一种基于深度特征和tradaboost的龙井茶品质鉴别方法
技术领域
1.本发明属于计算机视觉、迁移学习和龙井茶品质检测技术领域,尤其涉及一种基于深度特征和tradaboost的龙井茶品质鉴别方法。
背景技术:
2.龙井茶主要有西湖、钱塘和越州三大产区,同一产区生产的龙井茶也因采摘时间、工艺等的不同,存在品质差异。传统基于图像的龙井茶品质鉴别主要依赖于数字图像处理技术手动提取图像特征,构建分类模型。但是,由于不同产地和品质的龙井外观上相似度极高,这给传统图像处理带来很大困难,制约了鉴别准确率。
3.基于卷积神经网络的深度学习模型可以自动提取高阶特征,实现对高相似度图像的分类,然而,卷积神经网络参数极多,需要大量标注数据,标注数据主要依赖人工完成,会耗费大量的人力物力,这为深度学习模型的实施带来了限制。因此,如何在目标任务标注样本量很少的情况下构建深度学习模型,实现准确鉴别的同时节约时间和人力成本,是非常有学术和工程价值的问题。
技术实现要素:
4.为解决背景技术中提到的问题,本发明提出了一种基于深度特征和tradaboost的龙井茶品质鉴别方法,采取了如下的技术方案:
5.一种基于深度特征和tradaboost的龙井茶品质鉴别方法,包含如下步骤:
6.步骤1:领域划分与数据集标注;
7.步骤2:图像感兴趣区域提取、标准化与增强化;
8.步骤3:训练深度学习模型,构建特征提取器;
9.步骤4:构建实例迁移tradaboost模型;
10.步骤5:使用测试集评估模型分类效果。
11.进一步地,所述步骤1包括如下具体步骤:
12.收集用于鉴别品质的龙井茶图像,将其作为目标数据集,选取其中的少部分进行标注,建立与目标数据集类别空间相同的辅助数据集,作为源域,得到源域和目标域两个相关联的龙井茶品质数据集。
13.进一步地,所述源域和目标域的数据集具有相同的品质鉴别任务,源域和目标域的区别在于,源域是所有样本都是带标签的,即完全标注,目标域只有少量样本带标签,即仅有少量标注,少量指的是每个类别只有10个样本有标签。
14.进一步地,所述步骤2包括如下具体步骤:
15.将源域和目标域中所有带标签的样本合并,作为训练集,然后对训练集图像进行感兴趣区域提取、标准化、增强化等操作,得到预处理后的训练集;带标签的样本合并成训练集指的是,将类别空间相同的源域和目标域样本合并在同一类别空间下;感兴趣区域提取指的是,以图像几何中心为中心提取感兴趣区域,范围大小为600
×
540像素,提取得到的
感兴趣区域作为数据集图像;增强化指的是,对训练集中每张图像进行旋转、翻转、添加噪声、缩放操作并保存副本,从而使数据规模扩大到原来的5倍,避免因深度学习模型参数量过大出现过拟合;标准化指的是,进行基于图像各通道均值和方差的标准化。
16.进一步地,所述标准化操作所采用的公式为:
17.output=(input-mean)/std
18.其中,mean和std对应图像各通道的均值和方差,input和output对应图像每个通道像素的输入和输出值;通过标准化操作后,图像各个通道服从均值为0,方差为1的标准正态分布。
19.进一步地,所述步骤3包括如下具体步骤:
20.利用预处理后的训练集训练深度学习模型,将训练后的模型参数固定,对所有样本进行深度特征提取,使用在imagenet数据集上训练好的模型参数作为深度神经网络模型的初始化参数;然后,将最后一层全连接层的输出数调整为训练集的类别数,也即龙井茶品质鉴别的等级数;最后,将处理好的训练集数据在模型中进行若干轮次训练,直至模型损失基本不再下降。
21.进一步地,所述深度特征提取指的是将训练好的深度神经网络模型参数固定,去掉分类器和最后一个全连接层,将样本输入网络后的输出作为样本的深度特征表示;所选择的深度神经网络模型为轻量化卷积神经网络架构mobilenet v2。
22.进一步地,所述步骤4包括如下具体步骤:
23.利用训练集的深度特征训练改进的多分类tradaboost模型,保存训练好的模型;利用训练集图像样本提取的深度特征训练改进的多分类tradaboost模型,在迭代过程中,提高源域中与目标域相似样本的权重,降低与目标域不相似样本的权重,从而构建基于实例的迁移学习模型。
24.进一步地,所述源域样本的权重迭代方式与原始tradaboost算法相同,目标域样本的迭代方式,采取与前向分步算法相同的迭代方式,从而实现多分类。
25.进一步地,所述步骤5包括如下具体步骤:
