1.本发明涉及计算机视觉技术领域,特别涉及基于弱监督学习的视频目标分割 方法。
背景技术:
2.针对视频目标分割任务,现在主流的方法是基于全监督的视频目标分割,方 法包括时空记忆力模型(space-time memorynetworks,stm),前后背景融合模型 (collaborative video object segmentation by foreground-background integration, cfbi),小样本学习器模型(learning what to learn for video object segmentation, lwl)。这一类方法在训练阶段需要大量精标注的视频数据集,也就是要逐帧逐 像素对这些视频进行标注。在预测阶段需要提供每个视频的第一帧分割掩码,作 为模版告诉模型需要追踪哪些物体。全监督学习方法虽然能够得到较高的分割精 度,但是这类方法过度依赖逐帧逐像素精标注的视频训练集,人工标注成本过高, 且帧与帧之间往往较为相似,导致标注中有很多重复工作。
3.还有一类相似工作是只使用无标注视频学习的无监督视频目标分割。这类方 法训练过程是无监督的,主要利用了视频中的自然属性(如时序一致性、颜色等) 作为监督信号,学习到高级别的语义信息,然后用到视频目标分割任务上进行评 测。或者是把在静态图像上学习到的特征提取方法,迁移到视频上,用到视频语 义学习。这类方法不再依靠大规模精标注的数据集,但是由于没有第一帧分割掩 码的指导,他们的最终效果和全监督的视频目标分割方法还是有较大的差距。
4.目前也有个别研究者提出了弱监督的视频目标分割,也就是利用比分割掩码 更粗粒度的标签(比如定位框、多边形、点)来进行训练,使模型能够学习到分 割的功能。例如研究者paul voigtlaender提出了一种半自动视频标注方法,即使 用检测框到分割掩码(bounding box to segmentation mask,简称box2seg)模型,先 用定位框生成分割掩码作为伪标签,再用人工对伪标签进行精修,最终用来训练 视频目标分割网络。但是缺点在于他们使用的检测框到分割掩码模型是在静态图 像上训练的,分割效果不稳定;另一方面他们引入了人工进行交互式修正,成本 依然较高。
5.本发明的背景部分可以包含关于本发明的问题或环境的背景信息,而不一定 是描述现有技术。因此,在背景技术部分中包含的内容并不是申请人对现有技术 的承认。
技术实现要素:
6.本发明目的在于提供基于弱监督学习的视频目标分割方法,以克服传统检测 框到分割掩码模型不能利用时序信息导致分割效果不稳定以及引入人工进行交 互式修正导致成本较高的问题。
7.为实现上述发明目的,本发明采用以下技术方案:
8.基于弱监督学习的视频目标分割方法,包括如下步骤:
9.s1、输入原视频和定位框:输入原视频,经过抽帧得到得到各个帧的二维图 像,同时还得到各个帧的目标定位框,进行定位框级别的定位;根据定位框在原 图上进行切割,得到最后的切割后的图像;
10.s2、将所述切割后的图像和所述目标定位框输入管道分割模型后得到当前帧 的分割掩码即伪标签;
11.s3、用所述伪标签对视频目标分割模型进行训练。
12.进一步地:
13.步骤s1中,得到最后的切割后的图像的方法是:根据定位框向外拓展20% 的像素,在原图上进行切割,得到最后的切割后的图像。
14.进一步地:
15.所述管道分割模型是一种全卷积神经网络架构,该架构通过一个非本地模块 来充分利用输入序列的时序信息,从而捕获空间和时间中的长期依赖;非本地模 块由非本地块和拆分编码器两部分架构组成,其中拆分编码器包括询问编码器和 参考编码器,该架构能够将前序帧的图像语义信息和预测结果应用在当前帧的预 测中。
16.进一步地:
17.步骤s2中,得到当前帧的分割掩码包括如下步骤:
18.输入当前帧 定位框、真实分割掩码和前一帧分割掩码,其中当前帧 定位 框由询问编码器进行编码,真实分割掩码、前一帧分割掩码由参考编码器进行编 码,然后询问编码器和参考编码器得到的特征图经非本地块进行处理后,再通过 解码器解码,得到当前帧的分割掩码。
19.进一步地:
20.具体的管道分割模型结构如下:
21.输入包括当前帧加对应定位框、前序帧加分割掩码,将定位框作为第四通道 级联在当前帧后,分割掩码作为第四通道级联在前序帧后。
22.进一步地:
23.分割掩码包括第一帧真实掩码和后续帧预测结果的掩码。
24.进一步地:
