1.本发明涉及神经网络运算领域,并特别涉及一种规范化哈夫曼编解码方法及神经网络计算芯片。
背景技术:
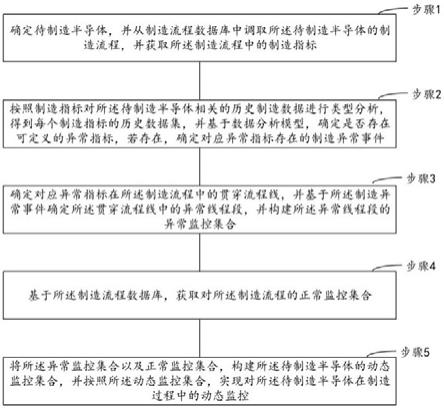
::2.熵编码是无损压缩算法的一个分支,在压缩解压的过程中按熵原理不会损失任何信息,其中信息熵表征信源不确定性的测度。熵编码算法的种类很多,本文主要介绍其中具有代表性的两种:哈夫曼编码和算术编码。3.哈夫曼编码(huffmancoding),由huffman在1952年首次提出,是一种基于最优二叉树(也称作哈夫曼树)结构的变长编码。其主要思想是待编码序列当中的每个字符(literal)都作为二叉树的叶节点,从而满足前缀编码(prefixcoding)的性质,即每个字符的编码都不是其它任何字符的编码前缀,以此降低解码的复杂程度。4.具体实现中,哈夫曼编码需要对每个字符进行词频统计,不断地将频率最小的两个子节点合并,作为其父节点的频率,递归直至产生根节点。如此生长出一棵二叉树的过程同时也是产生哈夫曼码表的过程,而每个字符的编码在哈夫曼树当中对应着根节点到其中一个叶节点的路径,分支向左则添加0,分支向右则添加1。图1给出了序列{aabbcccddddeeeee}对应的哈夫曼树,图2为这棵哈夫曼树对应的编码结果。5.从上述哈夫曼树的构建过程可以看到此编码具有两个特点:6.(1)词频越高的字符编码长度越小,因此整体字符序列的加权编码长度最优,因此哈夫曼编码被认为是压缩比最佳的熵编码。7.(2)同一个字符序列构建出的哈夫曼树并不唯一,比如举例当中字符a和b的父节点与字符d对应的叶节点频率相等,因此哈夫曼编码也有很多变种,不同的实现方式的硬件开销可能差别很大。技术实现要素:8.具体来说,本发明提出一种规范化哈夫曼编码方法,包括:9.步骤1、获取待规范的哈夫曼树数据;10.步骤2、自上而下地将该哈夫曼树数据中每一级节点中的叶子节点编码进行加1左移,以将该哈夫曼树数据中每一级节点中的叶子节点移到树结构的左侧,生成并存储该哈夫曼树数据的规范编码数据。11.所述的规范化哈夫曼编码方法,其中该哈夫曼树数据为字符序列,该步骤2包括:12.步骤21、将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;13.步骤22、提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;14.步骤23、提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;15.步骤24、提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;16.步骤25、用第四表减去该第三表,构成第五表;17.步骤26、按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;18.步骤27、按顺序集合该字符序列中所有字符的规范编码,得到该规范编码数据。19.所述的规范化哈夫曼解码方法,其中包括:20.步骤s1、获取待解码的规范编码数据,由从0开始累加的下标对该第四表和该第二表进行遍历,直到满足第四表中数值大于等于码流的前len位,得到当前码字数值、下标值、len值和该第四表中下标为0的值,其中len值为该第二表中有效码长;21.步骤s2、访问该第五表,用当前码字数值减去下标值对应的第五表中数值,得到字符排序,以该字符排序访问该第一表,得到该字符排序对应的字符。22.本发明还提出了一种基于规范化哈夫曼编码的神经网络计算芯片,其中包括:输入电路、运算电路以及存储电路;该运算电路包括主电路和从电路;23.输入电路,用于获取神经网络数据;24.该运算电路响应于量化指令,对该神经网络数据进行游程全零编码,得到游程压缩数据,其中该游程全零编码包括仅对该神经网络数据中的零字符进行游程编码;对该游程压缩数据进行哈夫曼编码,并自上而下地将编码结果中每一级节点中的叶子节点编码进行加1左移,以将该编码结果中每一级节点中的叶子节点移到树结构的左侧,生成该编码结果的规范哈夫曼编码,作为该神经网络数据的压缩结果;25.该存储电路,用于存储该压缩结果。26.所述的基于规范化哈夫曼编码的神经网络计算芯片,其中该编码结果为字符序列,该运算电路,用于将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;27.提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;28.