1.本发明属于氮氧化物治理领域,具体涉及一种基于聚类分析耦合神经网络预测的不良数据辨识方法。
背景技术:
2.随着物联网、机器学习、大数据分析等技术的发展,基于scr脱硝系统大数据分析的脱硝系统智能调控、催化剂管理等研究日益增多。然而,由于scr脱硝系统大数据采集过程中存在的测量误差、设备故障、传输故障等问题,原始样本中往往包含一些不良数据。这些不良数据不仅干扰脱硝系统控制,同时对于基于大数据分析的智能调控、催化剂管理造成了许多不利影响,限制这些技术的推广应用。因此,如何对不良数据进行辨识对于scr脱硝系统的稳定高效运行具有重要意义。
3.传统的不良数据辨识方法主要有物理判别法和数理统计法,物理判别法是基于人们对数据已知的客观认识,判断外界干扰、人为误差等对实测数据偏离正常值的方法,但由于scr脱硝系统产生的数据量大,人工判断工作量大且需要操作者具有丰富经验使得该方法实施难度较大。数理统计法是通过数理统计理论对不良数据进行鉴别,但由于scr脱硝技术发展较晚,目前鲜有对scr脱硝系统数据数理统计的研究,缺乏合适数理统计模型的指导,对不良数据鉴别的准确性难以保证。因此,亟需提出和发展有效的scr脱硝系统不良数据的检测与辨识方法。
技术实现要素:
4.本发明的目的在于克服现有技术的缺乏,提供一种基于聚类分析耦合神经网络预测的不良数据辨识方法。
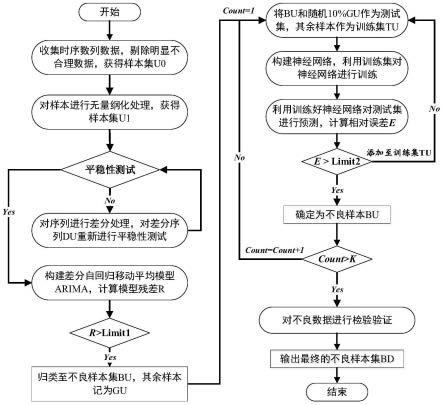
5.该方法首先通过对scr脱硝系统数据进行聚类分析,然后利用聚类后的样本分别进行神经网络建模和测试,通过计算测试样本预测值和初始值的相对误差大小鉴别不良样本;针对鉴别出的不良样本,进一步优化神经网络对不良样本进行检验和校正,并最终确定不良数据。
6.为了实现上述目的,达到上述技术效果,本发明通过以下技术方案实现:一种基于聚类分析耦合神经网络预测的不良数据辨识方法,其特征在于,包括以下步骤:
7.步骤1、获取烟气脱硝系统采集的原始数据,对原始数据进行无量纲化处理,记作样本集;
8.步骤2、从样本集随机选取k个样本作为k个聚类中心;
9.步骤3、计算样本集中每个样本与所述k个聚类中心的距离,将每个样本归类于与其距离最小的聚类中心所表示的类,直至完成样本集所有样本的分类,得到k个聚类样本集;
10.步骤4、按设定公式重新计算k个聚类中心,计算聚类中心与原聚类中心的距离;
11.步骤5、重复执行所述步骤3和所述步骤4直至满足预设条件一;
12.步骤6、构建bp神经网络;
13.步骤7、通过交叉验证法依次从所述k个聚类样本集中选择一个聚类样本集作为测试样本,其余聚类样本集作为训练样本进行神经网络训练,对测试样本进行预测,根据预设条件二将测试样本重新划归至不良样本集或训练样本集;
14.步骤8、对不良样本集进行检验和校正,确定最终不良数据。
15.优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤1所述的每个原始数据至少包含2个以上参数,且至少包含参数:出口no
x
浓度、脱硝效率或催化剂活性中的至少一个作为其标签参数。
16.优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤1所述的无量纲化方法采用下述公式1~3中任意之一计算:
[0017][0018][0019][0020]
式中,z
ni
为参数z的归一化值,zi为参数z的原始值,z
max
为参数z的最大值,z
min
为参数z的最小值,σ为参数z的标准差,μ为参数z的平均值。
[0021]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤2中的k值为所述参数总量的1~3倍。
[0022]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤3所述的距离公式为:
[0023][0024]
式中,d
ij
表示样本i和样本j之间的距离,z
ik
为样本i的参数k取值,n为单个样本的参数总数。
[0025]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤4所述的设定公式如下:
[0026][0027]
式中,zk为第k个聚类样本集的聚类中心,z
ki
为聚类样本集k中样本i,n为聚类样本集k中的样本总数。
[0028]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤5预设条件一为所有k个聚类中心与原聚类中心之间的距离小于0.001或者步骤5重复执行次数不少于k值的3倍。
