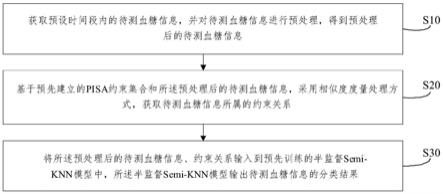
knn模型中,所述半监督semi-knn模型输出待测血糖信息的分类结果;
14.所述半监督semi-knn模型为采用训练数据集和所述pisa约束集合对knn模型进行训练,得到的用于识别血糖信息异常的半监督方式的模型,且所述训练数据集包括经由一阶差分处理的血糖数据。
15.可选地,所述s10之前,所述方法还包括:
16.s01、借助于cgm设备获取多个历史血糖数据,并对每一历史血糖数据进行预处理,并得到血糖序列;每一血糖序列中包括具有pisa时间戳标签的血糖数据和非pisa时间戳标签的血糖数据;
17.s02、将每一血糖序列划分为多个子序列,并对每一个子序列进行一阶差分计算,得到训练数据集;
18.s03、基于先验知识和训练数据集中的具有pisa时间戳标签的训练数据,按照半监督约束条件形成规则,生成pisa约束集合;
19.s04、将所述训练数据集和pisa约束集合对半监督semi-knn模型进行训练获取训练后的半监督semi-knn模型;
20.所述半监督semi-knn模型为改进knn模型并采用半监督方式构建的。
21.可选地,所述s04包括:
22.s04-1、遍历训练数据集的所有子序列,构建离线k维搜索二叉树,得到k-d树;
23.s04-2、基于所述k-d树,遍历pisa约束集合,获取半监督semi-knn模型的异常阈值σ,所述异常阈值的边界阈值为σ1和σ2,表示为σ=[σ1,σ2];
[0024]
其中,采用dtw相似性度量函数计算pisa约束集合中每一个pisa事件与其他事件的平均距离,得到距离集合;
[0025]
则根据下述公式(1)获得异常阈值σ=[σ1,σ2];
[0026]
σ1=q3 1.5(q3-q1),公式(1)
[0027]
σ2=q1-1.5(q3-q1),
[0028]
待测血糖数据距离pisa约束中ml关系的样本距离dist《σ2,则确定为异常样本;待测血糖数据距离pisa约束中cl关系的样本距离dist》σ1,则确定为异常样本;
[0029]
q3为距离集合中的上四分位数,q1为距离集合中的下四分位数。
[0030]
可选地,所述s02包括:
[0031]
对每一个血糖序列做滑动窗口处理,在血糖序列x={x1,x2,
…
,xn}中,经大小为w滑动窗口后形成若干子序列qi={xi,x
i 1
,
…
,x
i k
},
[0032]
一个序列子集为d={q1,q2,
…
,qm},对每一个子序列qi按照公式(2)进行一阶差分计算,
[0033]
h为一阶差分公式的改变量,h取值为0.8-1.2;
[0034][0035]
对所有的子序列计算一阶差分后,每一子序列的一阶差分值作为训练数据集。
[0036]
可选地,所述s10包括:
[0037]
借助于cgm设备获取大于等于30-45分钟的待测血糖信息;
[0038]
进行滤波处理,并通过滑动窗口方式对待测血糖信息进行预处理,以去除待测血
糖信息中的孤立噪声点并实现缺失值填补,得到待测血糖信息的待测血糖序列。也就是说,可对待测血糖信息进行滤波处理,并通过适当大小的滑动窗口方式遍历待测血糖信息,当滑窗范围内存在此类微小区域时将其平均处理,从而去除待测血糖信息准孤立噪声点。当由于传感器问题造成待测血糖信息存在缺失值时,首先可以判断缺失值连续存在的个数,然后通过一般的线性插值方法对待测血糖信息进行缺失值填补,得到待测血糖信息的预处理后的待测血糖序列。
[0039]
可选地,所述s20包括:
[0040]
当待测血糖序列中每一序列的血糖数据a与pisa约束集合中一个pisa事件b的sbd距离小于阈值λ时,即f
sbd
(a,b)《λ,则确定一个约束关系ml(a,b),并对pisa约束集合进行更新;λ为预设的大于0的数值;f表示两个序列计算sbd距离的函数;
[0041]
当待测血糖序列中每一序列的血糖数据a与pisa约束集合中一个pisa事件b的cl约束关系的sbd距离小于阈值λ时,即f
