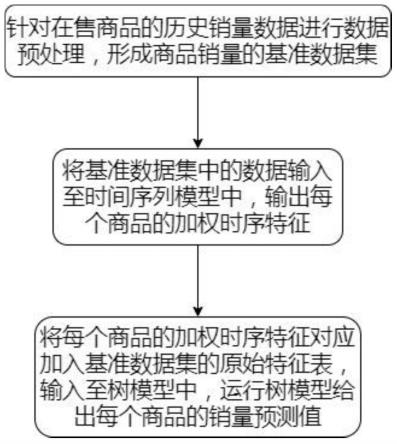
7.一种基于模型组合的商品销量预测方法,包括:
8.针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集;
9.将基准数据集中的数据输入至时间序列模型中,输出每个商品的加权时序特征;
10.将每个商品的加权时序特征对应加入基准数据集的原始特征表,输入至树模型中,运行树模型给出每个商品的销量预测值。
11.作为本发明的可选实施方式,所述时间序列模型的训练过程包括:
12.将基准数据集按照设定比例划分为训练数据集和测试数据集;
13.将训练数据集中每个商品的设定周期销量和对应的日期数据作为输入数据依次输入到prophet模型,将预测时期长度设置为测试数据集中该商品销量数据的长度;
14.运行prophet模型得到该商品全周期的销量拟合值;
15.可选地,可以将节假日的数据输入到prophet模型中辅助预测。
16.作为本发明的可选实施方式,本发明的一种基于模型组合的商品销量预测方法,包括:
17.将训练数据集中每个商品的设定周期销量和对应的日期特征输入到prophet模型,利用网格搜索找出每种商品销量数据的最佳的prophet模型参数;
18.得到每个商品对应的prophet模型最佳参数组合并保存,在预测不同的商品销量时调用对应的参数组合,进而运行prophet模型,得到该商品的销量拟合值;
19.可选地,所述prophet模型需要搜索的参数包括changepoint_prior_scale、seasonality_prior_scale和holidays_prior_scale,分别对应销量数据拐点灵敏度、季节性趋势灵敏度以及节假日效应灵敏度。
20.作为本发明的可选实施方式,所述树模型的训练过程包括:
21.以sku为单位,将prophet模型给出的趋势项、周期项、节假日项及残差项的拟合值分别输出pi;
22.根据不同需要设定四个拟合值的权重wi,将wi*p
it
的计算结果作为商品销量的时序特征加入到之前的训练数据集和测试数据集中,一同作为lightgbm模型的输入数据集;
23.运行所述lightgbm模型根据测试数据集给出每个商品的销量预测值。
24.作为本发明的可选实施方式,针对整个训练数据集进行lightgbm模型的参数寻优,所述lightgbm模型参数利用网格搜索进行优化;
25.将最优参数保存,在预测销量时调用该组参数进行模型构建和预测;
26.其中,所述lightgbm模型需要搜索的参数包括boosting_type(提升类型)、和/或num_leaves(叶子节点数)、和/或min_data_in_leaf(每个叶节点的最少样本数量)、和/或n_estimators(给出了boosted trees的数量)、和/或learning_rate(学习速率)、和/或feature_fraction(建树的特征选择比例)、和/或bagging_fraction(建树的样本采样比例)。
27.作为本发明的可选实施方式,所述prophet模型利用的特征为节假日数据;
28.所述lightgbm模型利用的特征包括销售日期(转化为年、季度、月、周、日五列数值特征)、和/或是否为周末(0-1变量)、和/或商品编码(商品唯一标识符)、和/或商品部类编码、和/或商品大类编码、和/或商品种类编码、和/或商品小类编码、和/或商品当日实际售价、和/或当日促销标志(0-1变量)、和/或节假日编码。
29.作为本发明的可选实施方式,所述针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集包括:
30.针对原始数据集进行清洗和结构化处理,删除重复订单和缺失订单,并针对订单级销售数据进行异常值处理;
31.将订单级别的销量数据以商品id和设定周期为粒度进行销售数据聚合,得到初始数据集;
32.从商品特征和日期特征方面进行指标选取与构建,得到宽表,并将拼接的宽表进行缺失值处理和异常值处理,得到新数据集;
33.按照一定的比例对新数据集进行划分,得到预测模型的训练数据集和测试数据集。
34.作为本发明的可选实施方式,所述针对订单级销售数据进行异常值处理包括:计
算设定周期某个商品所有单笔订单销量的均值μ1、标准差ε1以及99分位数q,将销量大于max{μ1 6ε1,q}的单笔订单视作异常订单,并予以剔除;