[0029]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤6所述的bp神经网络采用输入层、单隐含层和输出层的三层网络拓扑结构;隐含层和输出层的激活函数采用sigmoid函数或者双曲正切函数。
[0030]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤7所述的预设条件是指相对误差小于10%划归至训练样本,否则划归至不良样本。
[0031]
优选的,前述一种基于聚类分析耦合神经网络预测的不良数据辨识方法,步骤8所述的检验和校正步骤如下:
[0032]
1)删除不良样本,利用优化样本构建并训练bp神经网络,利用训练好的神经网络对不良样本进行测试,计算相对误差;
[0033]
2)筛选出相对误差不小于10%的样本确认为不良数据;筛选出相对误差不大于5%的样本修正为非不良数据;
[0034]
3)对所述步骤2)中所述筛选后的剩余样本重复执行所述步骤1)和所述步骤2)直至满足以下任一条件:
[0035]
条件ⅰ、执行所述步骤2)之后无剩余样本;
[0036]
条件ⅱ、重复执行次数不少于3次;
[0037]
4)将剩余样本全部确认为不良数据。
[0038]
本发明的有益效果为:
[0039]
1、scr烟气脱硝大数据采集及分析研究较少,目前对其样本参数数理统计分布和组成尚不清晰,聚类分析算法可以在不清楚数据所属类别特征,提炼数据之间的内在联系并将其划分为不同特征样本集,从而尽可能将不良样本划归至同一样本集,为后续的不良样本鉴别提供指导。
[0040]
2、神经网络模型具有强大的非线性拟合和泛化能力,通过多次构建和训练bp神经网络对聚类样本集进行测试,其一减小了神经网络训练过程中不良数据对训练结果的影响,其二避免了神经网络训练和测试的随机性,减小了计算量。
[0041]
3、通过优化样本构建和训练bp神经网络对所辨识的不良样本进行检验和校正,避免了不良样本的误判,提高了准确性。
附图说明
[0042]
图1为本发明方法的操作流程图。
具体实施方式
[0043]
下面结合附图和具体实施例对本发明做进一步说明。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0044]
本实施例以某燃煤电厂scr脱硝系统一年的正常运行数据为例,通过人为添加不良数据,使用本发明的方法对这些样本中的不良数据进行检测。
[0045]
实施例1
[0046]
一种基于聚类分析耦合神经网络预测的不良数据辨识方法,如图1所示,其具体实施步骤如下:
[0047]
步骤1、从scr脱硝系统收集的准确运行原始数据样本u0共计1000组,每组样本包括入口压力、入口烟气量、入口no
x
浓度、喷氨量、烟气温度、出口压力、出口no
x
浓度、脱硝效率、氨逃逸浓度、scr脱硝催化剂活性共计10个参数,从原始数据样本u0随机选取50组样本,人为添加其值10%的误差作为不良样本,对处理后样本按以下公式(1)进行无量纲化处理,
记为样本集u1:
[0048][0049]
式中,z
ni
为参数z的归一化值,zi为参数z的原始值,z
max
为参数z的最大值,z
min
为参数z的最小值;
[0050]
步骤2、从原始数据样本随机选取20个样本作为聚类中心ai,i=1,2,
……
,20;
[0051]
步骤3、按公式(2)计算其余样本与聚类中心的距离,将样本划归至与其最近的聚类中心所表示的聚类样本集,完成20个聚类样本集的划分,记为聚类样本集uki,i=1,2,
……
,20:
[0052][0053]
式中,d
ij
表示样本i和样本j之间的距离,z
ik
为样本i的参数k取值,n为单个样本的参数总数;
[0054]
步骤4、按公式(3)重新计算20个聚类样本集的聚类中心bi,i=1,2,
……
,20,按公式(2)计算新旧聚类中心的距离di,i=1,2,
……
,20;
[0055][0056]
式中,bk为第k个聚类样本集uk的聚类中心,z
ki
为聚类样本集uk中样本i,n为聚类样本集uk中的样本总数;
[0057]
步骤5、判断所有新旧聚类中心的距离di是否小于0.00001或者重复执行步骤2和步骤3的次数j超过60次,获得最终的聚类样本集uki,i=1,2,
……
,20;
[0058]
