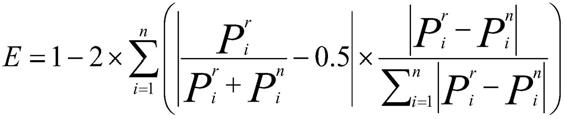
1.本发明涉及新能源技术领域,具体为一种分散式风电的功率预测方法。
背景技术:
2.分散式风电是指位于用电负荷中心附近,不以大规模远距离输送电力为目的,所产生的电力就近接入电网,并在当地消纳的风电项目,分散式风电场的功率预测结果精度提升技术,能够提升风机排列分散的风电场的短期、超短期功率预测精度,近年来获得了国内外科研单位的广泛关注。研究团队先期通过分散式风电场的功率预测结果精度提升技术课题的实施,开发了分散式风电场的功率预测系统。
3.本专利将围绕分散式风电场功率预测系统关键科学和技术问题开展研究。通过研究使用单风机预测、研究使用多种气象源及集合气象,与实测气象对比寻优、研究时间序列与神经网络模型相结合及时空模型、基于单机数据,研究分散式风电场多层高多气象要素的模拟测风技术等手段研究如何功率预测精度;最终获得分散式风电场的功率预测结果精度提升的关键技术。通过该课题的研究,为分散式风电场功率预测技术的应用提供参考,对推动风电场提高预测准确率具有重要意义。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术的不足,本发明提供了一种分散式风电的功率预测方法,具备通过研究使用单风机预测、研究使用多种气象源及集合气象,与实测气象对比寻优、研究时间序列与神经网络模型相结合及时空模型、基于单机数据,研究分散式风电场多层高多气象要素的模拟测风技术等手段研究如何功率预测精度;最终获得分散式风电场的功率预测结果精度提升的关键技术等优点,解决了上述提出的问题。
6.(二)技术方案
7.为实现上述通过以气象学和工程学原理为理论依据,通过接入风机机头风速仪、风向仪等的实时气象数据,结合数值计算和统计方法,从而得到全场范围内以及场内任意位置处各层高的实时气象数据,由于风范围较大的风电场,单一预测模型无法满足精度要求,因此通过考虑设计分区域预报模型,匹配具有代表性的风资源测量数据,分区域预报模型基于风机的分布,选择不同的区域,分别进行功率预测建模,最终获得分散式风电场的功率预测结果精度提升的关键技术的目的,本发明提供如下技术方案:一种分散式风电的功率预测方法,该预测方法的具体步骤为:
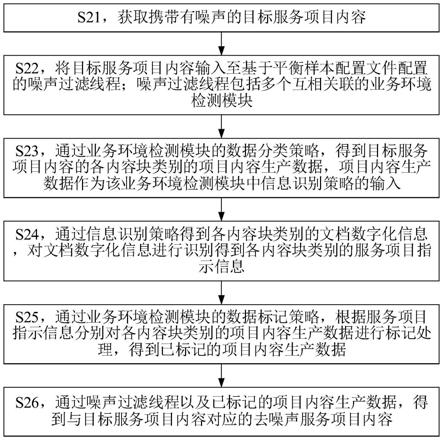
8.1)采集指定区域内风电场功率预测所需数据,通过各个风电场输出功率之间的相关性将区域内风电场分组;
9.2)根据历史观测气象数据和地形特点选定每组代表风电场,并在代表风电场选定虚拟测风塔位置;
10.3)通过步骤1中所得数据,建立代表风电场的功率预测模型,并计算出其短期预测
功率和超短期预测功率;
11.4)将各单机数据和步骤1中收集的预测所需数据进行整合,采用adaboost 算法进行组合式计算,对风电场的功率预测结果进行预测。
12.优选的,步骤1中的所需数据包括所有单台风机的风速历史数据、历史功率以及整场的平均风速数据、实际功率。
13.优选的,待步骤3中模型建立完毕,系统试运行后,现场需至少2周提供一次整场的平均风速数据、实际功率的数据。
14.优选的,步骤1中所需数据内包括的整场的平均风速数据、实际功率的时间分辨率为1min或者5min,当时间分辨率为10min时,需进行数据二次处理,由于会存在限电时段,所以需要现场提供手动限电记录。
15.优选的,步骤2中由于风机较为分散,考虑代表风电场,因此预测气象点应大于等于三处。
16.优选的,步骤3中的日预测曲线最大误差≤25%:
[0017][0018]
i是点数,n是96点,pni是第i点短期功率预测值,pri是第i点的实际功率;
[0019]
小时调和平均数准确率≥75%:
[0020][0021]
i是点数,n是96点,pni是第i点超短期功率预测值,pri是第i点的实际功率,通过以气象学和工程学原理为理论依据,通过接入风机机头风速仪、风向仪等的实时气象数据,结合数值计算和统计方法,从而得到全场范围内以及场内任意位置处各层高的实时气象数据。
[0022]
优选的,步骤4中的adaboost算法中,有两个权重,第一个是训练集中每个样本的权重,称为样本权重,用向量d表示;另一个是每一个弱学习算法具有一个权重,用向量α表示。
[0023]
假设有n个样本的训练集{(x1,y1),(x2,y2),...,(x
n
,y
n
)},初始时,设定每个样本的权重是相等的,即1/n,利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计:
[0024][0025]
其中,#error表示被错误分类的样本数目,#all表示所有样本的数目,这样便可以利用错误率ε计算弱学习算法h1的权重:
[0026][0027]
在第一次学习完成后,需要重新调整样本的权重,以使得在第一次分类中被错分权重的样本,在接下来的学习中可以重点对其进行学习:
[0028][0029]
其中,h
t
(x
i
)=y
i
表示对第i个样本训练正确,h
t
(x
i
)≠y
i
表示对第i个样本训练错误。zt是一个归一化因子:
[0030]
z
t
=sum(d)
[0031]
这样进行第二次的学习,当学习t轮后,得到了t个弱学习算法{h1,h2,....,h
t
} 及其权重{α1,α2,....,α
t
},对新的分类数据,分别计算t个弱分类器 {h1(x),h2(x),....,h
t
(x)},最终的adaboost算法的输出结果为:
[0032][0033]
其中,sign(x)是符号函数,adaboost算法是基于boosting思想的机器学习算法,其中,adaboost是adaptive boosting(自适应增强)的缩写, adaboost是一种迭代型的算法,其核心思想是针对同一个训练集训练不同的学习算法,即弱学习算法,然后将这些弱学习算法集合起来,构造一个更强的最终学习算法,为了构造出一个强的学习算法,首先需要选定弱学习算法,并利用同一个训练集不断训练弱学习算法,以提升弱学习算法的性能。
[0034]
优选的,adaboost算法中组合了四种单体方法,即bp神经网络、grnn 神经网络、elm极限学习机和orpc优化回归功率曲线,根据风机数据和虚拟测风数据的相关性,来校验虚拟测风数据的准确性,实时测风系统的实测数据在对虚拟测风数据进行评估中起到了非常关键的作用,为虚拟测风修订和参数调整提供了重要依据,实现了虚拟测风数据的优化,提升了准确度,减少了功率预测系统的误差,从而整体提高功率预测精度,由于风范围较大的风电场,单一预测模型无法满足精度要求,因此通过考虑设计分区域预报模型,匹配具有代表性的风资源测量数据,分区域预报模型基于风机的分布,选择不同的区域,分别进行功率预测建模,最终获得分散式风电场的功率预测结果精度提升的关键技术。
[0035]
(三)有益效果
[0036]
与现有技术相比,本发明提供了一种分散式风电的功率预测方法,具备以下有益效果:
[0037]
1、该分散式风电的功率预测方法,通过以气象学和工程学原理为理论依据,通过接入风机机头风速仪、风向仪等的实时气象数据,结合数值计算和统计方法,从而得到全场范围内以及场内任意位置处各层高的实时气象数据。
[0038]
2、该分散式风电的功率预测方法,由于风范围较大的风电场,单一预测模型无法满足精度要求,因此通过考虑设计分区域预报模型,匹配具有代表性的风资源测量数据,分区域预报模型基于风机的分布,选择不同的区域,分别进行功率预测建模,最终获得分散式风电场的功率预测结果精度提升的关键技术。
具体实施方式
[0039]
下面将结合本发明的实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明
中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0040]
一种分散式风电的功率预测方法,该预测方法的具体步骤为:
[0041]
1)采集指定区域内风电场功率预测所需数据,通过各个风电场输出功率之间的相关性将区域内风电场分组;
[0042]
2)根据历史观测气象数据和地形特点选定每组代表风电场,并在代表风电场选定虚拟测风塔位置;
[0043]
3)通过步骤1中所得数据,建立代表风电场的功率预测模型,并计算出其短期预测功率和超短期预测功率;
[0044]
4)将各单机数据和步骤1中收集的预测所需数据进行整合,采用adaboost 算法进行组合式计算,对风电场的功率预测结果进行预测,组合预测相对于单体预测具有更高的预测性能和出现极端预测误差的更小风险。
[0045]
步骤1中的所需数据包括所有单台风机的风速历史数据、历史功率以及整场的平均风速数据、实际功率;待步骤3中模型建立完毕,系统试运行后,现场需至少2周提供一次整场的平均风速数据、实际功率的数据;步骤1中所需数据内包括的整场的平均风速数据、实际功率的时间分辨率为1min或者 5min,当时间分辨率为10min时,需进行数据二次处理,由于会存在限电时段,所以需要现场提供手动限电记录;步骤2中由于风机较为分散,考虑代表风电场,因此预测气象点应大于等于三处;步骤3中的日预测曲线最大误差≤25%:
[0046][0047]
i是点数,n是96点,pni是第i点短期功率预测值,pri是第i点的实际功率;
[0048]
小时调和平均数准确率≥75%:
[0049][0050]
i是点数,n是96点,pni是第i点超短期功率预测值,pri是第i点的实际功率,通过以气象学和工程学原理为理论依据,通过接入风机机头风速仪、风向仪等的实时气象数据,结合数值计算和统计方法,从而得到全场范围内以及场内任意位置处各层高的实时气象数据,由于风范围较大的风电场,单一预测模型无法满足精度要求,因此通过考虑设计分区域预报模型,匹配具有代表性的风资源测量数据,分区域预报模型基于风机的分布,选择不同的区域,分别进行功率预测建模,最终获得分散式风电场的功率预测结果精度提升的关键技术;步骤4中的adaboost算法中,有两个权重,第一个是训练集中每个样本的权重,称为样本权重,用向量d表示;另一个是每一个弱学习算法具有一个权重,用向量α表示。
[0051]
假设有n个样本的训练集{(x1,y1),(x2,y2),...,(x
n
,y
n
)},初始时,设定每个样本的权重是相等的,即1/n,利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计:
[0052][0053]
其中,#error表示被错误分类的样本数目,#all表示所有样本的数目,这样便可以
利用错误率ε计算弱学习算法h1的权重:
[0054][0055]
在第一次学习完成后,需要重新调整样本的权重,以使得在第一次分类中被错分权重的样本,在接下来的学习中可以重点对其进行学习:
[0056][0057]
其中,h
t
(x
i
)=y
i
表示对第i个样本训练正确,h
t
(x
i
)≠y
i
表示对第i个样本训练错误。zt是一个归一化因子:
[0058]
z
t
=sum(d)
[0059]
这样进行第二次的学习,当学习t轮后,得到了t个弱学习算法{h1,h2,....,h
t
} 及其权重{α1,α2,....,α
t
},对新的分类数据,分别计算t个弱分类器 {h1(x),h2(x),....,h
t
(x)},最终的adaboost算法的输出结果为:
[0060][0061]
其中,sign(x)是符号函数,adaboost算法是基于boosting思想的机器学习算法,其中,adaboost是adaptive boosting(自适应增强)的缩写, adaboost是一种迭代型的算法,其核心思想是针对同一个训练集训练不同的学习算法,即弱学习算法,然后将这些弱学习算法集合起来,构造一个更强的最终学习算法,为了构造出一个强的学习算法,首先需要选定弱学习算法,并利用同一个训练集不断训练弱学习算法,以提升弱学习算法的性能,该 adaboost算法中组合了四种单体方法,即bp神经网络、grnn神经网络、elm 极限学习机和orpc优化回归功率曲线,根据风机数据和虚拟测风数据的相关性,来校验虚拟测风数据的准确性,实时测风系统的实测数据在对虚拟测风数据进行评估中起到了非常关键的作用,为虚拟测风修订和参数调整提供了重要依据,实现了虚拟测风数据的优化,提升了准确度,减少了功率预测系统的误差,从而整体提高功率预测精度。
[0062]
本发明的有益效果是:该分散式风电的功率预测方法,通过以气象学和工程学原理为理论依据,通过接入风机机头风速仪、风向仪等的实时气象数据,结合数值计算和统计方法,从而得到全场范围内以及场内任意位置处各层高的实时气象数据,由于风范围较大的风电场,单一预测模型无法满足精度要求,因此通过考虑设计分区域预报模型,匹配具有代表性的风资源测量数据,分区域预报模型基于风机的分布,选择不同的区域,分别进行功率预测建模,最终获得分散式风电场的功率预测结果精度提升的关键技术,根据风机数据和虚拟测风数据的相关性,来校验虚拟测风数据的准确性,实时测风系统的实测数据在对虚拟测风数据进行评估中起到了非常关键的作用,为虚拟测风修订和参数调整提供了重要依据,实现了虚拟测风数据的优化,提升了准确度,减少了功率预测系统的误差,从而整体提高功率预测精度;组合预测相对于单体预测具有更高的预测性能和出现极端预测误差的更小风险。
[0063]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以
理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。