25.对当前帧和前序帧分别裁剪和调整大小,并分别用不同的编码器进行编码, 对当前帧输入用询问编码器,对前序帧输入用参考编码器。
26.进一步地:
27.在两个编码器分别编码之后,将所有输入帧的特征图级联起来,并通过时空非本地块,得到softmax归一化之后的特征图;然后,对所得的特征图进行上采样解码,最终得到当前帧t的预测结果。
28.进一步地:
29.步骤s3中,在训练阶段,将交叉熵代价函数采用部分截断的交叉熵损失, 即部分截断的交叉熵代价函数。
30.基于弱监督学习的视频目标分割装置,使用上述的方法进行视频目标分割。
31.一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程 序,所述一个或者多个程序可被一个或者多个处理器执行,以实现上述的方法。
32.本发明具有如下有益效果:
33.本发明提出的基于弱监督学习的视频目标分割方法可以大大减小对于 精标注视频数据集的依赖,仅使用定位框作为监督信息进行训练也能够取 得较高的分割精度。
34.在一些实施例中,还有如下优点:
35.针对检测框到分割掩码模型进行改进,融合了视频的时序信息,因此 能够得到质量更高的伪标签,改善原本对每个视频帧独立进行检测框到分 割掩码分割造成的连续性差、物品遮挡漏检等问题;
36.对生成的伪标签进行了筛选和精修,筛去了坏样本、同时用人工标注 的准确分割掩码进行微调(finetune)精修,提升了伪标签的质量;
37.针对逐像素交叉熵代价函数进行改进,采用了截断的交叉熵损失函数, 因此模型更具鲁棒性,个别误分类的像素不会主导整个损失函数。
附图说明
38.图1是本发明实施例中基于弱监督学习的视频目标分割方法的流程图;
39.图2a-2d是本发明实施例中定位框在原图上切割的示意图;
40.图3a-3h是本发明实施例中利用图像和定位框预测分割掩码的示意图;
41.图4是本发明实施例中检测框到分割掩码模型的示意图;
42.图5是本发明实施例中管道分割模型的示意图;
43.图6是本发明实施例中原图和转换为矩阵后的定位框示意图;
44.图7是本发明实施例在两帧参考帧情况下通过管道分割模型预测分割掩码 的示意图。
具体实施方式
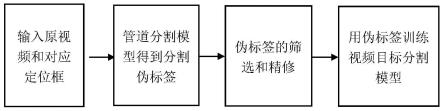
45.下面结合附图通过具体实施例对本发明作进一步的描述。以下实施例仅用于 更加清楚地表明本发明的技术方案,而不能以此来限制本发明的保护范围。
46.针对视频目标的分割任务,本发明提出了一种可以仅使用定位框标注进行训 练的方法,能够大大减轻对于逐帧逐像素精标注的视频训练集的依赖。本发明方 法的发明构思为:首先使用融合了视频时序信息的管道分割(tube to segmentation, 简称tube2seg)模型得到伪标签,并采用更具鲁棒性的损失函数、伪标签筛选等 方法优化伪标签,最后用生成的伪标签对视频目标分割模型进行训练。
47.本发明提出的仅用定位框进行训练的方法,在训练阶段只需定位框级别的标 注,在预测阶段仅提供第一帧的真实定位框,不需要对视频逐帧逐像素精标注, 能够大大减轻标注工作量。
48.本发明实施例提供一种基于弱监督学习的视频目标分割方法,具体流程如图 1所示,该方法主要包括以下四个步骤:
49.s1、输入原视频和对应定位框
50.如图2a-2d所示,原视频抽帧得到各个帧的二维图像,同时还得到各个帧的 目标定位框(即图2b-2d中的实线框)。根据定位框向外拓展20%的像素(即图 2a-2d中的虚线框),在原图上进行切割,就可以得到最后的切割后的图像(图 2d)。
51.s2、管道分割模型得到分割伪标签
52.如图3a-3h所示,检测框到分割掩码模型的目的是把利用输入的图像和定位 框,预测出对应定位框内目标物体的分割掩码(即伪标签)。其中图3a、图3c、 图3e和图3g分别为不同的输入的图像和目标定位框(图3a、图3c、图3e和图 3g中实线框),图3b、图3d、图3f和图3h分别为图3a、图3c、图3e和图3g 预测后对应定位框内目标物体的分割掩码。
53.传统检测框到分割掩码模型主要是编码器-解码器(encoder-decoder)的结构, 如图4所示,输入原图图像和真实检测框(定位框),经编码器学习得到更高层 的语义信息,并通过解码器得到高分辨率的逐像素分割掩码。但是传统检测框到 分割掩码模型是基于二维图像的,并没有融合视频的时序信息,因此直接利用在 视频上逐帧进行检测框到分割掩码分割,会有遮挡、形变、外观变化带来的分割 效果不稳定的情况。
