1.本发明涉及全面工厂控制技术领域,特别是涉及一种用于样本不足的工控系统的工控异常检测方法。
背景技术:
2.近年来,随着工业控制系统广泛应用于各个领域,工控异常检测算法变得尤为重要。异常检测算法对大量样本数据进行机器学习,根据标签掌握数据特点。
3.机器学习需要大量的样本数据,但对于大部分工厂而言,工控异常发生率是非常低的,因此能够获得的样本的量也非常小,远不足以满足机器学习的需求。即使是设备众多的化工厂,其操作范围依然很宽,在操作范围内可以确保dcs正常运转,以至于很多化工厂全寿命周期内,仅仅有几十次乃至更低的工控异常,远不足以完成机器学习的训练。即使有足够多的工控异常数据,在作为样本进行机器学习训练前还需要由相关领域的专家(需同时懂机器学习以及相关的工厂知识,人难找且薪资要求高)进行分析标注,需要投入大量的人力成本。
4.为解决这一难题,目前常用的方法是迁移学习,也即借用已经存在的知识对不同但相关领域缺乏样本的场景进行训练学习。最常用的迁移学习算法为tradaboost及其变形,算法中已进行过机器学习的数据集称作源域,待进行机器学习的数据集称作目标域,tradaboost算法要求以上两个数据集同结构,但由于工控异常数据来源稀少,可选的源域很少,很难让两个数据集同结构;即使能采用tradaboost算法,也会因为源域和目标域差别较大而导致分类器的auc值(可以近似理解为分类器的准确度)不高。此外,发明人发现,采用tradaboost算法进行机器学习时,迭代次数并非越大越好,而是存在一个最优值,但受限于计算量,这个最优值很难求取。
技术实现要素:
5.本发明提供一种用于样本不足的工控系统的工控异常检测方法。
6.解决的技术问题是:采用tradaboost算法进行工控异常迁移学习时,由于工控异常数据来源稀少,可选的源域很少,很难让两个数据集同结构,导致tradaboost算法应用受限;即使能采用tradaboost算法,也会因为源域和目标域差别较大而导致分类器的auc值不高;为解决上述技术问题,本发明采用如下技术方案:一种用于样本不足的工控系统的工控异常检测方法,采用机器学习算法来构建分类器,然后用分类器监测工控系统中各传感器的读数以判断当前是否处于工控异常状态,所述机器学习算法为tradaboost算法,且分类器的构建过程包括以下步骤:步骤一:合并源域的训练集和目标域的训练集;步骤二:初始化源域的训练集和目标域的训练集的权重;步骤三:使用二分类模型来训练合并后的训练集,得到一个分类器,记作临时分类器;步骤四:计算临时分类器在目标域的测试集上的错误率;
tradaboost算法,圆型表示adaptive-tradaboost算法,正三角是本文提出的乘以距离倒数的自适应回补参数算法;图4为基分类器数对auc的影响图,图中横坐标为基分类器个数,纵坐标为最终的分类器在目标域的测试集上的auc值;图5为迭代次数对auc的影响图,图中横坐标为迭代次数,纵坐标为最终的分类器在目标域的测试集上的auc值。
具体实施方式
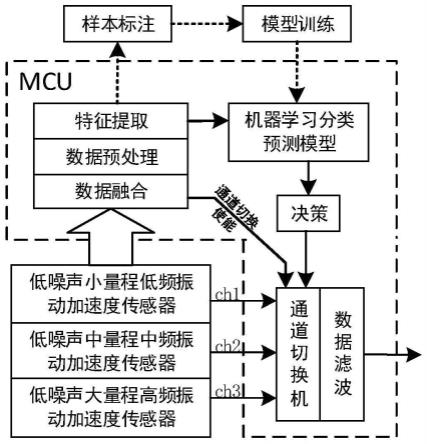
18.一种用于样本不足的工控系统的工控异常检测方法,采用机器学习算法来构建分类器,然后用分类器监测工控系统中各传感器的读数以判断当前是否处于工控异常状态。分类器可看作是一个函数,来自传感器的各种数据,如温度、压力、流量等作为自变量,而是否处于工控异常状态为因变量。这一函数可以集成到dcs系统或plc系统中,由dcs系统或plc系统自动根据传感器的读数进行判断并展示给工作人员。
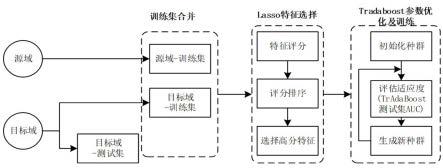
19.机器学习算法为tradaboost算法,且分类器的构建过程包括以下步骤:步骤一:合并源域的训练集和目标域的训练集;步骤二:初始化源域的训练集和目标域的训练集的权重;步骤三:使用二分类模型(gbdt、svm、lr、nn等都是可以的)来训练合并后的训练集,得到一个分类器,记作临时分类器;步骤四:计算临时分类器在目标域的测试集上的错误率;计算用的公式属于公知常识,这里不再赘述;注意这里在样本充足的场合中,是计算临时分类器在目标域的验证集上的错误率的,目标域通常按训练集、验证集、测试集分成6比2比2的比例,但本技术中这种样本很少的场合,这么分将导致训练集的数据不够。因此这里选择按3比1的比例将目标域分成训练集和测试集两部分;步骤五:根据错误率求取回补参数,源域的训练集的权重乘以回补参数;步骤六:迭代进行步骤三到五,迭代次数记作n,迭代完成后,输出最终的分类器;n由遗传算法求取。
20.源域和目标域的样本特征维数不相等;步骤三中,先评判样本特征对响应的影响程度高低,对所有的样本特征进行降序排列,然后截取排序靠前的样本特征进行训练,截取的样本特征维数不大于源域的样本特征维数、且不大于目标域的样本特征维数,以使两个样本特征维数的数据集可以用tradaboost算法进行迁移学习。
21.基于lasso模型对样本特征进行降序排列,lasso模型中,损失函数如下:假设样本数目为m,特征维度为n,式中x为m
×
