1.本发明属于网络安全技术领域,具体涉及一种基于机器阅读理解的威胁情报命名实体识别方法。
背景技术:
2.随着网络信息技术的快速发展,网络空间安全形势也日益严峻。要守护网络安全,不仅要在技术上强过攻击者,更要在意识上领先于攻击者,对“未知的未知”给予足够的重视,未雨绸缪,只有这样,才能做到固若金汤,不给黑客任何可乘之机。因此,威胁情报有效分析对于防御有组织、有预谋且花样繁多的安全威胁有着重要的现实意义与科研价值。
3.威胁情报分析必须立足于知识抽取,将对应的实体及关系进行识别,当前命名实体识别ner主要有以下几种:(1)基于单向长短期记忆(lstm)神经网络的lstm-crf模型。基于lstm优秀的序列建模功能,lstm-crf成为命名实体识别的基础框架之一,很多方法是以lstm-crf为主体框架,整合各种相关功能。例如,加入手工拼写特征、使用文字cnn提取文字特征或使用字符级lstm。(2)基于cnn的实体识别方案,如cnn-crf结构,或者基于cnn-crf,使用字符cnn提出的增强模型。(3)基于空洞卷积网络(idcnn-crf)的实体识别方案,它可以在提取序列信息的同时加快训练速度。(4)基于bilstm-crf模型为基础,利用注意力机制获取全文范围内的单词上下文或者采用gru计算单元,提出双向gru为基础的实体识别方法。
4.一方面,这些传统方法普遍存在的问题是不能代表词的多义性,以及对多层嵌套实体难以识别,而威胁情报恰恰存在大量的此类情况且威胁情报实体分类较为模糊,这也是威胁情报分析中的一大难点。另一方面,目前面向领域的ner研究相对集中于医学及生物学科等科学领域,面向网络安全的威胁情报领域的研究尚少。随着各领域内数据量的指数式激增,领域专业数据信息的自动化处理和分析已成主流趋势。因此,面向威胁情报领域的文本识别存在很大的研究价值和空间,对威胁情报分析也起到十分关键的作用。
技术实现要素:
5.本发明的目的在于提供一种基于机器阅读理解的威胁情报命名实体识别方法,提高命名实体识别准确度。
6.为实现上述目的,本发明所采取的技术方案为:
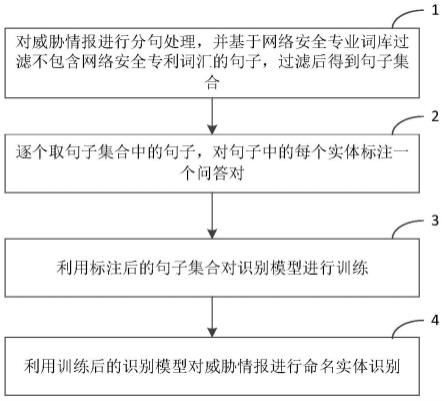
7.一种基于机器阅读理解的威胁情报命名实体识别方法,所述基于机器阅读理解的威胁情报命名实体识别方法,包括:
8.步骤1、对威胁情报进行分句处理,并基于网络安全专业词库过滤不包含网络安全专业词汇的句子,过滤后得到句子集合;
9.步骤2、逐个取句子集合中的句子,对句子中的每个实体标注一个问答对;
10.步骤3、利用标注后的句子集合对识别模型进行训练,包括:
11.步骤3.1、取句子中的一类实体进行训练,将实体标注的问答对中的问题和对应句子进行拼接,对拼接后的句子进行分词处理得到词序列,并基于词序列进行特征提取得到
文本特征矩阵;
12.步骤3.2、用两个二分类器对文本特征矩阵中每个词进行分类,第一个二分类器用于判断词是否为问题所对应的答案的开始词,第二个二分类器用于判断词是否为问题所对应的答案的结束词,得到句子中每个词属于开始词的概率以及每个词属于结束词的概率;
13.步骤3.3、从句子中每个词属于开始词的概率中选取概率为最大评分的词对应的索引作为开始索引,从句子中每个词属于结束词的概率中选取概率为最大评分的词对应的索引作为结束索引;
14.步骤3.4、根据开始索引和结束索引,使用一个二分类器计算开始词和结束词之间的匹配程度,输出匹配程度高于阈值的开始索引和结束索引作为预测答案;
15.步骤3.5、根据输出的预测答案以及实际答案计算损失函数用于更新各二分类器的参数,并返回步骤3.1继续进行识别模型训练直至收敛;
16.步骤4、利用训练后的识别模型对威胁情报进行命名实体识别。
17.以下还提供了若干可选方式,但并不作为对上述总体方案的额外限定,仅仅是进一步的增补或优选,在没有技术或逻辑矛盾的前提下,各可选方式可单独针对上述总体方案进行组合,还可以是多个可选方式之间进行组合。
18.作为优选,所述对句子中的每个实体标注一个问答对,包括:
19.为实体分配一个实体类型,每个实体类型预先设置对应于一个固定的问题,则将该实体类型对应的问题作为实体标注时的问题;
20.以词为单位,将实体在句子中出现的开始位置和结束位置作为标注时的答案。
21.作为优选,所述实体类型对应的问题为实体类型的名词解释。
22.作为优选,所述基于词序列进行特征提取得到文本特征矩阵,包括:
23.在词序列的头部添加一个特殊标记用于表示序列的开始,在间题和句子之间添加标记分隔符,得到完整词序列;
