1.本发明涉及一种基于识别的电子签名手写笔迹分割方法,属于笔迹分割领域。
背景技术:
2.笔迹分割是指将数据采集设备(如触摸屏、数字手写板等)获取的书写轨迹信息中的手写笔迹分解成孤立汉字的过程。笔迹分割的结果对后续汉字识别的准确度有极大影响。但由于手写体汉字的书写随意性很大,相邻汉字之间的位置关系也复杂多样,笔迹容易发生粘连和交叉,尚缺乏一种能准确分割电子签名手写笔迹的方法。
3.常见的汉字分割方法有基于笔画结构的方法、基于像素追踪的方法、基于神经网络识别的方法等。相对于其他方法,基于识别的汉字分割方法虽然可以动态选择分割点,减少分割错误,但单字分割耗时长且仍存在较多的重检和漏检的情况:如图2所示,同一个汉字的不同部件被独立分割,或出现与其他汉字一起被合并分割的情况。
4.yolov1的网络结构由24个卷积层、1个展开层(将多维度的卷积结果展开为一维结构,起过渡作用)、2个全连接层构成,目标检测步骤如下:首先将输入图像缩放到448
×
448的固定尺寸,然后将图像输入到卷积神经网络中,输出预测出边界框的坐标、框中物体的类别和置信度(即输出一个7
×7×
30的张量,7
×7×
30中的30=(20类概率 2
×
5(置信度,边框位置)。yolov1的优点是检测速度非常快,但由于划分图片网格较为粗糙,每个网格生成的边界框个数较少,使该网络对小尺寸目标和邻近目标的检测效果较差,且定位误差较多,使该网络整体检测精度也较低。
技术实现要素:
5.为了克服现有技术中存在的问题,本发明设计了一种基于识别的电子签名手写笔迹分割方法,通过合并边界框,解决由于断笔和文字结构的原因造成的单字被分割成多字的情况,提高笔迹分割准确度。
6.为了实现上述目的,本发明采用如下技术方案:
7.技术方案一:
8.一种基于识别的电子签名手写笔迹分割方法,包括以下步骤:
9.预先构建并训练笔迹分割模型;
10.获取待处理图像;输入待处理图像至笔迹分割模型,笔迹分割模型输出预测结果,预测结果包括若干个边界框和若干个目标置信度;
11.对所述若干个边界框进行合并,得到手写笔迹分割结果。
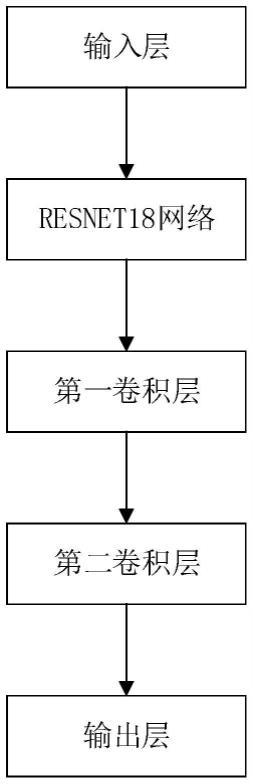
12.进一步地,所述笔迹分割模型包括输入层、主干网络、第一卷积层、第二卷积层和输出层。
13.进一步地,所述第一卷积层的卷积核为3*3;所述第二卷积层的卷积核为1*1。
14.进一步地,所述主干网络包括若干个卷积层和若干个残差结构。
15.进一步地,合并y轴方向上重合的边界框。
16.进一步地,合并x轴方向上间距小于间距阈值且合并后各边界框宽度的方差值降低的边界框。
17.进一步地,根据各边界框宽度的平均值,确定所述间距阈值。
18.进一步地,利用损失函数迭代训练所述笔迹分割模型,所述损失函数计算的损失值为目标预测损失值和边界框预测损失值之和。
19.进一步地,获取用户电子签名的笔迹坐标信息;根据所述笔迹坐标信息生成笔迹图片,将笔迹图片作为待处理图片输入至笔迹分割模型。
20.技术方案二:
21.一种基于识别的电子签名手写笔迹分割设备,包括处理器、用于存储所述处理器可执行指令和笔迹分割模型的存储器;所述处理器用于执行以下指令:
22.获取待处理图像;
23.输入待处理图像至笔迹分割模型,笔迹分割模型输出预测结果,预测结果包括若干个边界框和若干个目标置信度;
24.对所述若干个边界框进行合并,得到手写笔迹分割结果。
25.进一步地,所述笔迹分割模型包括输入层、主干网络、第一卷积层、第二卷积层和输出层。
26.进一步地,所述第一卷积层的卷积核为3*3;所述第二卷积层的卷积核为1*1。
27.进一步地,所述主干网络包括若干个卷积层和若干个残差结构。
28.进一步地,合并y轴方向上重合的边界框。
29.进一步地,合并x轴方向上间距小于间距阈值且合并后各边界框宽度的方差值降低的边界框。
30.进一步地,根据各边界框宽度的平均值,确定所述间距阈值。
31.进一步地,利用损失函数迭代训练所述笔迹分割模型,所述损失函数计算的损失值为目标预测损失值和边界框预测损失值之和。
32.进一步地,获取用户电子签名的笔迹坐标信息;根据所述笔迹坐标信息生成笔迹图片,将笔迹图片作为待处理图片输入至笔迹分割模型。
33.与现有技术相比本发明有以下特点和有益效果:
34.1、本发明将yolo_v1中的backbone主干网络修改为resnet18,将展平层和全连接层修改为3*3和1*1的卷积层,利用修改后的yolo_v1作为笔迹分割模型,其中resnet18能有效提高笔迹分割模型的特征提取速度和边界框位置准确度,第一卷积层和第二卷积层增加了更多空间信息,使笔迹分割模型能够学习到更多的特征,从而进一步提高笔迹分割模得到的边界框位置准确度。
