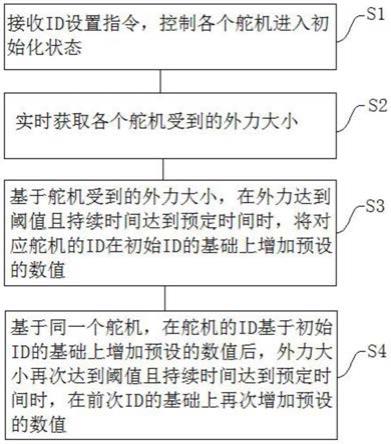
处理图形处理器中的工作负荷的方法和图形处理设备
1.本技术要求于2020年8月25日提交的题为“用于传递感知高速缓存分配的系统、方法和装置”第63/070,254号美国临时专利申请的优先权和权益,所述美国临时专利申请通过引用被包含。
技术领域
2.本公开总体涉及图形处理,并且更具体地,涉及用于在图形处理器中实现高速缓存策略的方法和设备。
背景技术:
3.gpu中的存储器子系统可被构造为具有主存储器和各级高速缓存的层级(hierarchy)。高速缓存策略可被应用于层级以指定高速缓存分配策略、替换策略等。
4.在该背景技术部分中公开的上述信息仅用于增强对发明的背景技术的理解,因此其可包含不构成现有技术的信息。
技术实现要素:
5.一种处理图形处理单元(gpu)中的工作负荷的方法可包括:检测gpu中的工作负荷的工作项,确定用于工作项的高速缓存策略,以及基于高速缓存策略,针对工作项的至少一部分来操作gpu中的高速缓存存储器层级的至少一部分。可基于从应用接收的信息来检测工作项。可基于监测一个或多个性能计数器来检测工作项。所述一个或多个性能计数器中的至少一个性能计数器可由驱动器监测。所述一个或多个性能计数器中的至少一个可由硬件检测逻辑来监测。可基于来自用户的存储器请求来确定高速缓存策略。存储器请求可包括工作项标识符(id)。用于工作项的高速缓存策略可包括静态高速缓存策略。用于工作项的高速缓存策略可包括动态高速缓存策略。可基于工作项的标识来确定用于工作项的高速缓存策略。可将工作项的标识映射到高速缓存策略。所述方法还可包括监测一个或多个性能计数器,其中,用于工作项的高速缓存策略可基于所述一个或多个性能计数器来确定。用于工作项的高速缓存策略可被映射到一个或多个性能计数器。所述方法还可包括监测一个或多个性能计数器,其中,用于工作项的高速缓存策略可基于工作项的标识和所述一个或多个性能计数器的组合来确定。所述方法还可包括监测一个或多个性能计数器,以及基于所述一个或多个性能计数器来改变用于工作项的高速缓存策略。高速缓存策略可包括第一高速缓存策略,所述方法还可包括基于所述一个或多个性能计数器来确定用于工作项的第二高速缓存策略,以及选择第一高速缓存策略或第二高速缓存策略中的一个来用于工作项。可基于运行时学习模型来选择用于工作项的高速缓存策略。
6.一种设备可包括:图形处理管道,包括一个或多个用户;高速缓存存储器层级,被配置为处理来自所述一个或多个用户的存储器请求;以及策略选择逻辑,被配置为:针对所述一个或多个用户中的至少一个用户,确定用于工作项的高速缓存策略,并且针对工作项的至少一部分,将高速缓存策略应用于高速缓存存储器层级的至少一部分。所述设备还可
包括:检测逻辑,被配置为检测工作项。策略选择逻辑的至少一部分可设置在中央逻辑单元中。策略选择逻辑的至少一部分可设置在所述一个或多个用户中的至少一个用户中。策略选择逻辑的至少一部分可设置在高速缓存存储器层级中。
7.一种存储器子系统可包括:存储器接口;高速缓存存储器层级,被配置为处理通过存储器接口的来自一个或多个用户的存储器请求;以及策略选择逻辑,被配置为:针对所述一个或多个用户中的至少一个用户确定用于工作项的高速缓存策略,并且针对工作项的至少一部分将高速缓存策略应用于高速缓存存储器层级的至少一部分。所述存储器子系统还可包括:检测逻辑,被配置为检测工作项。
附图说明
8.附图不一定按比例绘制,并且在整个附图中,为了说明的目的,类似结构或功能的元件通常由相同的参考标号或相同的参考标号的部分表示。附图仅旨在便于描述在此公开的各种实施例。附图没有描述在此公开的教导的每个方面,并且不限制权利要求的范围。附图与说明书一起示出了本公开的示例实施例,并且与说明书一起用于解释本公开的原理。
9.图1示出了根据本公开的可实现工作项感知高速缓存策略的系统的实施例。
10.图2示出了根据本公开的可实现工作项感知高速缓存策略的系统的示例实施例。
11.图3示出了根据本公开的用于实现工作项感知高速缓存策略的方法的示例实施例。
12.图4示出了根据本公开的工作项感知流量控制器的示例实施例。
13.图5示出了根据本公开的可基于离线学习来实现静态策略选择的工作项感知流量控制器的示例实施例。
14.图6示出了根据本公开的可基于性能计数器和离线学习来实现动态策略选择的工作项感知流量控制器的示例实施例。
15.图7示出了根据本公开的可基于性能计数器和在线学习来实现动态策略选择的工作项感知流量控制器的示例实施例。
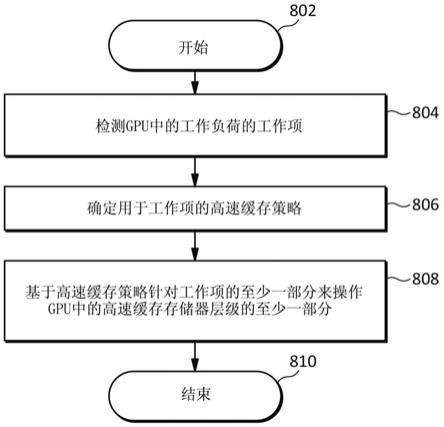
16.图8示出了根据本公开的处理gpu中的工作负荷的方法的实施例。
17.图9示出了本公开中所描述的方法或设备中的任一个可被集成到其中的图像显示装置的实施例。
18.图10示出了根据本公开的包括可实现工作项感知高速缓存策略的gpu的片上系统(soc)装置的实施例。
具体实施方式
19.概述
