1.本发明涉及基于参数迁移的越南语依存句法分析方法,属于自然语言处理领域。
背景技术:
2.在自然语言处理中,依存句法分析旨在识别句子中词与词之间的句法依赖关系。依存句法能为信息抽取、自动问答和机器翻译等任务提供句法特征,提高模型性能。
3.尽管已有的依存句法分析方法在特征编码、依存关系打分和解码等方面开展了大量的研究工作,也有效提升了依存句法分析的效果。但对于缺乏标注语料的越南语,人工标注需要耗费大量的人力物力,且得到的语料数据与标准标注数据之间存在很大的差距。同时,基于映射或反向翻译等方式获得的越南语标注语料与标准语料也存在一定的偏差。且越南语依存句法分析模型也存在由于缺少语料造成的模型泛化能力差、学习不充分等问题。但不同于短语结构分析对语言语法规则有固定结构要求,依存句法分析更关注句子中词语之间的语法联系,不同语言之间有共通联系,词性标注在不同语言之间存在共性特征。
技术实现要素:
4.本发明提供了基于参数迁移的越南语依存句法分析方法,使用参数迁移的方式,将从语料丰富语言学习到的依存句法分析先验知识应用到语料稀缺的越南语依存句法分析的学习当中,可以在一定程度上缓解训练语料不足所导致的模型训练效果较差,学习不充分等问题。
5.发明技术方案:基于参数迁移的越南语依存句法分析方法,所述方法的具体步骤如下:
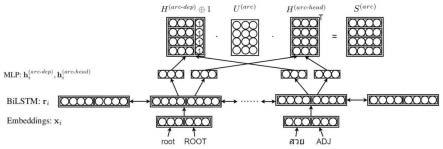
6.step1、对双仿射基模型进行拆解,将词语与词性标注部分分开,每个部分都会经过编码层、bilstm层以及mlp层,从而构造英语依存句法分析训练模型。
7.step2、训练英语依存句法分析模型,并得到词性标注部分训练参数。在训练越南语依存句法分析模型时,使用英语训练模型得到的词性标注参数,并继续训练越南语依存句法分析模型。
8.所述步骤step1的具体步骤为:
9.step1.1、双仿射模型拆解,将英语的词语与词性标注分别进行embedding编码,得到英语单词向量w
w_ei
和英语词性标注向量t
p_ei
,英语词语与词性标注的特征向量分别进入对应训练模块。
10.step1.2、英语单词向量w
w_ei
,进入bilstm层后得到相应w
w_ei
的上下文特征r
w_ei
;英语词性标注向量t
p_ei
进入bilstm层得到相应t
p_ei
的上下文特征r
p_ei
;
11.step1.3、经过bilstm层后得到r
w_ei
和r
p_ei
,二者分别经过对应的mlp层,词语部分得到特征和词性标注部分得到特征和
[0012][0013]
step1.4、英语词语与对应词性标注都走完embedding层、bilstm层和mlp层之后,将特征向量重新进行相应连接,得到连接特征和
[0014][0015]
step1.5、得到连接之后对应的特征向量和之后进入双仿射打分器中进行打分,得到英语句子依存句法分析的相应分数矩阵,将英语的训练模型训练完成。
[0016]
所述步骤step2的具体步骤为:
[0017]
step2.1、英语依存句法分析模型训练完成后,将模型参数进行保存。
[0018]
step2.2、构建越南语依存句法分析模型,在embedding词嵌入阶段将越南语单词向量w
vi
和对应词性标注向量t
vi
进行拼接,得到向量
[0019]
step2.3、在得到输入特征x
vi
后,将之通过bilstm层并得到每个输入元素的上下文特征r
vi
。
[0020]
step2.4、特征r
vi
经过两个不同的用于降维的多层感知机mlp后分别得到特征和
[0021][0022]
step2.5、进入双仿射打分层得到分数矩阵其中u
(1)
是k
×
k维的中间变换矩阵,u
(2)
是k
×
1维的变换矩阵,矩阵h是d个token的特征经过mlp二次编码出来的特征向量h的堆栈形式,其维度为d
×
k;
[0023][0024]
本发明的有益效果是:
[0025]
(1)将参数迁移方法应用于依存句法分析任务中,针对越南语模型泛化能力差,学习不充分等问题提出了基于参数迁移的越南语依存句法分析方法,有效解决问题。