35.2、本发明中修改了yolo_v中的损失函数,修改后损失函数l仅计算目标预测损失值和边界框预测损失值,则训练得到的笔迹分割模型仅输出目标特征14*14*1和边界框特征14*14*4,主干网络不用对目标类别的特征提取,笔迹分割模型的训练量大幅度降低、计算速度提升。
36.3、本发明通过合并边界框,解决由于断笔和文字结构的原因造成的单字被分割成多字的情况,提高笔迹分割准确度。
37.4、由于电子签名的文字量少(仅有2~4个字),边界框宽度的平均值在文字合并前
后波动较大,本发明利用边界框宽度的方差值指标进一步提高笔迹分割准确度,该方法计算量小、分割速度快。
附图说明
38.图1是本发明笔迹分割模型示意图;
39.图2是现有技术笔迹分割结果示意图;
40.图3、4是本发明笔迹分割结果示意图。
具体实施方式
41.下面结合实施例对本发明进行更详细的描述。
42.实施例一
43.一种基于识别的电子签名手写笔迹分割方法,包括以下步骤:
44.s1、如图1所示,构建笔迹分割模型:笔迹分割模型包括输入层、主干网络(本实施例中主干网络为resnet18,包括17个卷积层、1个全连接层的隐藏层以及多个残差结构)、第一卷积层(尺寸为3*3*512)、第二卷积层(尺寸为1*1*5)和输出层。
45.s2、构建损失函数l=l
obj
l
bbox
;
46.其中,l
ob
j为目标预测损失函数;l
bbox
为边界框预测损失函数。
[0047][0048][0049]
式中,λ
obj
=5;λ
noobj
=1;s2表示主干网络提取的特征的长宽尺寸,本实施例中s2=14*14;表示输入数据的标签值;和为控制函数,第i个格点中包含目标时,为1、为0,第i个格点中不包含目标时,为0、为1;λ
bbox
=5;xi和分别表示边界框x轴的实际位置和预测位置,yi和分别表示边界框y轴的实际位置和预测位置,wi和分别表示边界框的实际宽度和预测宽度,hi和分别表示边界框实际高度和预测高度。
[0050]
s3、构建训练数据集:
[0051]
从电子签名设备读取笔迹坐标文件;新建签名轨迹图层,利用笔迹坐标文件中的坐标信息还原签名轨迹,图层上以像素值0表示背景、像素值255表示签名轨迹,生成笔迹图片。
[0052]
标注笔迹图片中各文字所在区域坐标,格式为(x,y,w,h,c),其中x表示文字框x轴位置,y表示文字框y轴位置,w表示文字框宽度,h表示文字框高度,c表示该区域是否为文字区。将多张带标注的笔迹图片作为训练数据集,并按比例8:1:1划分为训练集,测试集和验证集。
[0053]
s4、设置超参数,训练笔迹分割模型
[0054]
设置初始学习率为0.1,单批次训练数据大小64,训练数据迭代次数10epoch。输入训练集至笔迹分割模型,利用损失函数l迭代训练笔迹分割模型。训练过程中,利用测试集
数据测试确定模型的准确率,观察模型准确率是否有明显的浮动,验证模型的泛化能力;利用验证集来测试模型准确率,通过调整超参数提升模型准确率。
[0055]
s5、获取待处理图像;输入待处理图像至笔迹分割模型,笔迹分割模型输出预测结果,预测结果(尺寸为14*14*5)包括若干个边界框(尺寸为14*14*4)、以及表示边界框内目标为文字可能性的目标置信度(尺寸为14*14*1)。
[0056]
实施例二
[0057]
进一步地,对笔迹分割模型输出的若干个边界框进行合并,具体步骤如下:
[0058]
a1、合并y轴方向上重合的边界框:如图3所示,若两个边界框在y轴方向上没有重叠但在x轴方向上重叠(具体为边界框与另一边界框在y轴坐标范围重合,x轴坐标范围没有重合),则合并两个边界框。
[0059]
a2、计算边界框宽度的平均值w和方差值s;
[0060]
a3、遍历边界框,查找x轴方向上间距小于间距阈值(本实施例中间距阈值设为0.5*w)的相邻边界框;若查找到多个间距小于间距阈值的相邻边界框,优先合并间距最小的相邻边界框;计算这两个相邻边界框合并后的边界框宽度的方差值s’,若s’《s,则合并这两个相邻边界框,重新计算并更新平均值w和方差值s;否则,不合并这两个相邻边界框;
[0061]
a4、重复执行步骤a3,直至没有可以合并的边界框,合并结果如图4所示。
[0062]
显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。