35.所述将订单级别的销量数据以商品id和设定周期为粒度进行销售数据聚合包括:将所有订单按商品和设定周期的聚合来获得每个商品设定周期的销量,并将聚合后的数据集按商品和日期排序;
36.所述缺失值处理是指将在某些日期没有销量的商品销量数据按日期补全,并将销量赋值为0;所述异常值处理是指首先计算每个商品日销量均值μ2和日销量标准差ε2,然后将日销量大于μ2 15ε2的日销量赋值为none(置空)。
37.本发明同时公开了一种基于模型组合的商品销量预测装置,具体技术方案如下:
38.一种基于模型组合的商品销量预测装置,包括,
39.数据预处理模块:针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集;
40.商品销量预测模块:将基准数据集中的数据输入至时间序列模型中,输出每个商品的加权时序特征;
41.将每个商品的加权时序特征对应加入基准数据集的原始特征表,输入至树模型中,运行树模型给出每个商品的销量预测值。
42.本发明同时还公开了一种存储介质,具体技术方案如下:
43.一种存储介质,存储有计算机可执行程序,所述计算机可执行程序被执行时,实现上述任意一项所述的一种基于模型组合的商品销量预测方法。
44.与现有技术相比,本发明的有益效果:
45.本发明的基于模型组合的商品销量预测方法可适用于零售商门店商品的销量预测,所述基于模型组合的商品销量预测方法采用新型的模型组合方法,将时间序列模型对每个商品进行趋势项、周期项、节假日项及残差项的拟合值和赋予的参数权重进行计算得到商品级别的时序特征,并将拟合值作为时序特征加入到原始特征表,输入到树模型中进行训练,实现时序模型与树模型的深度融合。因此,本发明基于模型组合的商品销量预测方法会根据商品的不同属性,分类寻找最优参数,得到精度较高的时间序列模型和树模型的组合模型,获得更准确的销量预测结果。
46.本发明提供了一种基于模型组合的商品销量预测方法,其中数据预处理阶段减少了销量预测过程中存在缺失值和极端值对预测误差的影响。通过数据维度变化、数据异常值处理、数据集成以及数据筛选,最终获取模型训练的基准数据集。
47.本发明实施例基于模型组合的商品销量预测方法中提供了一种零售商门店销售数据的预测模型p-lgb及其建立方法,从单个商品角度进行时序特征的拟合并融入到树模型中进行训练,采用系统的参数调优方法,得到了精准度高的p-lgb模型,该方法有效的提高了零售商门店销量数据预测的准确率。
48.因此,本发明的一种基于模型组合的商品销量预测方法构建的p-lgb模型的零售商门店商品的销量预测方法,使用零售门店的历史销售数据,通过数据预处理、模型组合以及参数调优实现门店销量预测。同时,可将预测结果按商品依次划分出来,用以指导零售门店销售和补货计划。
附图说明:
49.图1是本发明实施例公开的基于模型组合的商品销量预测方法的流程图;
50.图2是本发明实施例公开的基于模型组合的商品销量预测方法中预测模型建立的流程图;
51.图3是本发明实施例公开的零售商门店销量数据预测模型的一种参数优化流程图。
具体实施方式
52.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。
53.因此,以下对本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的部分实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
54.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征和技术方案可以相互组合。
55.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
56.在本发明的描述中,需要说明的是,术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,或者是本领域技术人员惯常理解的方位或位置关系,这类术语仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性。
57.参见图1及图3所示,本实施例提供了一种基于模型组合的商品销量预测方法,包括:
58.针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集;
59.将基准数据集中的数据输入至时间序列模型中,输出每个商品的加权时序特征;