sbd
(a,b)《λ,则确定一个约束关系cl(a,b),并对pisa约束集合进行更新;
[0042]
遍历待测血糖序列中每一序列,并将更新后的pisa约束集合作为待测血糖信息所属的约束关系。
[0043]
可选地,所述s30包括:
[0044]
基于所述k-d树和待测血糖序列,循环迭代方式获取距离到待测血糖序列中每一数据的最近的k个数据点,并得到使用阶段的k-d树,
[0045]
基于使用阶段的k-d树,遍历约束关系,获取待测血糖序列的pisa异常信息的分类结果;
[0046]
采用dtw相似性度量函数计算约束关系中每一个pisa事件与其他事件的实际距离,将该实际距离和异常阈值σ=[σ1,σ2]进行比较,获得属于pisa事件和非pisa事件的分类结果。
[0047]
可选地,将实际距离与异常阈值进行比较后,确定属于约束关系中ml约束的数据量,根据该数据量确定属于pisa事件中异常等级值。
[0048]
第二方面,本发明实施例还提供一种电子设备,其包括:存储器和处理器,所述存储器用于存储计算机程序,所述处理器用于执行所述存储器中存储的计算机程序并执行上述第一方面任一所述的基于半监督semi-knn模型的pisa故障识别方法的步骤。
[0049]
第三方面,本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上第一方面任一所述的基于半监督semi-knn模型的pisa故障识别方法的步骤。
[0050]
(三)有益效果
[0051]
本发明实施例的方法基于semi-knn模型进行异常分类,其解决了knn模型在执行异常检测时的不确定性问题;首次以约束形式引入先验知识形成半监督的异常检测方法,最大限度的利用有效先验知识,提高了检测结果的可靠性;通过对结果划分等级,提高结果的可信度,达到帮助医生实现临床判断的效果。
[0052]
本发明实施例中首次提出通过半监督方法进行cgm传感器故障诊断,通过引入先验知识(比如专家经验),提高了故障诊断结果的准确性;相比于传统无监督故障识别方法应用在cgm传感器故障诊断领域的效果,本发明的检测结果准确率更高,由引入半监督模型
的pisa约束集合可以保证针对pisa故障的较高的识别率和对未标定异常(如夜间发生的pisa异常事件)检测的置信度。
[0053]
另外,本发明提出的半监督模型针对时间序列数据类型,可将距离度量方式由原先的欧氏距离更新为dtw和sbd相似性度量方法,由此,提高了时间序列数据类型的度量准确性,也加快了整个计算程序的运行速度。
[0054]
本实施的方法可应用在连续血糖监测系统cgm中以增强cgm数据。故障检测不仅增强了cgm的安全性,还可以避免由于故障造成的治疗方案改变或预报预警等任务的可信度降低。应用本发明方法的cgm是检测压力感应传感器衰减(pisa)伪信号,提高检测的置信度。
附图说明
[0055]
图1为本发明一实施例提供的基于半监督semi-knn模型的pisa故障识别方法的流程图;
[0056]
图2(a)为构造k维搜索二叉树k-d tree的样例的过程示意图;
[0057]
图2(b)k-d tree的示意图;
[0058]
图3为新的样本的表示图;
[0059]
图4为约束关系对knn的异常检测迭代过程指引作用的示意图;
[0060]
图5为本发明另一实施例提供的基于半监督semi-knn模型的pisa故障识别方法的流程图。
具体实施方式
[0061]
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
[0062]
实施例一
[0063]
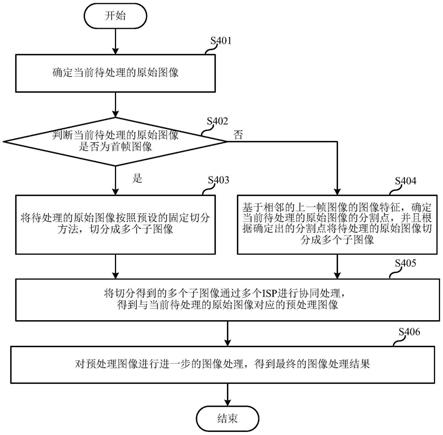
如图1所示,图1示出了一种基于半监督semi-knn模型的pisa故障识别方法的流程图,该方法的执行主体可为任一计算机/电子设备/cgm,该方法可包括下述的步骤:
[0064]
s10、获取预设时间段内的待测血糖信息,并对待测血糖信息进行预处理,得到预处理后的待测血糖信息。
[0065]
本实施例中,可借助于cgm获取大于等于30-45分钟的待测血糖信息;并对待测血糖信息进行滤波处理,并通过滑动窗口方式对待测血糖信息进行预处理,以去除待测血糖信息中的孤立噪声点并实现缺失值填补,得到待测血糖信息的待测血糖序列。
[0066]
需要说明的是,待测血糖信息的时间段可调整,根据预处理中的滑动窗口的参数值进行调整。
[0067]
s20、基于预先建立的pisa约束集合和所述预处理后的待测血糖信息,采用相似度度量处理方式,获取待测血糖信息所属的约束关系;
[0068]
所述pisa约束集合为半监督semi-knn模型训练阶段基于先验知识构造的具有ml约束、cl约束的集合,集合中每一元素为血糖子序列的一阶差分特征的信息。pisa约束集合中一定包含pisa信息,即根据pisa时间戳标签对训练阶段的血糖数据进行的预处理,然后创建的pisa约束集合。
[0069]
s30、将所述预处理后的待测血糖信息、约束关系输入到预先训练的半监督semi-knn模型中,所述半监督semi-knn模型输出待测血糖信息的分类结果;
[0070]
所述半监督semi-knn模型为采用训练数据集和所述pisa约束集合对knn模型进行训练,得到的用于识别血糖信息异常的半监督方式的模型,且所述训练数据集包括经由一阶差分处理的血糖数据。可理解的是,训练数据集是对训练阶段获取的血糖数据经由华创处理后的子序列集合进行一阶差分处理后的数据集。
[0071]
本实施例的方法基于semi-knn模型进行异常分类,其解决了knn模型在执行异常检测时的不确定性问题;首次以约束形式引入先验知识形成半监督的异常检测方法,最大限度的利用有效先验知识,提高了检测结果的可靠性;通过对结果划分等级,提高结果的可信度,达到帮助医生实现临床判断的效果。
[0072]
在实际应用中,在上述步骤s10之前,图1所示的方法还可包括下述的图中未示出的步骤:
[0073]
s01、借助于连续血糖监测系统cgm(即cgm设备)获取多个历史血糖数据,并对每一历史血糖数据进行预处理,并得到血糖序列;每一血糖序列中包括具有pisa时间戳标签的血糖数据和非pisa时间戳标签的血糖数据;
[0074]
s02、将每一血糖序列划分为多个子序列,并对每一个子序列进行一阶差分计算,得到训练数据集;
[0075]
举例来说,所述s02可包括:
[0076]
对每一个血糖序列做滑动窗口处理,在血糖序列x={x1,x2,
…
,xn}中,经大小为w滑动窗口后形成若干子序列qi={xi,x
i 1
,
…
,x
i k
},
[0077]
一个序列子集为d={q1,q2,
…
,qm},对每一个子序列qi按照公式(2)进行一阶差分计算,
[0078]
h为一阶差分公式的改变量,h取值为0.8-1.2,优选取1;
[0079][0080]
对所有的子序列计算一阶差分后,每一子序列的一阶差分值作为训练数据集。
[0081]
s03、基于先验知识和训练数据集中的具有pisa时间戳标签的训练数据,按照半监督约束条件形成规则,生成pisa约束集合;
[0082]
s04、将所述训练数据集和pisa约束集合对半监督semi-knn模型进行训练获取训练后的半监督semi-knn模型;
[0083]
所述半监督semi-knn模型为改进knn模型并采用半监督方式构建的。
[0084]
举例来说,s04可包括:
[0085]
s04-1、遍历训练数据集的所有子序列,构建离线k维搜索二叉树,得到k-d树;
[0086]
s04-2、基于所述k-d树,遍历pisa约束集合,获取半监督semi-knn模型的异常阈值σ,所述异常阈值的边界阈值为σ1和σ2,表示为σ=[σ1,σ2];
[0087]
其中,采用dtw相似性度量函数计算pisa约束集合中每一个pisa事件与其他事件的平均距离,得到距离集合;