提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;29.提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;30.用第四表减去该第三表,构成第五表;31.按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;32.按顺序集合该字符序列中所有字符的规范编码,得到该规范哈夫曼编码。33.本发明还提出了一种存储介质,用于存储所述任意一种规范化哈夫曼编码方法的程序。34.由以上方案可知,本发明的优点在于:35.1、针对量化后神经网络数据具有稀疏性的特点,本发明对游程编码进行了改进提出了游程全零编码,可以更高效的无损压缩神经网络数据;36.2、本发明的游程全零编码包括二阶字符替换,进一步提高了压缩效率的同时减少了数据中0出现的数量,为后续的哈夫曼编码留出了更多的压缩空间;37.3、对哈夫曼树自上而下地进行重整,省去存储完整的哈夫曼树结构,显著降低了查表操作的复杂程度。附图说明38.图1为哈夫曼树示例图;39.图2为哈夫曼树对应的编码结果表格图;40.图3和图4为规范化哈夫曼树示例图。具体实施方式41.本发明提出一种规范化哈夫曼编码方法,包括:42.步骤1、获取待规范的哈夫曼树数据;43.步骤2、自上而下地将该哈夫曼树数据中每一级节点中的叶子节点编码进行加1左移,以将该哈夫曼树数据中每一级节点中的叶子节点移到树结构的左侧,生成并存储该哈夫曼树数据的规范编码数据。44.所述的规范化哈夫曼编码方法,其中该哈夫曼树数据为字符序列,该步骤2包括:45.步骤21、将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;46.步骤22、提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;47.步骤23、提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;48.步骤24、提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;49.步骤25、用第四表减去该第三表,构成第五表;50.步骤26、按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;51.步骤27、按顺序集合该字符序列中所有字符的规范编码,得到该规范编码数据。52.所述的规范化哈夫曼解码方法,其中包括:53.步骤s1、获取待解码的规范编码数据,由从0开始累加的下标对该第四表和该第二表进行遍历,直到满足第四表中数值大于等于码流的前len位,得到当前码字数值、下标值、len值和该第四表中下标为0的值,其中len值为该第二表中有效码长;54.步骤s2、访问该第五表,用当前码字数值减去下标值对应的第五表中数值,得到字符排序,以该字符排序访问该第一表,得到该字符排序对应的字符。55.为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。56.规范化哈夫曼编码。同一个数据分布对应的哈夫曼编码并不唯一,这是由于在构建哈夫曼树的过程中可能出现频率相同的节点,为了更好地应用哈夫曼编码,我们需要一种固定且高效的构建哈夫曼树的方法,而通过这种方法产生的唯一的哈夫曼编码被称作规范化哈夫曼编码。57.哈夫曼树重整。具体地,本发明采用hsf编码作为规范化的哈夫曼编码。此编码的主要思想是将哈夫曼树自上而下地进行重整,同一级节点当中的叶子节点优先移到二叉树的左侧,在不改变频率分布的前提下使得所有编码都可以通过加1和加1左移来得到,进而用比较和加法运算替代复杂的二叉树遍历或完整的查表操作,极大地缩减了编解码所需的存储和计算开销。如图3、图4和表1所示,给定字符序列{u1,u2,u3,u4,u5}和任意的两组哈夫曼树,都可以用上述的重整方法找到它们的规范化形式。58.表1规范化哈夫曼编码示例[0059][0060][0061]码表重定义。可以看到,每一棵哈夫曼树都对应有其规范化形式,同时规范化后的码字之间具有硬件友好的运算规律:相同码长 1,不同码长 1后左移1位,我们可以利用这一规律重新定义码表,从而彻底省去存储完整的哈夫曼树结构,显著降低了查表操作的复杂程度。[0062]以上述待编码序列(a)为例,首先其编解码过程需要以下几种码表:[0063](1)chartable(第一表),所有待编码字符按照出现频率的降序排列,在例(a)当中即为{u1,u4,u5,u2,u3},编解码可以复用。