[0026]
(2)针对词性标注可以帮助提升依存句法分析效果的特点,将英语模型拆解训练
得到的词性标注训练参数应用于越南语模型训练,有效提升了越南语依存句法分析模型性能。
附图说明
[0027]
图1是本发明所使用的基线模型;
[0028]
图2是本发明提出的基于参数迁移的越南语依存句法分析方法对应的模型图。
具体实施方式
[0029]
实施例1:如图1和图2所示,基于参数迁移的越南语依存句法分析方法,所述方法的具体步骤如下:
[0030]
step1、对双仿射基模型进行拆解,将词语与词性标注部分分开,每个部分都会经过编码层、bilstm层以及mlp层,从而构造英语依存句法分析训练模型。
[0031]
step1.1、双仿射模型拆解,将英语的词语与词性标注分别进行embedding编码,得到英语单词向量w
w_ei
和英语词性标注向量t
p_ei
,英语词语与词性标注的特征向量分别进入对应训练模块;
[0032]
step1.2、英语单词向量w
w_ei
,进入bilstm层后得到相应w
w_ei
的上下文特征r
w_ei
;英语词性标注向量t
p_ei
进入bilstm层得到相应t
p_ei
的上下文特征r
p_ei
;
[0033]
step1.3、经过bilstm层后得到r
w_ei
和r
p_ei
,二者分别经过对应的mlp层,词语部分得到特征和词性标注部分得到特征和
[0034][0035]
step1.4、英语词语与对应词性标注都走完embedding层、bilstm层和mlp层之后,将特征向量重新进行相应连接,得到连接特征和
[0036][0037][0038]
step1.5、得到连接之后对应的特征向量和之后进入双仿射打分器中进行打分,得到英语句子依存句法分析的相应分数矩阵,将英语的训练模型训练完成。
[0039]
step2、训练英语依存句法分析模型,并得到词性标注部分训练参数。在训练越南语依存句法分析模型时,使用英语训练模型得到的词性标注参数,并继续训练越南语依存
句法分析模型。
[0040]
step2.1、英语依存句法分析模型训练完成后,将模型参数进行保存。
[0041]
step2.2、构建越南语依存句法分析模型,在embedding词嵌入阶段将越南语单词向量w
vi
和对应词性标注向量t
vi
进行拼接,得到向量
[0042]
step2.3、在得到输入特征x
vi
后,将之通过bilstm层并得到每个输入元素的上下文特征r
vi
。
[0043]
step2.4、特征r
vi
经过两个不同的用于降维的多层感知机mlp后分别得到特征和
[0044][0045]
step2.5、进入双仿射打分层得到分数矩阵其中u
(1)
是k
×
k维的中间变换矩阵,u
(2)
是k
×
1维的变换矩阵,矩阵h是d个token的特征经过mlp二次编码出来的特征向量h的堆栈形式,其维度为d
×
k;
[0046][0047]
为了说明本发明的效果,设置了2组对比实验。第一组实验时英语数据集训练模型拆解前后结果对比,第二组实验是不同参数迁移形式下越南语依存句法分析结果对比。
[0048]
(1)英语数据集训练模型拆解前后结果对比
[0049]
在双仿射基模型基础上进行拆解,构建英语依存句法分析训练模型,模型拆解前后实验结果如表1所示。
[0050]
表1 ud英语数据集基于双仿射的迁移模型拆解前后结果对比
[0051][0052][0053]
通过表1可以发现,在英语训练模型拆解后无论是在开发集的uas、las结果上还是在测试集的uas和las的结果上都出现了一定的下降。这是因为英语训练模型拆解后,在进行输入embedding编码时,将英语句子中的单词和对应的词性标注编码后分开进入bilstm层中,所以在进行上下文联系时,对于一个句子的完整结构会有一定缺漏,并且也相应缺少了单词与词性标注整合在一起,与上下文相互呼应的特征信息。虽然在mlp层之后,将二者信息进行了重新的连接,但在前期模型调整时缺少了关联信息,所以也会在一定程度上影响实验结果。