[0088]
则根据下述公式(1)获得异常阈值σ=[σ1,σ2];
[0089]
σ1=q3 1.5(q3-q1),公式(1)
[0090]
σ2=q1-1.5(q3-q1),
[0091]
待测血糖数据距离pisa约束中ml关系的样本距离dist《σ2,则确定为异常样本;待测血糖数据距离pisa约束中cl关系的样本距离dist》σ1,则确定为异常样本;
[0092]
q3为距离集合中的上四分位数,q1为距离集合中的下四分位数。
[0093]
为更好的理解上述的步骤s20,该步骤s20可具体说明如下:
[0094]
当待测血糖序列中每一序列的血糖数据a与pisa约束集合中一个pisa事件b的sbd距离小于阈值λ时,即f
sbd
(a,b)《λ,则确定一个约束关系ml(a,b),并对pisa约束集合进行更新;λ为预设的大于0的数值;f
sbd
表示两个序列计算sbd距离的函数;
[0095]
当待测血糖序列中每一序列的血糖数据a与pisa约束集合中一个pisa事件b的cl约束关系的sbd距离小于阈值λ时,即f
sbd
(a,b)《λ,则确定一个约束关系cl(a,b),并对pisa约束集合进行更新;
[0096]
遍历待测血糖序列中每一序列,并将更新后的pisa约束集合作为待测血糖信息所属的约束关系。
[0097]
相应地,上述步骤s30可包括:
[0098]
基于所述k-d树和待测血糖序列,循环迭代方式获取距离到待测血糖序列中每一数据的最近的k个数据点,并得到使用阶段的k-d树,
[0099]
基于使用阶段的k-d树,遍历约束关系,获取待测血糖序列的pisa异常信息的分类结果;
[0100]
采用dtw相似性度量函数计算约束关系中每一个pisa事件与其他事件的实际距离,将该实际距离和异常阈值σ=[σ1,σ2]进行比较,获得属于pisa事件和非pisa事件的分类结果。特别地,将实际距离与异常阈值进行比较后,确定属于约束关系中ml约束的数据量,根据该数据量确定属于pisa事件中异常等级值。
[0101]
本实施例的方法可集成在电子设备如异常检测器中,该异常检测器可识别pisa的异常问题,由此,在临床的急症患者护理中使用上述异常检测器,有效监测并可靠的量化患者的异常状态,解决了现有技术中的滞后性、实现了实时监测和分析。
[0102]
本实施例中首次提出通过半监督方法进行cgm传感器故障诊断,通过引入先验知识(比如专家经验),提高了故障诊断结果的准确性。同时解决了knn算法在执行异常检测时的不确定性问题。
[0103]
实施例二
[0104]
本实施例的方法可按照准备阶段、训练阶段和使用阶段的顺序对本实施例的方法进行详细说明,参照图5所示。
[0105]
1.准备阶段——历史cgm血糖数据获取及预处理
[0106]
连续血糖监测系统cgm(continuous glucose monitoring)是人工胰腺的关键部件之一,通过该设备可以对患者的血糖水平进行连续监控,从而帮助一型糖尿病(t1dm)患者将血糖浓度维持在安全范围内。
[0107]
1.1cgm血糖数据获取
[0108]
cgm通过葡萄糖感应器监测皮下组织间液的葡萄糖浓度而间接反映血糖水平,可提供连续、全面、可靠的全天血糖信息。所获取的历史血糖数据应包含完整三天数据,其中每五分钟采集一次血糖值,共3*288个血糖值,其中除了餐食、运动、睡眠等正常生理活动之
外,应包含实验按压所获得的若干个pisa典型故障信息,每一个pisa典型故障信息可包括准确的按压标签,用于建立后续的半监督semi-knn模型。
[0109]
1.2cgm血糖数据预处理
[0110]
通过上述设备即cgm采集历史血糖数据保存在存储设备中,可通过数字信号分析的方式进行预处理,包括滤波、缺失值填补、打标等。其中,滤波是为了去除cgm血糖序列上的孤立噪声点,孤立噪声点意为与该时刻前后血糖值偏差过大的数据,使用滑窗遍历序列,当滑窗范围内存在此类微小区域时将其平均处理,此步骤为可选的步骤,滤波后的血糖序列更平滑,便于后续处理。缺失值填补是为了防止存在血糖值空缺的情况,通常在使用的血糖序列是对缺失值填补之后的血糖序列,否则,容易出现后续处理中血糖曲线的断层,使得模型输出结果不准确。