24.利用albert模型对完整词序列进行特征提取得到文本特征矩阵,文本特征矩阵表示为e∈r
n*d
,其中n为句子长度,d为albert模型最后一层提取的特征的向量维度,即文本特征矩阵e的每一行代表一个词对应的特征向量。
25.作为优选,所述根据输出的预测答案以及实际答案计算损失函数,包括:
26.在训练阶段有三个损失函数分别为:开始位置损失函数l
start
、结束位置损失函数l
end
、实体匹配损失函数l
span
,最终识别模型的损失函数l为训练各阶段的损失总和,计算公式如下:
27.l
start
=ce(p
start
,y
start
)
28.l
end
=ce(p
end
,y
end
)
29.l
span
=ce(p
start_end
,y
start_end
)
30.l=αl
start
βl
end
γl
span
31.式中,p
start
为句子中每个词属于开始词的预测概率,y
start
为句子中每个词属于实体的开始词的实际概率,p
end
为句子中每个词属于结束词的预测概率,y
end
为句子中每个词属于实体的结束词的实际概率,p
start_end
表示开始词和结束词之间的预测匹配程度,y
start_end
表示开始词和结束词之间的实际匹配程度,ce()为交叉熵损失函数,α,β,γ为权重系数,α,β,γ∈[0,1]。
[0032]
本发明提供的基于机器阅读理解的威胁情报命名实体识别方法,基于机器阅读理解的威胁情报命名实体识别可以有效解决威胁情报实体分类模糊以及嵌套实体问题;构建的问题中自带实体隐藏信息可以有效提高识别准确率;将实体识别由序列标注问题转化为分类匹配问题,因此一个具有多个实体的句子可以生成多个训练样本,从而降低了对句子数量的要求。
附图说明
[0033]
图1为本发明的基于机器阅读理解的威胁情报命名实体识别方法的流程图;
[0034]
图2为本发明albert模型的输入输出示意图;
[0035]
图3为本发明利用识别模型进行命名实体识别的流程图。
具体实施方式
[0036]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0037]
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本发明。
[0038]
为了克服现有技术中威胁情报分析存在的难点,本实施例提供一种基于机器阅读理解的威胁情报命名实体识别方法,在训练样本稀少的情况下实现高准确率的命名实体识别。
[0039]
具体的,如图1所示,本实施例提供基于机器阅读理解的威胁情报命名实体识别方法,包括以下步骤:
[0040]
步骤1、对威胁情报进行分句处理,并基于网络安全专业词库过滤不包含网络安全专利词汇的句子,过滤后得到句子集合。
[0041]
由于目前没有相关的国际或者国内通用的网络安全专业词库,因此本实施例实施时可参考现有的网络安全专业词汇汇总库进行过滤,例如“网络安全词语(network security words)”、“网络安全专业词汇大全”等,当然也可以是现有网络安全专业词汇汇总库的集合,以达到全面过滤的目的,避免包含非专业词汇的句子对后续模型训练准确度和识别效率造成影响。
[0042]
步骤2、逐个取句子集合中的句子,对句子中的每个实体标注一个问答对。
[0043]
问答对(qj,aj)中,问题qj是用于查询实体ej的一段说明,答案aj是实体ej在句子si中的位置,其中i为句子集合中句子的索引,si为句子集合中的第i条句子,j为句子中实体的索引,ej为句子中的第j个实体。给定一个案例,句子si=“we further tested tweety chat and saw red flags indicating their targets of interest:verification emails with a physical address whose postal code is assigned to a provincial capital that also appears(upon logging in)as a chat channel in tweety chat.”,要标注的实体ej=“tweety chat”,具体标注流程如下:
[0044]
1)问题标注:根据专家知识人工为实体ej分配一个实体类型,每个实体类型预先设置对应于一个固定的问题。问题的定义可直接参考实体类型的名词解释。
[0045]