60.将每个商品的加权时序特征对应加入基准数据集的原始特征表,输入至树模型中,运行树模型给出每个商品的销量预测值。
61.本实施例的基于模型组合的商品销量预测方法可适用于零售商门店商品的销量预测,所述基于模型组合的商品销量预测方法采用新型的模型组合方法,将时间序列模型对每个商品进行趋势项、周期项、节假日项及残差项的拟合值和赋予的参数权重进行计算得到商品级别的时序特征,并将拟合值作为时序特征加入到原始特征表,输入到树模型中进行训练,实现时序模型与树模型的深度融合。因此,本实施例基于模型组合的商品销量预测方法会根据商品的不同属性,分类寻找最优参数,得到精度较高的时间序列模型和树模型的组合模型,获得更准确的销量预测结果。
62.本实施例基于模型组合的商品销量预测方法基于新型模型组合方法建立的p-lgb模型:该模型由prophet模型和lightgbm模型两部分构成。
63.prophet是facebook开源的一个时间序列预测算法,主要由趋势项g(t)、季节项s(t)、节假日项h(t)和误差项组成,该模型基于时间序列分解和机器学习的拟合来预测未来时间序列的走势,适用于具有明显的内在规律的商业行为数据。prophet模型会基于输入的已知时间序列的时间戳和相应的标签值来输出未来给定的时间序列长度内的预测值,并且会同时给出预测值的置信区间,即合理的上下界。这类规范类似于广义可加模型(generalized additive model,gam),这是一种非线性的回归模型。
64.lightgbm算法由微软提出,主要用于解决gbdt在海量数据中遇到的问题,以便其可以更好更快地用于工业实践中。从lightgbm名字可以看出其是轻量级(light)的梯度提升机(gbm),具有训练速度快、内存占用低的特点。主要是通过gradient-based one-side sampling(goss)和exclusive feature bundling(efb)(基于梯度的one-side采样和互斥的特征捆绑)这两个方法来解决gbdt计算复杂度将受到特征数量和数据量双重影响,造成处理大数据时十分耗时的问题。
65.本实施例基于模型组合的商品销量预测方法在进行销量预测时,需要先针对prophet模型和lightgbm模型进行训练,构建出prophet模型和lightgbm模型组合的p-lgb模型,直接用于进行商品销量的预测。
66.参见图2所示,本实施例的一种基于模型组合的商品销量预测方法,所述时间序列模型的训练过程包括:
67.将基准数据集按照设定比例划分为训练数据集和测试数据集;
68.将训练数据集中每个商品的设定周期销量和对应的日期数据作为输入数据依次输入到prophet模型,将预测时期长度设置为测试数据集中该商品销量数据的长度;
69.运行prophet模型得到该商品全周期(即该商品在训练集和测试集中数据总长度)的销量拟合值。
70.本实施例将基准数据集划分为训练数据集和测试数据集,训练数据集用于模型训练,输出模型在测试集上的预测结果,进行结果检验。
71.可选地,可以将节假日的数据(包括节假日的标识和节假日的日期范围)输入到prophet模型中辅助预测。
72.进一步地,本实施例的一种基于模型组合的商品销量预测方法,包括:
73.将训练数据集中每个商品的设定周期销量和对应的日期特征输入到prophet模型,利用网格搜索找出每种商品销量数据的最佳的prophet模型参数;
74.得到每个商品对应的prophet模型最佳参数组合并保存,在预测不同的商品销量时调用对应的参数组合,进而运行prophet模型,得到该商品的销量拟合值。
75.可选地,所述prophet模型需要搜索的参数包括changepoint_prior_scale、seasonality_prior_scale和holidays_prior_scale,分别对应销量数据拐点灵敏度、季节性趋势灵敏度以及节假日效应灵敏度。
76.参见图2所示,作为本实施例的可选实施方式,本实施例的一种基于模型组合的商品销量预测方法中,所述树模型的训练过程包括:
77.以sku为单位,将prophet模型给出的趋势项、周期项、节假日项及残差项的拟合值分别输出pi;
78.根据不同需要设定四个拟合值的权重wi,将wi*p
it
的计算结果作为商品销量的时
序特征加入到之前的训练数据集和测试数据集中,一同作为lightgbm模型的输入数据集;
79.运行所述lightgbm模型根据测试数据集给出每个商品的销量预测值。