26.使用不带标签的待测龙井茶图像在深度学习模型上提取深度特征,然后导入多分类tradaboost模型进行品质鉴别;首先,将不带标签的目标域样本,即测试集样本,导入到训练好的深度学习模型中,得到深度特征,再将深度特征导入到训练好的tradaboost分类器中,评估龙井茶品质鉴别准确率;测试集图像需进行标准化,但是不需要进行增强,首先测试集样本被导入深度特征提取器得到1280维特征向量,再导入训练好的tradaboost模型得到预测结果,通过绘制混淆矩阵和计算测试集准确率衡量模型准确率。
27.本发明的有益效果是:充分利用相关联的源域数据集提供的信息,利用深度神经网络和强泛化性和实力样本间的相似性,构建迁移学习模型。模型能够实现目标任务小样本情况下的龙井茶品质鉴别。该方法消耗时间和算力少,效率高,节约大量标注成本和人力物力,为龙井茶品质自动化识别增加了应用场景。
附图说明
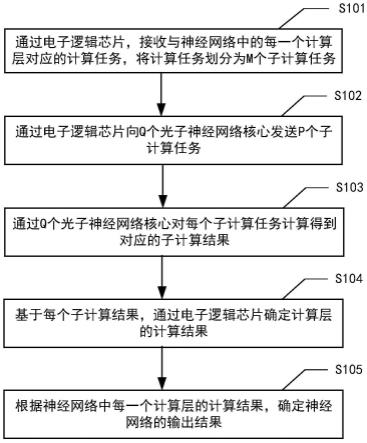
28.图1为本发明龙井茶品质鉴别方法的流程图;
29.图2为roi提取示意图;
30.图3为源域和目标域数据集示意图;
31.图4为mobilenet v2网络结构示意图;其中conv表示卷积(convolution),s表示步长(stride),p表示填充(padding);
32.图5(a)为钱塘龙井目标域混淆矩阵示意图;
33.图5(b)为越州龙井目标域混淆矩阵示意图。
具体实施方式
34.下面结合附图和实例对本发明作进一步详细说明。
35.如图1所示,本发明的一种基于深度特征和tradaboost的龙井茶品质鉴别方法,包括如下步骤:
36.步骤1:领域划分与数据集标注。收集用于鉴别品质的龙井茶图像,将其作为目标数据集,选取其中的少部分进行标注。建立与目标数据集类别空间相同的辅助数据集,作为源域,例如,目标数据集为四个等级的龙井茶品质区分,源域数据集也应为四个等级的龙井茶品质区分,对该数据集进行充分标注。得到源域和目标域两个相关联的龙井茶品质数据集。源域和目标域数据集应具有相同的品质鉴别任务,例如,源域和目标域均为若干个等级的龙井茶,但是来自不同的产地。源域和目标域的区别在于,源域是所有样本都是带标签的,即完全标注,目标域只有少量样本带标签,即仅有少量标注,少量指的是,每个类别只有10个左右样本有标签。
37.步骤2:图像感兴趣区域提取、标准化与增强化:将源域和目标域中所有带标签的样本合并,作为训练集,然后对训练集图像进行感兴趣区域提取、标准化、增强化等操作,得到预处理后的训练集。带标签的样本合并成训练集指的是,将类别空间相同的源域和目标域样本合并在同一类别空间下。感兴趣区域提取指的是,为了更突出龙井茶本身的特征,去除背景可能带来的影响,以图像几何中心为中心提取感兴趣区域,范围大小为600
×
540像素,其中基本不包含背景信息,提取得到的感兴趣区域作为数据集图像。增强化指的是,对训练集中图像进行45
°
旋转、90
°
旋转、水平翻转、竖直翻转、添加椒盐噪声、添加高斯噪声、1:2缩放中随机选取4种方式进行处理并保存副本,从而使数据规模扩大到原来的5倍,避免因深度学习模型参数量过大出现过拟合。标准化指的是,进行基于图像各通道均值和方差的标准化。标准化操作所采用的公式为:
38.output=(input-mean)/std
39.其中,mean和std对应图像各通道的均值和方差,input和output对应图像每个通道像素的输入和输出值。通过标准化操作后,图像各个通道服从均值为0,方差为1的标准正态分布,有利于神经网络卷积层的特征提取。
40.步骤3:训练深度学习模型,构建特征提取器:利用预处理后的训练集训练深度学习模型,将训练后的模型参数固定,对所有样本进行深度特征提取。使用在imagenet数据集上训练好的模型参数作为深度神经网络模型的初始化参数,然后,将最后一层全连接层的输出数调整为训练集的类别数,也即龙井茶品质鉴别的等级数。最后,将处理好的训练集数据在模型中进行若干轮次训练,直至模型损失基本不再下降。深度特征提取指的是,将训练好的深度神经网络模型参数固定,去掉分类器和最后一个全连接层,将样本输入网络后的输出作为样本的深度特征表示。考虑到应用阶段,对特征提取网络的时空复杂度有很高的
要求,因此所选择的深度神经网络模型为性能出色的轻量化卷积神经网络架构mobilenet v2,该网络架构在imagenet数据集上的预训练模型属于互联网公开资源。首先,使用预训练模型参数初始化mobilenet v2模型,将全连接层的输出改为训练集的类别数。训练过程中观察训练集损失与准确率,待平稳后停止训练,保存模型参数。去除训练好的mobilenet v2模型的softmax层和全连接层,其余层参数保存,从而构建得到深度特征提取器。特征提取器的输入图像尺寸为224
