1.本发明涉及一种文本分类方法,特别是一种基于有监督对比学习的细粒度文本分类方法。
背景技术:
2.细粒度文本分类需要区分出具有细微差别的类间关系,比如在细粒度情感分类中不仅需要区分情感类别而且需要区分出情感强度。因此不仅需要区分褒义、贬义这2种类别,而且需要区分出褒义和贬义的程度,因此每个类别又会划分为情感的一般表达和极度描述,比如针对褒义继续划分为一般褒义和极度褒义。
3.本文所要解决的是因为类别间具有层级关系导致的细粒度文本分类问题,因为类别是分层的树状结构,底层的叶子类别往往具有相同的父类别,比如类别“敌对-口头-拒绝”和类别“敌对-口头-反对”具有相同的父类别“敌对-口头”,只有叶子类别不同,因为具有相同的父类别这会导致不同类别的文本之间语义上十分相似,针对该问题不仅要区分样本所属类别,而且应该区分出样本之间语义的不同。
4.针对普通文本分类问题,现有的解决方法是通过预训练语言模型bert得到文本的向量表示,然后利用交叉熵损失函数进行微调。但是交叉熵损失函数对于细粒度分类并不合适,因为交叉熵损失的排他性会同等看待每个类别,比如将一个原本一般褒义的样本错分极度褒义和极度贬义在损失函数上并没有不同,但实际上一般褒义的样本和极度褒义的样本语义距离更近于极度贬义,而对比学习恰恰是解决这种问题,他能保证针对当前样本距离正例的距离近于负例。因此我们引入了有监督对比损失进行联合训练,针对当前样本合理的设计正负例,对比损失可以保证当前样本距离正例的距离近于负例的距离。
技术实现要素:
5.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于有监督对比学习的细粒度文本分类方法。
6.为了解决上述技术问题,本发明公开了一种基于有监督对比学习的细粒度文本分类方法,包括以下步骤:
7.步骤1,构建文本分类模型,并定义层级分类体系,细粒度刻画类别;
8.步骤2,选取样本,并对于每个样本合理构建正负例,进行数据增广;
9.步骤3,基于交叉熵损失和对比损失对文本分类模型进行联合训练,实现细粒度文本分类。
10.本发明中,步骤1包括:
11.定义层级分类体系,刻画类别之间的层次化关系,不同层次的标签之间通过符号-隔开,通过定义该标签希望为政治、军事、外交等领域的新闻提供文档级的分类功能。
12.本发明中,步骤2包括:
13.从文本数据集中选取一批样本作为训练样本,即定义批处理内的样本个数为k,该
批处理batch内正样本集合为p,负样本集合为n,定义该批处理batch内的样本xi及其标签yi为集合{xi,yi}
i∈i
,其中集合i={1,
…
,k};
14.步骤2-1,构建训练数据集;
15.步骤2-2,正负例构建;
16.步骤2-3,基于随机词替换的数据增广。
17.本发明中,步骤2-1包括:
18.对于选取的样本,构建训练语料;所述训练语料包括文章标题、文章内容和文章的层级分类标签;
19.对训练语料进行预处理;所述预处理包括:将繁体字转换为简体字,全角数字和全角字母转为半角数字和半角字母;
20.将文章标题与正文采用句号拼接起来,判断长度是否超过预设的长度阈值;如果没有超过,将拼接结果作为文章;如果超过预设的长度阈值,对文章进行截断处理,将截断后的内容作为文章;
21.对每个样本进行上述操作得到训练数据集。
22.本发明中,步骤2-2所述正负例构建方法包括:
23.针对步骤2-1得到的每个训练数据集中的数据,即每个训练样本xi,其正例定义为具有相同类别标签的样本及其增广后的样本,负例定义为不同类别标签的样本及其增广后的样本:
24.p={p:p∈i,y
p
=yi∧p≠i}
25.n={p:p∈i,y
p
≠yi}
26.其中,i表示所有样本下标集合,p为集合i中的元素,y
p
为其对应的标签,yi表示样本xi的类别,p表示样本xi的正样本集合,n表示其负样本集合;
27.步骤2-3所述基于随机词替换的数据增广方法包括:
28.对步骤2-2中经过正负例构建的训练数据集中的数据利用jieba分词器进行分词,并随机选择如下4种替换方式:
29.替换方式1,同义词替换:随机选择n个单词,对于选中的每个单词利用同义词进行替换;
30.替换方式2,随机插入:句子中随机选择1个单词,查找到其同义词,将该同义词插入到句子随机一个位置,该过程重复n次;