20.本公开的一些原理涉及针对gpu工作负荷中的不同工作项使用不同的高速缓存策略。通过基于不同的工作项的流量模式应用不同的高速缓存策略,一些实施例可例如通过增加高速缓存命中率、增加有效高速缓存容量、和/或减少各种高速缓存级和/或主存储器之间的数据移动来改善性能和/或降低功耗。
21.本公开的一些原理涉及用于检测工作项和/或不同工作项之间的边界的各种方法和设备。例如,在一些实施例中,可通过应用编程接口(api)从应用和/或程序员接收一个或
多个提示来检测工作项。作为附加示例,在各种实施例中,可通过监测和识别可指示流量行为(诸如,图中的顶点或图元的数量、使用中的渲染目标的数量、存储器单元的分配、管道状态、使用中的资源的数量和/或类型、使用中的数据格式和/或元数据、图中的顶点与图元的比率、颜色和/或深度数据访问与纹理访问的比率、正被访问的数据区域、高速缓存冲刷和/或同步等)的变化的一个或多个性能计数器的变化,在驱动器级和/或硬件级检测工作项或连续工作项之间的边界。
22.本公开的一些原理涉及用于针对不同工作项实现各种高速缓存策略的方法和设备。一些实施例可实现静态策略、动态策略和/或策略的混合组合。例如,可基于识别工作项和/或其特性来针对该工作项实现静态高速缓存策略。例如,可使用针对各种工作项的流量模式的离线学习以及将工作项映射到可针对特定工作项被优化的高速缓存策略来确定静态策略。
23.作为另一示例,可使用运行时学习算法来实现动态策略。例如,可在运行时将各种高速缓存策略应用于工作项,并且可监测所得到的性能以提供对每个策略的有效性的反馈。然后可在工作项的持续时间内选择并应用有效或最佳策略。可选地,可继续监测所选择的策略的性能,并且可基于检测到的策略有效性的变化来修改策略。
24.作为另一示例,可基于离线学习和性能计数器(诸如,每秒帧数(fps)、命中率等)的混合组合来实现动态策略。例如,可使用离线学习来确定用于工作项的多个高速缓存策略,其中,每个高速缓存策略对于不同的性能计数器集合可以是有效的或最佳的。在运行时,可基于工作项的标识(identity)和当前性能计数器的组合来选择高速缓存策略。在一个示例中,工作项的标识可以是工作项标识符(id)。
25.在此公开的原理具有独立的实用性并且可单独实现,而不是每个实施例都可利用每个原理。此外,原理还可以以各种组合来实现,一些组合可以以协同的方式放大各个原理的益处。
26.工作负荷和高速缓存策略
27.gpu可包括具有各种组件或级(诸如,命令处理器、光栅化器、着色器、纹理单元等)的管道。为了执行它们的功能,这些组件可访问存储器子系统,存储器子系统可包括例如主存储器和具有一个或多个级的高速缓存存储器层级。gpu工作负荷可包括通过组件中的一个或多个执行图形处理操作的各种子步骤(sub-pass)。对于不同类型的数据(诸如,颜色、深度、纹理等),不同的子步骤可具有不同的运行时流量模式(也称为流量行为)。这些流量模式可在不同的渲染子步骤之间改变,每个渲染子步骤可在渲染管道中执行不同的任务(诸如,产生几何形状和/或照明、应用后处理效果等)。
28.最佳高速缓存策略可取决于访问高速缓存层级的子步骤的流量模式。然而,由于各个渲染子步骤的流量模式可能基本上彼此不同,因此对于一个子步骤可很好地工作的高速缓存策略对于其他子步骤可能是有害的。由于gpu工作负荷可包括具有不同流量模式的多个子步骤,因此gpu可实现进行权衡以为整个工作负荷提供最佳整体性能的高速缓存策略。然而,这可能导致一些子步骤的性能显著降低。
29.工作项感知高速缓存(aware cache)策略
30.图1示出了根据本公开的可实现工作项感知高速缓存策略的系统的实施例。图1中所示的系统可包括图形处理管道(graphics processing pipeline)102、存储器子系统104
和流量控制逻辑(traffic control logic)106。管道102可包括可通过存储器请求110访问存储器子系统104的任何类型和/或任何数量的用户(client)108。用户108的示例可包括命令处理器、几何单元(geometry unit)、光栅化器(rasterizer)、着色器(shader)、纹理单元、渲染缓冲器(例如,色彩缓冲器、深度缓冲器等)、属性提取器和/或任何其他管道子块等。在一些实施例中,用户可包括可访问存储器子系统104的任何实体(包括用户内的资源)。
31.存储器子系统104可包括一个或多个主存储器118以及一个或多个高速缓存存储器层级(也称为高速缓存层级)120,每个高速缓存存储器层级120可包括任何类型和/或任何数量的高速缓存存储器。例如,在一些实施例中,存储器子系统104可包括具有单个高速缓存的高速缓存层级,而在其他实施例中,高速缓存层级可具有一个或多个1级(l1)高速缓存、2级(l2)高速缓存和/或3级(l3)高速缓存。在一些实施例中,一个或多个主存储器可被认为是高速缓存存储器层级的一部分。
32.流量控制逻辑106可包括利用高速缓存流量模式中的空间和/或时间局部性来实现针对由管道102执行的不同工作项的不同高速缓存策略(例如,分配策略、替换策略、可共享性等)的功能。工作项的示例可包括步骤(pass)、子步骤、阶段(phase)等、和/或它们的任何部分。在一些实施例中,工作项可包括具有可受益于特定高速缓存策略的存储器流量特性的时间和/或处理的任何描绘。