80.本实施例将prophet模型下计算出每个商品销量的拟合值作为商品销量的时序特征补充到原始特征宽表中,此时主要特征包括销售日期、节假日特征、商品编码特征、商品各级类别编码、商品售价、商品促销特征等。
81.作为本实施例的可选实施方式,本实施例的一种基于模型组合的商品销量预测方法,针对整个训练数据集进行lightgbm模型的参数寻优,所述lightgbm模型参数利用网格搜索进行优化;
82.将最优参数保存,在预测销量时调用该组参数进行模型构建和预测;
83.其中,所述lightgbm模型需要搜索的参数包括boosting_type(提升类型)、和/或num_leaves(叶子节点数)、和/或min_data_in_leaf(每个叶节点的最少样本数量)、和/或n_estimators(给出了boosted trees的数量)、和/或learning_rate(学习速率)、和/或feature_fraction(建树的特征选择比例)、和/或bagging_fraction(建树的样本采样比例)。
84.进一步地,本实施例的一种基于模型组合的商品销量预测方法,所述prophet模型利用的特征为节假日数据;
85.所述lightgbm模型利用的特征包括销售日期(转化为年、季度、月、周、日五列数值特征)、和/或是否为周末(0-1变量)、和/或商品编码(商品唯一标识符)、和/或商品部类编码、和/或商品大类编码、和/或商品种类编码、和/或商品小类编码、和/或商品当日实际售价、和/或当日促销标志(0-1变量)、和/或节假日编码。
86.优选地,lightgbm模型所使用的训练集并不需要进行缺失值补全。因为lightgbm模型并不要求商品销量数据在日期上是完整的,所以并不需要将不一定准确的补缺值作为lightgbm模型的训练,以保证lightgbm模型获得数据的准确性。
87.优选地,当零售门店的商品种类较多,并且商品存在多级分类的情况,可以选择在大类或者中类级别对lightgbm模型进行参数寻优。具体而言就是针对每一个大类或者中类的商品数据集,通过网格搜索进行lightgbm模型的参数寻优,然后保存每个类别下最佳的lightgbm模型参数组合,在预测时调用该参数组合来预测该类商品的销量。
88.零售门店在售商品的历史销量数据需要进行数据预处理,形成标准格式的、符合后续模型的对于输入数据质量要求的数据集。数据预处理包括异常订单处理、日销量聚合、缺失值处理、异常值处理以及数据集划分。
89.参见图2所示,作为本实施例的可选实施方式,本实施例的一种基于模型组合的商品销量预测方法,所述针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集包括:
90.针对原始数据集进行清洗和结构化处理,删除重复订单和缺失订单,并针对订单级销售数据进行异常值处理;具体地,采用python对原始数据集进行清洗和结构化处理,删除重复订单和缺失订单,并针对订单级销售数据进行异常值处理。
91.将订单级别的销量数据以商品id和设定周期为粒度进行销售数据聚合,得到初始数据集;为了实现设定周期以“天”为粒度的单商品销量预测,将订单级别的销量数据以商品id和“天”为粒度进行销售数据聚合,得到初始数据集。
92.从商品特征和日期特征方面进行指标选取与构建,得到宽表,并将拼接的宽表进行缺失值处理和异常值处理,得到新数据集;
93.按照一定的比例对新数据集进行划分,得到预测模型的训练数据集和测试数据集。可选地,将新数据集按照0.85:0.15的比例划分为训练数据集和测试数据集(构建和训练p-lgb模型需要进行数据集划分,实际预测时不需要该步骤)。
94.可选地,本实施例所述针对订单级销售数据进行异常值处理包括:计算设定周期某个商品所有单笔订单销量的均值μ1、标准差ε1以及99分位数q,将销量大于max{μ1 6ε1,q}的单笔订单视作异常订单,并予以剔除。
95.可选地,本实施例所述将订单级别的销量数据以商品id和设定周期为粒度进行销售数据聚合包括:将所有订单按商品和设定周期的聚合来获得每个商品设定周期的销量,并将聚合后的数据集按商品和日期排序。
96.可选地,本实施例所述缺失值处理是指将在某些日期没有销量的商品销量数据按日期补全,并将销量赋值为0;所述异常值处理是指首先计算每个商品日销量均值μ2和日销量标准差ε2,然后将日销量大于μ2 15ε2的日销量赋值为none(置空)。
97.本实施例基于模型组合的商品销量预测方法的预测结果处理:将预测结果按商品依次划分出来,用以指导零售门店销售和补货计划。