[0111]
在实际处理中,还需要对填补后的血糖序列进行打标处理,对存在按压动作的实验区间段进行标记,其余时间不进行标记,用来区分pisa事件和其他未知事件,由此,可有效保证半监督semi-knn模型的准确性。
[0112]
上述是对cgm采集的血糖数据的预处理过程的说明。连续采集的包含pisa按压实验事件的cgm血糖序列经过预处理之后得到滤波、缺失值填补后的血糖序列和pisa时间戳标签。
[0113]
2.准备阶段——构造特征并根据先验知识添加初始种子
[0114]
由实验按压的pisa事件时间段可知,可以对血糖序列中的部分数据进行打标处理,上述预处理得到的pisa时间戳标签,比如9:00
–
9:45区间,基于pisa时间戳标签获取血糖序列中9个血糖值为pisa事件发生时的血糖值,其对应的一阶差分特征也就对应为pisa事件特征。
[0115]
2.1构造特征
[0116]
通常,血糖序列中血糖数据较多,无法使用几个数值表达整个序列的特征,本实施例中采用滑动窗口方式对血糖序列进行处理。具体地,在血糖序列x={x1,x2,
…
,xn}中,经大小为w滑动窗口后形成若干子序列qi={xi,x
i 1
,
…
,x
i k
},一个序列子集定义为d={q1,q2,
…
,qm},对每一个子序列qi进行一阶差分计算,计算公式(1)如下,其中h为一阶差分公式的改变量,本实施例在血糖序列特征构造中h取值0.8至1.2,优选取1;
[0117][0118]
对所有的子序列计算一阶差分后,作为后续模型即半监督semi-knn模型的输入。本实施例中采用一阶差分特征,一方面避免原始血糖序列形态各异造成对模型通用性的影响,另一方面一阶差分特征对时间序列的波动性有较好的抑制作用,可以让半监督semi-knn模型的输入更加简单。
[0119]
2.2根据专家经验(先验知识)添加初始种子
[0120]
当前半监督操作的数据集中若干个数据点的代表样本称为种子seed,其表现形式可以为样本点本身,或者以约束形式存在。成对约束由must-link(ml)和cannot-link(cl)组成,ml约束中的两个数据点必须在同一个集群中,而cl约束声明的两个数据点必须在不同的集群中。
[0121]
本实施例中,将已知的pisa事件标签规定为半监督模型的初始种子,与其他生理
knn模型的异常阈值σ,所述异常阈值的边界阈值为σ1和σ2,表示为σ=[σ1,σ2]。
[0138]
计算每一个pisa事件于其他正常生理事件的平均距离,该距离通常采用欧式距离,但为了适合血糖序列数据类型,更好的表达时间序列的形状相似性,这里使用在时间轴下warping扭曲以达到更好的对齐效果的dtw相似性度量函数。得到所有的平均距离之后,计算该距离集合的上四分位数q3和下四分位数q1,则模型的异常阈值σ1=q3 1.5(q3-q1),σ2=q1-1.5(q3-q1),当距离正常样本的距离dist》σ1或dist《σ2时,认为该样本为异常样本。
[0139]
也就是说,待测血糖数据距离pisa约束中ml关系的样本距离dist《σ2,则确定为异常样本;待测血糖数据距离pisa约束中cl关系的样本距离dist》σ1,则确定为异常样本。
[0140]
4.使用阶段——获得新到血糖数据,执行约束传播
[0141]
半监督semi-knn模型训练完成之后,可以对实时采集的血糖数据进行检验,当新到的血糖序列包含pisa故障事件(即非pisa事件)时,可以做到准确的识别。
[0142]
4.1待测血糖数据
[0143]
获取待分析的连续且至少包含45分钟内的血糖值,也就是9个血糖测量点,并进行预处理,如滤波处理,并通过滑动窗口方式实现去除待测血糖信息中的孤立噪声点并实现缺失值填补,得到待测血糖信息的待测血糖序列。4.2约束传播