33.在一些实施例中,控制逻辑106可包括工作项检测逻辑112、策略选择逻辑114和/或学习逻辑116。工作项检测逻辑112可包括用于检测工作项和/或不同工作项之间的边界的功能。(在一些实施例中,检测工作项和/或检测不同工作项之间的边界可被统称为检测工作项。)工作项检测逻辑112可在api级、驱动器级、硬件级、和/或它们的任何组合进行操作。
34.策略选择逻辑114可包括针对管道102中的一个或多个用户以及存储器子系统104中的一个或多个高速缓存层级或它们的部分选择和/或实现一个或多个高速缓存策略的功能。在一些实施例中,高速缓存策略可以是静态的、动态的和/或它们的任何组合。在一些实施例中,可基于用户信息和/或特性、工作项信息和/或特性、性能计数器(performance counter)、学习到的特性和/或特性行为、和/或它们的任何组合来实现高速缓存策略。
35.学习逻辑116可包括在一些情况下基于所应用的高速缓存策略来监测和/或学习工作项和/或工作项性能的特性、流量模式等的功能,监测可包括开环监测和/或闭环监测。学习算法可在线、离线和/或以它们的任何组合来实现。
36.在一些实施例中,流量控制功能可以以集中式方式(例如,大部分或完全)在流量控制逻辑106内实现。在其他实施例中,流量控制逻辑106中的一些或全部可以以分布式方式实现,包括分布在一个或多个其他组件中,如虚线所示,流量控制逻辑106a和106b分别位于管道102(和/或管道102的组件)和/或存储器子系统104(和/或存储器子系统104的组件)中。因此,工作项检测逻辑112、策略选择逻辑114和/或学习逻辑116中的一些或全部也可分布在整个系统中,包括分布在整个系统的其他组件中。
37.流量控制逻辑106可用硬件、软件或它们的任何组合来实现。例如,在可至少部分地用硬件实现的一些实施例中,控制逻辑可包括电路(诸如,组合逻辑、顺序逻辑)、一个或多个定时器、计数器、寄存器、状态机、易失性存储器(诸如,动态随机存取存储器(dram)和/
或静态随机存取存储器(sram))、非易失性存储器(诸如,闪存)、复杂可编程逻辑器件(cpld)、现场可编程门阵列(fpga)、应用专用集成电路(asic)、执行指令的复杂指令集计算机(cisc)和/或精简指令集计算机(risc)处理器等,以执行它们各自的功能。尽管被示出为多个个体组件,但在一些实施例中,工作项检测逻辑112、策略选择逻辑114和/或学习逻辑116可被集成到单个组件中,和/或被示出为单个组件的一些组件可用多个组件来实现。例如,在一些实施例中,学习逻辑116可被集成到策略选择逻辑114中。
38.出于说明本公开的原理的目的,下面可在一些具体实现细节的情况下描述一些示例实施例。然而,本公开原理不限于这些示例细节。
39.为了方便起见,贯穿本公开,工作项可表示整个工作项和/或工作项的一部分两者。类似地,工作项可表示工作项和/或工作项之间的边界两者。同样为了方便起见,层级可表示整个层级和/或层级的一部分两者。
40.图2示出了根据本公开的可实现工作项感知高速缓存策略的系统的示例实施例。图2中所示出的系统可包括图形处理管道202、存储器子系统204和流量控制逻辑206。出于说明的目的,管道202被示出具有可通过存储器请求210访问存储器子系统204的呈子块形式的一系列用户,包括命令处理器218、几何单元220、光栅化器222、一个或多个着色器224以及纹理单元226,但其他实施例可具有任何其他数量和/或类型的用户。
41.同样出于说明的目的,存储器子系统204被示出为具有高速缓存层级以及主存储器234和存储器接口236,高速缓存层级具有l1高速缓存228、l2高速缓存230和l3高速缓存232,但是其他实施例可具有任何其他数量和/或类型的组件。在一些实施例中,存储器接口可包括一个或多个总线、仲裁器等。用于存储器请求210的存储器可位于主存储器234和/或l1高速缓存、l2高速缓存和/或l3高速缓存中,并且使用数据、地址类型和/或其他信息238来访问。
42.在一些实施例中,流量控制逻辑206可包括工作项检测逻辑、策略选择逻辑和/或学习逻辑。在一些实施例中,流量控制逻辑206可以以如图2中所示的集中式方式实现,但是在其他实施例中,流量控制逻辑206中的一些或全部可分布在整个系统中。例如,在一些实施例中,可在一个或多个子块中实现工作项感知流量逻辑,以使得子块能够做出其自己的策略决策。在这样的实施例中,子块可选择高速缓存策略并将所选择的高速缓存策略与存储器请求一起发送到存储器子系统204。存储器请求还可包括可由存储器子系统204用来设置用于工作项或工作项的一部分的策略的工作项标识符(id)。作为另一示例,在一些实施例中,工作项感知流量逻辑可在l1高速缓存、l2高速缓存和/或l3高速缓存中的一个或多个中被实现为例如本地状态机(localized state machine)。