例如,表1给出了stix中对网络攻击领域部分实体类型的名词解释,可直接将这些名词解释作为实体标注时问题。本案例中,实体ej(“tweety chat”)分配的实体类型为malware.backdoor,则问题qj=“a malicious program that allows an attacker to perform actions on a remote system,such as transferring files,acquiring passwords,or executing arbitrary commands.”。
[0046]
表1 stix中对网络攻击领域部分实体类型的名词解释
[0047][0048]
2)答案标注:在句子si中标注实体ej的出现位置,形式为[startj,endj],以词为单位。其中,startj为开始词的位置(简称开始位置),endj为结束词的位置(简称结束位置),实体ej的出现位置可能有多个。本案例中,实体ej(“tweety chat”)的出现位置为[3,4]和[43,44]。本实施例中词的位置理解为词在句子中的索引。
[0049]
步骤3、利用标注后的句子集合对识别模型进行训练。本实施例中的识别模型包括三个二分类器,将实体识别由序列标注问题转化为分类匹配问题。具体的,模型训练过程如下:
[0050]
步骤3.1、输入问题及句子:如图2所示,取句子中的一类实体进行训练,将实体标注的间答对中的问题qj和对应句子si进行拼接,对拼接后的句子进行分词处理得到词序列,并基于词序列进行特征提取得到文本特征矩阵。
[0051]
其中得到词序列后,在词序列的开头添加一个特殊标记[cls],用于标识序列的开始,在问题和原句子间用标记[sep]分隔符进行分隔,最终完整词序列表示为{[cls],q1,q2,
……
,qm,[sep],x1,x2,
……
,xn}的形式。其中,qv为问题qj中的第v个词,xk为原句子si中的第k个词。
[0052]
需要说明的是,上述完整词序列为本实施例提供的一种表示形式,在满足具有特殊标记和分隔符的前提下,可以替换标记或进一步添加不影响模型进行特征提取的标记,例如图2中所示的在词序列的末尾再添加一个特殊标记,用于标识序列的结束,最终得到的完整词序列可表示为{[cls],q1,q2,......,qm,[sep1],x1,x2,......,xn,[sep2]}。
[0053]
得到完整词序列后将完整词序列输入到albert模型中进行特征提取,得到文本特征矩阵e∈r
n*d
。其中n为句子长度,d为albert模型最后一层提取的特征矩阵的向量维度,即文本特征矩阵e的每一行代表一个词对应的特征向量。
[0054]
当在有一部分该领域的标注数据后,机器阅读理解所具有的问答特性,结合albert模型可以进行知识的拓展学习,所以该领域的其他场景就算缺乏标注数据也可以正常使用,进而克服了训练样本稀少的问题。
[0055]
步骤3.2、多重二元分类:用两个二分类器对文本特征矩阵中每个词xk进行分类,第一个二分类器用于判断词xk是否为问题所对应的答案的开始词,第二个二分类器用于判断词xk是否为问题所对应的答案的结束词,得到句子中每个词属于开始词的概率以及每个词属于结束词的概率。
[0056]
具体地,句子中的词属于开始词的概率p
start
和属于结束词的概率p
end
的计算分别如公式(1)和公式(2)所示,其中,e是albert模型输出的文本特征矩阵,t
start
∈r
d*2
和t
end
∈r
d*2
是识别模型需要学习的参数,p
start
和p
end
为矩阵,矩阵的每一行表示每个词对应的索引(例如k)作为给定查询的实体开始/结束位置的概率分布,矩阵的两列分别表示二分类器输出的为true和false的概率。
[0057]
p
start
=softmax
each row
(e
·
t
start
)∈r
n*2
ꢀꢀꢀ
(1)
[0058]
p
end
=softmax
each row
(e
·
t
end
)∈r
n*2
ꢀꢀꢀ
(2)
[0059]
步骤3.3、预测索引:从句子中每个词属于开始词的概率中选取概率为最大评分的词对应的索引作为开始索引,从句子中每个词属于结束词的概率中选取概率为最大评分的词对应的索引作为结束索引。
[0060]
具体的,对概率矩阵p
start
和p
end
的每一行使用argmax函数,得到可能是开始词对应的开始索引(如公式(3)所示)和结束词对应的结束索引(如公式(4)所示)。其中,上标(i)和(j)分别表示第i行和第j行,argmax()为输出最大评分的索引。