31.替换方式3,随机替换:句子中随机选择两个单词,然后相互交换位置,该过程重复n次;
32.替换方式4,随机删除:针对句子中每个单词依概率p进行删除,总计删除的单词个数记作m;
33.m=p(del)l
34.其中,l表示句子长度,p(del)表示每个位置做单词删除的概率;
35.经过替换后得到数据增广后的训练数据集。
36.本发明中,步骤3包括:
37.步骤3-1,通过bert编码得到语义向量;
38.步骤3-2,计算对比损失拉近同类别样本距离;
39.步骤3-3,计算文本分类交叉熵损失;
40.步骤3-4,构建联合损失函数,对文本分类模型进行联合训练,实现细粒度文本分类。
41.本发明中,步骤3-1所述通过bert编码(bert就是一种文本编码方法,bert:pre-training of deep bidirectional transformers for language understanding)得到语义向量,方法包括:
42.对于数据增广后的训练样本通过bert分词号首位添加两个特殊标记[cls]和[eos],标记为:
[0043]
xi=[cls],t1,t2,
…
,t
l
,[eos]
[0044]
其中l为文档长度,对于该样本序列xi经过bert特征抽取后的向量标记为hi;
[0045]
本发明中,步骤3-2所述计算对比损失拉近同类别样本距离l
cl
,方法包括:
[0046][0047]
其中,i是取值为1至k的自然数,xi表示增广后批处理内每个样本;τ是取值0到1之间的温度参数,h
p
表示当前样本的正样本x
p
经过bert编码后的向量表示,hi是当前样本xi经过bert编码号的向量归一化后的表示,k是集合中去除当前训练样本i以后的其他训练样本,hk是其bert语义编码。
[0048]
本发明中,步骤3-3所述计算文本分类交叉熵损失的方法包括:
[0049]
对于经过增广后的样本xi计算交叉熵损失l
ce
,方法包括:
[0050][0051]
其中,c表示类别个数,y
i,c
是样本真实标签,是模型输出,表示样本xi于类别c的概率。
[0052]
本发明中,步骤3-4中所述构建联合损失函数l的方法包括:
[0053]
l=(1-λ)l
ce
λl
cl
[0054]
其中,λ是超参数,控制两个损失函数的比重。
[0055]
有益效果:
[0056]
针对细粒度文本分类的实际需求,定义层级分类体系;为了区分细粒度文本分类,引入基于对比学习的损失函数;为了构建样本的正例,提出了一种基于随机替换的数据增广方式;提出一种基于对比损失和交叉熵损失相结合的细粒度文本分类方法,引入了对比学习的思想解决细粒度文本分类问题,保证同类别样本较近的语义距离。
附图说明
[0057]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0058]
图1为本发明方法流程图。
具体实施方式
[0059]
本发明首先定义关注的文本类型,并定义层级的分类体系;对样本利用随机替换的思想进行数据增广;针对给定样本合理的定义正负例,其中同类别的样本及其增广样本作为正例,其他类别的样本作为负例;通过合理的定义正负例,利用对比学习的思想保证同类别样本语义距离近于不同类别的样本,从而解决因为类别层级关系导致的细粒度分类问题。
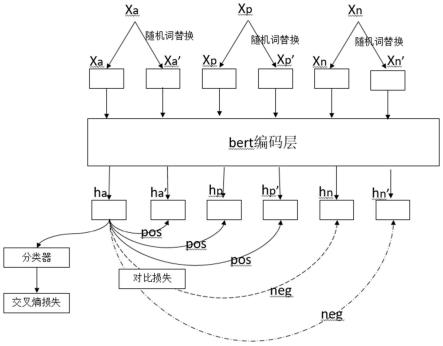
[0060]
如图1所示,首先对训练样本xa构建正例x
p
和负例xn,然后各自通过随机词替换,便构成了5个样本对,其中x
a’,x
p
,x
p’构成xa的正例,xn和x
n’构成xa的负例。利用这5个样本对进行对比损失训练。同时xa经过分类器进行文本分类。本发明提供了一种基于有监督对比学习的细粒度文本分类方法,具体包括如下步骤:
[0061]
步骤1主要定义层级分类体系,刻画类别之间的层次化关系,如“协作-口头-表达意愿-实质合作”,不同层次的标签之间通过
“‑”
隔开,通过定义该标签希望为政治、军事、外交等领域的新闻提供文档级的分类功能;
[0062]
步骤2包括:
[0063]
定义batch内的样本个数为k,该batch内正样本集合为p,负样本集合为n,定义该batch内的样本及其标签为集合{xi,yi}