43.软件驱动器可向管道202提供输入240(诸如,命令、图、顶点、图元等)。驱动器还可向流量控制逻辑206提供工作项信息242。在一些实施例中,工作项信息可包括工作项id、工作项的存储器特性(例如,可指示从工作项预期的流量行为的特性)等。
44.流量控制逻辑206还可接收和监测性能计数器244,性能计数器244可例如在软件驱动器和/或硬件级实现。流量控制逻辑206可从l1高速缓存、l2高速缓存和/或l3高速缓存、和/或主存储器234中的任何一个或全部接收和监测附加性能计数器248(诸如,命中率、流量模式等)。附加信息246(诸如,用户信息、工作项信息等)可通过存储器接口236被传递到流量控制逻辑206。
45.流量控制逻辑206可例如通过向l1高速缓存、l2高速缓存和/或l3高速缓存、和/或主存储器234发送一个或多个分配级、替换策略、可共享性策略等,将一个或多个高速缓存策略250应用于用于一个或多个工作项和/或一个或多个工作项的一部分的高速缓存层级。
46.在一些实施例中,图1和图2中所示的系统可例如通过提高高速缓存命中率和/或有效高速缓存容量、和/或通过减少高速缓存层级的各个级以及主存储器之间的数据移动,实现可提高性能和/或降低功耗的工作项感知策略。取决于实现细节,可降低gpu核存储器层级以及存储器互连和/或主存储器和相关联的高速缓存中的功耗。在一些实施方式中,功率降低可扩展到最低(或最后)级高速缓存(llc),llc可以是例如gpu和/或其他组件(诸如,多媒体块)之上的一级。在一些实施例中,在此公开的系统和/或方法中的一个或多个可在对应用和/或驱动器进行很少修改或没有修改的情况下实现。
47.如上面关于图1和图2中所示的实施例所描述的,流量控制逻辑206可用硬件、软件或它们的任何组合来实现。
48.关于图2中所示的实施例以及在此描述的任何其他实施例描述的操作、组件、连接、数据流等是示例操作、示例组件、示例连接、示例数据流等。在一些实施例中,可省略这些元件中的一些和/或可包括其他元件。在一些实施例中,可改变操作、组件、连接、数据流等的时间和/或空间顺序。此外,在一些实施例中,多个操作、多个组件、多个连接、多个数据流等可组合成单个元件,和/或单个操作、单个组件、单个连接、单个数据流等可分布在多个元件之间。
49.运行时操作
50.图3示出了根据本公开的用于实现工作项感知高速缓存策略的方法的示例实施例。图3中所示的方法可例如使用系统(诸如,图1和图2中所示的系统)来实现,但是图3中所示的方法不限于图1和图2中描述的任何具体细节。
51.可在api检测操作302、软件驱动器检测操作304、硬件检测操作306和/或它们的组合,检测新工作项和/或边界(工作项和/或边界可统称为工作项)。如果在操作308未检测到新工作项,则高速缓存层级可在操作310继续使用当前工作项感知高速缓存策略。
52.如果在操作308检测到新工作项,则所采用的路径可取决于如何检测工作项。例如,如果由api操作302检测到新工作项,则该方法可进行到操作312,在操作312,api可向软件驱动器通知新工作项并进行到操作314。如果由软件驱动器检测操作304检测到新工作项,则该方法可跳过操作312并进行到操作314,在操作314,驱动器可向一个或多个用户(例如,纹理单元、着色器、光栅化器等)通知新工作项并进行到操作316。如果由硬件检测操作306检测到新工作项,则该方法可跳过操作312和操作314并进行到操作316,在操作316,一个或多个用户可更新工作项信息(诸如,工作项id、工作项的存储器特性等)。
53.然后,该方法可进行到操作318,在操作318,工作项中涉及的一个或多个用户可将可能包括工作项信息的一个或多个存储器请求发送到存储器子系统。在操作320,工作项感知策略选择逻辑可拦截一些或所有存储器请求(例如,与新工作项中涉及的用户有关的那些存储器请求)。在操作322,可将用于新工作项的更新的高速缓存策略应用于一个或多个用户和一个或多个高速缓存(例如,涉及新工作项的那些用户和高速缓存)。
54.在一些实施例中,该方法然后可进行到操作310,在操作310,高速缓存层级可在工作项的持续时间内继续使用当前工作项感知高速缓存策略。在一些其他实施例中,该方法
可通过操作324进行循环,在操作324,可监测一个或多个性能计数器。然后可基于性能计数器来更新当前高速缓存策略。在一些实施例中,该方法可通过操作324进行有限次数循环,例如,直到工作项的流量模式被确定,并且适当的高速缓存策略被应用于高速缓存层级。在其他实施例中,该方法可在工作项的持续时间内继续通过操作324进行循环,以基于通过监测性能计数器确定的改变的流量模式来连续地调整高速缓存策略。
55.关于图3中所示的实施例以及在此描述的任何其他实施例描述的操作、组件、连接、数据流等是示例操作、示例组件、示例连接、示例数据流等。在一些实施例中,可省略这些元件中的一些和/或可包括其他元件。在一些实施例中,可改变操作、组件、连接、数据流等的时间和/或空间顺序。此外,在一些实施例中,多个操作、多个组件、多个连接、多个数据流等可组合成单个元件,和/或单个操作、单个组件、单个连接、单个数据流等可分布在多个元件之间。
56.工作项检测