[0144]
对待测血糖序列执行约束传播算法,目的是将原先训练数据集中的pisa约束集合进行扩充,从而在半监督semi-knn模型使用时辅助判断,使结果更加精确。
[0145]
具体执行过程如下:
[0146]
4.2.1遍历原先训练数据集中的pisa约束集合,计算sbd距离
[0147]
当一个序列子集为d={q1,q2,
…
,qm},d中的任意qi将其他序列视为最近邻,最近邻的意思是当前序列到其他子序列ql的距离均小于阈值λ,该阈值可以通常是人为规定,上述的成对约束包含以下性质:
[0148]
1)任意q∈d,可以生成ml(q,r),其中r∈d;
[0149]
2)给定ml(p,q)、(q,r)可以得到ml(p,r);
[0150]
3)给定ml(p,q),可以生成ml(c,p)和ml(p,r),其中c∈d,r∈d;
[0151]
4)给定cl(p,q),可以生成cl(c,p)和cl(p,r),其中c∈d,r∈d。
[0152]
本实施例中选择的距离度量为sbd距离,sbd算法是一种基于互相关的形状相似性度量,其高效且无参数的特性是dtw度量所不可比拟的,dtw是一种精度很高但计算成本也很高的测量方法。并且sbd算法的精度接近于dtw算法,因此sbd可以更好的用来度量cgm曲线间的相似性,并方便实现在线的相似性计算。
[0153]
4.2.2执行约束传播
[0154]
当待测血糖序列中每一序列的血糖数据a与训练数据集中某个pisa事件b的sbd距离小于阈值λ时,即f
sbd
(a,b)《λ,则可以确定一个约束关系ml(a,b),由上述约束传播性质可以对约束集合进行更新。
[0155]
当待测血糖序列中每一序列的血糖数据a与训练数据集中某个pisa事件b的cl约束关系的sbd距离小于阈值λ时,即f
sbd
(a,b)《λ,则可以确定一个约束关系cl(a,b),同样由上述约束传播性质可以对约束集合进行更新。
[0156]
5.使用阶段——使用半监督semi-knn模型检测异常,并判断异常等级
[0157]
执行完步骤4之后,输入半监督semi-knn模型的为待测血糖序列中每一序列的血糖数据和对pisa约束集合扩充的约束关系,使用步骤3.2.2所建立的半监督semi-knn模型进行异常检测,并根据约束关系判断异常等级,具体执行步骤如下:
[0158]
5.1搜索k最近邻,并计算平均距离
[0159]
待测血糖序列中每一序列的血糖数据(即新的血糖数据)输入到半监督semi-knn模型中,通过步骤3.2.1建立的k维搜索二叉树,可以得到距离每一序列的血糖数据最近的k个数据点,比如依据上述步骤3.2.1建立的k维搜索二叉树样本,假设每一序列的血糖数据是(2.1,3.1),如图3所示。首先通过二叉搜索,找到最近邻的近似点(2,3),计算距离是0.1414;然后回溯到父节点(5,4),以(2.1,3.1)为圆心,0.1414为半径,发现与y=4的超平面不相交,因此不用进入到右子空间搜索;然后再回溯到父节点(7,2),该圆也不与x=7的超平面相交,因此不用进入(7,2)的右子空间搜索;至此回溯完毕,得到最近的样本为(2,3),循环迭代k次即可得到最近的k个样本点,称为k近邻。k近邻得到后,计算与每一序列的血糖数据的平均距离,用该距离作为异常判定的得分,当该得分满足3.2.2阈值情况时,将该样本点视作pisa故障事件。
[0160]
需要说明的是,在迭代过程中,当新到样本存在与pisa的约束关系时,应满足k近邻样本中不包含cl关系,即迭代过程中如果遇到cl关系的样本距离新到样本的距离满足k近邻的要求,应当舍弃该样本,继续向下迭代,约束关系对knn的异常检测迭代过程指引作用可以用图4表示。
[0161]
5.2根据约束关系,输出异常等级
[0162]
