1.本发明属于面向化学品风险管理的高通量筛查技术领域,涉及到一种基于定量构效关系(qsar)模型筛查致癌性化学品的方法。
背景技术:
2.致癌性化学品的筛查,是化学品风险管理的核心内容之一。致癌性是指人类暴露于某些化学品后,这些化学品可诱发个体癌症的发生或增加群体癌症发病率的性质。因其产生后果的严重性,因此有必要在其进入到环境前对具有致癌性的化学品进行筛查。
3.经济合作与发展组织(oecd)发布的相关导则(oecd导则451)主要基于啮齿动物的致癌试验。但这种测试方法,耗时长、效率低并且有违动物伦理,难以实现对数量众多的化学品的致癌性进行一一评定。需要发展高效(高通量)的筛查技术。基于定量构效关系(qsar)的计算模拟技术,建立化学品分子结构特征与其致癌性之间的关联,可有效筛查具有致癌性的化学品。
4.随着化学品种类的多样性增加,分子特征更加丰富,能够在同类化学品的少数物理化学描述符与其性质之间构建线性的qsar已不能满足筛查需求。近年来,基于机器学习算法的qsar在挖掘预测终点与大量分子特征内在联系方面呈现出较强优势,其中,集成学习策略的引入,能够发挥多种机器学习算法的优势,从而有效提高模型的预测性能,有望在致癌性化学品筛查方面发挥重要作用,有助于筛选优先控制具有致癌性的化学品。
5.目前,已有一些研究构建了化学品致癌性的qsar预测模型。文献“food chem.toxicol.,2016,97,141-149.”构建了基于致癌潜力数据库(cpdb)中1042种化学品描述符与指纹特征相结合预测化学品致癌性的朴素贝叶斯模型;文献“regul.toxicol.pharmacol.,94,8-15.”构建了基于多个数据库(包括体内大鼠致癌数据库isscan)中的化合物的描述符的k近邻、随机森林和多层感知机等模型。此外,文献“sci.rep.,7,2118.”构建了基于cpdb数据库中1003种化合物的指纹特征的单一算法的集成模型。已有模型未进行明确的应用域表征,并且每种机器学习算法都有其优势,基于单一算法的集成学习模型难以发挥出算法各自的优势。因此,有必要发展基于多种算法的集成学习模型来筛查致癌性化学品。
6.基于以上原因,通过对cpdb数据库中的化合物进行处理,获取了805种化学品的致癌性数据,通过padel-descriptor软件计算了这些化合物的pubchem指纹,构建了筛查致癌性化学品的集成学习模型,并对模型应用域进行了表征,明确了模型的适用范围。
技术实现要素:
7.本发明构建了一种高效的筛查致癌性化学品的集成学习方法,该方法可以根据化学品smiles码计算得到的pubchem指纹,构建预测化学品致癌性的分类模型,为致癌的化学品筛查提供基础工具;在建模过程中参照oecd对qsar模型构建和使用导则,进行了内、外部验证考察模型的稳健性和预测能力。
8.本发明的技术方案:
9.一种筛查致癌性化学品的多种算法集成的方法,步骤如下:
10.(1)数据库构建
11.从cpdb数据库整理了805种化学品的致癌终点数据,其中包括427种致癌物和378种非致癌物;这些数据中不包括无机物、有机金属化合物以及混合物,c原子数小于3的化合物,分子质量《40和》600的化合物。
12.(2)计算化学品的分子指纹
13.采用open babel 2.3.2.2软件将记载化学品smiles码的csv格式文件转化成sdf格式文件;将sdf文件输入padel-descriptor 2.21软件中,计算pubchem指纹并进行了预处理和特征筛选,预处理过程包括去掉缺失值和方差为0的特征,特征筛选过程中计算了pubchem每一位特征间的皮尔森相关系数,为防止过拟合将大于0.7的特征去除;
14.(3)模型训练
15.以化合物的pubchem指纹作为模型的输入,有无致癌性作为模型的预测终点,构建分类机器学习模型。将数据集按3:1的比例随机拆分为训练集和测试集,内部验证采取十折交叉验证重复十次,以减小随机误差。测试集用于模型的外部验证。采用四种机器学习算法:支持向量机(svm,support vector machine),随机森林(rf,random forests),梯度提升决策树(gbdt,gradient boosting decision trees)和人工神经网络(ann,artificial neural network)作为基分类器,采取三三组合的方式并结合软投票的策略构建了共4个集成模型。在ann模型中,为了避免过拟合,采用批处理(每次输入一定数目的训练样本)和dropout方法,该方法可用于训练样本相对较小而特征维数多的数据集。在迭代次数下,随机将一定比例的隐藏层的神经元的权重设为0,以此来提升模型的泛化能力。通过网格搜索法确定算法的最佳超参数;集成模型的最佳超参数源于每种基分类器的最佳超参数。
16.模型调节的超参数如下:基分类器svm的最佳超参数为径向基作为核函数,c=1000,gamma=1;基分类器rf的最佳超参数为用gini指数划分属性,最大深度(max_depth)为40,弱分类器即决策树的数目(n_estimators)为1000,每棵决策树的最大特征数为总特征数的平方根(max_features='sqrt'),随机种子(random_state)设为10;基分类器gbdt的最佳超参数为学习率(learning_rate)等于0.001,max_depth=20,n_estimators=2000,max_features='sqrt',random_state=10;基分类器ann的最佳超参数为隐藏层神经元(neurons)个数为512,每批次训练的样本数(batch_size)为500,dropout_rate=0.5,总迭代次数(epochs)为500,输入层采用线性整流函数作为激活函数,隐藏层采用sigmoid函数作为激活函数,二分类的交叉熵作为损失函数,优化器选择rmsprop(root mean square prop),在更新权重时可修正梯度的摆动幅度,同时使得损失函数更快收敛。
17.(4)模型评估
18.使用训练集准确率(ra),敏感度(r