57.根据本公开,可在包括api域、驱动器域、硬件域等、或它们的组合的不同域中检测工作项。在此描述的工作项检测技术可例如用图1至图3中所示的任何系统和/或方法来实现,但是这些技术不限于图1至图3中描述的任何具体细节。
58.在应用级,根据本公开的各种技术可用于使程序员或应用能够直接和/或间接地向流量控制逻辑通知新工作项。例如,在一些实施例中,api可包括和/或实现一个或多个扩展以提供以下功能:明确地向流量控制逻辑通知工作项,以及提供可使得流量控制逻辑能够选择和/或维护适合于工作项的高速缓存策略的信息。在一些实施方式中,可通过驱动器将该信息传递到流量控制逻辑。
59.作为另一示例,程序员或应用可通过提供提示来间接地向流量控制逻辑通知工作项。例如,一些api可提供开放式存储器系统,该开放式存储器系统可使硬件供应商能够实现可基于使用提供最佳存储器位置的不同存储器类型。因此,程序员可通过为每个工作项分配不同的存储器类型来区分工作项。在一些实施例中,这可使得能够基于工作项的类型和/或属性来调整存储器事务和/或相关联的高速缓存策略以用于改进的性能。
60.在一些实施例中,取决于实现细节,识别api域中的工作项可在改善工作项的性能方面为程序员或应用提供更多的透明度和/或灵活性。此外,在api级识别工作项可提高准确性,因为识别可由程序员而不是尝试推断工作项的行为的二阶影响的机器和/或算法来执行。
61.在驱动器级,根据本公开的各种技术(例如,试探法)可被用于例如通过监测一个或多个性能计数器(诸如,管道的状态、维度的数量和/或类型、正被处理的图的数量、图中的顶点和/或图元的数量、使用中的渲染目标的数量、使用中的资源的数量和/或类型(例如,存储器单元或“团块”(blob)的分配)、资源转变、使用中的数据格式、着色器元数据等)来检测新工作项。
62.例如,在一些实施例中,一旦潜在工作项和/或工作项内的存储器单元已被识别为工作项感知高速缓存策略的候选,gpu驱动器就可尝试针对流量控制逻辑设置适当的提示。在一些实施例中,gpu驱动器可能够确定存储器单元何时可用作可呈现的图像。此检测可在创建这样的图像时发生,因此gpu驱动器可有机会设置适当的存储器类型以指示新工作项。例如,当gpu驱动器导入外部分配的存储器(例如,取得外部分配的存储器的所有权)时,可
设置此存储器类型。存储器的分配区域可与存储器类型映射,存储器类型可向硬件通知驱动器期望特定存储器区域被处理的特定方式。
63.在硬件级,根据本公开的各种技术(例如,试探法)可用于检测新工作项,例如,通过监测一个或多个性能计数器(诸如,高速缓存冲刷和/或高速缓存同步、使用中的渲染目标的数量、顶点与图元的比率、色彩和/或深度数据存取与纹理存取的比率、被访问的数据区域、到在当前工作项中尚未利用的区域的流量等)。可在各种时间使用这些和/或其他参数来推断工作项和/或连续工作项之间的边界的存在和/或身份。
64.在一些实施例中,取决于实现细节,识别硬件域中的工作项可能涉及很少的软件支持或没有软件支持。
65.在一些实施例中,检测工作项的目的可以是允许流量控制逻辑找到一个或多个工作项的起点(以及随后的终点)。在一些实施例中,工作项的实际身份和/或类型(诸如,几何缓冲器子步骤、光照子步骤等)可能不是确定针对新工作项的高速缓存策略的主要因素。例如,在一些实现中,可基于学习用于工作项的存储器流量行为而不是知道工作项的标识来确定高速缓存策略。然而,在其他实施例中,用于新工作项的高速缓存策略可部分地或完全地基于身份或类型。
66.在工作项的特性可跨工作负荷保持相同的情况下,可对该工作项应用静态策略。例如,到显示帧缓冲器的传送可被更明确地优化。
67.在一些实施例中,在识别出一个或多个工作项之后,可通知一个或多个用户(诸如,gpu子块和/或高速缓存层级元件)何时存在由gpu执行的工作项的改变。该通知可利用可基于工作项识别机制而变化的机制来实现。此外,在一个或多个用户和/或高速缓存层级元素被通知gpu正在执行的新工作项之后,它们可重新评估它们各自的高速缓存策略,以评估它们是否可针对新工作项使用更优的策略。例如,如果l2高速缓存被通知工作项的改变,则l2高速缓存中的工作项感知策略逻辑可评估用于先前工作项的高速缓存替换策略对于新工作项是否是可接受的或最佳的。如果发现用于先前工作项的策略对于新工作项也是可接受的或最佳的,则l2高速缓存可不采取任何动作。然而,如果l2高速缓存中的工作项感知策略逻辑识别出用于新工作项的更优的替换策略,则l2高速缓存可应用新的替换策略以更好地适合新工作项。
68.在一些实施例中,根据本公开(包括下面描述的任何示例),工作项感知策略逻辑可使用不同的评估机制来识别对于工作项是可接受的或最佳的策略。
69.学习流量行为
70.在根据本公开的一些实施例中,可在包括驱动器级、硬件级和/或它们的任何组合的任何域中实现针对工作项的高速缓存存储器流量行为的学习。在此描述的流量行为学习技术可例如用图1至图3中所示的任何系统和/或方法来实现,但是这些技术不限于图1至图3中描述的任何具体细节。