[0061][0062][0063]
表示开始词的概率矩阵p
start
的第i行,表示结束词的概率矩阵p
end
的第j行。由于一个矩阵中可能存在多个实体,因此概率矩阵经过argmax()处理后可能输出多个开始索引或结束索引,即和相当于一个集合。
[0064]
步骤3.4、进行二元链接:根据开始索引和结束索引,使用一个二分类器计算开始词和结束词之间的匹配程度,输出匹配程度高于阈值的开始索引和结束索引作为预测答案。具体步骤如下:
[0065]
根据步骤3.3中得到的开始索引和结束索引和使用一个二分类器计算开始索引对应的开始词和结束索引对应的结束词匹配的概率(即匹配程度,如公式(5)所示),其中,e是albert模型输出的文本特征矩阵,concat()为向量拼接,索引索引m∈r
1*2d
是识别模型需要学习的参数。当时,模型判定x(i
start
:j
end
)是实体,否则不是实体。
[0066][0067]
式中,为句子si中索引i
start
位置处的开始词,为句子si中索引j
end
位置处的结束词,sigmoid()为sigmoid函数,x(i
start
:j
end
)表示由句子中索引i
start
至j
end
部分构成的实体,属于同一实体的开始词和结束词必然具有较高的匹配概率,因此本实施例遍历和中的索引利用匹配概率对预测实体进行筛选。
[0068]
步骤3.5、根据输出的预测答案以及实际答案计算损失函数用于更新各二分类器的参数,并返回步骤3.1继续进行识别模型训练直至收敛。
[0069]
在训练阶段有三个损失函数分别为:开始位置损失函数l
start
、结束位置损失函数l
end
、实体匹配损失函数l
span
,最终识别模型的损失函数l为训练各阶段的损失总和,计算公式如下:
[0070]
l
start
=ce(p
start
,y
start
)
ꢀꢀꢀ
(6)
[0071]
l
end
=ce(p
end
,y
end
)
ꢀꢀꢀ
(7)
[0072]
l
span
=ce(p
start_end
,y
start_end
)
ꢀꢀꢀ
(8)
[0073]
l=αl
start
βl
end
γl
span
ꢀꢀꢀ
(9)
[0074]
式中,p
start
为句子中每个词属于开始词的预测概率,y
start
为句子中每个词属于实体的开始词的实际概率,p
end
为句子中每个词属于结束词的预测概率,y
end
为句子中每个词属于实体的结束词的实际概率,p
start_end
表示开始词和结束词之间的预测匹配程度,y
start_end
表示开始词和结束词之间的实际匹配程度,ce()为交叉熵损失函数,α,β,γ为权重系数,α,β,γ∈[0,1]。本实施例利用两个对应的序列(例如p
start
,y
start
)进行损失函数计算。
[0075]
由于匹配程度基于开始索引和结束索引进行计算,因此本实施例中的p
start_end
理解为而其中每个开始词和结束词的匹配概率即为y
start_end
同理理解。
[0076]
步骤4、利用训练后的识别模型对威胁情报进行命名实体识别。
[0077]
给定威胁情报中一个句子,参照图3,具体识别详细步骤如下:
[0078]
步骤4.1、输入待预测文本及问题:按照步骤3.1中的方法拼接si和待识别实体类型的问题,添加特殊标记和分隔符后输入albert模型进行特征提取,得到文本特征矩阵e∈rn*d
。
[0079]
步骤4.2、计算位置概率:使用步骤3.2和步骤3.3中训练好的二分类器计算得到对应的开始索引和结束索引。
[0080]
步骤4.3、进行位置匹配:使用步骤3.4中训练好的开始-结束匹配器(即二分类器)得到配对好的开始-结束索引,即为相应需要得到的每类实体的具体字符串,该字符串也就是对应的答案。
[0081]
本实施例基于机器阅读理解的威胁情报命名实体识别可以有效解决威胁情报实体分类模糊以及嵌套实体问题;构建的问题中自带实体隐藏信息可以有效提高识别准确率;将实体识别由序列标注问题转化为分类匹配问题,因此一个具有多个实体的句子可以生成多个训练样本,从而降低了对句子数量的要求。
[0082]
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0083]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