se
),特异性(r
sp
)和受试者工作特征曲线(roc)下的面积(a
roc
)表征模型拟合优度;验证集的ra,r
se
,r
sp
,a
roc
和马修斯相关系数(r
mcc
)表征模型预测能力;使用训练集的十折交叉验证的标准偏差(std)表征模型稳健性。
19.最终模型的预测效果为:
20.由svm,gbdt和ann算法构建的集成模型表现效果:r
a(train)
=0.927,std
train
=4.6,r
se(train)
=0.932,std
train
=5.6,r
sp(train)
=0.922,std
train
=3.7,a
roc(train)
=0.945,std
train
=4.1,r
a(test)
=0.792,r
se(test)
=0.878,r
sp(test)
=0.609,a
roc(test)
=0.816,r
mcc
=0.506;
21.由svm,rf和ann算法构建的集成模型表现效果:r
a(train)
=0.929,std
train
=4.3,r
se(train)
=0.934,std
train
=5.4,r
sp(train)
=0.924,std
train
=3.4,a
roc(train)
=0.947,std
train
=4.2,r
a(test)
=0.792,r
se(test)
=0.878,r
sp(test)
=0.609,a
roc(test)
=0.812,r
mcc
=0.506;
22.由rf,gbdt和ann算法构建的集成模型表现效果:r
a(train)
=0.871,std
train
=4.9,r
se(train)
=0.875,std
train
=6.4,r
sp(train)
=0.869,std
train
=3.4,a
roc(train)
=0.934,std
train
=4.2,r
a(test)
=0.792,r
se(test)
=0.878,r
sp(test)
=0.609,a
roc(test)
=0.815,r
mcc
=0.506;
23.由svm,gbdt和rf算法构建的集成模型表现效果:r
a(train)
=0.681,std
train
=6.0,r
se(train)
=0.710,std
train
=8.0,r
sp(train)
=0.657,std
train
=4.0,a
roc(train)
=0.743,std
train
=6.0,r
a(test)
=0.778,r
se(test)
=0.857,r
sp(test)
=0.609,a
roc(test)
=0.808,r
mcc
=0.478;
24.(5)应用域表征
25.采用rdkit软件包生成化学品的maccs分子指纹,计算验证集化学品分子a与训练集化学品分子b之间的谷本相似度(tanimotosimilarity),计算式如下:
[0026][0027]
其中,s
ab
是分子a和b的谷本相似度,x
ja
是分子a的第j个指纹特征,x
jb
是分子b的第j个特征,n是指纹的特征位数。
[0028]
定义相似度阈值(s
cutoff
)和最少相似分子数量(n
min
),来定义应用域,即若训练集中与目标分子谷本相似度大于s
cutoff
的化学品数超过n
min
,则判定该分子处于应用域内。本发明的应用域为:s
cutoff
=0.85,n
min
=1。对外部验证集进行了应用域表征,共72种化合物落在应用域内。
[0029]
本发明的有利效果是:所建集成模型可同时发挥不同算法的优势,模型的预测性能有所提高,且具有明确表征的应用域。该方法简便高效,有望在致癌性化学品的高通量筛查方面发挥作用,为健全化学品管理提供基础工具,服务于化学品风险管控和新污染物治理的国家重大需求。
附图说明
[0030]
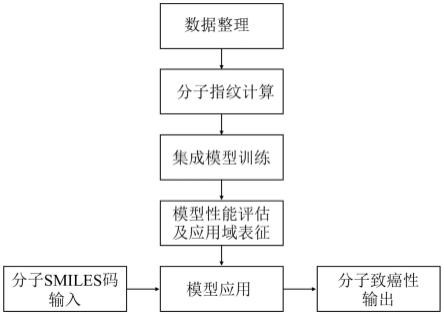
图1为整体方法的构建流程。
具体实施方式
[0031]
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
[0032]
实施例1
[0033]
给定一个化学品叔丁基对苯二酚(cas号:1948-33-0),要预测其致癌性。首先根据叔丁基对苯二酚的smiles码,利用rdkit软件包计算其maccs分子指纹,然后计算其与训练集化学品分子的谷本相似度,计算得训练集中分子与其相似度大于0.85(s
cutoff
),所以叔丁基对苯二酚在模型应用域内。进一步利用padel-descriptor软件计算其pubchem分子指纹,使用本发明构建的集成模型进行预测。得到结果其活性为0,与实验结果一致。
[0034]
实施例2
[0035]
给定一个化学品甲硫氧嘧啶(cas号:56-04-2),要预测其致癌性。首先根据甲硫氧嘧啶的smiles码,利用rdkit软件包计算其maccs分子指纹,然后计算其与训练集化学品分子的谷本相似度,计算得训练集中分子与其相似度大于0.85(s
cutoff
),所以甲硫氧嘧啶在模型应用域内。进一步利用padel-descriptor软件计算其pubchem分子指纹,使用本发明构建的集成模型进行预测。得到结果其活性为1,与实验结果一致。
[0036]
实施例3
[0037]
给定一个化学品5-丙烯基-苯并-1,3-二氧戊环(cas号:120-58-1),要预测其致癌性。首先根据5-丙烯基-苯并-1,3-二氧戊环的smiles码,利用rdkit软件包计算其maccs分子指纹,然后计算其与训练集化学品分子的谷本相似度,计算得训练集中分子与其相似度大于0.85(s
cutoff
),所以5-丙烯基-苯并-1,3-二氧戊环在模型应用域内。进一步利用padel-descriptor软件计算其pubchem分子指纹,使用本发明构建的集成模型进行预测。得到结果其活性为1,与实验结果一致。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。