71.在一些实施例中,可使用离线分析来学习流量行为,离线分析可使得流量控制逻辑能够应用对于特定工作项可能有益或最佳的策略。例如,在显示帧缓冲器优化的情况下,可离线分析以下特性和/或性能计数器中的一个或多个:跨用户(在用户之间)和/或在用户内重复使用生产者(producer)(数据写入器)和/或消费者(consumer)(数据读取器)关系、无分配行(no-allocate line)、每个用户的读取流量和/或写入流量、部分写入、存储器类
型等。
72.在一些实施例中,这些特性中的一个或多个可通过性能计数器来监测,性能计数器可例如在硬件、一个或多个软件驱动器等中实现。此外,性能计数器的监测可用于工作项检测。
73.在一些情况下,工作项的总数(诸如,帧内的子步骤)可保持不变。因为此情形可用于检测最终子帧写入,所以一些实施例可针对此情形实施一个或多个检查。在检测到子通道的数量改变时,根据本公开的学习算法可潜在地重新开始和/或擦除所有先前学习,或者保存先前学习以供稍后(例如,在检测到返回到先前行为时)使用。
74.在一些实施例中,针对工作项的流量行为的学习可在帧的一部分、整个帧和/或多个帧上发生。可跟踪帧内的每个工作项的特性,并且一旦学习了工作项的一个或多个特性,就可使用所学习的特性来确定改进的或最佳的高速缓存策略(诸如,分配策略、替换策略等),并将确定的高速缓存策略应用于未来帧的相同工作项。
75.工作项感知流量控制器
76.图4示出了根据本公开的工作项感知流量控制器的示例实施例。图4中所示的控制器可用于例如实现在此公开的任何流量控制逻辑,包括图1和图2中所示的流量控制逻辑。工作项感知流量控制器(或者流量控制器)402可包括分配级逻辑404、替换策略逻辑406和策略选择逻辑408。策略选择逻辑408可响应于来自多种源中的任何一个的输入410,使用在此公开的任何策略选择技术来选择一个或多个高速缓存策略。例如,输入410可包括如图4中所示的用户信息和/或工作项信息,并且用户信息和/或工作项信息可例如从存储器、驱动器、api等接收。附加地或可选地,输入410可包括任何其他信息,包括性能计数器(诸如,命中率、每秒帧数等)。
77.由策略选择逻辑408选择的一个或多个高速缓存策略412可被传送到分配级逻辑404和/或替换策略逻辑406以用于实现。分配级逻辑404可响应于一个或多个输入410和由策略选择逻辑408选择的一个或多个高速缓存策略412来提供分配策略414。图4中所示的实施例可包括替换策略逻辑406的三个实例,以在高速缓存层级中的每个高速缓存级提供单独的替换策略,但是其他实施例可仅包括替换策略逻辑406的一个实例或任何其他数量的实例。同样地,其他实施例可包括分配级逻辑404的任何数量的实例。
78.替换策略逻辑406可响应于由策略选择逻辑408选择的一个或多个高速缓存策略412和来自分配级逻辑404的输出416(可包括例如分配策略414和/或输入410中的一个或多个)来提供替换策略418。
79.在一些实施例中,流量控制器402可拦截例如来自存储器接口的一些或所有存储器请求,并且使用来自每个请求的一个或多个属性(诸如,用户标识符(用户id)、工作项id、读取和/或写入指示符等)来例如基于每个请求分配一个或多个高速缓存策略,分配一个或多个高速缓存策略也可基于高速缓存层级中的每级来实现。可基于每个级来分配的高速缓存策略的元素的示例包括请求是可高速缓存的还是不可高速缓存的、保留时间、替换策略等。在一些实施例中,流量控制器402可将工作项id令牌(token)和/或其他请求属性映射到所选择的高速缓存策略,并将该策略分配给该请求。
80.策略选择逻辑
81.根据本公开,可使用各种方法来选择和/或应用用于工作项的一个或多个高速缓
存策略。方法的示例包括基于离线学习的每个工作项的静态策略选择、基于运行时条件和离线学习的动态策略选择、和/或基于运行时条件和运行时学习的动态策略选择。在一些实施例中,可针对不同的输出特性优化一个或多个高速缓存策略。例如,可优化一个或多个策略以最大化fps、减少存储器流量等。在一些实施例中,如果策略可为可能与该策略可应用于的特定工作项相关的一个或多个参数提供最佳或几乎最佳的结果,则该策略可被认为是最佳的。在一些实施例中,如果高速缓存策略在该高速缓存策略可被应用于的工作项的持续时间或持续时间的一部分内不改变,则高速缓存策略可被认为是静态的,而如果高速缓存策略在该高速缓存策略可被应用于的工作项的持续时间或持续时间的一部分内改变或能够改变,则该高速缓存策略可被认为是动态的。这些仅为示例技术,并且可根据本公开的原理实施其他技术和/或它们的组合。在此描述的策略选择技术可例如用图1至图3中所示的任何系统和/或方法来实现,但是这些技术不限于那些附图中描述的任何具体细节。如上所述,为了方便起见,贯穿本公开,工作项可表示整个工作项和/或工作项的一部分,工作项可表示工作项和/或工作项之间的边界,并且层级可表示整个层级和/或层级的一部分。类似地,最佳可表示可能不是最佳但仍然有效、有益、改进等的事物。
