1.本发明属于计算机视觉图像分割领域,具体涉及一种基于受控像素嵌入表征显式交互的场景全景分割方法及系统。
背景技术:
2.图像分割作为计算机视觉领域中的一个基础且有着丰厚研究成果的任务,可以简单的分离为仅关注场景中前后景物体语义类别的语义分割任务和仅关注场景中作为前景出现的物体的类别以及该物体实例观念的实例分割任务。长久以来,语义分割与实例分割任务的研究都是分离进行的。而在2018年,学术界新提出的一项用全景分割任务将语义分割和实例分割统一了起来,自此学术界和工业界开始了对全景分割任务的研究探索及应。全景分割确保场景中每一个像素拥有唯一的语义类别,且如果该类别为规定的前景类别,还需要为该像素指定唯一的实例id。
3.从方法上区分,全景分割范式可以分为top-down和bottom-up两种。top-down的全景分割方案则是分别进行语义分割与实例分割,研究的重点在于如何在后处理过程中将像素的语义类别冲突和像素实例id的冲突去除,以得到唯一的语义类别和实例id,在分割精度上是能够凌驾于bottom-up的方案的,但通常因为模型flops过大,无法在模型参数量不缩减的情况下取得更快的分割速度。反观bottom-up的方案,侧重于研究如何高效精简的刻画实例个体,从而有效的表征一个实例,然后通过这些中间结果作为实例组装的线索,从语义分割结果中二次剥离出实例个体以完成实例分割,最终得到全景分割的结果。相比之下,bottom-up的方法虽然精度不能完全超越top-down的方法,但却凭借着优异的分割速度被学术界和工业界不断迭代优化,取得了良好的发展。也因为如此,bottom-up的方案在分割精度上逐渐有赶超top-down方法的趋势,甚至可以在分割精度和速度中取得很好的平衡。
4.然而,bottom-up的全景分割范式在结构设计上还有着改进的空间。bottom-up的方法注重使用额外的实例表征线索来刻画实例个体本身,因此在结构上呈现出多任务回归的特点,而最终的实例分割结果又是从语义分割结果中剥离出来,这就意味着实例分割的性能严重依赖于语义分割的结果。在多任务多分支的优化过程中,一旦作为主任务的语义分割没有得到较优的解,即便是作为实例组装线索的其他分任务优化的很好,对最终的全景分割也会有很严重的影响。
技术实现要素:
5.为了解决现有技术中存在的问题,本发明提供一种基于受控像素嵌入表征显式交互的场景全景分割方法,区别于典型的bottom-up结构的全景分割框架,本发明使用了基于度量学习的特征表征方法,并通过显式约束限定了全景分割框架中语义特征向量与实例个体特征向量的关系,通过这种显式的优化学习方式,保证了像素的语义嵌入表征和实例个体的嵌入表征可控,并有效的增强了原始的语义特征向量和实例个体特征向量,是一种新的高性能的全景分割方法
6.为了实现上述目的,本发明采用的技术方案是:一种基于受控像素嵌入表征显式交互的场景全景分割方法,包括以下步骤:
7.从训练数据集中随机采样出一个批次的图像数据,对输入图像进行下采样和特征编码,将经过特征编码的图像进行像素语义信息和实例个体信息的解码,得到像素的语义表征s和实例表征i;
8.借助原始输入图像的真实全景分割标签,获得原始输入图像中的语义roi、实例个体roi以及实例个体质心coi,然后像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o;
9.对语义表征s进行语义分割,得到模型输出的语义分割结果p;同时对实例表征i,进行实例质心热图回归,得到模型输出的实例质心热图h;
10.基于实例表征i和实例质心热图h得到实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果。
11.基于优化后的einet模型,输出优化后的实例表征i,语义分割结果p与实例质心热图h,先基于优化后的实例表征i和实例质心热图h得到优化后的实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果;