上述步骤输出异常检测结果的同时,可以考虑统计k近邻中是否包含pisa的约束关系。也就是得到每一序列的血糖数据的在半监督semi-knn模型中的距离之后,除了与异常阈值进行比较,还需要考虑是否存在约束关系,即前述的约束传播阶段所获取的结果。
[0163]
具体操作如下:当不包含任何约束关系时,判断为异常等级1;当包含扩充的pisa约束集合的ml关系时,依据包含扩充的pisa约束集合的ml关系数量分配更高的异常等级2,3,
…
n。存在扩充的pisa约束集合的ml约束越多时,异常等级越高。
[0164]
前述的dtw(dynamic time warping)算法用于检测两条时间序列相似程度,对时间序列进行拉伸或压缩,使其尽可能的对齐。大部分情况下,两个序列整体上具有非常相似的形状,但是这些形状在x轴上并不是对齐的。在比较相似度之前,需要将其中一个(或者两个)序列在时间轴下warping扭曲,以达到更好的对齐。而dtw就是实现这种warping扭曲的一种有效方法。
[0165]
sbd算法是一种基于互相关(cross-correlation)的形状相似性度量,其高效且无参数的特性是dtw度量所不可比拟的,dtw是一种精度很高但计算成本也很高的测量方法。并且sbd算法的精度接近于dtw算法,因此sbd可以更好的用来度量cgm曲线间的相似性,并方便实现在线的相似性计算。
[0166]
通过互相关计算两条时序数据之间的滑动内积,对于相位偏移具有原生的鲁棒性。对于给定的两条时间序列x=(x1,x2,
…
,xm)和y=(y1,y2,
…
,ym),以及给定对应的相位差s,两条曲线的内积结果如下:
[0167]
[0168][0169]
标准互相关ncc及距离度量sbd可计算如下:
[0170][0171][0172]
本实施例对上述相似度度量方式进行实验,实验结果可知,sbd相似性度量算法抗噪能力强,可以有效的区分出pisa故障事件与正常序列的波形差距,而其它序列之间的噪声差异可以有效避免;dtw相似性度量算法对形状特征敏感,在距离输出归一化后可以放大形状的微小差异;欧氏距离对血糖曲线幅值敏感,即在原始序列分布中的绝对距离差能被完整的表现出来。
[0173]
实施例三
[0174]
本实施例还提供一种电子设备,包括:存储器和处理器;所述处理器用于执行所述存储器中存储的计算机程序,以实现执行上述实施例一和实施例二任意所述的基于半监督semi-knn模型的pisa故障识别方法的步骤。
[0175]
应当注意的是,在权利要求中,不应将位于括号之间的任何附图标记理解成对权利要求的限制。词语“包含”不排除存在未列在权利要求中的部件或步骤。位于部件之前的词语“一”或“一个”不排除存在多个这样的部件。本发明可以借助于包括有若干不同部件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的权利要求中,这些装置中的若干个可以是通过同一个硬件来具体体现。词语第一、第二、第三等的使用,仅是为了表述方便,而不表示任何顺序。可将这些词语理解为部件名称的一部分。
[0176]
此外,需要说明的是,在本说明书的描述中,术语“一个实施例”、“一些实施例”、“实施例”、“示例”、“具体示例”或“一些示例”等的描述,是指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0177]
尽管已描述了本发明的优选实施例,但本领域的技术人员在得知了基本创造性概念后,则可对这些实施例作出另外的变更和修改。所以,权利要求应该解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0178]
显然,本领域的技术人员可以对本发明进行各种修改和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也应该包含这些修改和变型在内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。