98.本发明实施例提供了一种基于模型组合的商品销量预测方法,其中数据预处理阶段减少了销量预测过程中存在缺失值和极端值对预测误差的影响。通过数据维度变化、数据异常值处理、数据集成以及数据筛选,最终获取模型训练的基准数据集。本发明实施例基于模型组合的商品销量预测方法中提供了一种零售商门店销售数据的预测模型p-lgb及其建立方法,从单个商品角度进行时序特征的拟合并融入到树模型中进行训练,采用系统的参数调优方法,得到了精准度高的p-lgb模型,该方法有效的提高了零售商门店销量数据预测的准确率。
99.因此,本发明的一种基于模型组合的商品销量预测方法构建的p-lgb模型的零售商门店商品的销量预测方法,使用零售门店的历史销售数据,通过数据预处理、模型组合以及参数调优实现门店销量预测。通过数据维度变化、数据异常值处理、数据集成以及数据筛选,形成模型训练的基准数据集;采用新型的模型组合方法,将prophet模型对每个商品进行趋势项、周期项、节假日项及残差项的拟合值和赋予的参数权重进行计算得到商品级别的时序特征,并将拟合值作为时序特征加入到原始特征表,输入到lightgbm的模型中进行训练,实现时序模型与树模型的深度融合。模型会根据商品的不同属性,分类寻找最优参数,得到精度较高的p-lgb模型,获得更准确的销量预测结果。
100.本实施例同时提供一种基于模型组合的商品销量预测装置,包括,
101.数据预处理模块:针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集;
102.商品销量预测模块包括:
103.时间序列模型模块,将基准数据集中的数据输入至时间序列模型模块中,输出每个商品的加权时序特征;
104.树模型模块,将每个商品的加权时序特征对应加入基准数据集的原始特征表,输入至树模型模块中,运行树模型给出每个商品的销量预测值。
105.本实施例的基于模型组合的商品销量预测装置可实现零售商门店商品的销量预测,所述基于模型组合的商品销量预测装置采用新型的模型组合方法,时间序列模型模块对每个商品进行趋势项、周期项、节假日项及残差项的拟合值和赋予的参数权重进行计算得到商品级别的时序特征,并将拟合值作为时序特征加入到原始特征表,输入到树模型模块中进行训练,实现时序模型与树模型的深度融合。因此,本实施例基于模型组合的商品销量预测装置会根据商品的不同属性,分类寻找最优参数,得到精度较高的时间序列模型和树模型的组合模型,获得更准确的销量预测结果。
106.本实施例基于模型组合的商品销量预测装置基于新型模型组合方法建立的p-lgb模型:该模型由prophet模型和lightgbm模型两部分构成。
107.prophet是facebook开源的一个时间序列预测算法,主要由趋势项g(t)、季节项s(t)、节假日项h(t)和误差项组成,该模型基于时间序列分解和机器学习的拟合来预测未来时间序列的走势,适用于具有明显的内在规律的商业行为数据。prophet模型会基于输入的已知时间序列的时间戳和相应的标签值来输出未来给定的时间序列长度内的预测值,并且会同时给出预测值的置信区间,即合理的上下界。这类规范类似于广义可加模型(generalized additive model,gam),这是一种非线性的回归模型。
108.lightgbm算法由微软提出,主要用于解决gbdt在海量数据中遇到的问题,以便其可以更好更快地用于工业实践中。从lightgbm名字可以看出其是轻量级(light)的梯度提升机(gbm),具有训练速度快、内存占用低的特点。主要是通过gradient-based one-side sampling(goss)和exclusive feature bundling(efb)(基于梯度的one-side采样和互斥的特征捆绑)这两个方法来解决gbdt计算复杂度将受到特征数量和数据量双重影响,造成处理大数据时十分耗时的问题。
109.本实施例基于模型组合的商品销量预测装置在进行销量预测时,需要先针对prophet模型和lightgbm模型进行训练,构建出prophet模型和lightgbm模型组合的p-lgb模型,直接用于进行商品销量的预测。
110.本实施例的一种基于模型组合的商品销量预测装置,包括时间序列模型训练模块,所述时间序列模型训练模块进行时间序列模型的训练过程包括:
111.将基准数据集按照设定比例划分为训练数据集和测试数据集;
112.将训练数据集中每个商品的设定周期销量和对应的日期数据作为输入数据依次输入到prophet模型,将预测时期长度设置为测试数据集中该商品销量数据的长度;