[0054]
(2)不同参数迁移形式下越南语依存句法分析结果对比
[0055]
对于不同参数迁移形式下越南语依存句法分析的结果做对比实验,验证词性标注对于越南依存句法分析的有效性,以及本方法的效果提升。
[0056]
第一种参数迁移形式(c_none):越南语训练模型同英语训练模型一样均进行拆分。但在越南语依存句法分析模型训练时,参数均重新初始化,不使用英语训练模型的参数。
[0057]
第二种参数迁移形式(c_half_words):越南语训练模型同英语训练模型一样均进行拆分。在参数迁移时,只迁移词语部分的训练参数,即越南语拆解模型训练时,词性标注部分的模型参数重新初始化,词语部分的参数使用英语模型训练好的词语部分的参数。
[0058]
第三种参数迁移形式(c_half_pos):越南语训练模型同英语训练模型一样均进行拆分。在参数迁移时,只迁移词性标注部分的训练参数,即越南语拆解模型训练时,词语部分的模型参数重新初始化,词性标注部分的参数使用英语模型训练好的词性标注部分的参数。
[0059]
第四种参数迁移形式(c_whole):越南语训练模型同英语训练模型一样均进行拆分。在参数迁移时,迁移词语部分以及词性标注部分的训练参数,即越南语拆解模型训练时,词语部分的模型参数以及词性标注部分的参数均使用英语模型训练好的参数。
[0060]
第五种参数迁移形式(e_half_word):第五种参数迁移的形式为越南语依存句法分析的训练模型使用原始双仿射模型,训练参数则使用英语模型训练好的词语部分的参数。
[0061]
第六种参数迁移形式(e_half_pos):第六种参数迁移的形式为越南语依存句法分析的训练模型使用原始双仿射模型,训练参数则使用英语模型训练好的词性标注部分的参数。
[0062]
实验结果如表2所示:
[0063]
表2不同参数迁移形式下越南语依存句法分析结果对比
[0064][0065][0066]
表2展示出了不同参数迁移形式下越南语依存句法结果的对比情况,从中可以发现,提出的参数迁移方法效果最佳。从基模型与c_none的结果对比中可以发现,对于越南语来说,在模型embedding阶段将词语部分和词性标注部分分开编码,分开训练会造成模型性能的降低,在编码阶段词语和词性标注的连结可以有助于训练模型更好的学习到这两部分的关联特征信息,有助于提升依存句法分析的打分过程的准确性。从c_none、c_half_words和c_half_pos三种参数迁移形式的结果对比中,可以发现,迁移学习英语词语部分的参数,初始化越南语词性标注部分的参数对越南语依存句法分析效果的提升虽然有一定的帮助,
但相比来说,迁移学习英语词性标注部分的参数而初始化越南语词语部分的参数可以更好的提升越南语依存句法分析的效果。但从c_whole的结果中可以发现,若两部分的参数同时迁移使用,对测试集的效果提升更加明显,对验证集的提升并不明显。对比e_half_word、e_half_pos和上述实验结果可以发现,英语训练模型进行拆解,越南语训练模型保持基模型状态,在此基础上进行参数的迁移性能提升的结果更加优异,说明在保持越南语训练模型编码阶段词语部分和词性标注部分的连结是很有必要的,获取两者的关联特征以及共同训练也是很重要的。同时对比e_half_word和e_half_pos这两种参数迁移形式下的结果也能够发现,词性标注部分的特征信息对于越南语依存句法分析的效果提升是更加有用的。
[0067]
通过以上实验数据证明了本发明使用基于参数迁移的越南语依存句法分析方法能够解决越南语依存句法分析语料稀缺情况下模型泛化能力差、学习不充分等问题。实验表明本发明的方法相比基线模型取得了一定的提升效果。针对低资源条件下越南语依存句法分析任务,本发明提出的基于参数迁移的越南语依存句法分析方法对提升越南语依存句法分析性能是有效的。
[0068]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