12.所述einet模型包括卷积神经网络、带空洞池化金字塔特征解码器和特征金字塔的特征解码器、能生成语义分割结果的语义分割任务头以及用于回归实例质心热图的任务头,卷积神经网络用于对输入图像进行特征编码,一个带空洞池化金字塔特征解码器用于语义解码,得到像素的语义表征s;特征金字塔的特征解码器用于实例个体解码得到像素的实例表征i;
13.所述einet模型优化包括以下步骤:
14.从训练数据集中随机采样出一个批次的图像数据,对输入图像进行下采样和特征编码,将经过特征编码的图像进行像素语义信息和实例个体信息的解码,得到像素的语义表征s和实例表征i;
15.借助原始输入图像的真实全景分割标签,获得原始输入图像中的语义roi、实例个体roi以及实例个体质心coi,然后像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o;
16.对语义表征s进行语义分割,得到模型输出的语义分割结果p;同时对实例表征i,进行实例质心热图回归,得到模型输出的实例质心热图h;
17.基于语义roi的高维特征向量v,实例roi的高维特征向量e,实例质心coi的高维特征向量o和语义分割结果p与实例质心热图h,使用基于特征显式交互的优化函数,对模型进行优化更新,得到所述优化后的einet模型。
18.基于实例表征i和实例质心热图h得到实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果具体如下:基于优化的模型,输出优化后的实例质心热图h与实例表征i,先从实
例质心热图h中解析出实例个体的实际坐标位置,然后抽取所述实际坐标位置的coi高维特征向量,绑定实例个体的id和其对应的coi高维特征向量,构成实例质心表征字典m;
19.基于优化的模型,输出优化后的语义分割结果p,先用语义分割结果p中属于前景类别的像素构成待实例分割的像素集合,再通过度量待实例分割像素集合中每个像素的实例表征与实例质心表征字典中每个实例id对应高维特征向量的距离,为待实例分割的像素集合中的每个像素分配实例id,以此从语义分割结果中剥离出实例个体完成前景类物体的实例分割,从而得到最终的全景分割结果。
20.从训练数据集中随机采样出一个批次的图像数据,对输入图像进行下采样和特征编码,将经过特征编码的图像进行像素语义信息和实例个体信息的解码,得到像素的语义表征s和实例表征i,具体实现方法如下:
21.s101,使用四组不同降采样倍率的卷积block对输入模型的图像进行像素特征编码;
22.s102,使用双分支的特征解码器对像素编码特征进行解码,包括一路基于空洞池化金字塔模组的语义解码分支和一路基于金字塔式上采样的实例个体解码分支,并在两条分支进行解码时,分别通过跨越式连接使用了编码模块给予的高分辨率特征,最终得到像素的语义表征s和实例表征i。
23.借助原始输入图像的真实全景分割标签,获得原始输入图像中的语义roi、实例个体roi以及实例个体质心coi,然后像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o的具体实现方法如下:
24.s201,记像素的语义表征s的形状为d
×h×
w,原始输入图像中共有j类物体,经过一个形状为j
×h×
w的ground truth roi进行解码特征的抽取后,得到j个语义roi的高维特征向量,记为
25.s202,记像素的实例表征i的形状为d
×h×
w,原始输入图像中共有k个前景的thing类实例对象,经过一个形状为k
×h×
w的ground truth roi进行解码特征的抽取后,得到k个实例roi的高维特征向量,记为
26.s203,经过一个形状为k
×h×
w的ground truth roi先进行实例质心位置计算,再从实例表征i中进行解码特征的抽取,得到k个实例个体质心coi的高维特征向量,记为
27.对语义表征s进行语义分割,得到模型输出的语义分割结果p;同时对实例表征i,进行实例质心热图回归,得到模型输出的实例质心热图h的具体实现方法如下:
28.s301,将所述语义表征s输入到语义分割任务头中,具体的,通过一个softmax多分类器,就得到了语义分割结果,记为p;
29.s302,将实例表征i送入实例质心热图回归的任务头,通过参数化的卷积层,输出实例质心热图h。