82.图5示出了根据本公开的可基于离线学习来实现静态策略选择的工作项感知流量控制器502的示例实施例。工作项感知流量控制器502可包括可与图4中所示的实施例中的那些类似的分配级逻辑504和替换策略逻辑506。同样的,图5中的输入510、一个或多个高速缓存策略512、分配策略514、输出516和替换策略518也可与图4中所示的实施例中的那些类似。策略选择逻辑可被实现为可执行对应用和/或工作项行为的剖析(profile)和/或分析的离线学习静态策略逻辑508。每个工作项的一个或多个最佳策略可被离线识别,并被硬编码在硬件中,和/或在驱动器或可将一个或多个策略应用于高速缓存层级的任何其他布置中实现。例如,可在运行时检测工作项,并且可将它们的身份传送给在执行该工作项时可能涉及的一个或多个用户(例如,硬件子块)。在一些实施例中,用户、流量控制逻辑、高速缓存层级等中的一个或多个可将工作项身份映射到一个或多个相应的最佳策略。
83.在一些实施例中,取决于实现细节,该机制可涉及对硬件进行很少的改变,因此可相对容易地实现。
84.图6示出了根据本公开的可基于性能计数器和离线学习来实现动态策略选择的工作项感知流量控制器602的示例实施例。工作项感知流量控制器602可包括可与图4中所示的实施例中的那些类似的分配级逻辑604和替换策略逻辑606。同样的,图6中的输入610、一个或多个高速缓存策略612、分配策略614、输出616和替换策略618也可与图4中所示的实施例中的那些类似。与图5的实施例一样,策略选择逻辑可被实现为可实现对应用和/或工作项行为的离线剖析和/或分析的离线学习静态策略逻辑608。然而,离线学习静态策略逻辑608可基于性能计数器620(诸如,fps、命中率等)来识别每个工作项的多个最佳策略,fps、命中率等可由离线学习静态策略逻辑608监测和/或通过选择器622输入到离线学习静态策略逻辑608。最佳策略可被离线识别,并被硬编码在硬件中、和/或在驱动器或可将一个或多个策略应用于高速缓存层级的任何其他布置中实现。
85.在一些实施例中,离线学习静态策略逻辑608可在工作项的开始处识别并应用最佳高速缓存策略,并且在工作项的持续时间内应用该策略。在一些其他实施例中,离线学习静态策略逻辑608可继续监测性能计数器,并且响应于一个或多个变化的性能计数器而在
工作项的执行期间改变高速缓存策略。
86.在一些实施例中,因为一个或多个学习算法可离线执行从而可不涉及许多资源约束,因此一个或多个学习算法可以是相对复杂的。基于该离线学习,逻辑可被硬编码到工作项感知策略硬件中,该工作项感知策略硬件可接收输入610(诸如,用户id、工作项id等)以及各种性能计数器(诸如,fp、各种高速缓存的命中率等)。基于这些输入,离线学习静态策略逻辑608可选择一个或多个高速缓存策略612,一个或多个高速缓存策略612可被传送到分配级逻辑604和替换策略逻辑606以用于实现。在一些实施例中,在运行时检测到的工作项及其身份可由一个或多个用户(例如,子块)连同一个或多个存储器请求一起传输给流量控制器。
87.在一些实施例中,取决于实现细节,该机制可基于特定工作项的运行时行为来提供更细粒度和/或微调的策略选择。
88.图7示出了根据本公开的可基于性能计数器和在线学习来实现动态策略选择的工作项感知流量控制器702的示例实施例。工作项感知流量控制器702可包括可与图4中所示的实施例中的那些类似的分配级逻辑704和替换策略逻辑706。同样的,图7中的输入710、一个或多个高速缓存策略712、分配策略714、输出716和替换策略718也可与图4中所示的实施例中的那些类似。然而,策略选择逻辑可用一个或多个运行时学习模型708和运行时逻辑724来实现。因此,策略选择逻辑可执行很少或不执行对应用和/或工作项行为的离线剖析和分析。相反,一个或多个运行时学习模型708和运行时逻辑724可通过顺序地应用多个可用的高速缓存策略并使用反馈机制来评估每个策略的有效性,来在运行时识别每个工作项的最佳策略,从而学习每个工作项的一个或多个最佳策略。在一些实施例中,一旦学习了工作项的最佳策略,就可在工作项的持续时间内使用该最佳策略。可选地,一个或多个运行时学习模型708和运行时逻辑724可继续监测所应用的策略的有效性,并且响应于一个或多个变化的性能计数器而改变策略。在一些实施例中,一个或多个运行时学习模型708可用回归分析、模糊逻辑、机器学习等来实现。
89.在一些实施例中,可将一个或多个学习的策略保存在例如硬件中的一个或多个表、驱动器级等中,因此在任何未来出现具有类似行为的对应工作项时可利用在过去学习期间识别的一个或多个最佳策略。
90.在一些实施例中,取决于实现细节,该方法可在运行时学习特定策略的有效性。
91.尽管工作项感知流量控制器402、502、602和702可被示出为单个单元,但是如上面关于图1和图2中所示的实施例所描述的,它们的功能可分布在不同的组件之间。此外,如上面关于图1和图2中所示的实施例所描述的,流量控制器的任何功能可用硬件、软件和/或它们的组合来实现。