[0064](2)lentable(第二表),所有有效码长的升序排列,例(a)当中的hsf编码只有2bit和3bit,对应的lentable为{2,3},编解码可以复用。[0065](3)rangetable(第三表),每个有效码长的最后一个码字对应的字符在chartable当中的排序下标,例(a)当中2bit和3bit的最后一个码字分别对应u5和u3,因此rangetable为{2,4},只在编码阶段使用。[0066](4)limittable(第四表),每个有效码长的最后一个码字的数值,例(a)当中2bit和3bit的最后一个码字分别为10和111,因此limittable为{2,7},只在解码阶段使用。[0067](5)basetable(第五表),limittable减去rangetable,例(a)当中的basetable为{0,3},编解码可以复用。[0068]在此基础上,给定例(a)当中的字符u4和上述编码表,产生其hsf编码的流程可以分为以下三个步骤:[0069]lookup,访问chartable,得到u4的排序rank,即rank(u4)=1;[0070]compare,访问rangetable,得到大于等于rank(u4)的第一项下标index,因为rank(u4)≤2,所以index(u4)=0;[0071]add,访问basetable和lentable,得到下标index对应的基值base和码长len,base与rank相加即为码字的数值,结合len就能够得到字符u4的hsf编码:base(u4)=0,len(u4)=2,code(u4)=0 1=1,所以最终的编码结果为01。[0072]对应地,我们可以推导出从一串形如01xxx的hsf码流中解析出第一个字符u4的解码流程:[0073]compare,访问limittable和lentable,由一个从0开始累加的下标index进行遍历,直到满足limit≥码流的前len位,因为limittable当中的下标为0的值limit≥码流的前2bit,所以index=0,limit=2,len=2,code=1;[0074]sub,访问basetable,用code值减去下标index对应的base值得到字符排序,即rank=1-0=1;[0075]lookup,访问chartable,得到排序rank对应的字符,因此最终的解码结果为chartable当中排序为1的项,也即字符u4。[0076]以上就是对规范化哈夫曼编码算法的介绍,可以看出hsf编码能够简化哈夫曼编码的存储和运算结构,同时自然地将编解码流程都切分为3级流水线,为硬件部署提供了高效且合理的实现方案。[0077]本文提出了规范化的哈夫曼编码,通过哈夫曼树重整和码表重定义,设计出了一种存储和计算非常精简的熵编码,用于对游程全零编码后的字符进行进一步的压缩。[0078]本发明还提出了一种基于规范化哈夫曼编码的神经网络计算芯片,其中包括:输入电路、运算电路以及存储电路;该运算电路包括主电路和从电路;[0079]输入电路,用于获取神经网络数据;[0080]该运算电路响应于量化指令,对该神经网络数据进行游程全零编码,得到游程压缩数据,其中该游程全零编码包括仅对该神经网络数据中的零字符进行游程编码;对该游程压缩数据进行哈夫曼编码,并自上而下地将编码结果中每一级节点中的叶子节点编码进行加1左移,以将该编码结果中每一级节点中的叶子节点移到树结构的左侧,生成该编码结果的规范哈夫曼编码,作为该神经网络数据的压缩结果;[0081]该存储电路,用于存储该压缩结果。[0082]所述的基于规范化哈夫曼编码的神经网络计算芯片,其中该编码结果为字符序列,该运算电路,用于将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;[0083]提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;[0084]提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;[0085]提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;[0086]用第四表减去该第三表,构成第五表;[0087]按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;[0088]按顺序集合该字符序列中所有字符的规范编码,得到该规范哈夫曼编码。当前第1页12当前第1页12