×
224
×
3,输出为1280维特征向量。
41.步骤4:构建实例迁移tradaboost模型:利用训练集的深度特征训练改进的多分类tradaboost模型,保存训练好的模型。利用训练集图像样本提取的深度特征训练改进的多分类tradaboost模型,在迭代过程中,提高源域中与目标域相似样本的权重,降低与目标域不相似样本的权重,从而构建基于实例的迁移学习模型。源域样本的权重迭代方式与原始tradaboost算法相同,目标域样本的迭代方式,采取与前向分步算法(stagewise additive modeling,samme)相同的迭代方式,从而实现多分类。
42.步骤5:使用测试集评估模型分类效果。使用不带标签的待测龙井茶图像在深度学习模型上提取深度特征,然后导入多分类tradaboost模型进行品质鉴别;首先,将不带标签的目标域样本(也即测试集样本)导入到训练好的深度学习模型中,得到深度特征,再将深度特征导入到训练好的tradaboost分类器中,评估龙井茶品质鉴别准确率。测试集图像也需进行标准化,但是不需要进行增强。首先测试集样本被导入深度特征提取器得到1280维特征向量,再导入训练好的tradaboost模型得到预测结果。通过绘制混淆矩阵和计算测试集准确率衡量模型准确率。
43.实施例:
44.为了验证本方法的有效性,我们采集了来自西湖、钱塘和越州三个产区的不同品质龙井茶,构建了三个数据集,对应不同的源域和目标域。步骤1:领域划分与数据集标注。
45.我们在同样的图像采集装置中采集了来自三个产地的不同品质龙井茶,构建了三个数据集:西湖龙井、钱塘龙井和越州龙井,每个数据集都包含4种不同品质的龙井,其中每个类别都有100张图像。我们将西湖龙井设置为源域,全部人工标注,钱塘龙井和越州龙井设置为目标域,每个类别仅有10张图像人工标注,从而构建了小样本情况下的龙井茶品质鉴别任务。
46.步骤2:图像感兴趣区域提取、标准化与增强化
47.原始图像的尺寸为1920
×
1080,为了去除背景影响,我们提取中间600
×
540区域为感兴趣区域(region of interest,roi),如图2所示。使用python语言,在pytorch框架下搭建图像处理模块,进行数据增强与标准化。最终训练集包含图像2200张。源域和目标域数据集样本如图3所示。
48.步骤3:训练mobilenet v2模型,构建特征提取器
49.使用pytorch模块构建预训练参数初始化的mobilenet v2模型,网络结构如图4所示。导入训练集进行训练,图像输入前统一缩放为224
×
224分辨率,batch-size设置为32,采用的优化方法为随机梯度下降法,学习率设置为0.0001。损失函数使用交叉熵损失评估分类精度。结果表明,模型在几轮迭代后已经基本稳定,测试集和验证集的损失和准确率都稳定在一定的水平,达到了较好的训练效果。
50.步骤4:构建多分类tradaboost模型。
51.改进的tradaboost算法伪代码如下表所示。
[0052][0053]
步骤5:使用测试集评估模型分类效果。
[0054]
将处理好的测试集数据导入训练好的模型,评估模型泛化能力,此处采用混淆矩阵来表明两个目标域的品质鉴别情况,如图5(a)-5(b)所示。下表列出了普通图像处理、深度学习和迁移学习三种方法在两个目标域的准确率。
[0055][0056]
结果表明,使用手动提取的颜色和纹理特征,导入到支持向量机(support vector machine,svm)分类器中,对图像所反映的信息提取不够,导致准确率低。当直接使用mobilenet v2模型进行从源域到目标域的迁移时,由于所有样本都参与了训练,领域之间的偏差并没有得到很好的消除,虽然深度学习能够提取高阶语义特征使准确率得到了一定改善,但是性能仍然有限。当使用mobilenet v2提取的深度特征结合tradaboost分类器时,相似样本的权重被提高,不相似样本的权重被降低,从而筛选出领域差异小的样本,实现有效迁移,最终在两个目标域的准确率分别达到了94.5%和93.3%。
[0057]
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。