113.运行prophet模型得到该商品全周期(即该商品在训练集和测试集中数据总长度)的销量拟合值。
114.本实施例的一种基于模型组合的商品销量预测装置包括数据预处理模块,所述数据预处理模块将基准数据集按照设定比例划分为训练数据集和测试数据集。本实施例的数据预处理模块将基准数据集划分为训练数据集和测试数据集,训练数据集用于模型训练,输出模型在测试集上的预测结果,进行结果检验。
115.可选地,可以将节假日的数据(包括节假日的标识和节假日的日期范围)输入到prophet模型中辅助预测。
116.进一步地,本实施例的一种基于模型组合的商品销量预测装置,时间序列模型训练模块首先将训练集中每个商品的日销量和日期特征(节假日特征为主)输入到prophet模
型,利用网格搜索找出每种商品销量数据的最佳的prophet模型参数:
117.得到每个商品对应的prophet模型最佳参数组合并保存,在预测不同的商品销量时调用对应的参数组合,进而运行prophet模型,得到该商品的销量拟合值。
118.可选地,所述prophet模型需要搜索的参数包括changepoint_prior_scale、seasonality_prior_scale和holidays_prior_scale,分别对应销量数据拐点灵敏度、季节性趋势灵敏度以及节假日效应灵敏度。
119.作为本实施例的可选实施方式,本实施例的一种基于模型组合的商品销量预测装置中,所述树模型模块进行树模型训练过程包括:
120.以sku为单位,将prophet模型给出的趋势项、周期项、节假日项及残差项的拟合值分别输出pi;
121.根据不同需要设定四个拟合值的权重wi,将wi*p
it
的计算结果作为商品销量的时序特征加入到之前的训练数据集和测试数据集中,一同作为lightgbm模型的输入数据集;
122.运行所述lightgbm模型根据测试数据集给出每个商品的销量预测值。
123.本实施例将prophet模型下计算出每个商品销量的拟合值作为商品销量的时序特征补充到原始特征宽表中,此时主要特征包括销售日期、节假日特征、商品编码特征、商品各级类别编码、商品售价、商品促销特征等。
124.作为本实施例的可选实施方式,本实施例的一种基于模型组合的商品销量预测装置,树模型模块针对整个训练数据集进行lightgbm模型的参数寻优,所述lightgbm模型参数利用网格搜索进行优化;
125.将最优参数保存,在预测销量时调用该组参数进行模型构建和预测;
126.其中,所述lightgbm模型需要搜索的参数包括boosting_type(提升类型)、和/或num_leaves(叶子节点数)、和/或min_data_in_leaf(每个叶节点的最少样本数量)、和/或n_estimators(给出了boosted trees的数量)、和/或learning_rate(学习速率)、和/或feature_fraction(建树的特征选择比例)、和/或bagging_fraction(建树的样本采样比例)。
127.进一步地,本实施例的一种基于模型组合的商品销量预测装置,所述prophet模型利用的特征为节假日数据;
128.所述lightgbm模型利用的特征包括销售日期(转化为年、季度、月、周、日五列数值特征)、和/或是否为周末(0-1变量)、和/或商品编码(商品唯一标识符)、和/或商品部类编码、和/或商品大类编码、和/或商品种类编码、和/或商品小类编码、和/或商品当日实际售价、和/或当日促销标志(0-1变量)、和/或节假日编码。
129.优选地,lightgbm模型所使用的训练集并不需要进行缺失值补全。因为lightgbm模型并不要求商品销量数据在日期上是完整的,所以并不需要将不一定准确的补缺值作为lightgbm模型的训练,以保证lightgbm模型获得数据的准确性。
130.优选地,当零售门店的商品种类较多,并且商品存在多级分类的情况,可以选择在大类或者中类级别对lightgbm模型进行参数寻优。具体而言就是针对每一个大类或者中类的商品数据集,通过网格搜索进行lightgbm模型的参数寻优,然后保存每个类别下最佳的lightgbm模型参数组合,在预测时调用该参数组合来预测该类商品的销量。
131.零售门店在售商品的历史销量数据需要进行数据预处理,形成标准格式的、符合
后续模型的对于输入数据质量要求的数据集。数据预处理包括异常订单处理、日销量聚合、缺失值处理、异常值处理以及数据集划分。