步骤6、取每组样本的前9个参数为神经网络输入值,最后1个参数为神经网络输出值,构建只有一个隐含层的bp神经网络;
[0059]
步骤7、通过交叉验证法依次选择一个聚类样本集作为测试样本,其余聚类样本集作为训练样本进行神经网络训练,对测试样本进行预测,将预测相对误差e超过10%的样本划归至不良样本集,其余情况重新划归至训练样本集;
[0060]
步骤8、剔除原始样本中所有标记的不良样本,利用其余样本重新构建和训练bp神经网络,利用训练好的神经网络对不良样本进行检验和校正,具体步骤如下:
[0061]
1)删除不良样本,利用优化样本构建并训练bp神经网络,利用训练好的神经网络对不良样本进行测试,计算相对误差;
[0062]
2)筛选相对误差大于20%的样本,确定为不良数据;筛选相对误差小于5%的样本,修正为非不良数据;
[0063]
3)对步骤2)中筛选后的剩余样本重复执行步骤1)和步骤2)直至满足以下任一条件:条件1、执行步骤2)之后无剩余样本;条件2、重复执行次数不少于3次;
[0064]
4)将剩余样本全部确认为不良数据bd。
[0065]
经以上步骤操作,该方法鉴别出45组不良数据,所鉴别出的样本全部为设定的不良样本,通过本方法得到的不良数据的辨识率为90%,准确率为100%。
[0066]
实施例2
[0067]
一种基于聚类分析耦合神经网络预测的不良数据辨识方法,如图1所示,其具体实
施步骤如下:
[0068]
步骤1、从scr脱硝系统收集的准确运行原始数据样本u0共计1000组,每组样本包括入口压力、入口烟气量、入口no
x
浓度、喷氨量、烟气温度、出口压力、出口no
x
浓度、脱硝效率、氨逃逸浓度、scr脱硝催化剂活性共计10个参数,从原始样本u0随机选取50组样本,人为添加其值10%的误差作为不良样本,对处理后样本按以下公式(1)进行无量纲化处理,记为样本集u1:
[0069][0070]
式中,z
ni
为参数z的归一化值,zi为参数z的原始值,z
max
为参数z的最大值,z
min
为参数z的最小值;
[0071]
步骤2、从原始数据随机选取30个样本作为聚类中心ai,i=1,2,
……
,30;
[0072]
步骤3、按公式(2)计算其余样本与聚类中心的距离,将样本划归至与其最近的聚类中心所表示的聚类样本集,完成30个聚类样本集的划分,记为聚类样本集uki,i=1,2,
……
,30;
[0073][0074]
式中:d
ij
表示样本i和样本j之间的距离,z
ik
为样本i的参数k取值,n为单个样本的参数总数;
[0075]
步骤4、按公式(3)重新计算30个聚类样本集的聚类中心bi,i=1,2,
……
,30,按公式(2)计算新旧聚类中心的距离di,i=1,2,
……
,30;
[0076][0077]
式中,bk为第k个聚类样本集uk的聚类中心,z
ki
为聚类样本集uk中样本i,n为聚类样本集uk中的样本总数;
[0078]
步骤5、判断所有新旧聚类中心的距离是否小于0.00001或者重复执行步骤2和步骤3的次数j超过90次,获得最终的聚类样本集uki,i=1,2,
……
,30;
[0079]
步骤6、取每组样本的前9个参数为神经网络输入值,最后1个参数为神经网络输出值,构建只有一个隐含层的bp神经网络;
[0080]
步骤7、通过交叉验证法依次选择一个聚类样本集作为测试样本,其余聚类样本集作为训练样本进行神经网络训练,对测试样本进行预测,将预测相对误差e超过10%的样本划归至不良样本集,其余情况重新划归至训练样本集;
[0081]
步骤8、剔除原始样本中所有标记的不良样本,利用其余样本重新构建和训练bp神经网络,利用训练好的神经网络对不良样本进行检验和校正,具体步骤如下:
[0082]
1)删除不良样本,利用优化样本构建并训练bp神经网络,利用训练好的神经网络对不良样本进行测试,计算相对误差;
[0083]
2)筛选相对误差大于10%的样本,确定为不良数据;筛选相对误差小于5%的样本,修正为非不良数据;
[0084]
3)对步骤2)中筛选后的剩余样本重复执行步骤1)和步骤2)直至满足以下任一条件:条件1、执行步骤2)之后无剩余样本;条件2、重复执行次数不少于3次;
[0085]
4)将剩余样本全部确认为不良数据bd。
[0086]
经以上步骤操作,该方法鉴别出47组不良数据,所鉴别出的样本全部为设定的不良样本,通过本方法得到的不良数据的辨识率为94%,准确率为100%。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。