背景技术:
::2.熵编码是无损压缩算法的一个分支,在压缩解压的过程中按熵原理不会损失任何信息,其中信息熵表征信源不确定性的测度。熵编码算法的种类很多,本文主要介绍其中具有代表性的两种:哈夫曼编码和算术编码。3.哈夫曼编码(huffmancoding),由huffman在1952年首次提出,是一种基于最优二叉树(也称作哈夫曼树)结构的变长编码。其主要思想是待编码序列当中的每个字符(literal)都作为二叉树的叶节点,从而满足前缀编码(prefixcoding)的性质,即每个字符的编码都不是其它任何字符的编码前缀,以此降低解码的复杂程度。4.具体实现中,哈夫曼编码需要对每个字符进行词频统计,不断地将频率最小的两个子节点合并,作为其父节点的频率,递归直至产生根节点。如此生长出一棵二叉树的过程同时也是产生哈夫曼码表的过程,而每个字符的编码在哈夫曼树当中对应着根节点到其中一个叶节点的路径,分支向左则添加0,分支向右则添加1。图1给出了序列{aabbcccddddeeeee}对应的哈夫曼树,图2为这棵哈夫曼树对应的编码结果。5.从上述哈夫曼树的构建过程可以看到此编码具有两个特点:6.(1)词频越高的字符编码长度越小,因此整体字符序列的加权编码长度最优,因此哈夫曼编码被认为是压缩比最佳的熵编码。7.(2)同一个字符序列构建出的哈夫曼树并不唯一,比如举例当中字符a和b的父节点与字符d对应的叶节点频率相等,因此哈夫曼编码也有很多变种,不同的实现方式的硬件开销可能差别很大。技术实现要素:8.具体来说,本发明提出一种规范化哈夫曼编码方法,包括:9.步骤1、获取待规范的哈夫曼树数据;10.步骤2、自上而下地将该哈夫曼树数据中每一级节点中的叶子节点编码进行加1左移,以将该哈夫曼树数据中每一级节点中的叶子节点移到树结构的左侧,生成并存储该哈夫曼树数据的规范编码数据。11.所述的规范化哈夫曼编码方法,其中该哈夫曼树数据为字符序列,该步骤2包括:12.步骤21、将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;13.步骤22、提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;14.步骤23、提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;15.步骤24、提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;16.步骤25、用第四表减去该第三表,构成第五表;17.步骤26、按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;18.步骤27、按顺序集合该字符序列中所有字符的规范编码,得到该规范编码数据。19.所述的规范化哈夫曼解码方法,其中包括:20.步骤s1、获取待解码的规范编码数据,由从0开始累加的下标对该第四表和该第二表进行遍历,直到满足第四表中数值大于等于码流的前len位,得到当前码字数值、下标值、len值和该第四表中下标为0的值,其中len值为该第二表中有效码长;21.步骤s2、访问该第五表,用当前码字数值减去下标值对应的第五表中数值,得到字符排序,以该字符排序访问该第一表,得到该字符排序对应的字符。22.本发明还提出了一种基于规范化哈夫曼编码的神经网络计算芯片,其中包括:输入电路、运算电路以及存储电路;该运算电路包括主电路和从电路;23.输入电路,用于获取神经网络数据;24.该运算电路响应于量化指令,对该神经网络数据进行游程全零编码,得到游程压缩数据,其中该游程全零编码包括仅对该神经网络数据中的零字符进行游程编码;对该游程压缩数据进行哈夫曼编码,并自上而下地将编码结果中每一级节点中的叶子节点编码进行加1左移,以将该编码结果中每一级节点中的叶子节点移到树结构的左侧,生成该编码结果的规范哈夫曼编码,作为该神经网络数据的压缩结果;25.该存储电路,用于存储该压缩结果。26.所述的基于规范化哈夫曼编码的神经网络计算芯片,其中该编码结果为字符序列,该运算电路,用于将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;27.提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;28.提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;29.