30.基于语义roi的高维特征向量v,实例roi的高维特征向量e,实例质心coi的高维特征向量o和语义分割结果p与实例质心热图h,使用基于特征显式交互的优化函数,对模型进
行优化更新,得到所述优化后的einet模型的具体实现方法如下:
31.s401,通过显式特征交互优化更新语义分支表征。使用实例roi的高维特征向量e对语义表征i进行优化,先用实例roi的高维特征向量e通过关系矩阵加权的方式,更新维护于全数据集中的语义原型词典q中的语义特征向量,然后再用更新后的语义原型词典q的特征向量替换增强前的像素语义表征s;
32.s402,通过显式特征交互优化更新实例分支表征。使用更新后维护于整个训练数据集上的语义原型词典q中的k个语义特征向量优化|j|个实例roi的高维特征向量e,使用三元组损失拉近实例个体表征与语义原型词典q中该实例真实所属语义类别的语义特征之间的距离,而推远实例个体表征与语义原型词典中非该实例真实所属语义类别的语义特征之间的距离;
33.s403,通过交叉熵损失优化更新语义分割结果p;
34.s404,通过平均最小二乘损失优化更新实例质心热图h;
35.s405,通过l2正则手段优化更新实例质心表征,使实例个体的质心coi特征向量能够代表实例个体的表征e。
36.另外,本发明提供一种基于受控像素嵌入表征显式交互的场景全景分割系统,包括编码和解码模块、特征抽取模块、任务回归模块以及分割模块;
37.编码和解码模块用于从训练数据集中随机采样出一个批次的图像数据,对输入图像进行下采样和特征编码,将经过特征编码的图像进行像素语义信息和实例个体信息的解码,得到像素的语义表征s和实例表征i;
38.特征抽取模块用于借助原始输入图像的真实全景分割标签,获得原始输入图像中的语义roi、实例个体roi以及实例个体质心coi,然后像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o;
39.任务回归模块用于对语义表征s进行语义分割,得到模型输出的语义分割结果p;同时对实例表征i,进行实例质心热图回归,得到模型输出的实例质心热图h;
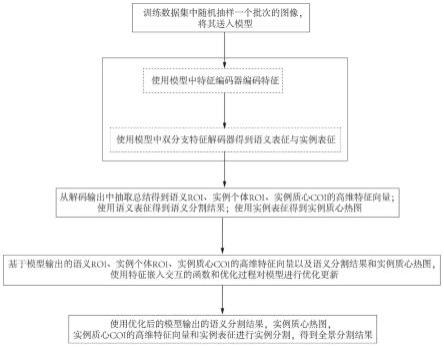
40.分割模块用于基于优化后的实例表征i和实例质心热图h得到优化后的实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果。
41.本发明也提供一种计算机设备,包括处理器以及存储器,存储器用于存储计算机可执行程序,处理器从存储器中读取部分或全部所述计算机可执行程序并执行,处理器执行部分或全部计算可执行程序时能实现本发明所述基于受控像素嵌入表征显式交互的场景全景分割的方法。
42.同时提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时,能实现本发明所述的基于受控像素嵌入表征显式交互的场景全景分割的方法。
43.与现有技术相比,本发明至少具有以下有益效果:
44.1、本发明提供的基于受控像素嵌入表征显式交互的场景全景分割方法,只需要一个语义分割任务头和一个实例质心热图回归任务头就可以完成场景全景分割,这在模型框架设计上降低了对于实例组装线索回归任务的依赖程度,在多任务联合优化的框架下,减
轻了联合优化难度,有利于bottom-up范式的全景分割方案的语义分割主分支取得更好的分割精度。
45.2、本发明提供的基于受控像素嵌入表征显式交互的场景全景分割方法,在训练优化过程中,使用显式的特征交互损失函数对模型的中间输出特征进行提前优化,得到了更好的语义表征和实例表征,对全景分割任务的性能提升明显。
46.3、本发明提供的基于受控像素嵌入表征显式交互的场景全景分割方法,使用l2正则化对实例个体本身的特征向量进行质心化压缩,能够在前景物体的质心位置抽取到紧凑的特征表示,是一种实例个体新的表征线索。
附图说明
47.图1为本发明的整体框架流程图;
48.图2为本发明的特征编码器模块与双分支特征解码器模块示意图;
49.图3为本发明的语义分割roi、实例个体roi以及实例个体质心coi的高维特征向量抽取总结示意图;
50.图4为本发明的受控像素在语义分支和实例分支抽取得到的roi高维特征向量进行显式特征交互的示意图。