54.为了克服传统检测框到分割掩码模型不能利用时序信息这个问题,本发明对 检测框到分割掩码模型进行了改进,改进后的新模型可以称为管道分割(tube tosegmentation,简称tube2seg)模型。管道分割模型依然是一种全卷积神经网络架 构,该架构通过一个非本地模块(non-local module)来充分利用输入序列的时序信 息,从而捕获空间和时间中的长期依赖。非本地模块(non-local module)由非本地 块(non-local block)和拆分编码器(split-encoder)两部分架构组成,其中拆分编码器 包括询问编码器(query-encoder)和参考编码器(reference-encoder),该架构能够将 前序帧的图像语义信息和预测结果应用在当前帧的预测中。如图5所示,输入当 前帧 定位框、真实分割掩码(即第一帧分割掩码)和前一帧分割掩码,其中当 前帧 定位框由询问编码器进行编码,真实分割掩码、前一帧分割掩码由参考编 码器进行编码,然后询问编码器和参考编码器得到的特征图经非本地块进行处理 后,再通过解码器解码,即可得到当前帧的分割掩码(即伪标签)。
55.具体的管道分割模型结构如下:
56.输入包括当前帧 对应定位框,前序帧 分割掩码(包括第一帧真实掩码和 后续帧预测结果的掩码),将定位框作为第四通道级联在当前帧后分割掩码作为 第四通道级联在前序帧后。如图6所示,输入原图 定位框,其中0-1的矩阵其 实就是定位框转换为跟原图一样的矩阵,0表示定位框外的像素,1表示定位框 内的像素。
57.在裁剪和调整大小之后,对这两部分分别用不同的编码器进行编码,对当前 帧输入用询问编码器,对前序帧输入用参考编码器。
58.图7中显示的是只有两帧参考帧的情况,即前一帧和第一帧,这也是最重要 的两帧,第一帧有最准确的真实掩码,前一帧和当前帧的物体形态最为相似,实 际操作中也可以按需求增加其他中间帧。
59.图中 表示矩阵乘法,表示逐像素的加法。在两个编码器分别编码之后,将所有输入帧的特征图级联起来(表示为),并通过时空非本地块(non-local block),得到softmax归一化之后的特征图。然后,对所得的特征图进行上采样解码,最终得到当前帧t的预测结果。
60.用矩阵运算表示为:
61.[0062][0063]
其中softmax(x)表示归一化指数函数,x是输入帧的特征向量,t表示转置运算,采用1*1卷积操作分别进行g(x)、θ(x)和φ(x)的线性映射,w表示映射的权重,w
θ
就是θ(x)映射中的权重矩阵,因此映射可以表示为(xw
θ
)和(xw
φ
),两次映射的结果再一起进行矩阵乘法(第一项需要进行转置操作才能匹配),则得到(xw
θ
)
t
(xw
φ
)=x
twθtwφ
x。这样做能够加强同一帧中不同位置像素的联系、以及帧与帧之间的联系,提高长距离依赖。
[0064]
s3、伪标签的筛选和精修使用改进的管道分割模型生成分割伪标签依然有一些坏样本,为了提升伪标签的质量,本发明采用了三种措施:
[0065]
第一是坏样本过滤,我们根据生成掩码(mask)的置信度进行筛选,把总体置信度小于特定阈值(比如70%)的分割掩码视为坏样本删去,训练阶段把这些帧的标签设置为空,不进行梯度回传。另一种办法是人工干预,进行坏样本筛选,更准确但是需要额外的人力。
[0066]
第二是精修,每个视频标注一帧的真实掩码对管道分割模型进行精修,能够大大提高伪标签的质量。
[0067]
第三是在训练阶段采用更具鲁棒性的损失函数。传统分割网络采用逐像素的交叉熵代价函数l
θ
(x,y)=-logp
θ
(x,y),在某个像素x分类为y的置信度p(x,y)非常小时,取负对数的值会趋近于无穷大,因此个别误分类的像素导致损失过大,容易造成过拟合。为了增强损失函数的鲁棒性,我们将交叉熵代价函数改进为部分截断的交叉熵损失(partiallyhuberisedcross-entropyloss)部分截断的交叉熵代价函数。该函数定义如下,当置信度p(x,y)小于某个阈值(τ=2,3,4,5,可结合实际情况调整该超参数),损失函数截断为线性,从而限制这种误分类的情况,增强整体的鲁棒性。
[0068][0069]
优选地,可使用其他人工干预的方法交互式提升伪标签质量。
[0070]
s4、用伪标签训练视频目标分割模型
[0071]