提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;30.用第四表减去该第三表,构成第五表;31.按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;32.按顺序集合该字符序列中所有字符的规范编码,得到该规范哈夫曼编码。33.本发明还提出了一种存储介质,用于存储所述任意一种规范化哈夫曼编码方法的程序。34.由以上方案可知,本发明的优点在于:35.1、针对量化后神经网络数据具有稀疏性的特点,本发明对游程编码进行了改进提出了游程全零编码,可以更高效的无损压缩神经网络数据;36.2、本发明的游程全零编码包括二阶字符替换,进一步提高了压缩效率的同时减少了数据中0出现的数量,为后续的哈夫曼编码留出了更多的压缩空间;37.3、对哈夫曼树自上而下地进行重整,省去存储完整的哈夫曼树结构,显著降低了查表操作的复杂程度。附图说明38.图1为哈夫曼树示例图;39.图2为哈夫曼树对应的编码结果表格图;40.图3和图4为规范化哈夫曼树示例图。具体实施方式41.本发明提出一种规范化哈夫曼编码方法,包括:42.步骤1、获取待规范的哈夫曼树数据;43.步骤2、自上而下地将该哈夫曼树数据中每一级节点中的叶子节点编码进行加1左移,以将该哈夫曼树数据中每一级节点中的叶子节点移到树结构的左侧,生成并存储该哈夫曼树数据的规范编码数据。44.所述的规范化哈夫曼编码方法,其中该哈夫曼树数据为字符序列,该步骤2包括:45.步骤21、将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;46.步骤22、提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;47.步骤23、提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;48.步骤24、提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;49.步骤25、用第四表减去该第三表,构成第五表;50.步骤26、按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;51.步骤27、按顺序集合该字符序列中所有字符的规范编码,得到该规范编码数据。52.所述的规范化哈夫曼解码方法,其中包括:53.步骤s1、获取待解码的规范编码数据,由从0开始累加的下标对该第四表和该第二表进行遍历,直到满足第四表中数值大于等于码流的前len位,得到当前码字数值、下标值、len值和该第四表中下标为0的值,其中len值为该第二表中有效码长;54.步骤s2、访问该第五表,用当前码字数值减去下标值对应的第五表中数值,得到字符排序,以该字符排序访问该第一表,得到该字符排序对应的字符。55.为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。56.规范化哈夫曼编码。同一个数据分布对应的哈夫曼编码并不唯一,这是由于在构建哈夫曼树的过程中可能出现频率相同的节点,为了更好地应用哈夫曼编码,我们需要一种固定且高效的构建哈夫曼树的方法,而通过这种方法产生的唯一的哈夫曼编码被称作规范化哈夫曼编码。57.哈夫曼树重整。具体地,本发明采用hsf编码作为规范化的哈夫曼编码。此编码的主要思想是将哈夫曼树自上而下地进行重整,同一级节点当中的叶子节点优先移到二叉树的左侧,在不改变频率分布的前提下使得所有编码都可以通过加1和加1左移来得到,进而用比较和加法运算替代复杂的二叉树遍历或完整的查表操作,极大地缩减了编解码所需的存储和计算开销。如图3、图4和表1所示,给定字符序列{u1,u2,u3,u4,u5}和任意的两组哈夫曼树,都可以用上述的重整方法找到它们的规范化形式。58.表1规范化哈夫曼编码示例[0059][0060][0061]码表重定义。可以看到,每一棵哈夫曼树都对应有其规范化形式,同时规范化后的码字之间具有硬件友好的运算规律:相同码长 1,不同码长 1后左移1位,我们可以利用这一规律重新定义码表,从而彻底省去存储完整的哈夫曼树结构,显著降低了查表操作的复杂程度。[0062]以上述待编码序列(a)为例,首先其编解码过程需要以下几种码表:[0063](1)chartable(第一表),所有待编码字符按照出现频率的降序排列,在例(a)当中即为{u1,u4,u5,u2,u3},编解码可以复用。