132.作为本实施例的可选实施方式,本实施例的一种基于模型组合的商品销量预测装置,所述数据预处理模块针对在售商品的历史销量数据进行数据预处理,形成商品销量的基准数据集包括:
133.数据预处理模块针对原始数据集进行清洗和结构化处理,删除重复订单和缺失订单,并针对订单级销售数据进行异常值处理;具体地,采用python对原始数据集进行清洗和结构化处理,删除重复订单和缺失订单,并针对订单级销售数据进行异常值处理。
134.数据预处理模块将订单级别的销量数据以商品id和设定周期为粒度进行销售数据聚合,得到初始数据集;为了实现设定周期以“天”为粒度的单商品销量预测,将订单级别的销量数据以商品id和“天”为粒度进行销售数据聚合,得到初始数据集。
135.数据预处理模块从商品特征和日期特征方面进行指标选取与构建,得到宽表,并将拼接的宽表进行缺失值处理和异常值处理,得到新数据集;
136.数据预处理模块按照一定的比例对新数据集进行划分,得到预测模型的训练数据集和测试数据集。可选地,将新数据集按照0.85:0.15的比例划分为训练数据集和测试数据集(构建和训练p-lgb模型需要进行数据集划分,实际预测时不需要该步骤)。
137.可选地,本实施例所述数据预处理模块针对订单级销售数据进行异常值处理包括:计算设定周期某个商品所有单笔订单销量的均值μ1、标准差ε1以及99分位数q,将销量大于max{μ1 6ε1,q}的单笔订单视作异常订单,并予以剔除。
138.可选地,本实施例所述数据预处理模块将订单级别的销量数据以商品id和设定周期为粒度进行销售数据聚合包括:将所有订单按商品和设定周期的聚合来获得每个商品设定周期的销量,并将聚合后的数据集按商品和日期排序。
139.可选地,本实施例所述缺失值处理是指将在某些日期没有销量的商品销量数据按日期补全,并将销量赋值为0;所述异常值处理是指首先计算每个商品日销量均值μ2和日销量标准差ε2,然后将日销量大于μ2 15ε2的日销量赋值为none(置空)。
140.本实施例基于模型组合的商品销量预测装置的预测结果处理:将预测结果按商品依次划分出来,用以指导零售门店销售和补货计划。
141.本发明实施例提供了一种基于模型组合的商品销量预测装置,其中数据预处理阶段减少了销量预测过程中存在缺失值和极端值对预测误差的影响。通过数据维度变化、数据异常值处理、数据集成以及数据筛选,最终获取模型训练的基准数据集。本发明实施例基于模型组合的商品销量预测装置提供了一种零售商门店销售数据的预测模型p-lgb及其建立方法,从单个商品角度进行时序特征的拟合并融入到树模型中进行训练,采用系统的参数调优方法,得到了精准度高的p-lgb模型,该方法有效的提高了零售商门店销量数据预测的准确率。
142.因此,本发明的一种基于模型组合的商品销量预测装置构建的p-lgb模型的零售商门店商品的销量预测方法,使用零售门店的历史销售数据,通过数据预处理、模型组合以及参数调优实现门店销量预测。通过数据维度变化、数据异常值处理、数据集成以及数据筛选,形成模型训练的基准数据集;采用新型的模型组合方法,将prophet模型对每个商品进行趋势项、周期项、节假日项及残差项的拟合值和赋予的参数权重进行计算得到商品级别
的时序特征,并将拟合值作为时序特征加入到原始特征表,输入到lightgbm的模型中进行训练,实现时序模型与树模型的深度融合。模型会根据商品的不同属性,分类寻找最优参数,得到精度较高的p-lgb模型,获得更准确的销量预测结果。
143.本实施例同时还提供一种存储介质,存储有计算机可执行程序,其特征在于,所述计算机可执行程序被执行时,实现如上述任意一项所述的一种基于模型组合的商品销量预测方法。
144.本实施例还提供了一种电子设备,包括处理器和存储器,所述存储器用于存储计算机可执行程序,当所述计算机程序被所述处理器执行时,所述处理器执行所述一种基于模型组合的商品销量预测方法。
145.本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
146.以上实施例仅用以说明本发明而并非限制本发明所描述的技术方案,尽管本说明书参照上述的各个实施例对本发明已进行了详细的说明,但本发明不局限于上述具体实施方式,因此任何对本发明进行修改或等同替换;而一切不脱离发明的精神和范围的技术方案及其改进,其均涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