n的矩阵,y为m
×
1的向量,α为常数系数,θ为n
×
1的向量,为经验损失函数,含义为惩罚系数、取值为θ的l1范数。由于正则项非零,这就迫使那些弱的特征所对应的系数变成0。根据特征所对应系数据的绝对值从大到小排序,在取前若干维度时,就能保证取到的数据是重要数据。
22.通过控制变量法求取截取的样本特征维数的最优值,其中,自变量为样本特征维
数,因变量为最终的分类器的auc值,样本特征维数的最优值需使最终的分类器的auc值最高。
23.步骤五中,采用源域和目标域的距离对回补参数进行修正。
24.步骤五中,回补参数,其中,t代表计算回补参数时处于第几次迭代,为当前的临时分类器在目标域的测试集上的错误率,d为源域和目标域的距离。
25.回补参数求取过程如下:假设所有源域样本均被正确分类,第t 1次迭代时,源域样本权重之和满足,而目标域所有样本权值之和s
t
可表示为:上式中m和n分别表示源域和目标域的样本数目,ε错误率,t迭代次数,w权重,h基分类器。当t 1次迭代时,源域样本权重分布为:假设回补参数为c
t
,经过t迭代后,源域样本权重趋于平稳,源域样本权重趋于平稳,即,计入源域和目标域的距离,经过公式推导得到自适应回补参数为:从理论上分析,权重的调整应该结合两个数据集相似程度,两个数据集越相似,源域对目标域的帮助越大,回补参数越大;反之,两个数据集越不相似,回补参数越小。所以本文采用最大均值差异(maximum mean discrepancy, mmd)计算两个数据集的距离,距离的倒数乘以c
t
,以此来根据数据关联调整权重,如下:步骤三中,采用堆叠泛化的方式进行训练。
26.基分类器个数以及迭代次数同时通过遗传算法求取。
27.求取基分类器个数以及迭代次数的遗传算法中,染色体由任务序列编码,群体初始化采用基分类器数目和迭代次数,适应度函数为评价指标auc的值,选择算子为轮盘赌选择,交叉算子为单点交叉,突变算子为位反转突变,本实施例中,由于数据离散程度高,收敛很快,因此未设置精英保留策略。如果实际使用中,难以收敛到全局最优解,精英保留策略可选择保留适应度最高的若干组,比如3-5组。
28.实施例1:本实验运行在windows10系统,cpu为amd ryzen 7 4800h,gpu为nvidia geforce rtx 2060,内存16.0 gb,python版本3.7,tensorflow版本为1.14。
29.本实验采用两个数据集进行实验验证,其中一个数据集为工控领域公开数据集作为源域数据,另一个为工控领域自建数据集作为目标域数据。公开数据集是新加坡科技大学网络安全研究中心2018年构建的攻击水厂系统的c-town水分配数据集(简称新加坡水厂
数据集)(riccardo taormina et al. battle of the attack detection algorithms: disclosing cyber attacks on water distribution networks[j]. journal of water resources planning and management, 2018, 144(8). doi: 10.1061/(asce)wr.1943-5452.0000969)。新加坡水厂数据集网络管道由429个管道,388个连接点,7个储罐,11个泵等组成。该网络包括scada系统,其作用是协调操作并存储所提供的读书plc。本文采用数据集的全部数据15551条,123维。自建数据集来自某油库工控系统,数据集包含26个过滤器、14个泵,14个罐、管道等组成。数据集采用多种攻击作为异常样本,异常样本攻击包括数据篡改和数据劫持等假数据类型攻击。本文目标域实验数据为3959条训练数据,1320条测试数据。
[0030]
首先经过探究发现,源域与目标域样本比例在3:1以内,更有利于迁移到目标域。两个数据集数量存在差异,所以初始权重为数据量的倒数。其次检查数据匹配度,发现新加坡水厂数据包含123个特征,而自建数据集包含131个特征,特征不匹配先进行特征重排序,最多可以保留前123维,但是数据多不意味着效果好,特征选择保留数据为50时结果最优,具体实验结果如图2所示。
[0031]
图中横轴为特征数目,纵轴为auc的值。从图中可以看出来,当特征选择数量为50的时候,最有利于分类器的构建,auc的数值达到了97.2%。
[0032]
特征选择完成以后,采用mmd计算两个数据集的距离约为6,并同时采用几种现有的tradaboost进行比较,结果如图3所示。从图中可以看出来添加自适应回补参数的两条线上升速度快,权重两极分化严重,且其他三组参数均高于乘以距离倒数的自适应回补参数的一组。
[0033]
采用遗传算法对基分类器个数以及迭代次数进行优化,结果如图4-5所示,基分类器个数为70,迭代次数为7时最优。
[0034]
算法各个部分完成后,输入源数据和目标数据实验结果与其他算法的对比结果如下表所示:以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。