具体实施方式
51.为使本技术的创新性技术方案和优点相对更加清楚,下面将结合附图对本发明的技术方案进行清楚、完整地描述。
52.本发明提供一种基于受控像素嵌入表征显示交互的场景全景分割方法,包括以下步骤:
53.步骤1,从训练数据集中随机采样出一个批次的图像数据后送入模型,先使用卷积神经网络进行下采样,完成对输入图像的特征编码任务,然后将编码器的输出结果输入到两分支的带空洞池化金字塔和特征金字塔的特征解码器中,分别进行像素语义信息和实例个体信息的解码任务,得到模型所输出的像素语义表征s和实例表征i;
54.步骤2,借助输入图像的真实全景分割标签,获得输入图像中的语义roi,实例个体roi以及实例个体质心coi,然后在1中获得的像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在1中获得的像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o;
55.步骤3,将步骤1中获得的语义表征s,送入一个带有softmax操作的语义分割任务头,得到模型输出的语义分割结果p;同时,将步骤1中获得的实例表征i,送入一个进行实例质心热图回归的任务头,得到模型输出的实例质心热图h。
56.步骤4,基于实例表征i和实例质心热图h得到的实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果。
57.如图1所示,本发明基于einet(embedding interaction network)模型得到分割结果,输出优化后的实例表征i,语义分割结果p与实例质心热图h,先基于优化后的实例表
征i和实例质心热图h得到优化后的实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果;
58.所述einet模型包括卷积神经网络、带空洞池化金字塔特征解码器和特征金字塔的特征解码器、能生成语义分割结果的语义分割任务头以及用于回归实例质心热图的任务头,卷积神经网络用于对输入图像进行特征编码,一个带空洞池化金字塔特征解码器用于语义解码,得到像素的语义表征s;特征金字塔的特征解码器用于实例个体解码得到像素的实例表征i;
59.所述einet模型优化包括以下步骤:
60.s100,从训练数据集中随机采样出一个批次的图像数据,对输入图像进行下采样和特征编码,将经过特征编码的图像进行像素语义信息和实例个体信息的解码,得到像素的语义表征s和实例表征i;
61.s200,借助原始输入图像的真实全景分割标签,获得原始输入图像中的语义roi、实例个体roi以及实例个体质心coi,然后像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o;
62.s300,对语义表征s进行语义分割,得到模型输出的语义分割结果p;同时对实例表征i,进行实例质心热图回归,得到模型输出的实例质心热图h;
63.s400,基于语义roi的高维特征向量v,实例roi的高维特征向量e,实例质心coi的高维特征向量o和语义分割结果p与实例质心热图h,使用基于特征显式交互的优化函数,对模型进行优化更新,得到所述优化后的einet模型。
64.s500,使用经过优化更新的模型,从训练数据集中随机采样出一个批次的图像数据后送入模型,如图2所示,先使用卷积神经网络进行下采样,完成对输入图像的特征编码任务,然后将编码器的输出结果输入到两分支的带空洞池化金字塔和特征金字塔的特征解码器中,分别进行像素语义信息和实例个体信息的解码任务,得到模型所输出的像素语义表征s和实例表征i。
65.每一个步骤具体实现过程分别如下:
66.步骤11,像素特征编码
67.输入图像分辨率为1024
×
2048,在经过模型特征编码器的卷积操作进行下采样时,先后使用四组卷积block对图像进行特征编码,分别得到4倍、8倍、16倍、16倍采样的像素特征,完成对原始输入图像的特征编码,并将富含低频语义特征的4倍、8倍降采样特征图用于下文中特征解码器模块。
68.步骤12,像素语义分支与实例分支特征解码