i∈i
,其中i={1,
…
,k}
[0064]
步骤2-1:构建训练数据集,包括如下步骤:
[0065]
采集训练语料,所述训练语料包括文章标题、文章内容、文章的层级分类标签;
[0066]
对训练语料进行预处理,所述预处理包括:将繁体字转换为简体字,全角数字和全角字母转为半角数字和半角字母;
[0067]
将文章标题与正文采用句号拼接起来,判断长度是否超过预设的长度阈值;如果没有超过,将拼接结果作为文章;如果超过预设的长度阈值,对文章进行截断处理,将截断后的内容作为文章;
[0068]
步骤2-2:基于随机词替换的数据增广
[0069]
首先对原始样本利用jieba进行分词,随机选择如下4中替换方式:
[0070]
同义词替换:随机选择n个单词,对于选中的每个单词利用同义词进行替换;
[0071]
随机插入:句子中随机选择1个单词,然后查找到其同义词,然后将该同义词插入到句子随机一个位置,该过程重复n次;
[0072]
随机替换:句子中随机选择两个单词,然后相互交换位置,该过程重复n次;
[0073]
随机删除:针对句子中每个单词依概率p进行删除。
[0074]
其中l表示句子长度,p表示每个位置做单词删除的概率。
[0075]
n=pl
[0076]
步骤2-3:正负例构建:
[0077]
针对每个样本xi,其正例定义为具有相同类别标签的样本及其增广后的样本,负例定义为不同类别标签的样本及其增广后的样本。
[0078]
p={p:p∈i,y
p
=yi∧p≠i}
[0079]
n={p:p∈i,y
p
≠yi}
[0080]
步骤3包括:
[0081]
步骤3-1:bert编码向量
[0082]
对于原始文档经过bert分词号首位添加两个特殊标记[cls]和[eos],标记为
[0083]
xi=[cls],t1,t2,
…
,t
l
,[eos]
[0084]
其中l为文档长度,对于该序列xi经过bert特征抽取后的向量标记为hi[0085]
步骤3-2:对比损失拉近同类别样本距离:
[0086][0087]
其中i表示batch内每个样本xi,batch大小原本为k,因为每个样本做了数据增广,所以batch大小变为2k。τ是取值(0,1)的温度参数参数,针对难以区分的负样本来说,网络原本输出值较大,如果该温度参数取值较大会降低该负样本的权重,反之该参数取值越小会相应增加难于区分的负样本的权重,从而产生更多难以区分的负样本;hi是当前样本xi经过bert编码号的向量归一化后的表示。
[0088]
步骤3-3:文本分类交叉熵损失
[0089]
对于样本xi计算交叉熵损失,
[0090][0091]
其中c表示类别个数,y
i,c
是样本真实标签,是模型输出样本i属于类别c的概率;
[0092]
步骤3-4:联合损失函数
[0093]
l=(1-λ)l
ce
λl
cl
[0094]
其中λ是超参数,控制两个损失函数的比重。
[0095]
实施例:
[0096]
如下两个样本属于两种不同类别,但因为两者类别之间有交叉,所以导致两者具有相同的语义表达,普通文本分类在这种语义接近的文本上表达效果很差。
[0097]
样本1:韩联社报道称,在美国华盛顿接受韩国媒体采访时,正在访问美国的xxx表示,“我还是理解不了(xx等人的抗议)”,并拒绝向日本方面道歉
[0098]
样本1标签:敌对-口头-拒绝
[0099]
样本2:xxx说,伊朗拒绝了xxx提出的访问德黑兰的要求,并表示调停人之一是xxxx
[0100]
样本2标签:敌对-口头-拒绝交流"
[0101]
按照步骤2构建样本的正负例,其正样本构建为从同类别中随机选择一个,以样本1为例其正例为“敌对-口头-拒绝”随机选择一个样本,负例为除“敌对-口头-拒绝”之外的任意一个其他类别中选择一例。然后对于正负例及其自身进行数据增广,形成增广后的样本。按照步骤3进行交叉熵损失和对比学习损失的联合训练。
[0102]
本发明提供了一种基于有监督对比学习的细粒度文本分类方法的思路及方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均
可用现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