[0064](2)lentable(第二表),所有有效码长的升序排列,例(a)当中的hsf编码只有2bit和3bit,对应的lentable为{2,3},编解码可以复用。[0065](3)rangetable(第三表),每个有效码长的最后一个码字对应的字符在chartable当中的排序下标,例(a)当中2bit和3bit的最后一个码字分别对应u5和u3,因此rangetable为{2,4},只在编码阶段使用。[0066](4)limittable(第四表),每个有效码长的最后一个码字的数值,例(a)当中2bit和3bit的最后一个码字分别为10和111,因此limittable为{2,7},只在解码阶段使用。[0067](5)basetable(第五表),limittable减去rangetable,例(a)当中的basetable为{0,3},编解码可以复用。[0068]在此基础上,给定例(a)当中的字符u4和上述编码表,产生其hsf编码的流程可以分为以下三个步骤:[0069]lookup,访问chartable,得到u4的排序rank,即rank(u4)=1;[0070]compare,访问rangetable,得到大于等于rank(u4)的第一项下标index,因为rank(u4)≤2,所以index(u4)=0;[0071]add,访问basetable和lentable,得到下标index对应的基值base和码长len,base与rank相加即为码字的数值,结合len就能够得到字符u4的hsf编码:base(u4)=0,len(u4)=2,code(u4)=0 1=1,所以最终的编码结果为01。[0072]对应地,我们可以推导出从一串形如01xxx的hsf码流中解析出第一个字符u4的解码流程:[0073]compare,访问limittable和lentable,由一个从0开始累加的下标index进行遍历,直到满足limit≥码流的前len位,因为limittable当中的下标为0的值limit≥码流的前2bit,所以index=0,limit=2,len=2,code=1;[0074]sub,访问basetable,用code值减去下标index对应的base值得到字符排序,即rank=1-0=1;[0075]lookup,访问chartable,得到排序rank对应的字符,因此最终的解码结果为chartable当中排序为1的项,也即字符u4。[0076]以上就是对规范化哈夫曼编码算法的介绍,可以看出hsf编码能够简化哈夫曼编码的存储和运算结构,同时自然地将编解码流程都切分为3级流水线,为硬件部署提供了高效且合理的实现方案。[0077]本文提出了规范化的哈夫曼编码,通过哈夫曼树重整和码表重定义,设计出了一种存储和计算非常精简的熵编码,用于对游程全零编码后的字符进行进一步的压缩。[0078]本发明还提出了一种基于规范化哈夫曼编码的神经网络计算芯片,其中包括:输入电路、运算电路以及存储电路;该运算电路包括主电路和从电路;[0079]输入电路,用于获取神经网络数据;[0080]该运算电路响应于量化指令,对该神经网络数据进行游程全零编码,得到游程压缩数据,其中该游程全零编码包括仅对该神经网络数据中的零字符进行游程编码;对该游程压缩数据进行哈夫曼编码,并自上而下地将编码结果中每一级节点中的叶子节点编码进行加1左移,以将该编码结果中每一级节点中的叶子节点移到树结构的左侧,生成该编码结果的规范哈夫曼编码,作为该神经网络数据的压缩结果;[0081]该存储电路,用于存储该压缩结果。[0082]所述的基于规范化哈夫曼编码的神经网络计算芯片,其中该编码结果为字符序列,该运算电路,用于将该字符序列中所有待编码字符按照出现频率的降序排列,构成第一表;[0083]提取该字符序列中涉及的所有有效码长,升序排列所有有效码长,构成第二表;[0084]提取该字符序列中各有效码长的最后一个码字对应的字符在该第一表中的排序下标,构成第三表;[0085]提取该字符序列中每个有效码长的最后一个码字的数值,构成第四表;[0086]用第四表减去该第三表,构成第五表;[0087]按顺序依次提取该字符序列中字符作为当前字符,通过访问该第一表,得到当前字符的排序;访问该第三表,得到大于等于该排序的第一项下标index;访问该第五表和该第二表,得到下标对应的基值和码长,该基值与该排序相加作为当前字符的码字数值,以该码长表示该码字数值即为当前字符的规范编码;[0088]按顺序集合该字符序列中所有字符的规范编码,得到该规范哈夫曼编码。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。