我们用原视频和得到的分割伪标签训练视频目标分割网络,包括但不限于当前效果比较好的时空记忆力模型(space-timememorynetworks,简称stm),前后背景融合模型(collaborativevideoobjectsegmentationbyforeground-backgroundintegration,简称cfbi),小样本学习器模型(learningwhattolearnforvideoobjectsegmentation,简称lwl)。这部分直接应用当前最好的视频目标分割模型训练即可。优选地,还可以使用生成的伪标签训练视频实例分割模型,可应用在视频实例分割。
[0072]
视频目标分割方法效果分析
[0073]
我们用伪标签训练好的视频目标分割模型进行预测,在下表中详细展示了不同设置下训练的stm-vos(视频目标分割时空记忆力模型)在davis2017和youtube-vos2018数据集上的评估结果。前三行是引用stm文章【ohsw,leejy,xun,etal.videoobjectsegmentationusingspace-timememorynetworks[j].2019.】的实验结果。接下来的七行是我 们实验复现的结果,从全监督模式到弱监督模式,我们验证了多种不同的策 略,例如过滤噪声样本、使用一个真实掩码进行微调以及利用鲁棒损失函数。 注意,在第二
列“视频标注掩码数量”的值中,符号{*}表示需要人工评估伪 标签质量。
[0074][0075]
在采用检测框到分割掩码 精修 鲁棒性函数的情况下最终和全监督模式训 练的差距仅有1.4%(youtube-vos数据集)。
[0076]
和其他弱监督视频目标分割方法的效果对比如下:我们列出了各自方法所使 用的监督信息,可以看出我们的方法在youtube-vos数据集的效果尤其突出, 能够在标注数据量和最终效果上取得很好的折中。下表中展示了时空记忆力视频 目标分割方法(包括stm-vos的两种设置:box2seg模型 鲁棒损失函数、 box2seg模型 标签精修)、两种弱监督视频目标分割方法(包括premvos、 siam r-cnn)和四种无监督视频目标分割方法(包括mast、mug、uvc、 corrflow)的比较。第二列“标注图片掩码数量”,显示这些方法是否使用静态图 像的分割掩码。第三列“标注视频检测框数量”,显示这些方法是否使用视频序 列的检测框。第四列“标注视频掩码数量”,显示这些方法使用的视频分割掩码 数量。可以看出我们已经在很大程度上超越了之前的所有方法。
[0077][0078]
实际应用场景及应用
[0079]
视频目标分割是计算机视觉领域中一个非常重要的方向,在视频编辑、场景 理解、视频监控、事件检索中都有相关需求,比如要得到输入视频中人体的位置 和所占区域,或者需要进一步对人体进行强调、描边、消除都需要视频目标分割 技术。
[0080]
在工业应用中,视频会议的背景遮挡/替换应用就是一个非常典型的视频目 标分
割技术,首先将视频中的人体分割出来,保留人体作为前景,其他部分作为 背景区域,并进一步根据用户偏好把背景替换为书房、办公室、海边等不同背景 图案。再比如,各视频播放软件中的弹幕防挡功能也是基于视频目标分割技术实 现的,对于腾讯视频、哔哩哔哩中用户发送弹幕较多的视频,弹幕完全挡住了主 体人物,其他用户既想要能够看清视频中的人物,又不想完全关闭有趣的弹幕, 这时候通过视频目标分割技术把主体人物分割出来作为前景,弹幕遇到主体人的 掩码后不从前面滑过,这样就能够实现主体人物的防挡功能。
[0081]
而在实际应用中,逐帧标注视频目标是非常耗时且昂贵的工作,且视频帧之 间相似性较高,存在大量冗余工作。如果能够只利用便宜、易获取的检测框标注, 来学习视频分割模型,将能够大大降低应用成本。在本发明实施例中,检测框只 需要确定目标的四个关键角点,而分割的标注需要逐像素级别的标注。本发明实 施例中的方法能够仅利用检测框信息或者较少的分割标注,获得逼近于完全逐像 素标注方法学习得到的模型效果,能够大大提高效率、降低成本。
[0082]
以上内容是结合具体的优选实施方式对本发明所做的进一步详细说明,不能 认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员 来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而 且性能或用途相同,都应当视为属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。