69.当模型的特征编码器对输入图像进行特征编码,得到像素的高维特征向量后,使用两分支的解码器,分别解码得到语义信息和实例个体信息。在语义解码分支中,编码信息先经过一组由1
×
1大小的卷积核,3
×
3大小且空洞率为6的空洞卷积核,3
×
3大小且空洞率为12的空洞卷积核,3
×
3大小且空洞率为18的空洞卷积核,图像池化层组成的空洞池化金字塔模组得到编码特征向量的初次解码,再经过4次卷积操作和上采样操作,将解码特征的分辨率恢复至原始输入图像分辨率的四分之一,最后将步骤11中所生成的4倍、8倍降采样
特征图进行跨越式连接至解码器模块中,得到像素的语义表征s。在实例个体解码分支中,本发明使用金字塔式上采样的设计方式,先将16倍分辨率特征编码进行一次上采样得到8倍分辨率特征编码,再将该8倍分辨率与原8倍特征编码进行堆叠,此后将该8倍分辨率特征进行一次上采样得到4倍分辨率特征,并将该4倍分辨率特征与原4倍分辨率特征进行堆叠,得到像素的实例表征i。
70.如图3所示,借助输入图像的真实全景分割标签,获得输入图像中的语义roi,实例个体roi以及实例个体质心coi,然后在步骤1中获得的像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在步骤1中获得的像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o。
71.步骤21,语义roi高维特征向量的抽取总结
72.从步骤1中获取到像素的语义表征s后,依据语义分割的ground truth进行语义roi高维特征向量的抽取总结。记语义特征解码的形状为d
×h×
w,输入图像中共有j类物体(在语义分支中把前景的thing类实例对象和背景的stuff类对象统称为物体),那么经过一个形状为j
×h×
w的ground truth roi进行解码特征的抽取后,得到j个语义roi的高维特征向量,记为
73.步骤22,实例roi高维特征向量的抽取总结
74.从步骤1中获取到像素的实例表征i后,依据实例分割的ground truth进行实例roi高维特征向量的抽取总结。记实例个体特征解码的形状为d
×h×
w,输入图像中共有k个前景的thing类实例对象,经过一个形状为k
×h×
w的ground truth roi进行解码特征的抽取后,就得到了这k个实例roi的高维特征向量,记为
75.步骤23,实例个体质心coi的高维特征向量抽取总结
76.从步骤1中获取到像素的实例表征i后,依据实例分割的ground truth进行实例个体质心coi高维特征向量的抽取总结。记实例个体特征解码的形状为d
×h×
w,输入图像中共有k个前景的thing类实例对象,经过一个形状为k
×h×
w的ground truth roi先进行实例质心位置计算,再进行解码特征抽取后,得到这k个实例个体质心coi的高维特征向量,记为为
77.将步骤1中获得的语义表征s送入语义分割任务头,得到模型输出的语义分割结果p。同时,将步骤1中获得的实例表征i,送入一个进行实例质心热图回归的任务头,得到模型输出的实例质心热图h。
78.步骤31,获得语义分割结果
79.语义表征s被输入到语义分割任务头中,通过一个softmax多分类器,就得到了语义分割结果,记为p。
80.步骤32,获得实例质心热图的回归结果
81.实例表征i被送入实例质心热图回归的任务头,通过参数化的卷积层,输出实例质心热图h。
82.如图4所示,基于步骤2中模型输出的语义roi的高维特征向量v,实例roi的高维特征向量e和实例质心coi的高维特征向量o,以及步骤3中模型输出的语义分割结果p与实例质心热图h,使用基于特征显式交互的优化函数,对模型进行优化更新。即s400所述。
83.步骤a,优化更新语义分支表征
84.训练数据集中,前景类和背景类物体的类别数目分别为|c
st
|和|c
th
|,那么整个数据集中共包含的语义类别数目为|c|=|c
st
| |c
th
|。对于语义表征,维持一个存在于模型整个学习周期的语义原型词典用来储存在训练数据集中学习到的各个类别物体的高维语义向量,在对语义分支的表征进行增强时,首先通过如下公式计算语义roi高维特征向量v和实例roi高维特征向量e之间的相似度:
[0085][0086]
其中ω
k,j
表示第k个语义类别下的物体与第j个实例个体之间的相似度,de(
·
,
·
)则是欧式距离度量,且代入欧式距离度量公式前要先将特征进行l2归一化处理,记为φ(
·
)。
[0087]
然后使用实例roi高维特征向量e与维护在整个数据集中的语义原型词典q,通过滑动更新的方式,对该语义原型字典进行优化更新,具体如下式:
[0088][0089]
式中μ=0.9,是滑动更新参数。
[0090]
最后用更新过后的语义原型词典中类别属于前景类的高维特征来替换未增强的语义表征,如下式:
[0091][0092]
式中yi即表示第i个像素的语义类别。
[0093]
至此,就通过实例roi的高维特征向量e完成了对语义表征的优化更新。
[0094]
步骤b,优化更新实例分支表征
[0095]
对实例表征进行优化更新时,本发明使用维护在整个训练数据集中的语义原型词典对实例个体的roi特征向量进行了增强。具体的,本发明使用三元组损失,迫使第k个实例roi的高维特征向量与语义原型词典中该实例个体真实的语义类别对应的语义原型特征向量的距离足够接近,而与不属于该实例个体语义类别的语义原型特征向量的距离足够远。首先需要通过如下式定义三元组损失中的正负样本对的距离:
[0096][0097]
式中为改进的相似度度量公式,gk为第k个实例个体的真实语义类别,ek是第k个实例个体的高维特征向量。
[0098]
然后通过如下所示的三元组损失来约束第k个实例个体的正负样本对之间的距离,达到我们的优化目的:
[0099][0100]
式中α=0.15是用于控制正负样本对之间距离的参数。
[0101]
最后对所有的实例个体都进行上述的优化,全体实例个体的优化损失函数的加和如下式:
[0102][0103]
至此,实现使用维护于整个训练数据集中的语义原型词典中的k个语义表征对|j|个实例roi的高维特征向量e进行了优化。
[0104]
步骤c,优化更新语义分割结果
[0105]
语义表征s被输入到语义分割任务头中,通过一个softmax多分类器,就得到了语义分割结果,记为p。形式上,p是一个像素类别的概率分布,在进行优化时,使用交叉熵损失对语义分割结果进行优化。
[0106]
步骤d,优化更新实例质心热图
[0107]
将实例表征i送入实例质心热图回归的任务头,通过参数化的卷积层,输出实例质心热图h。在进行优化时,使用平均最小二乘损失对实例质心热图h进行优化。
[0108]
步骤e,优化更新实例质心表征
[0109]
为了能够在实例个体质心位置得到实例个体的整体表征,本发明使用l2正则手段将实例roi的高维特征向量e压缩至实例质心位置,以迫使实例个体的表征e与实例个体的质心coi特征向量的距离不能太远。具体的优化约束如下:
[0110][0111]
步骤4,使用经过经过优化更新完毕的模型,输出优化后的实例表征i,语义分割结果p与实例质心热图h,先基于优化后的实例表征i和实例质心热图h得到优化后的实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果。
[0112]
步骤s41,产生实例质心表征字典m
[0113]
首先基于模型输出的实例质心热图h解析得到按照质心置信度降序排列的前30个带语义类别的实例质心坐标,且记所述实例质心的语义类别集合为i
th
,然后从优化后的实例表征i中抽取实例质心coi特征向量备用,构成实例质心表征字典m,该字典的键为实例个体的id,值为相应实例id对应的coi高维特征向量。
[0114]
步骤s42,从语义分割结果p中获得实例分割结果
[0115]
逐个从语义类别的从语义分割结果中分离出实例个体,具体的,对于第一个带语义类别的实例质心,它的语义类别记为a,则首先从s51中获得到语义分割结果中选出所有语义类别为a的像素作为待分离集合,然后计算该待分离集合中所有像素的实例表征与实例质心表征字典m中存在的30个实例质心coi特征向量的距离,记待分割像素集合中第i个像素的实例表征为ii,实例质心表征字典m中id为k的实例个体的coi高维特征向量为mk,则第i个像素的实例id计算方式如下:
[0116][0117]
以此完成a语义类别下的实例分割,并按照如此流程依次完成n
th
∩i
th
中剩余语义类别的实例分割任务,进而完成全景分割中对于前后景语义类别分割的任务和对于前景类别物体实例分割的要求。
[0118]
综上,本发明通过度量学习的相关理论让像素的表征可控,然后为了进一步增强学习到的语义特征和实例个体特征,利用了显式的约束来让语义表征和实例表征进行特征的交互,接着使用交互增强过的特征进行语义分割和实例线索的回归任务;由于本技术的像素表征过程受控,故在后处理中可以基于距离度量直接使用学习到的受控特征来组装实例,从而完成实例分割,因此在训练阶段不需要太多数量的实例线索回归任务,一定程度上减轻了多任务优化的压力,有效缓解了上面涉及到的现今bottom-up方法依然存在的问题。
[0119]
另外,本发明还提供一种基于受控像素嵌入表征显式交互的场景全景分割系统,包括编码和解码模块、特征抽取模块、任务回归模块以及分割模块;
[0120]
编码和解码模块用于从训练数据集中随机采样出一个批次的图像数据,对输入图像进行下采样和特征编码,将经过特征编码的图像进行像素语义信息和实例个体信息的解码,得到像素的语义表征s和实例表征i;
[0121]
特征抽取模块用于借助原始输入图像的真实全景分割标签,获得原始输入图像中的语义roi、实例个体roi以及实例个体质心coi,然后像素的语义表征s中凭借语义roi抽取总结语义roi的高维特征向量v,同时在像素的实例表征i中凭借实例个体roi抽取总结实例roi的高维特征向量e,并借助实例个体质心coi抽取总结实例质心coi的高维特征向量o;
[0122]
任务回归模块用于对语义表征s进行语义分割,得到模型输出的语义分割结果p;同时对实例表征i,进行实例质心热图回归,得到模型输出的实例质心热图h;
[0123]
分割模块用于基于优化后的实例表征i和实例质心热图h得到优化后的实例质心coi的高维特征向量o,再通过计算实例质心coi的高维特征向量o与像素实例表征i的相似度来进行实例分割,从而得到全景分割的结果。
[0124]
可选的,本发明还提供一种计算机设备,包括处理器以及存储器,存储器用于存储计算机可执行程序,处理器从存储器中读取部分或全部所述计算机可执行程序并执行,处理器执行部分或全部计算可执行程序时能实现本发明所述的基于受控像素嵌入表征显式交互的场景全景分割方法的步骤。
[0125]
以及一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时,能实现本发明所述的基于受控像素嵌入表征显式交互的场景全景分割方法的步骤。
[0126]
可以采用计算机程序设计语言编写能用于执行本技术所述方法的程序,所述计算机程序可以为源代码形式、对象代码形式、可执行文件或某些中间形式,计算机程序设计语言可以是c 、java、fortran、c#或python,
[0127]
所述基于组合式剪枝的深度神经网络模型压缩的设备可以是笔记本电脑、平板电脑、桌面型计算机、手机或工作站。
[0128]
处理器可以是中央处理器(cpu)、数字信号处理器(dsp)、专用集成电路(asic)或现成可编程门阵列(fpga)。
[0129]
对于本发明所述存储器,可以是笔记本电脑、平板电脑、桌面型计算机、手机或工作站的内部存储单元,如内存、硬盘;也可以采用外部存储单元,如移动硬盘、闪存卡。
[0130]
计算机可读存储介质可以包括计算机存储介质和通信介质。计算机存储介质包括以用于存储诸如计算机可读指令、数据结构、程序模块或其他数据等信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动介质。计算机可读存储介质可以包括:只读
存储器(rom,read only memory)、随机存取记忆体(ram,random access memory)、固态硬盘(ssd,solid state drives)或光盘等。其中,随机存取记忆体可以包括电阻式随机存取记忆体(reram,resistance)。
[0131]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