92.关于图4至图7中所示的实施例以及在此描述的任何其他实施例描述的操作、组件、连接、数据流等是示例操作、示例组件、示例连接、示例数据流等。在一些实施例中,可省略这些元件中的一些和/或可包括其他元件。在一些实施例中,可改变操作、组件、连接、数据流等的时间和/或空间顺序。此外,在一些实施例中,多个操作、多个组件、多个连接、多个数据流等可组合成单个元件,和/或单个操作、单个组件、单个连接、单个数据流等可分布在多个元件之间。
93.显示写入期间的缓存分配
94.在一些实施例中,对显示帧缓冲器的写入可分配llc中的高速缓存行,这可导致可由后续读取使用的行的淘汰(eviction)。因此,llc中的读取未命中可能导致更高的延迟和/或增加的dram流量。作为在此公开的技术的示例实施方式,驱动器可识别这些工作负荷的最终工作项,并且在最终工作项正被执行时通知gpu硬件。作为特定优化,gpu硬件又可选择不在llc中分配显示帧缓冲器写入,这可由此减少dram流量、读取的访问延迟以及渲染最终子帧所需的周期。这种选择性非分配技术可例如在基于图块的架构以及即时模式渲染器中实现,在即时模式渲染器中,来自本地(gpu上)渲染目标的i/o可能更难以分类。
95.工作项感知高速缓存策略方法
96.图8示出了根据本公开的处理gpu中的工作负荷的方法的实施例。该方法可开始于操作802。在操作804,该方法可检测gpu中的工作负荷的工作项。在操作806,该方法可确定用于工作项的高速缓存策略。在操作808,该方法可基于高速缓存策略针对工作项的至少一部分来操作gpu中的高速缓存存储器层级的至少一部分。该方法可终止于操作810。
97.关于图8中所示的实施例以及在此所述的任何其他实施例描述的操作和/或组件是示例操作和/或组件。在一些实施例中,可省略一些操作和/或组件和/或可包括其他操作和/或组件。此外,在一些实施例中,可改变操作和/或组件的时间和/或空间顺序。
98.尽管在gpu的情况下描述了一些实施例,但是发明原理也可应用于其他类型的处理系统。
99.图9示出了本公开中所描述的方法或设备中的任一个可被集成到其中的显示装置(例如,图像显示装置)904的实施例。显示装置904可具有任何形状因子(诸如,用于pc、膝上型计算机、移动装置等的平板显示器、投影仪、vr眼罩等),并且可基于任何成像技术(诸如,阴极射线管(crt)、数字光投影仪(dlp)、发光二极管(led)、液晶显示器(lcd)、有机led(oled)、量子点等)来显示具有像素的图像(例如,光栅化图像)906。图像处理器910(诸如,图形处理器(gpu)和/或显示驱动器912)可将图像处理和/或转换为可在成像装置904上显示或通过成像装置904显示的形式。图像906的一部分被放大示出,因此像素908是可见的。本公开中描述的任何方法或设备可集成到成像装置904、处理器910和/或显示驱动器912中,以生成图9中所示的像素908和/或像素组。在一些实施例中,图像处理器910可包括例如在集成电路911上实现的管道、高速缓存层级和/或流量控制逻辑,流量控制逻辑可实现一个或多个工作项感知高速缓存策略和在此描述的任何其他发明原理。在一些实施例中,集成电路911还可包括显示驱动器912和/或可实现显示装置904的任何其他功能的任何其他组件。
100.图10示出了根据本公开的包括可实现工作项感知高速缓存策略的gpu的片上系统(soc)装置的实施例。soc 1002可包括中央处理器1004、主存储器1006、gpu 1008和显示驱动器1010。gpu 1008可包括流量控制逻辑1012、管道1014和存储器子系统1016,流量控制逻辑1012、管道1014和存储器子系统1016可例如以与上面关于图1至图2和图4至图7描述的方式类似的方式来实现,并且可实现在此公开的任何工作项感知高速缓存策略,包括例如上面关于图3和图8描述的那些策略。图10中所示的soc 1002可被集成到例如图像显示装置(诸如,图9中所示的实施例)中。
101.在各种实现细节的情况下描述了上面公开的实施例,但是本公开的原理不限于这些或任何其他具体细节。例如,一些功能被描述为由特定组件实现,但是在其他实施例中,
功能可分布在不同位置中的不同系统和组件之间并且具有各种用户界面。特定实施例被描述为具有特定的过程、步骤等,但是这些术语也包括可用多个过程、步骤等实现特定的过程、步骤等的实施例,或者多个过程、步骤等可被集成到单个过程、步骤等中的实施例。对组件或元件的引用可仅表示组件或元件的一部分。在一些实施例中,确定也可表示至少部分地确定,检测可表示至少部分地检测,并且基于可表示至少部分地基于。
102.除非从上下文中另有明确说明,否则在本公开和权利要求书中使用诸如“第一”和“第二”的术语可仅用于区分它们所修饰的事物的目的,并且可不指示任何空间或时间顺序。对第一事物的引用可能不暗示第二事物的存在。为了方便起见,可提供诸如章节标题等的各种组织辅助,但是根据这些辅助布置的主题和本公开的原理不受这些组织辅助的限制。
103.可组合上述各种细节和实施例以产生根据本专利公开的发明原理的附加实施例。由于在不脱离发明构思的情况下,可在布置和细节上修改本专利公开的发明原理,因此这些改变和修改被认为落入所附权利要求的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。